概述
副本管理器是负责管理和操作集群中 Broker 的副本,也承担部分分区管理工作,比如变更分区副本日志路径。副本管理器会处理以下来自 Client 或 Controller 的请求:
- LeaderAndIsr 请求。来自 Controller,副本管理器会根据携带的信息进行 Follower/Leader 角色变换。
- StopReplica 请求。来自 Controller,停止副本。
- UpdateMedatada 请求。来自 Controller,更新元数据。
- Producer 请求。来自生产者客户端。向本地追加消息。
- ListOffset 请求。
副本管理器有以下两点需要我们关注:
- Follower/Leader 角色变换。Controller 将分区分配好的方案发送给相关 Broker,Broker 的副本管理器根据这份分配方案对自己管理的副本进行调整。会出现下线某个副本、将 follower 副本变更为 leader 副本等操作。这些操作都是由副本管理器完成的。
组件

副本管理器相关组件介绍如下:
| 组件名称 | 说明 |
|---|---|
| LogAppendResult | 写入副本消息操作后返回的结果信息 |
| LogDeleteRecordsResult | 删除副本操作后返回的结果信息 |
| LogReadResult | 读取副本本地日志返回的结果信息,包含消息数据、High Watermark、Log Start Offset 等 |
| FetchPartitionData | 返回分区数据及相关元数据信息,包含High Watermark、Log Start Offset |
| HostedPartition | 表示当前Broker所管理的分区状态。共有4种状态,其中 Deferred 状态是 Raft 协议的专属状态。另外不包括 None、Online 和 Offline。 |
| ReplicaManager | 副本管理器的实现类,定义各类数据结构及处理逻辑 |
ReplicaManager
我们从最重要的类 ReplicaManager 进行分析。先对相关变量进行学习:
变量
/*** 副本管理器:负责管理和操作集群中Broker的副本对象,* 另外还承担了一部分分区管理工作,比如变更整个分区的副本日志路径等。** {@link ReplicaManager} 类非常重要,它是Kafka构建副本同步机制的重要组件之一。* 副本同步过程出现的问题大都比较难解决。* 副本同步本质上是副本读取+副本写入。* 定义了4个时间轮用于处理延迟请求。延迟请求类型包括有:PRODUCER、FETCH、DELETE_RECORDS、ELECT_LEADERS** @param config 配置管理类* @param metrics 监控指标类* @param time 定时器类* @param zkClient Zookeeper客户端* @param scheduler Kafka调度器* @param logManager 日志管理器* @param isShuttingDown 是否已经关闭* @param quotaManagers 配额管理器(用于限流)* @param brokerTopicStats Broker主题监控指标类* @param metadataCache Broker元数据缓存* @param logDirFailureChannel 失效日志路径处理器。Kafka1.1新增对JBOD的支持,即Broker可以配置多个日志路径,* 如果某个日志路径不可用(比如磁盘出现故障),那么就可以切换到其它日志路径(最好是另一块新的磁盘),以保障集群可用。* @param delayedProducePurgatory 处理延迟「PRODUCER」请求的Purgatory* @param delayedFetchPurgatory 处理延迟「FETCH」请求的Purgatory* @param delayedDeleteRecordsPurgatory 处理延迟「DELETE_RECORDS」请求的Purgatory* @param delayedElectLeaderPurgatory 处理延迟「ELECT_LEADERS」请求的Purgatory* @param threadNamePrefix 线程名前缀* @param configRepository 配置类* @param alterIsrManager ISR管理器*/class ReplicaManager(val config: KafkaConfig,metrics: Metrics,time: Time,val zkClient: Option[KafkaZkClient],scheduler: Scheduler,val logManager: LogManager,val isShuttingDown: AtomicBoolean,quotaManagers: QuotaManagers,val brokerTopicStats: BrokerTopicStats,val metadataCache: MetadataCache,logDirFailureChannel: LogDirFailureChannel,val delayedProducePurgatory: DelayedOperationPurgatory[DelayedProduce],val delayedFetchPurgatory: DelayedOperationPurgatory[DelayedFetch],val delayedDeleteRecordsPurgatory: DelayedOperationPurgatory[DelayedDeleteRecords],val delayedElectLeaderPurgatory: DelayedOperationPurgatory[DelayedElectLeader],threadNamePrefix: Option[String],configRepository: ConfigRepository,val alterIsrManager: AlterIsrManager) extends Logging with KafkaMetricsGroup {/*** Broker管理多个分区,它需要对这些分区的状态有所了解。* 从Broker视角来分析,它的本职工作就是管理副本,Kafka没有所谓的分区管理器,* 而ReplicaManager副本管理器会拥有副本对应分区的状态。* 集群的Controller是大管家,它是第一时间感知集群所有分区的变化的,* 然后通过控制类请求向具体的Broker发送请求,Broker收到请求后更新本地缓存。*/protected val allPartitions = new Pool[TopicPartition, HostedPartition](valueFactory = Some(tp => HostedPartition.Online(Partition(tp, time, configRepository, this))))/*** Broker的副本拉取线程并非只存在一个线程,而是由「num.replica.fetchers」指定,默认值:1。* 如果num.replica.fetchers>1,那就需要线程池管理器管理这些拉取线程。replicaFetcherManager 就是用来干这个的。* ReplicaManager类利用replicateFetcherManager管理所有Fetcher线程的生命周期,包括创建、启动、添加、停止和移除等。*/val replicaFetcherManager = createReplicaFetcherManager(metrics, time, threadNamePrefix, quotaManagers.follower)// ...}
LogManager
日志管理器。副本管理器对日志的删除、读取和写入都是委托 LogManager 来完成的。
metadataCache
这是 Broker 内部对集群元数据缓存。从该对象中可以获取分区详情,包括 Leader、AR 以及 ISR 集合。每台 Broker 都是和 Controller 打交道,并非直接从 Zookeeper 获取集群元数据信息。通过异步从 Controller 同步集群元数据信息。
logDirFailureChannel
kafka 1.1 版本新增对 JBOD 的支持。即如果 Broker 配置了多个日志路径(一般在不同磁盘上),当某个日志路径不可用后(比如磁盘空间不够),Broker 依然能正常工作。其中 logDirFailureChannel 是暂存失效日志路径的管理器类。
Purgatory
Purgatory 是由监视器和时间轮组成的,用来处理延迟请求操作。副本管理器定义了 4 个 Purgatory,分别是:
- DelayedOperationPurgatory[DelayedProduce]:存放生产者发送的请求。
- DelayedOperationPurgatory[DelayedFetch]:存放来自其它 Follower 或 Consumer 的 FETCH 请求。
- DelayedOperationPurgatory[DelayedDeleteRecords]:存放删除消息的延迟请求。
DelayedOperationPurgatory[DelayedElectLeader]:存放分区Leader选举的延迟操作。
controllerEpoch
每个副本管理器缓存 Controller 版本号,用来屏蔽 Zombie Controller,在某一时刻,可能存在两个 Kafka Controller,但是它们的版本号不相同,新的 Controller 版本号较大。
allPartitions
副本管理器将管理的副本以分区来分类。从这一角度也相当于承担部分管理分区的职责。
replicaFetcherManager
Broker 上的 Follower 副本需要和 Leader 副本保持同步,同步操作会使用单独的线程池完成,这些线程称为 FETCH 线程,它们是由
replicaFetcherManager所管理,默认 FETCH 线程数量为 1。启动副本管理器
/*** 启动副本管理器*/def startup(): Unit = {// #1 周期性检查 ISR 是否存在已过期的副本,如果存在,则将它从 ISR 集合中移除。// 每隔config.replicaLagTimeMaxMs / 2毫秒执行一次检查,这个时间既不会太大,导致决策过慢,而导致数据丢失。// 也不会太小,导致 ISR 集合会频繁更新。scheduler.schedule("isr-expiration", maybeShrinkIsr _, period = config.replicaLagTimeMaxMs / 2, unit = TimeUnit.MILLISECONDS)// #2 周期性检查关闭空闲的副本迁移线程scheduler.schedule("shutdown-idle-replica-alter-log-dirs-thread", shutdownIdleReplicaAlterLogDirsThread _, period = 10000L, unit = TimeUnit.MILLISECONDS)val haltBrokerOnFailure = config.interBrokerProtocolVersion < KAFKA_1_0_IV0logDirFailureHandler = new LogDirFailureHandler("LogDirFailureHandler", haltBrokerOnFailure)logDirFailureHandler.start()}
ISR 扩缩
我们知道, ISR 集合是 Leader 的预备役,当 Leader 所在的 Broker 宕机后,Controller 的分区状态机会在根据 Leader 副本选举策略在 ISR 中选择一个副本作为该分区的 Leader。成为预备役是有一定条件的,如果没有满足条件,那么先”退下”修炼好了再来。副本状态机通过定时任务来收缩集群部分分区(那里 Leader 在当前的 Broker 的分区)的 ISR 集合。
ISR 收缩
- 周期性(15S)地检查所在当前 Broker 的 Leader 分区,判断是否需要对该分区的 ISR 列表进行收缩。
- 收缩条件是:
(currentTimeMs - followerReplica.lastCaughtUpTimeMs) > maxLagMs(30S) - 将修改后的 ISR 列表发送给Controller(AlterIsrRequest)。Controller收到请求后会更新Zookeeper节点数据,并向其它Broker广播更新元数据请求。
如果抬升了 HW,那么尝试解锁延迟请求。
/*** 这个方法会被周期性调用,主要判断是否需要对 ISR 集合进行扩缩操作。* 1.收缩操作:指将ISR集合中与Leader差距过大的副本移除的过程。* 2.扩容操作:将消息成功追赶的副本添加到ISR集合中。** 如果定义差距过大呢?* ISR中Follower滞后Leader的时间超过Broker端参数「replica.lag.time.max.ms(30S)」的1.5倍,则意味差距过大,该副本需要被剔除* 那为啥是 1.5 倍呢?因为线程周期性检查的时间是 replica.lag.time.max.ms 的一半,所以滞后程序小于1.5倍的副本仍有存在ISR集合中。* 可以理解为最多检查3次,如果超过3次发现时间过大,那么就会从ISR中移除。*/private def maybeShrinkIsr(): Unit = {trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR")allPartitions.keys.foreach { topicPartition =>// 对在线的分区进行ISR缩容操作onlinePartition(topicPartition).foreach(_.maybeShrinkIsr())}}
/*** 遍历分区所有在线的副本,剔除那些不满足ISR规范的副本ID* 不满足条件:如果超过默认时间(30)*1.5,那么就认为该副本已经跟不上队伍,需要从ISR集合中剔除*/def maybeShrinkIsr(): Unit = {// 判断是否需要执行ISR收缩val needsIsrUpdate = !isrState.isInflight && inReadLock(leaderIsrUpdateLock) {needsShrinkIsr()}val leaderHWIncremented = needsIsrUpdate && inWriteLock(leaderIsrUpdateLock) {leaderLogIfLocal.exists { leaderLog =>// 获取out-of-sync的副本列表val outOfSyncReplicaIds = getOutOfSyncReplicas(replicaLagTimeMaxMs)if (outOfSyncReplicaIds.nonEmpty) {val outOfSyncReplicaLog = outOfSyncReplicaIds.map { replicaId =>s"(brokerId: $replicaId, endOffset: ${getReplicaOrException(replicaId).logEndOffset})"}.mkString(" ")val newIsrLog = (isrState.isr -- outOfSyncReplicaIds).mkString(",")// 更新Zookeeper中相关的ISR数据以及broker的元数据本地缓存shrinkIsr(outOfSyncReplicaIds)// 尝试更新Leader副本的高水位值,因为分区的HW是由ISR集合中最小的LEO值决定maybeIncrementLeaderHW(leaderLog)} else {false}}}// 如果抬升了HW,那么部分FETCH就可以得到响应,尝试延迟请求if (leaderHWIncremented)tryCompleteDelayedRequests()}
/*** Follower和Leader有一样的LEO值,不会被认为是out-of-sync。成为out-of-sync有以下两大类:* 1.卡住的Followers。如果副本的LEO的值已经很长时间没有被更新(更新时间间隔>maxLagMs),那么就说明Followers卡住了,需要从ISR中剔除。* 2.慢的Followers。能力有限,能胜任ISR还是需要有两把刷子的。如果你同步太慢了,对不起,你被剔除了。如果副本在最后的maxLagMs毫秒内没有* 读到LEO,那么说明Follower滞后。** 两种类型都是通过检查 lastCaughtUpTimeMs 来处理的,这个值表示副本最后完全赶上的时间。如果违反任何一个条件,该副本就被认为是不同步的。* 旧的「replica.lag.max.message」参数在 kakfa0.11.0 版本正式被移除,原因在于这个参数用户不好把控。设置过大会增大数据丢失风险,* 设置过小则会导致ISR集合对网络波动十分敏感,频繁扩缩容。** 如果已经有ISR更新请求发送,那么本次就会返回空集合。*/def getOutOfSyncReplicas(maxLagMs: Long): Set[Int] = {val current = isrStateif (!current.isInflight) {// 候选的处于ISR的副本列表,已经剔除Leaderval candidateReplicaIds = current.isr - localBrokerId// 获取当前时间val currentTimeMs = time.milliseconds()// 获取Leader的LEO值val leaderEndOffset = localLogOrException.logEndOffset// 获取out-of-sync的副本列表candidateReplicaIds.filter(replicaId => isFollowerOutOfSync(replicaId, leaderEndOffset, currentTimeMs, maxLagMs))} else {Set.empty}}/*** 确认该副本是否需要从ISR集合中被剔除,* 剔除标准是:(currentTimeMs - followerReplica.lastCaughtUpTimeMs) > maxLagMs*** @param replicaId 副本ID* @param leaderEndOffset Leader的LEO值* @param currentTimeMs 当前时间戳* @param maxLagMs 最大滞后时间间隔,默认值:30S* @return*/private def isFollowerOutOfSync(replicaId: Int, leaderEndOffset: Long, currentTimeMs: Long, maxLagMs: Long): Boolean = {// #1 获取副本详情val followerReplica = getReplicaOrException(replicaId)// #2 主要是判断时间戳:当前时间-副本最大追上时间戳 > maxLagMs,// 说明距离上次追上的时间差距过大,需要从ISR集合中剔除followerReplica.logEndOffset != leaderEndOffset &&(currentTimeMs - followerReplica.lastCaughtUpTimeMs) > maxLagMs}// _lastCaughtUpTimeMs就是每个Follower的FETCH时间if (followerFetchOffsetMetadata.messageOffset >= leaderEndOffset)_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, followerFetchTimeMs)else if (followerFetchOffsetMetadata.messageOffset >= lastFetchLeaderLogEndOffset)_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, lastFetchTimeMs)
ISR 扩容
如果此前该副本已经从 ISR 中被剔除,它也可以经过一段时间同步后追上 Leader 副本。因此,每次每当收到 Follower 的 FETCH 请求,都会判断一个它是否需要重新进入 ISR。核心方法是在 Partition#maybeExpandIsr(),具体源码解析如下:
/*** 每当收到Follower的FETCH请求时,对应副本的 LEO 就会增加,因此可以尝试判断该Follower是否有资格重新加入ISR集合中。* 判断条件:* 1.副本的LEO >= 分区的HW* 2.追上了当前Leader版本号对应的baseoffset。这是因为如果分区的HW值可能小于Leader baseoffset。* 如果允许 HW<=副本LEO < Leader' baseoffset 加入ISR,那么如果发生Leader选举,这个副本当选Leader,则* follower LEO 到 Leader' baseoffset 的数据会丢失。** @param followerReplica* @param followerFetchTimeMs*/private def maybeExpandIsr(followerReplica: Replica, followerFetchTimeMs: Long): Unit = {// #1 判断该副本是否可以加入ISR集合中,如果可以,返回trueval needsIsrUpdate = canAddReplicaToIsr(followerReplica.brokerId) && inReadLock(leaderIsrUpdateLock) {needsExpandIsr(followerReplica)}if (needsIsrUpdate) {inWriteLock(leaderIsrUpdateLock) {// #2 再次判断if (needsExpandIsr(followerReplica)) {// #3 将该副本重新添加到ISR列表中:向Controller发送AlertIsrRequest请求expandIsr(followerReplica.brokerId)}}}}
判断
/*** 判断当前副本是否有资格重新加入ISR** @param followerReplica 待判断的副本ID* @return*/private def needsExpandIsr(followerReplica: Replica): Boolean = {canAddReplicaToIsr(followerReplica.brokerId) && isFollowerAtHighwatermark(followerReplica)}
根据 follower 和分区水位线以及leader startOffset 比较,大于等于这两项就说明有资格重新加入 ISR 列表
/*** 判断副本的LEO值是否在分区HW之上,即 replica'LEO >=HW** @param followerReplica* @return*/private def isFollowerAtHighwatermark(followerReplica: Replica): Boolean = {leaderLogIfLocal.exists { leaderLog =>// #1 获取Follower的LEOval followerEndOffset = followerReplica.logEndOffset// #2 follower的LEO >= 分区的HW && follower的LEO >= 分区leader的baseoffsetfollowerEndOffset >= leaderLog.highWatermark && leaderEpochStartOffsetOpt.exists(followerEndOffset >= _)}}
将消息写入副本:appendRecords
从上图可知,需要调用此方法有以下使用场景:
- 场景一:写入生产者消息。
- 场景二:事务管理器写入事务元数据。
- 场景三:写入事务标记数据。
- 场景四:消费暑写入组消息。
我们知道,因为副本的存在,Leader 在持久化生产者消息时需要对 ACKS 进行处理:
- ACKS = 0,Leader 持久化到本地文件就表示生产者消息发送成功。生产者不会收到 Leader 的答复。
- ACKS = -1,必须等待位于 ISR 集合中的所有副本完成同步后才会返回消息写入成功的响应。
实现延迟操作就是基于 Purgatory 完成的。
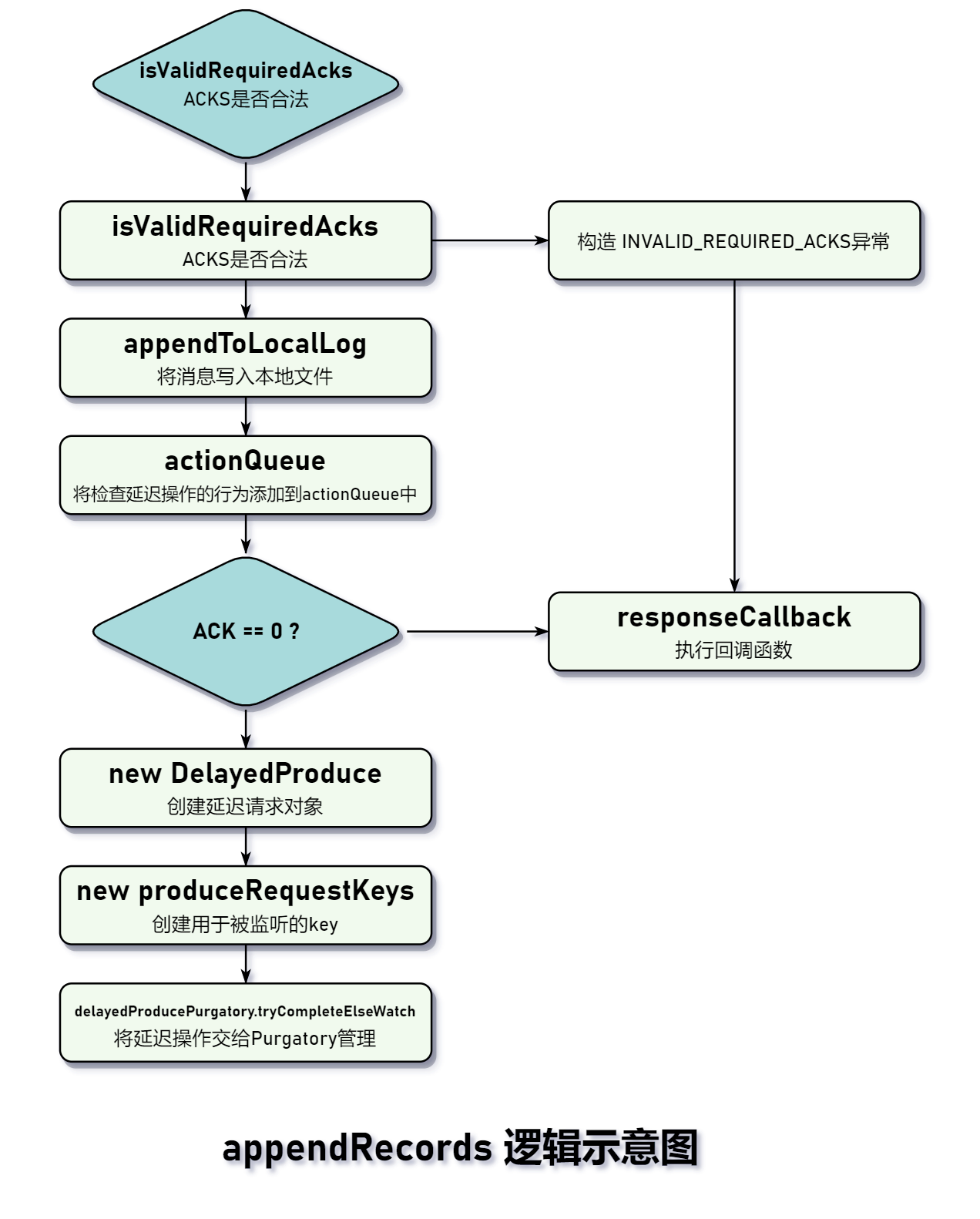
可以看到,其实日志写入的核心方法是步骤 #2 的 appendToLocalLog:
// kafka.server.ReplicaManager#appendToLocalLog/*** 将消息写入本地日志* @param internalTopicsAllowed* @param origin* @param entriesPerPartition* @param requiredAcks* @return*/private def appendToLocalLog(internalTopicsAllowed: Boolean,origin: AppendOrigin,entriesPerPartition: Map[TopicPartition, MemoryRecords],requiredAcks: Short): Map[TopicPartition, LogAppendResult] = {val traceEnabled = isTraceEnableddef processFailedRecord(topicPartition: TopicPartition, t: Throwable) = {val logStartOffset = onlinePartition(topicPartition).map(_.logStartOffset).getOrElse(-1L)brokerTopicStats.topicStats(topicPartition.topic).failedProduceRequestRate.mark()brokerTopicStats.allTopicsStats.failedProduceRequestRate.mark()error(s"Error processing append operation on partition $topicPartition", t)logStartOffset}entriesPerPartition.map { case (topicPartition, records) =>brokerTopicStats.topicStats(topicPartition.topic).totalProduceRequestRate.mark()brokerTopicStats.allTopicsStats.totalProduceRequestRate.mark()// reject appending to internal topics if it is not allowedif (Topic.isInternal(topicPartition.topic) && !internalTopicsAllowed) {(topicPartition, LogAppendResult(LogAppendInfo.UnknownLogAppendInfo,Some(new InvalidTopicException(s"Cannot append to internal topic ${topicPartition.topic}"))))} else {try {// #1 获取分区对象val partition = getPartitionOrException(topicPartition)// #2 向该分区追加消息val info = partition.appendRecordsToLeader(records, origin, requiredAcks)val numAppendedMessages = info.numMessages// 返回写入结果(topicPartition, LogAppendResult(info))} catch {// handle exception}}}}
步骤 #2 最终还是调用 Log.appendAsLeader 方法将日志写入到本地文件中。
副本读取:fetchMessages
在副本管理器中,方法 fetchMessages 是负责读取副本数据的方法。无论是消费者 Consumer 还是 Follower 副本,它们都是向 Broker 发送 FETCH 请求,Broker 收到请求后调用 ReplicaManager#fetchMessages 方法从底层日志中读取消息并返回给客户端。
为了提供网络通信效率,FETCH 请求也被设计成延迟操作:当无法满足最小值时就会等待一段时间(请求超时时间),直到满足条件或超时才会执行延迟操作。FETCH 的延迟操作相当于是一个缓冲请求,避免无意义的 FETCH 请求,导致集群网络负载过大。
/*** 从本地日志文件中获取消息,如果没有足够大小的消息,则会一直等待直到满足大小或超时后,回调函数被调用。* 消息者可以从任意副本中发送FETCH请求,但Follower只能向Leader发送FETCH请求。** @param timeout 请求超时时间* @param replicaId 副本ID* @param fetchMinBytes 一次拉取最小数量* @param fetchMaxBytes 一次拉取最大数量* @param hardMaxBytesLimit* @param fetchInfos 消息数据填充对象* @param quota 配额* @param responseCallback 响应回调方法* @param isolationLevel 隔离级别* @param clientMetadata 客户端元数据*/def fetchMessages(timeout: Long,replicaId: Int,fetchMinBytes: Int,fetchMaxBytes: Int,hardMaxBytesLimit: Boolean,fetchInfos: Seq[(TopicPartition, PartitionData)],quota: ReplicaQuota,responseCallback: Seq[(TopicPartition, FetchPartitionData)] => Unit,isolationLevel: IsolationLevel,clientMetadata: Option[ClientMetadata]): Unit = {// #1 区分FETCH请求来自Follower还是Consummerval isFromFollower = Request.isValidBrokerId(replicaId)val isFromConsumer = !(isFromFollower || replicaId == Request.FutureLocalReplicaId)// #2 确定隔离级别:根据不同的请求方以及隔离级别规定最大可读取范围:// 1.如果是Follower发出的请求,可以读到LEO// 2.如果请求来自READ_COMMITTED的消费者,那么可以读到Log Stable Offset值// 3.如果请求来自其它隔离级别的消费者,可以读到HW位置val fetchIsolation = if (!isFromConsumer)FetchLogEndelse if (isolationLevel == IsolationLevel.READ_COMMITTED)FetchTxnCommittedelseFetchHighWatermark// #3 如果请求来自跟或来Follower自旧版本的客户端(无 ClientMetadata),则限制对Leader的获取// Restrict fetching to leader if request is from follower or from a client with older version (no ClientMetadata)val fetchOnlyFromLeader = isFromFollower || (isFromConsumer && clientMetadata.isEmpty)// 定义读取日志方法// 从日志中读取消息(其实是确定起始物理位移+长度,并非直接将日志加载到内存中。使用FileChannel.transferTo()通过mmap文件将数据直接写入底层socket,避免内存拷贝)def readFromLog(): Seq[(TopicPartition, LogReadResult)] = {val result = readFromLocalLog(replicaId = replicaId,fetchOnlyFromLeader = fetchOnlyFromLeader,fetchIsolation = fetchIsolation,fetchMaxBytes = fetchMaxBytes,hardMaxBytesLimit = hardMaxBytesLimit,readPartitionInfo = fetchInfos,quota = quota,clientMetadata = clientMetadata)if (isFromFollower) updateFollowerFetchState(replicaId, result)else result}// #5 读取日志文件val logReadResults = readFromLog()// #6 对获取结果「logReadResults」统一处理var bytesReadable: Long = 0var errorReadingData = falsevar hasDivergingEpoch = falseval logReadResultMap = new mutable.HashMap[TopicPartition, LogReadResult]logReadResults.foreach { case (topicPartition, logReadResult) =>brokerTopicStats.topicStats(topicPartition.topic).totalFetchRequestRate.mark()brokerTopicStats.allTopicsStats.totalFetchRequestRate.mark()if (logReadResult.error != Errors.NONE)errorReadingData = trueif (logReadResult.divergingEpoch.nonEmpty)hasDivergingEpoch = truebytesReadable = bytesReadable + logReadResult.info.records.sizeInByteslogReadResultMap.put(topicPartition, logReadResult)}// #7 立刻响应需要具备以下条件:// 1.FETCH请求没有设置超时时间// 2.FETCH请求没有获取到任何数据// 3.已经累积足够多的数据可以发送响应了// 4.读取日志过程出现错误,比如磁盘损坏等// 5.我们发现了多个epoch(diverging epoch)if (timeout <= 0 || fetchInfos.isEmpty || bytesReadable >= fetchMinBytes || errorReadingData || hasDivergingEpoch) {// #7-1 可以立即发送FETCH Response响应val fetchPartitionData = logReadResults.map { case (tp, result) =>val isReassignmentFetch = isFromFollower && isAddingReplica(tp, replicaId)tp -> result.toFetchPartitionData(isReassignmentFetch)}// 调用回调函数responseCallback(fetchPartitionData)} else {// #7-2 无法满足立即返回FETCH Response,那么就需要对该请求进行延迟处理val fetchPartitionStatus = new mutable.ArrayBuffer[(TopicPartition, FetchPartitionStatus)]fetchInfos.foreach { case (topicPartition, partitionData) =>logReadResultMap.get(topicPartition).foreach(logReadResult => {val logOffsetMetadata = logReadResult.info.fetchOffsetMetadatafetchPartitionStatus += (topicPartition -> FetchPartitionStatus(logOffsetMetadata, partitionData))})}val fetchMetadata: SFetchMetadata = SFetchMetadata(fetchMinBytes, fetchMaxBytes, hardMaxBytesLimit,fetchOnlyFromLeader, fetchIsolation, isFromFollower, replicaId, fetchPartitionStatus)// 创建「DelayedFetch」延迟操作对象val delayedFetch = new DelayedFetch(timeout, fetchMetadata, this, quota, clientMetadata, responseCallback)// 根据分区构建监听的keyval delayedFetchKeys = fetchPartitionStatus.map { case (tp, _) => TopicPartitionOperationKey(tp) }// 将给delayedFetchPurgatory处理delayedFetchPurgatory.tryCompleteElseWatch(delayedFetch, delayedFetchKeys)}}

什么时候能够立即返回 Response 呢? 只要满足以下 4 个条件中的任意一个即可:
- FETCH 请求没有设置超时时间。请求方希望请求能够立即返回,无论是否成功读取数据。
- 未获取到任何数据。
- 已累积足够多的数据。
- 读取过程中出现异常。
-
Follower/Leader角色切换(处理LeaderAndIsrRequest)
一切的来源是收到 Controller 的
LeaderAndIsrReqeust请求: ```scala /**- 处理 Controller 发来的 {@link LeaderAndIsrRequest}
- Broker根据这个请求会进行相应处理:将旧的leader降级为follower,将旧的follower晋升为leader
- 然后移除相关监控指标,移除旧follower从获取线程中移除,并新的follower添加到获取线程中
- @param correlationId
- @param leaderAndIsrRequest
- @param onLeadershipChange
@return */ def becomeLeaderOrFollower(correlationId: Int, leaderAndIsrRequest: LeaderAndIsrRequest,
onLeadershipChange: (Iterable[Partition], Iterable[Partition]) => Unit): LeaderAndIsrResponse = {
replicaStateChangeLock synchronized { val controllerId = leaderAndIsrRequest.controllerId val requestPartitionStates = leaderAndIsrRequest.partitionStates.asScala // Map
val topicIds = leaderAndIsrRequest.topicIds() val response = { // #1 屏蔽Zombie Controller发送的请求 // 判断Controller版本号,如果小于缓存中的Controller版本号,说明是已过期的Controller发送的数据,忽略即可 if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) { leaderAndIsrRequest.getErrorResponse(0, Errors.STALE_CONTROLLER_EPOCH.exception) } else { // #2 存放每个分区变更结果,value是相关错误,如果该分区成功变更则为None,否则为相关错误码 val responseMap = new mutable.HashMap[TopicPartition, Errors]
// #3 更新broker缓存中的Controller版本号,一直保持最新的值 controllerEpoch = leaderAndIsrRequest.controllerEpoch
// #4 记录本轮合法变更状态的分区列表 val partitionStates = new mutable.HashMapPartition, LeaderAndIsrPartitionState
// #5 按分区处理Controller发过来的数据,检查本地分区状态是否异常 requestPartitionStates.foreach { partitionState =>
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)// #6 从本地缓存中获取分区状态val partitionOpt = getPartition(topicPartition) match {case HostedPartition.Offline =>// #6-1 分区处于「Offline」状态,这可能是因为底层日志目录出现问题,比如磁盘满了// 返回 Errors.KAFKA_STORAGE_ERROR 错误responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)Nonecase _: HostedPartition.Deferred =>// #6-2「Deferred」状态不能存在依赖ZK的环境中,抛出异常,这只会存在Raft协议版本的Controllerthrow new IllegalStateException("We should never be deferring partition metadata changes and becoming a leader or follower when using ZooKeeper")case HostedPartition.Online(partition) =>// #6-3「Online」状态,直接赋值partitionOpt即可Some(partition)case HostedPartition.None =>// #6-4「None」状态,说明Broker本地缓存中没有该分区的状态,那么就创建新的对象并加入缓存中,// 再返回即可val partition = Partition(topicPartition, time, configRepository, this)allPartitions.putIfNotExists(topicPartition, HostedPartition.Online(partition))Some(partition)}// #7 对partitionOpt中的分区挨个检查,进行相关安全校验// 比如Topic id、版本号等,确保数据一致性partitionOpt.foreach { partition =>val currentLeaderEpoch = partition.getLeaderEpochval requestLeaderEpoch = partitionState.leaderEpochval requestTopicId = topicIds.get(topicPartition.topic)// #7-1 检查主题ID是否合法if (!partition.checkOrSetTopicId(requestTopicId)) {// TOPIC ID 不合法,返回Errors.INCONSISTENT_TOPIC_ID错误responseMap.put(topicPartition, Errors.INCONSISTENT_TOPIC_ID)} else if (requestLeaderEpoch > currentLeaderEpoch) {// #7-2 请求携带的Leader版本号 > 本地缓存的leader版本号。那么这是一次合法的leadership决定。// 因为每次ISR变换版本号都会+1,如果不大于本地缓存的版本号说明这个请求是过期的if (partitionState.replicas.contains(localBrokerId)) partitionStates.put(partition, partitionState)else {// 缓存不存在,返回相关错误responseMap.put(topicPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION)}} else if (requestLeaderEpoch < currentLeaderEpoch) {// #7-3 过期的请求(仅针对这个主题,有可能其它主题是合法的),返回Errors.STALE_CONTROLLER_EPOCH错误responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH)} else {// #7-4 版本号相等也是错误responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH)}}
}
// #8 获取当前Broker即将由Follower变为Leader的分区 val partitionsToBeLeader = partitionStates.filter { case (_, partitionState) =>
partitionState.leader == localBrokerId
}
// #9 获取当前Broker即将由Leader变为Follower的分区 val partitionsToBeFollower = partitionStates.filter { case (k, _) => !partitionsToBeLeader.contains(k) }
// #10 高水位检查点,这是一个文件,将各个Leader分区的HW周期性地持久化到本地磁盘中 val highWatermarkCheckpoints = new LazyOffsetCheckpoints(this.highWatermarkCheckpoints)
val partitionsBecomeLeader = if (partitionsToBeLeader.nonEmpty) {
// #11 将原本是Follower的副本晋升为LeadermakeLeaders(controllerId, controllerEpoch, partitionsToBeLeader, correlationId, responseMap, highWatermarkCheckpoints)
} else {
Set.empty[Partition]
}
val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty) {
// #12 将原本是Leader的副本降级为FollowermakeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap, highWatermarkCheckpoints)
} else {
Set.empty[Partition]
}
// #13 移除旧Leader相关监控指标 val followerTopicSet = partitionsBecomeFollower.map(_.topic).toSet updateLeaderAndFollowerMetrics(followerTopicSet)
// #14 更新分区状态:如果本地日志为空,说明底层的日志路径不可用,将该分区状态更改为「Offline」 leaderAndIsrRequest.partitionStates.forEach { partitionState =>
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)if (localLog(topicPartition).isEmpty)markPartitionOffline(topicPartition)
}
// #15 启用高水位检查点专属线程:定期将Broker上所有非Offline分区的高水位值写入到检查点文件中 // 在第一次收到「LeaderAndIsr」请求后就会初始化HW检查点线程 startHighWatermarkCheckPointThread()
// #16 添加日志路径数据迁移线程 maybeAddLogDirFetchers(partitionStates.keySet, highWatermarkCheckpoints)
// #17 关闭空闲的副本拉取线程 replicaFetcherManager.shutdownIdleFetcherThreads()
// #18 关闭空闲日志路径数据迁移线程 replicaAlterLogDirsManager.shutdownIdleFetcherThreads()
// #19 执行Leader变更后的回调方法 onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower) if (leaderAndIsrRequest.version() < 5) {
// 构造LeaderAndIsrResponse对象并返回val responsePartitions = responseMap.iterator.map { case (tp, error) =>new LeaderAndIsrPartitionError().setTopicName(tp.topic).setPartitionIndex(tp.partition).setErrorCode(error.code)}.toBuffernew LeaderAndIsrResponse(new LeaderAndIsrResponseData().setErrorCode(Errors.NONE.code).setPartitionErrors(responsePartitions.asJava), leaderAndIsrRequest.version())
} else {
val topics = new mutable.HashMap[String, List[LeaderAndIsrPartitionError]]responseMap.asJava.forEach { case (tp, error) =>if (!topics.contains(tp.topic)) {topics.put(tp.topic, List(new LeaderAndIsrPartitionError().setPartitionIndex(tp.partition).setErrorCode(error.code)))} else {topics.put(tp.topic, new LeaderAndIsrPartitionError().setPartitionIndex(tp.partition).setErrorCode(error.code) :: topics(tp.topic))}}val topicErrors = topics.iterator.map { case (topic, partitionError) =>new LeaderAndIsrTopicError().setTopicId(topicIds.get(topic)).setPartitionErrors(partitionError.asJava)}.toBuffernew LeaderAndIsrResponse(new LeaderAndIsrResponseData().setErrorCode(Errors.NONE.code).setTopics(topicErrors.asJava), leaderAndIsrRequest.version())
} } }
// #20 返回响应 response } }
<a name="UbAWu"></a>## 对旧的 Follower 晋升为 Leader1. 停掉这些分区对应的 `FETCH` 线程。1. 更新 Broker 缓存中的分区元数据。1. 将指定分区添加到 Leader 分区集合。```scala/*** Follower晋升为Leader,需要进行以下步骤:* 1.停止FETCH数据拉取线程(因为不需要向Leader拉取数据了)* 2.更新缓存中的分区元数据* 3.将该分区添加到Leader Partition集合中** 出现异常将会传播到 {@link KafkaApis} 对象中,每个分区都会包含这个异常,因为我们无法得知异常是哪个分区所抛出。** @param controllerId Controller所在的Broker ID* @param controllerEpoch Controller版本号* @param partitionStates 分区状态,从LeadderIsrRequest中获得* @param correlationId 请求体中的Correlation字段,用于日志调试* @param responseMap 响应集合* @param highWatermarkCheckpoints 操作磁盘上高水位检查点文件的工具类* @return*/private def makeLeaders(controllerId: Int,controllerEpoch: Int,partitionStates: Map[Partition, LeaderAndIsrPartitionState],correlationId: Int,responseMap: mutable.Map[TopicPartition, Errors],highWatermarkCheckpoints: OffsetCheckpoints): Set[Partition] = {// #1 先将所有的分区的错误状态置为NONEpartitionStates.keys.foreach { partition =>responseMap.put(partition.topicPartition, Errors.NONE)}val partitionsToMakeLeaders = mutable.Set[Partition]()try {// #2 将这些分区从FETCH线程中移除,意味着FETCH线程不再需要再向这些分区的leader发送FETCH请求了replicaFetcherManager.removeFetcherForPartitions(partitionStates.keySet.map(_.topicPartition))partitionStates.forKeyValue { (partition, partitionState) =>try {// #3 委托Partition完成对follower晋升为leader的操作if (partition.makeLeader(partitionState, highWatermarkCheckpoints))partitionsToMakeLeaders += partitionelseNone} catch {case e: KafkaStorageException =>// 磁盘出现问题了,抛出异常stateChangeLogger.error(s"the replica for the partition is offline due to disk error $e")val dirOpt = getLogDir(partition.topicPartition)error(s"Error while making broker the leader for partition $partition in dir $dirOpt", e)responseMap.put(partition.topicPartition, Errors.KAFKA_STORAGE_ERROR)}}} catch {case e: Throwable =>partitionStates.keys.foreach { partition =>stateChangeLogger.error(s"Error while processing LeaderAndIsr request correlationId $correlationId received " +s"from controller $controllerId epoch $controllerEpoch for partition ${partition.topicPartition}", e)}// Re-throw the exception for it to be caught in KafkaApisthrow e}partitionsToMakeLeaders}
对旧的 Leader 降低为 Follower
我们先对 Follower 需要做什么工作有一个简单认为:通过 FETCH 线程向 Leader 发送 FETCH 请求,同步消息。所以 FETCH 线程会有相关 Follower 数据。如果有新的 Follower ,则需要添加到 FETCH 线程中进行数据同步操作。
- 将结果返回集合中所有分区的处理结果状态初始化为 Errors.NONE。
- 遍历 partitionStates 中的所有分区,依次为每个分区执行以下逻辑:
- 从分区详情中获取分区的 Leader Broker ID。
- 拿着上一步获取的 Broker ID,去 Broker 元数据缓存中找到 Leader Broker 对象。
- 如果对象存在,则调用
Partition#makeFollow()方法将当前原本是Leader的副本降低为Follower副本。降级成功,将分区添加到结果集合中。 - 如果 leader 对象不存在,依然创建出分区 follower 副本的日志对象。
def makeFollower(partitionState: LeaderAndIsrPartitionState,highWatermarkCheckpoints: OffsetCheckpoints): Boolean = {inWriteLock(leaderIsrUpdateLock) {val newLeaderBrokerId = partitionState.leaderval oldLeaderEpoch = leaderEpoch// #1 更新Controller版本号controllerEpoch = partitionState.controllerEpoch// #2 更新分区本地缓存:保存AR和清空ISRupdateAssignmentAndIsr(assignment = partitionState.replicas.asScala.iterator.map(_.toInt).toSeq,isr = Set.empty[Int],addingReplicas = partitionState.addingReplicas.asScala.map(_.toInt),removingReplicas = partitionState.removingReplicas.asScala.map(_.toInt))try {// #3 创建日志对象createLogIfNotExists(partitionState.isNew, isFutureReplica = false, highWatermarkCheckpoints)} catch {case e: ZooKeeperClientException =>stateChangeLogger.error(s"A ZooKeeper client exception has occurred. makeFollower will be skipping the " +s"state change for the partition $topicPartition with leader epoch: $leaderEpoch.", e)return false}val followerLog = localLogOrExceptionval leaderEpochEndOffset = followerLog.logEndOffsetleaderEpoch = partitionState.leaderEpochleaderEpochStartOffsetOpt = NonezkVersion = partitionState.zkVersionalterIsrManager.clearPending(topicPartition)if (leaderReplicaIdOpt.contains(newLeaderBrokerId) && leaderEpoch == oldLeaderEpoch) {false} else {leaderReplicaIdOpt = Some(newLeaderBrokerId)true}}}
- 更新 Controller Epoch 值
- 更新分区本地缓存。保存 AR 和清空 ISR。
- 如果分区不存在相关日志目录,创建日志对象。
// #1 从FETCH线程移除已成为follower的分区,因为这些分区的Leader已经发生变更,所以需要重新更新一下缓存replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition))// #2 收到 StopReplica 请求时强制完成延迟的操作。// 在分区重新分配的情况下,我们不能依靠接收 LeaderAndIsr 请求来完成这些操作,// 因为领导者可能不再是一个副本了。以前发生这种情况时,延迟操作最终会超时partitionsToMakeFollower.foreach { partition =>completeDelayedFetchOrProduceRequests(partition.topicPartition)}if (isShuttingDown.get()) {} else {// #3 构建FETCH线程元数据:Map[TopicPartition, InitialFetchState]val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map { partition =>val leader = metadataCache.getAliveBrokers.find(_.id == partition.leaderReplicaIdOpt.get).get.brokerEndPoint(config.interBrokerListenerName)val log = partition.localLogOrExceptionval fetchOffset = initialFetchOffset(log)partition.topicPartition -> InitialFetchState(leader, partition.getLeaderEpoch, fetchOffset)}.toMap// #4 将FETCH元数据添加到FETCH线程,线程会根据元数据从对应的leader节点拉取消息replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)}} catch {case e: Throwable =>throw e}

若有收获,就点个赞吧
0 人点赞
