概述
Kafka 的网络底层是基于 Java NIO 实现,考虑维护成本,尽量减少对其它项目的依赖,它并没有使用当下流行的网络基础设施框架 Netty,而是自己实现了一套基于 Java NIO 的异步非阻塞网络模型。本章,我们会通过源码深入了解客户端的各个组件的功能以及口味工业级的异步非阻塞网络框架有哪些细节。
上图是客户端网络层层次结构图,里面包含了构建客户端异步非阻塞模型的核心组件,由下到上依次做简要介绍:
- 第一层:JDK NIO。熟悉 Java NIO 网络编程的同学都应该十分了解。这里就不做说明。
- 第二层:传输层。这里 Kafka 是将 SSL 握手动作抽象出来。Kafka 支持多种安全传输协议更多详见官方文档。安全协议的验证是由 SslTransportLayer 实现类完成,而我们通常不需要加密传输,一般使用 PlaintextTransportLayer。它们都持有 Java 的 SelectionKey 和 SocketChannel,这是不是很熟悉呢?
- 第三层:KafkaChannel。这个对象持有传输层的实现类,因此,可以向底层的 SocketChannel 发送数据。抽象这一层主要是有两个非常重要的变量,分别是表示从通道中读到的数据对象
receive和写入通道的数据对象send,通过这两个对象可以判断数据读取/写入即时状态。这也是 Kafka 处理”粘包”的关键。 - 第四层:Kafka Selector。这个并非是 Java 的 Selector,所以我特别在前面加上 Kafka。我们知道,Kafka 的客户端会和多个 Broker 端建立连接(因为可能需要向多个主题分区发送数据),因此,需要一个”大管家”管理 KafkaChannel,于是 Kafka Selector 应运而生。除了保存每个 KafkaChannel 对象外,它还持有 Java Selector,这样就能通过轮询获取感兴趣的事件集合。网络 I/O 事件的核心处理逻辑就是在 Selector 中实现的。
- 第五层:KafkaClient。这是客户端直接交互的类,KafkaClient 接口定义了非常常用的 API,比如判断节点是否就绪、发送数据、执行 I/O 操作、断开某个节点的 Socket 连接等等。对客户端屏蔽了底层网络实现细节。
- 第六层:Sender 线程。Client 端只有一个网络 I/O 线程,通过多路复用技术和多个 Broker 进行数据交互。它在
while()循环中不断从消息缓冲区抽取数据并发送给 Broker。
通过上面的图示与概述,相信读者应该对 Client 端的网络组件有大致的了解,下面会从源码讲解组件之间是如何串和数据是如何流转的。
生产者-消费者模型 Sender 线程
概述是由下到上讲述各个组件的功能,接下来是由上到下通过源码方式讲述各个组件具体实现逻辑。org.apache.kafka.clients.producer.internals.Sender 线程是我们的突破口,正如节点标题所说,它是构成生产者-消费者模型的一部分。很明显,它属于消费者,不断从 RecordAccumulator 消息缓冲区中获取消息批次然后发送给 Broker 端。核心源码如下:
// org.apache.kafka.clients.producer.internals.Senderpublic class Sender implements Runnable {@Overridepublic void run() {log.debug("Starting Kafka producer I/O thread.");// main loop, runs until close is calledwhile (running) {try {// #1 不断从缓存队列中获取消息批次并发送给BrokerrunOnce();} catch (Exception e) {log.error("Uncaught error in kafka producer I/O thread: ", e);}}}/*** Sender线程核心逻辑。逻辑十分清晰:* 1.如果有事务管理器,则需要进行事务处理,比如生成PID、事务ID等。* 事务管理器比较麻烦,详见 https://cwiki.apache.org/confluence/display/KAFKA/KIP-98+-+Exactly+Once+Delivery+and+Transactional+Messaging* 2.从{@link RecordAccumulator}中抽取数据。这里,需要明确一点,存在{@link RecordAccumulator}是以分区为key,value就是该分区的消息数据。但是对Sender来说,* 它是以Broker节点为粒度,所以需要转换为key为Broker ID,value为消息数据,这个消息数据包含多个主题。* 3.执行网络I/O操作,对SocketChannel进行读/写操作。将数据发送给Broker端、接收来自上一次发送的ACK响应。*/void runOnce() {// #1 阶段一:事务管理器处理事务/幂等(如果有必要的话)if (transactionManager != null) {try {// #1-1transactionManager.maybeResolveSequences();// #1-2 校验事务管理器状态,如果有致命异常,则不能继续发送数据if (transactionManager.hasFatalError()) {RuntimeException lastError = transactionManager.lastError();if (lastError != null)maybeAbortBatches(lastError);client.poll(retryBackoffMs, time.milliseconds());return;}// #1-3 检查当前Producer是否需要一个新的PId,如果需要,// 则组装InitProducerId请求并放入「pendingRequests」队列中等待发送transactionManager.bumpIdempotentEpochAndResetIdIfNeeded();// #1-4 如果事务管理器中有需要发送的请求,则先将请求发送出现if (maybeSendAndPollTransactionalRequest()) {// 返回return;}} catch (AuthenticationException e) {// This is already logged as error, but propagated here to perform any clean ups.log.trace("Authentication exception while processing transactional request", e);transactionManager.authenticationFailed(e);}}// 获取当前时间戳long currentTimeMs = time.milliseconds();// #2 阶段二:从消息缓冲区中(RecordAccumulator)抽取待消息批次,// 并放入指定KafkaChannel变量中,等待发送long pollTimeout = sendProducerData(currentTimeMs);// #3 阶段三:真正执行网络I/O操作,对底层SocketChannel进行读/写等I/O操作client.poll(pollTimeout, currentTimeMs);}}
Sender 实现 Runnable,意味着它是一个线程。runOnce() 才是 Sender 类的核心逻辑:
- 事务管理器处理事务相关操作,比如生成 PID、事务 ID 等。详见 kafka 官方文档对事务说明。
- 从消息缓冲区(RecordAccumulator)抽取可发送的消息批次。并放入到
KafkaChannel#send变量中,等待数据网络 I/O 执行。 - 执行网络 I/O 操作。向底层 SocketChannel 读取/写入二进制数据。
可见,Sender 线程作为消费者,不断从消息缓冲区中获取消息批次,并将消息调用 KafkaClient#poll(Time) 方法执行网络 I/O。
Sender 线程从消息缓冲区中抽取数据
主要核心方法是 Sender#sendProducerData,最重要的目的是从 RecordAccumulator 缓冲区中抽取数据并放入对应的 KafkaChannel#send 变量中,等待网络 I/O 执行。
// org.apache.kafka.clients.producer.internals.Sender#sendProducerData/*** 从{@link RecordAccumulator} 中抽取可发送的消息批次,并放入 {@link KafkaChannel#send} 变量中** 1. 过滤未知分区Leader的主题列表。需要重新从Broker获取这些主题的元数据信息。* 2. 遍历「数据已就绪」的节点列表,挨个判断KafkaChannel是否可以发送数据(连接是否就绪、inFlightReqeust数量等等)* 3. 从「消息缓冲区 {@link RecordAccumulator}」中抽取待发送批次,并以节点为单位转化为 Map<Integer, List<ProducerBatch>> 形式,* 表示我要向节点发送这么一批数据。数据抽取也是有讲究的,每个节点抽取的数据量不能超过 {@link #maxRequestSize}* 4. 将批次信息写入{@link #inFlightBatches}变量中,表示即将发送或已发送但未收到 ACK 的消息批次。* 5. 处理已过期的消息批次,分为事务和非事务批次处理。对于非事务的处理方式较为简单:1.更新ProducerBatch状态 2.从「inFlightBatches」中移除 3.从RecordAccumulator移除* 6. 将将待发送的消息批次写入{@link KafkaChannel#send}变量中,等待写入底层的 {@link java.nio.channels.SocketChannel}** @param now 当前时间* @return*/private long sendProducerData(long now) {// #1 获取集群元数据Cluster cluster = metadata.fetch();// #2 过滤得到可发送数据的节点列表、未知分区Leader的主题列表RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);// #3 如果存在分区Leader未知的主题列表,那么可能的原因是主题被删除了或该分区正在发生副本Leader选举,会出现无Leader的真空期。// 此时客户端需要做的事情就是向Broker请求该主题的元数据信息,并有这些主题的数据暂时不会发送给Brokerif (!result.unknownLeaderTopics.isEmpty()) {for (String topic : result.unknownLeaderTopics)this.metadata.add(topic, now);// 更新刚才添加的主题的元数据信息this.metadata.requestUpdate();}// #4 遍历已就绪节点集合,再次判断节点是否可以发送数据Iterator<Node> iter = result.readyNodes.iterator();long notReadyTimeout = Long.MAX_VALUE;while (iter.hasNext()) {Node node = iter.next();// #4-1 判断节点是否准备好发送数据(Socket连接状态、是否被限流等全局因素考虑)if (!this.client.ready(node, now)) {// 节点没有准备好,则从当前列表中移除,数据留待下次连接就绪后再发送iter.remove();// 计算并更新下次Sender唤醒时间notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));}}// #5 从缓存队列中(RecordAccumulator)抽取数据,得到结果集:Map<Broker ID, 发送给该Broker的批次列表>Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);// #6 将批次添加到Sender线程的「inFlightBatches」中addToInflightBatches(batches);// #7 保证单个分区的顺序性,前提是「max.in.flight.requests.per.connection=1」,// 这会让发往该分区的请求看起来是阻塞式I/O操作:即发送请求1->接收请求1响应->发送请求2->接收请求2响应。// 虽然能保证单个分区的顺序性,但是会造成分区吞吐量严重下降。// 如果一定要确保单分区的顺序性,则可以使用幂等Producer实现if (guaranteeMessageOrder) {// #7-1 告诉RecordAccumulator,下次抽取消息批次时跳过这些分区,// 因为它们每次只能发送一个消息批次,必须等待收到ACK后才能发送下一个批次for (List<ProducerBatch> batchList : batches.values()) {for (ProducerBatch batch : batchList)// 静默该分区this.accumulator.mutePartition(batch.topicPartition);}}// #8 重置下一个消息批次过期时间accumulator.resetNextBatchExpiryTime();// #9 从飞行队列「inFlightBatches」中获取「过期」的消息批次列表List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);// #10 从消息缓冲区中获取「过期」的消息批次列表List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);// #11 汇总两个过期批次,统一处理expiredBatches.addAll(expiredInflightBatches);// #12 处理「过期」的消息批次,如果有事务,则进行事务相关的错误处理for (ProducerBatch expiredBatch : expiredBatches) {String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " +expiredBatch.topicPartition + ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";// #12-1 对于过期的消息批次,无事务处理:1.更新ProducerBatch状态 2.从「inFlightBatches」中移除 3.从RecordAccumulator移除failBatch(expiredBatch, -1, NO_TIMESTAMP, new TimeoutException(errorMessage), false);if (transactionManager != null && expiredBatch.inRetry()) {// #12-2 关于事务方面的处理transactionManager.markSequenceUnresolved(expiredBatch);}}sensors.updateProduceRequestMetrics(batches);// #12 计算发送超时时间。// ① 有可发送的批次,则置为0,这样可以立即循环并尝试发送更多数据。// ② 没有可发送的批次,超时时间将是「下一批到期时间」和「检查数据可用性的延迟时间」之间的最小值// ③ 节点可能由于 lingering、回退等原因,有尚未发送的数据。long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);pollTimeout = Math.max(pollTimeout, 0);if (!result.readyNodes.isEmpty()) {pollTimeout = 0;}// #13 将待发送的消息批次写入KafkaChannel#send变量中,等待发送sendProduceRequests(batches, now);// #4 返回执行poll(time)轮询的超时时间return pollTimeout;}
为了更好地理解相关 API 调用顺序,这里贴一幅图方便大家理解: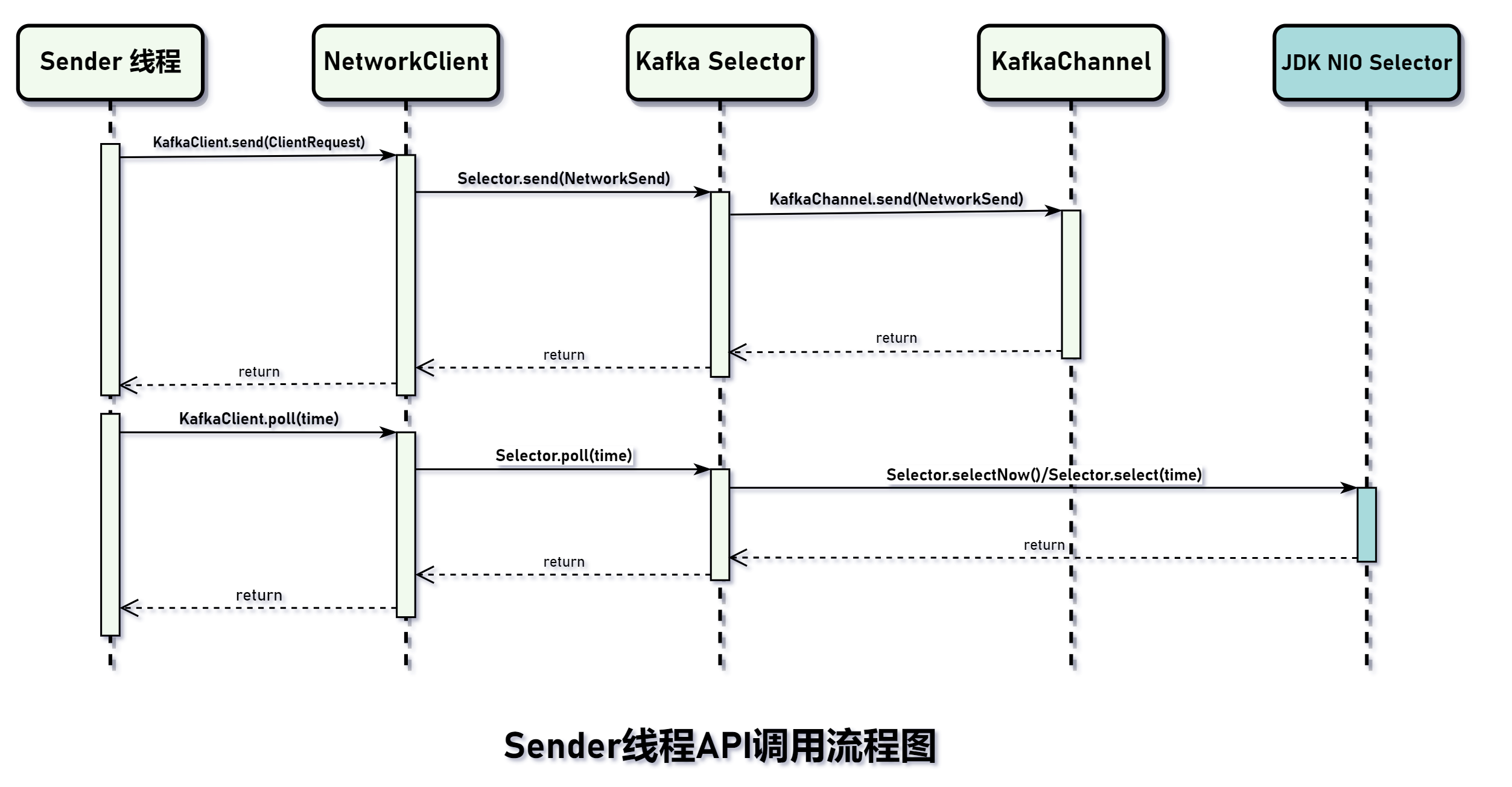
核心方法是步骤 #13,这个方法做以下操作:
- 为保证向下兼容,需要将消息转换为节点所能支持的最小版本号所对应的消息格式。
- 构建 ClientReqeust 对象,该对象包含目标的 Broker ID、收到 ACK 响应后执行的回调函数、请求头和请求体。
注意:由于本章节重点是讲述客户端网络组件之间的串联关系,对于其它重要的但非本章重点的内容只做一点概述。
// org.apache.kafka.clients.producer.internals.Sender#sendProduceRequest/*** 1.Magic版本处理。如果有不满足最小版本号的消息批次,为保证向下兼容,需要对每个消息进行转换。* 2.构建ProduceRequestData.TopicProduceDataCollection,存放分区消息批次* 3.构建ProduceRequest.Builder对象,包含ACKS、请求超时时间、事务ID、分区消息批次* 4.构建ClientRequest对象,节点ID、请求Builder对象、请求超时时间、响应成功后的回调函数* 5.将ClientRequest对象交给 {@link KafkaClient#send(ClientRequest, long)}实例** @param now 现在时间戳* @param destination 目标节点ID* @param acks acks配置,详见 {@link org.apache.kafka.clients.producer.ProducerConfig#ACKS_CONFIG},-1=all* @param timeout 响应超时时间,详见 {@link org.apache.kafka.clients.CommonClientConfigs#REQUEST_TIMEOUT_MS_CONFIG}* @param batches 消息批次集合,集合内的批次都发往同一个节点Node*/private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {if (batches.isEmpty())return;// 分区对应批次。在同一个节点中,每个分区只会对应一个批次final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());// #1 找到消息的最小版本号byte minUsedMagic = apiVersions.maxUsableProduceMagic();for (ProducerBatch batch : batches) {if (batch.magic() < minUsedMagic)minUsedMagic = batch.magic();}// 记录节点对应的所有分区数据ProduceRequestData.TopicProduceDataCollection tpd = new ProduceRequestData.TopicProduceDataCollection();// #2 遍历批次,如果版本号不匹配,为了保证向下兼容会对每条消息进行转换。for (ProducerBatch batch : batches) {TopicPartition tp = batch.topicPartition;// #2-1 获取记录MemoryRecords records = batch.records();// #2-2 为保证消息格式向下兼容,需要将所有的消息记录转化为最低版本号// 如果有必要,可以向下转换到使用的最小魔法值。// 一般来说,在生产者构建批处理和Sender线程发送请求之间可能会有延迟,所以我们可能根据已过时的元数据来选择消息格式。// 在最坏的情况下,由于我们乐观地选择使用新的消息格式,但发现Broker并不支持,所以我们需要在发送前在客户端进行向下转换。// 这是为了处理围绕集群升级的边缘情况,因为在这种情况下,并非所有Broker都支持相同的消息格式版本,肯定会有出入的。// 例如,如果一个分区从一个支持新的Magic版本的Broker迁移到一个不支持新的Magic版本的Broker,那么我们就需要对消息进行转换。if (!records.hasMatchingMagic(minUsedMagic))records = batch.records().downConvert(minUsedMagic, 0, time).records();// #2-3 根据主题名称从「tpd」对象中获取消息数据ProduceRequestData.TopicProduceData tpData = tpd.find(tp.topic());if (tpData == null) {// #2-4 如果没有则创建新的对象tpData = new ProduceRequestData.TopicProduceData().setName(tp.topic());// #2-5 将对象添加到tpdtpd.add(tpData);}// #2-6 将消息批次添加到tpData对象tpData.partitionData().add(new ProduceRequestData.PartitionProduceData().setIndex(tp.partition()).setRecords(records));recordsByPartition.put(tp, batch);}// #3 从事务管理器中获取事务IDString transactionalId = null;if (transactionManager != null && transactionManager.isTransactional()) {transactionalId = transactionManager.transactionalId();}// #4 创建一个请求体Builder(Builer设计模式),用于构建ProduceRequest对象ProduceRequest.Builder requestBuilder = ProduceRequest.forMagic(minUsedMagic,new ProduceRequestData().setAcks(acks) // ACKS配置.setTimeoutMs(timeout) // 请求超时时间.setTransactionalId(transactionalId) // 事务ID.setTopicData(tpd)); // 发往Broker的所有分区数据// #5 构建响应处理器,当成功收到ACK响应后,会回调这个函数RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());String nodeId = Integer.toString(destination);// #6 使用ClientRequest对象包装请求节点ID、Builder、响应回调函数、是否期望收到Broker的ACK响应等数据ClientRequest clientRequest =client.newClientRequest(nodeId, requestBuilder, now, acks != 0, requestTimeoutMs, callback);// #7 将ClientRequest对象交给KafkaClient处理client.send(clientRequest, now);}
上面的源码重点就是构建 ClientRequet 对象,这个对象包含一个请求的所有元数据信息和批次消息,当然,Kafka 为向下兼容也做了很多努力。步骤 #7 将已构建好的 ClientRequest 对象交给 KakfaClient 处理。
KafkaClient 顶层接口 统一抽象
接口 KfkaClient 定义了很多十分好用的 API,比如我想找到最小负载的节点,可以调用 leastLoadedNode(long now); 比如我要发送数据,可调用 send(ClientRequest, long); 手动执行 I/O 操作,可调用 poll(long, long) 等等。其中最重要的两个方法当属 send 和 poll。
// org.apache.kafka.clients.KafkaClient/*** 定义数据发送、数据接收、相关判断等接口。主要实现是 {@link NetworkClient}* ① 判断节点状态(是否已经准备就绪)* ② 判断连接等待时间。根据规则计算连接等待时间。* ③ 判断节点是否已经断开连接了。* ④ 将 {@link ClientRequest} 对象放入缓存* ⑤ 真正执行I/O操作,将缓存中的数据发往节点或读取节点返回的数据,并放入相应的对象中。** 这个是一个高级的API接口,定义了数据发送、触发I/O操作、判断等一系列方法。*/public interface KafkaClient extends Closeable {/*** 这个方法很重要,是客户端发送消息的入口。* 我们之前说过,Sender线程会按规则从 {@link org.apache.kafka.clients.producer.internals.RecordAccumulator}* 抽取数据,并按<node id, List<ProducerBatch>>形式组装数据,* 然后由 {@link org.apache.kafka.clients.producer.internals.Sender#sendProduceRequest(long, int, short, int, List)} 方法创建 {@link ClientRequest},* 最后调用这个API向SocketChannel写入数据(当然,这个写入不是由 {@link KafkaClient} 实现类完成,而是 {@link org.apache.kafka.common.network.TransportLayer} 完成) 。** 这个方法主要目的是将待发送的 {@param request} 封装为 {@link org.apache.kafka.common.network.Send} 对象,* 然后再把该对象写入 {@link org.apache.kafka.common.network.KafkaChannel#send} 中。** @param request 待发送请求对象* @param now 当前时间戳*/void send(ClientRequest request, long now);/*** {@link #send(ClientRequest, long)} 方法将数据已经放入指定位置({@link org.apache.kafka.common.network.KafkaChannel#send}),* 这个方法本质就是调用JDK底层的 {@link java.nio.channels.SocketChannel#write(ByteBuffer)}将 {@link KafkaChannel#send}的数据写入通道中。* 当然,这个方法并非只做这么一件事情,还要接收从节点返回过来的Response消息,在收到响应后做收尾工作,比如触发相关回调函数。** @param timeout 超时时间* @param now 当前时间戳* @return*/List<ClientResponse> poll(long timeout, long now);// ...}
NetworkClient 是 KafkaClient 唯一实现类,熟悉一下内部变量:
/*** 定义数据发送、数据接收、相关判断等接口。*/public class NetworkClient implements KafkaClient {// 用于执行底层网络I/O请求/响应// 这个对象是Kafka的轮询器,用于private final Selectable selector;// 元数据更新类private final MetadataUpdater metadataUpdater;// 集群节点连接状态private final ClusterConnectionStates connectionStates;// 按节点ID分类,缓存「in-flight」的请求private final InFlightRequests inFlightRequests;// 配置 SO_SNDBUF(发送缓冲区大小),默认值:131072private final int socketSendBuffer;// 配置 SO_RCVBUF (接收缓冲区),默认值:32768private final int socketReceiveBuffer;// 每个响应超时时间,默认值:30000private final int defaultRequestTimeoutMs;// Socket重连退避时间,默认值:50private final long reconnectBackoffMs;/*** 是否需要和 broker 商进行版本协调。默认值:true* 由于Kafka大版本之间存在不同协议。因此,需要在发送数据之前进行版本协调,* 否则出现错误或broker端不接收发送端发送的数据。* 在发送数据前会发送一个 {@link ApiVersionsRequest} 类型的请求*/private final boolean discoverBrokerVersions;// API版本号private final ApiVersions apiVersions;/*** 记录需要进行版本协调的节点。* 当和节点完成TCP/SSL连接后,下一步就是和节点协调版本。*/private final Map<String, ApiVersionsRequest.Builder> nodesNeedingApiVersionsFetch = new HashMap<>();/*** 存储中止发送的请求*/private final List<ClientResponse> abortedSends = new LinkedList<>();// ...}
个人觉得重要的变量是 selector、inFlightRequest、connectionStates。
inFlightReqeust
这是说说 inFlightRequest,飞行集合我们在 Sender 见过,它是存储分区对应的消息批次,而在 NetworkClient 的这个是存储节点对应的请求体,源码如下图所示:
// org.apache.kafka.clients.InFlightRequestsfinal class InFlightRequests {/** 默认值:5 */private final int maxInFlightRequestsPerConnection;private final Map<String, Deque<NetworkClient.InFlightRequest>> requests = new HashMap<>();// others}
这个队列存在的意义有以下几点:
- 根据
Deque数量判断节点负载情况。数量越小,说明节点负载越小。 - 限流。如果
Deque数量超出maxInFlightRequestsPerConnection,那么就不允许向该发送数据。Sender 线程在抽取数据时会通过这个队列判断是否可以抽取该节点的消息。 - 处理超时请求。如果
Deque存在超时的请求,那么 kafka 会主动关闭该节点的 Socket 连接,并处理相关请求。 保证响应是有序接收的。当收到来自 Broker 端的 ACK 响应,这个响应就对应
Deque#peekFirst()的请求。doSend
// org.apache.kafka.clients.NetworkClient#doSend(org.apache.kafka.clients.ClientRequest, boolean, long, org.apache.kafka.common.requests.AbstractRequest)/*** 1.根据版本号生成请求头* 2.根据请求头和请求体构建 {@link Send} 子类* 3.生成 {@link InFlightRequest} 请求并放入 {@link #inFlightRequests} 队列中* 4.委托 {@link org.apache.kafka.common.network.Selector} 发送请求** @param clientRequest 待发送的请求* @param isInternalRequest 是否属于内部请求* @param now 当前时间戳* @param request 请求体*/private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {String destination = clientRequest.destination();// #1 生成请求头RequestHeader header = clientRequest.makeHeader(request.version());// #2 根据请求头构建Send对象Send send = request.toSend(header);// #3 生成 InFlightRequest 并放入「in-flight」队列中// NetworkClient对象中也有「in-flight」的设计,可以通过这个对象判断Client与Broker的连接是否拥堵InFlightRequest inFlightRequest = new InFlightRequest(clientRequest,header,isInternalRequest,request,send,now);this.inFlightRequests.add(inFlightRequest);// #4 委托Selector发送数据,入参是目标的Broker ID和待发送的数据selector.send(new NetworkSend(clientRequest.destination(), send));}
方法
doSend()将请求体加入InFlightRequest对象中,然后构建NetworkSend对象交给Selector发送。kafka Selectable
Kafka 使用 Selectable 来管理多个 KafkaChannel,核心功能是监控 KafkaChannel 数据读/写状态。当然,还有数据写入、执行 I/O 操作等方法。
// org.apache.kafka.common.network.Selectable/*** 该接口定义一个异步、多通道网络I/O接口。* 我们时刻记住,Kafka的网络模型(无论客户端还是服务端)都是基于JDK NIO 异步非阻塞模型,所以它需要不断轮询并处理相关I/O。* 对于 {@link Selectable} 而言,相关 API 调用顺序是* // 1.建立TCP连接 {@link #connect(String, InetSocketAddress, int, int)}* // 在一个while(true)轮询并处理I/O数据* while(true) {* // 2.发送数据* send();* // 3.执行I/O* poll();* // 4.回调已完成发送的请求的回调函数* completedSends();* // 5.回调已成功接收的响应的回调函数* completedReceives()* }*** 这个网络接口很有特点:* ① 一个 {@link Selectable} 实例对象掌管多个 {@link KafkaChannel} 连接通道,即一个对象掌管多个 TCP 连接。详见 {@link Selector} 实现类。* 因此,由于它们之间的操作是独立的,因此管控相对较容易。* ② {@link NetworkSend} 对象包含消息所发往的节点ID,方法 {@link #send(NetworkSend)} 根据节点ID从缓存中选择合适的 {@link KafkaChannel} 并写入缓存,* 此时数据并未没有写入底层的 {@link java.nio.channels.SocketChannel}。* ③ 方法 {@link #poll(long)} 才会触发底层I/O操作的核心方法,它会触发真正的I/O操作。*/public interface Selectable {/*** See {@link #connect(String, InetSocketAddress, int, int) connect()}*/int USE_DEFAULT_BUFFER_SIZE = -1;/*** 和目标节点建立Socket连接** @param id 待连接的目标节点的Broker ID* @param address 待连接IP地址* @param sendBufferSize TCP发送缓冲区大小* @param receiveBufferSize TCP接收缓冲区大小* @throws IOException*/void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException;/*** 调用 {@link java.nio.channels.Selector#wakeup()} 方法*/void wakeup();/*** 关闭Kafka轮询器,并关闭该轮询器绑定的所有Socket连接*/void close();/*** 关闭指定Socket连接** @param id 待关闭的节点ID*/void close(String id);/*** 将待发送的请求体对象放到对应的 {@link KafkaChannel#send} 变量中。* 此时还不会将数据写入底层的 SocketChannel,当调用 {@link #poll(long)} 后才会真正执行I/O操作。** @param send 包装待发送的请求体*/void send(NetworkSend send);/*** 执行底层的I/O操作* 将{@link KafkaChannel#send}变量的数据写入SocketChannel。* 或从SocketChannel读取数据并写入{@link KafkaChannel#receive}变量** @param timeout 超时时间* @throws IOException*/void poll(long timeout) throws IOException;/*** 获取当前Selector管理的所有KafkaChannel完成发送的 {@link KafkaChannel#send}变量值,返回一个List集合。* 这是由上次调用 {@link #poll(long)} 所生成。* 我们需要明确:{@link Selectable} 实例管理多个{@link KafkaChannel},也就是说,* 底层的 {@link KafkaChannel} 数据的接收和发送都是由Selectable实现类统一调度的。* 那Selectable是如何知道哪些通道事件已就绪了?答案就是Selectable持有{@link java.nio.channels.Selector},* 它所管理的通道会将相关事件注册到该Selector对象中,这样,Selectable就拥有感知通道的I/O事件。** @return*/List<NetworkSend> completedSends();/*** "收割"已完成数据接收的 {@link KafkaChannel#receive} 变量,* 这是由上次调用 {@link #poll(long)} 所生成。* @return*/Collection<NetworkReceive> completedReceives();/*** 返回在最近一次 {@link #poll(long)} 方法产生的连接已断开的数据集合* @return*/Map<String, ChannelState> disconnected();/*** 返回在最近一次 {@link #poll(long)} 方法产生的连接已完成的节点ID集合* @return*/List<String> connected();// others}
Selector是 Selectable 唯一实现类,看看它有哪些重要的变量:// org.apache.kafka.common.network.Selectorpublic class Selector implements Selectable, AutoCloseable {public static final long NO_IDLE_TIMEOUT_MS = -1;public static final int NO_FAILED_AUTHENTICATION_DELAY = 0;/*** 关闭模式枚举类*/private enum CloseMode {/*** 优雅关闭:处理剩余收到的缓冲区中的数据,并通知连接已关闭*/GRACEFUL(true),/*** 仅通知:丢弃缓冲区内的所有数据,仅通知连接已关闭*/NOTIFY_ONLY(true),/*** 直接关闭:丢弃缓冲区内的所有数据,不做任何通知*/DISCARD_NO_NOTIFY(false);boolean notifyDisconnect;CloseMode(boolean notifyDisconnect) {this.notifyDisconnect = notifyDisconnect;}}private final Logger log;// JDK 底层的轮询器。一个轮询器可以轮询多个 {@link SocketChannel} 通道private final java.nio.channels.Selector nioSelector;// 缓存Kafka Selector所管理的 {@link KafkaChannel}private final Map<String, KafkaChannel> channels;// 显示对KafkaChannel静默private final Set<KafkaChannel> explicitlyMutedChannels;// 表示缓存不够了private boolean outOfMemory;// 保存成功写入底层 SocketChannel 的对象请求体(由 {@link NetworkSend} 对象封装)private final List<NetworkSend> completedSends;// 保存从SocketChannel读取的完整的数据private final LinkedHashMap<String, NetworkReceive> completedReceives;private final Set<SelectionKey> immediatelyConnectedKeys;// 正在关闭的KafkaChannel。为了优雅关闭private final Map<String, KafkaChannel> closingChannels;/*** SocketChannel的内核Buffer还有未读取的数据,* 待下次调用 {@link #poll(long)} 时优先从这些通道中读取*/private Set<SelectionKey> keysWithBufferedRead;/*** 一次「poll()」方法调用过程中发现的已断开的Socket连接*/private final Map<String, ChannelState> disconnected;/*** 一次「poll()」方法调用过程中新建立的连接*/private final List<String> connected;/*** 一次「poll()」过程中向哪些「Node」节点发送失败*/private final List<String> failedSends;// 时间工具private final Time time;private final SelectorMetrics sensors;/*** 创建 {@link KafkaChannel} 的构造器(Builder),* 根据配置创建 {@link TransportLayer} 接口所对应的实现类。* 如果有安全要求,配置了SSL等安全协议,则会生成 {@link SslTransportLayer},* 如果没有安全要求,则会生成 {@link PlaintextTransportLayer}*/private final ChannelBuilder channelBuilder;/*** 内存对象池,分配 ByteBuffer 对象*/private final MemoryPool memoryPool;private final IdleExpiryManager idleExpiryManager;// 默认值:-1private final int maxReceiveSize;private final boolean recordTimePerConnection;private final LinkedHashMap<String, DelayedAuthenticationFailureClose> delayedClosingChannels;private final long lowMemThreshold;private final int failedAuthenticationDelayMs;/*** 指示上次调用{@link #poll(long)}后在读取数据方面是否取得进展。* 这个参数被用来避免当内存容量不足以读取更多的数据时出现小循环。** 默认是true,表示上次{@link #poll(long)} 在读数据方面取得进展,否则为false*/private boolean madeReadProgressLastPoll = true;// other}
下面的列表是比较重要的变量:
| 变量 | 作用 |
|---|---|
| java.nio.channels.Selector nioSelector | JDK 底层轮询器,轮询 Client 所有 SocketChannel 的感兴趣事件 |
| Map |
Client 所有 KafakChannel,key为 通道所连接的 Broker ID,因此,我们就可以通过 Broker ID 获取相应的 KafkaChannel |
| NetworkSend | NetworkSend 是对 ClientRequest 的二进制数据数据的表示形式,它是关注二进制数据,直接可以和 SocketChannel 打交道,内部有变量记录数据大小、已写入字节数、剩余字节数等元数据。 |
| List |
保存将数据全部写入 SocketChannel 的 NetworkSend 对象。遍历 channels 列表,收集 NetworkSend 剩余字节数为 0 的对象即可。因为 NetworkSend 对象保存 destinationId,所以只有 List 存储即可 |
| LinkedHashMap |
保存从 SocketChannel 接收完整的 NetworkReceive 对象。NetworkReceive 是处理 TCP “粘包”的关键类。 |
| Set |
SocketChannel 的内核 Buffer 还有未读取的数据,需要将它记录下来,下次poll()操作时优先从这些通道中读取数据 |
| ChannelBuilder channelBuilder | 根据配置文件构建 TransportLayer 特定的实现类。 如果启用 SSL,则会生成 SslTransportLayer,否则生成 PlaintextTransportLayer |
| MemoryPool memoryPool | ByteBuffer 对象池 |
| IdleExpiryManager idleExpiryManager | 根据 LRU 算法关闭空闲的 Socket 连接,减少资源浪费 |
再看核心方法 send(NetworkSend)
// org.apache.kafka.common.network.Selector#send/*** 1.从缓存中获取{@link KafkaChannel}* 2.将 {@link NetworkSend}对象写入 {@link KafkaChannel#send}变量中** @param send 包装待发送的请求体*/public void send(NetworkSend send) {// #1 获取目标节点Broker IDString connectionId = send.destinationId();// #2 根据Broker ID从缓存中获取KafkaChannelKafkaChannel channel = openOrClosingChannelOrFail(connectionId);if (closingChannels.containsKey(connectionId)) {this.failedSends.add(connectionId);} else {try {// #3 将NetworkSend写入KafkaChannel#send变量中channel.setSend(send);} catch (Exception e) {// #4 无论出现什么异常,都需要关闭KafkChannel,并设置相关状态channel.state(ChannelState.FAILED_SEND);this.failedSends.add(connectionId);close(channel, CloseMode.DISCARD_NO_NOTIFY);if (!(e instanceof CancelledKeyException)) {log.error("Unexpected exception during send, closing connection {} and rethrowing exception {}", connectionId, e);throw e;}}}}
- 根据 Broker ID 从变量
channels或closingChannels获取 kafakChannel 对象。 - 如果
closingChannels包含该 Broker ID,说明该通道正要关闭,不允许发送数据。 - 对于正常的通道则将待发送的对象写入
KafkaChannel#send变量中。
怎么样,其实核心步骤就是将对象 NetworkSend 写入 KafkaChannel#send 变量中。
到这里,待发送的数据准备到位了,接下来我们就可以执行网络 I/O 操作。
I/O 操作
NetworkClient#poll
Sender 线程调用 KafkaClient#poll() 方法,就表示执行网络 I/O 操作。我们看看 NetworkClient#poll() 源码是如何实现的:
// org.apache.kafka.clients.NetworkClient#poll/*** 对底层的 Socket 进行读/写操作** @param timeout 超时时间。实际值可能是 timeout、reqeust timeout 和 metdata timeout 的最小值* @param now 当前时间* @return 接收到的响应集合*/@Overridepublic List<ClientResponse> poll(long timeout, long now) {// 确保NetworkClient状态处于「ACTIVE」ensureActive();// #1 处于由于不支持的版本号而出现异常或连接断开的请求if (!abortedSends.isEmpty()) {List<ClientResponse> responses = new ArrayList<>();// #1-1 将响应添加到response集合中,并清除「abortedSends」handleAbortedSends(responses);// #1-2 执行回调函数completeResponses(responses);// #1-3 返回return responses;}// #2 如果需要,则进行「元数据更新」操作。maybeUpdate(now)只是组装请求体,并不执行I/O操作,并返回超时时间// 向负载最小的节点发送「MetadataRequest」请求long metadataTimeout = metadataUpdater.maybeUpdate(now);try {// #2-1 执行网络I/O操作this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));} catch (IOException e) {log.error("Unexpected error during I/O", e);}// process completed actionslong updatedNow = this.time.milliseconds();List<ClientResponse> responses = new ArrayList<>();// #3 处理已完成数据发送的KafkaChannel。这是"收割"上一次调用poll()函数成功发送的请求handleCompletedSends(responses, updatedNow);// #4 处理成功收到Broker的ACK响应handleCompletedReceives(responses, updatedNow);// #5 处理已断开的Socket连接handleDisconnections(responses, updatedNow);// #6 处理新创建的Socket连接handleConnections();// #7 如果某个Socket连接刚创建,那么首先就要发送一个「APIVersion」请求handleInitiateApiVersionRequests(updatedNow);// #8 处理超时的Socket连接handleTimedOutConnections(responses, updatedNow);// #9 处理超时的请求handleTimedOutRequests(responses, updatedNow);// #10 执行回调函数completeResponses(responses);// #11 返回return responses;}
逻辑十分清晰明了,画个图看看:
#
最核心的方法是 selector.poll(time),源码如下:
// org.apache.kafka.common.network.Selector#poll/*** △ 基于Java的NIO网络编程模型,* 处理 {@link SocketChannel} 的OP_CONNECT、OP_WRITE、OP_READ等I/O事件。** @param timeout 需要等待的超时时间* @throws IllegalArgumentException* @throws IllegalStateException*/@Overridepublic void poll(long timeout) throws IOException {if (timeout < 0) throw new IllegalArgumentException("timeout should be >= 0");boolean madeReadProgressLastCall = madeReadProgressLastPoll;// #1 清除所有与上次「poll()」调用的全部缓存数据clear();// #2 判断Socket Buffer中是否还有数据boolean dataInBuffers = !keysWithBufferedRead.isEmpty();// #3 设置超时时间if (!immediatelyConnectedKeys.isEmpty() || (madeReadProgressLastCall && dataInBuffers))timeout = 0;// #4 判断缓存压力是否仍然存在if (!memoryPool.isOutOfMemory() && outOfMemory) {// #4-1 走到这里,就说明之前迫于缓存压力而无法发送数据的情况已经过去了(缓解)// 现在可以发送数据了。遍历当前Selector管理的所有KafkaChannel,并将它们取消静默for (KafkaChannel channel : channels.values()) {if (channel.isInMutableState() && !explicitlyMutedChannels.contains(channel)) {channel.maybeUnmute();}}// #4-2 更新状态outOfMemory = false;}long startSelect = time.nanoseconds();// #5 调用JDK的Selector#selectNow()/select(time)获取已就绪事件数量// 记住,在NIO编程中,只有注册相关事件才会得到SelectionKeyint numReadyKeys = select(timeout);long endSelect = time.nanoseconds();this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());// #6 处理I/O事件,只要一个条件成立就会执行:// 1.I/O事件数量>0 2.存在可瞬时连接的Socket连接 3.Socket Buffer仍存在数据暂未被读取if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {// #6-1 获取就绪事件集合Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys();// #6-2 从Socket Buffer仍存在数据的通道中抽取数据。这种情况是因为数据到了内核的Buffer中,但是Kafka没有足够的内存接收,// 所以这批数据一直存在内核的Buffer,等待下次轮询时读取if (dataInBuffers) {// 1.将「keysWithBufferedRead」集合一分为二,// 剔除本轮「readyKeys」,然后对剩余的「SelectionKey」进行相应的I/O处理keysWithBufferedRead.removeAll(readyKeys);Set<SelectionKey> toPoll = keysWithBufferedRead;keysWithBufferedRead = new HashSet<>();// 2.I/O处理pollSelectionKeys(toPoll, false, endSelect);}// #7 内核Buffer已经存在数据或底层SocketChannel已准备发送数据,那么对SocketChannel进行读/写操作pollSelectionKeys(readyKeys, false, endSelect);// #8 别忘记清除这些SelectionKey,否则会出大问题readyKeys.clear();// #9 瞬时建立的连接单独处理pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);// #10 清除瞬时建立的连接集合immediatelyConnectedKeys.clear();} else {// #11 本次poll()在读数据操作中没有取得进展madeReadProgressLastPoll = true;}long endIo = time.nanoseconds();this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());// #12 关闭延迟的通道completeDelayedChannelClose(endIo);// #13 根据LRU算法策略关闭最旧的Socket连接maybeCloseOldestConnection(endSelect);}
- 步骤
#5就是调用 Java 的Selector#select()方法从内核中获取就绪的事件数量。 - 可能由于 ByteBuffer 对象池容量不够而导致没有空间容纳内核已经接收到的数据,Kafka 使用
keysWithBufferedRead记录这个SelectionKey,随后会优先从这些 SocketChannel 获取数据(步骤#6-2)。 - 步骤
#7的方法是 Selector 的核心方法,它会根据已就绪的 I/O 事件对 SocketChannel 建立Socket连接/读/写等操作。这是 Kafka 网络编程核心方法。 - 其余步骤与网络编程关联较小,所以就不在这里进行说明。
处理 I/O 事件 pollSelectionKeys
客户端的 SocketChannel 感兴趣的 I/O 事件共有三类,分别是
- OP_CONNECT:客户端主题和 Broker 建立连接。
- OP_READ:SocketChannel 可读。
- OP_WRITE:SocketChannel 可写。
相关源码如下:
// org.apache.kafka.common.network.Selector#pollSelectionKeys/*** {@link Selector} 核心方法,用于I/O操作* Selector对每个 {@link SocketChannel} 通道雨露均沾** @param selectionKeys 待处理的 {@link SelectionKey} 集合,可以从该对象中获取底层的 {@link SocketChannel}* @param isImmediatelyConnected 是否处理瞬时连上的Socket连接* @param currentTimeNanos 当前时间戳*/void pollSelectionKeys(Set<SelectionKey> selectionKeys, boolean isImmediatelyConnected, long currentTimeNanos) {// #1 determineHandlingOrder方法打乱集合,避免相关通道处于饥饿for (SelectionKey key : determineHandlingOrder(selectionKeys)) {// #2 获取KafkaChannel,与底层的java.nio.channels.SocketChannel一一对应,代表一个TCP连接KafkaChannel channel = channel(key);long channelStartTimeNanos = recordTimePerConnection ? time.nanoseconds() : 0;boolean sendFailed = false;String nodeId = channel.id();sensors.maybeRegisterConnectionMetrics(nodeId);// #3 更新空闲连接时间if (idleExpiryManager != null)idleExpiryManager.update(nodeId, currentTimeNanos);try {// #4 处理瞬时连上或OP_CONNECT事件的Socket连接if (isImmediatelyConnected || key.isConnectable()) {if (channel.finishConnect()) {// #4-1 底层TCP连接已建立,Selector对象记录已建连的节点IDthis.connected.add(nodeId);this.sensors.connectionCreated.record();} else {// #4-2 连接未就绪,跳过continue;}}// #5 底层TCP通道已连接(isConnected()返回true)但是还未完成身份认证(ready()返回false)// Kafka提供多种安全认证机制,主要分为SSL和SASL2两大类。其中SASL是基于账号密码的认证方式if (channel.isConnected() && !channel.ready()) {// #5-1 ①完成TCP或TCP+SSL握手; ② 完成身份认证channel.prepare();// #5-2 再次判断通道是否已准备就绪(通道就绪包含两个条件:①底层TCP/TCP+SSL已建立连接;②通道Kakfa身份认证)if (channel.ready()) {long readyTimeMs = time.milliseconds();boolean isReauthentication = channel.successfulAuthentications() > 1;// 记录认证延迟if (isReauthentication) {// 超过一次认证成功sensors.successfulReauthentication.record(1.0, readyTimeMs);if (channel.reauthenticationLatencyMs() == null)log.warn("Should never happen: re-authentication latency for a re-authenticated channel was null; continuing...");elsesensors.reauthenticationLatency.record(channel.reauthenticationLatencyMs().doubleValue(), readyTimeMs);} else {sensors.successfulAuthentication.record(1.0, readyTimeMs);if (!channel.connectedClientSupportsReauthentication()) sensors.successfulAuthenticationNoReauth.record(1.0, readyTimeMs);}log.debug("Successfully {} authenticated with {}", isReauthentication ? "re-" : "", channel.socketDescription());}}// #6 更新KafkaChannel通道状态if (channel.ready() && channel.state() == ChannelState.NOT_CONNECTED)channel.state(ChannelState.READY);// 身份认证相关处理Optional<NetworkReceive> responseReceivedDuringReauthentication = channel.pollResponseReceivedDuringReauthentication();responseReceivedDuringReauthentication.ifPresent(receive -> {long currentTimeMs = time.milliseconds();addToCompletedReceives(channel, receive, currentTimeMs);});// #7 尝试从通道中读取数据if (channel.ready()&& (key.isReadable() || channel.hasBytesBuffered())&& !hasCompletedReceive(channel)&& !explicitlyMutedChannels.contains(channel)) {attemptRead(channel);}// #8 对于SslTransportLayer而言有用,而PlainTransportLayer则固定返回falseif (channel.hasBytesBuffered()) {// 这个通道有字节排在我们无法读取的中间缓冲区中(可能是因为没有内存)。// 可能的情况是底层套接字不会在下一次 poll() 中出现,因此我们需要记住该通道以进行下一次轮询调用,否则数据可能永远停留在所述缓冲区中。// 如果我们尝试处理缓冲数据并且没有任何进展,则会清除通道缓冲状态以避免每次检查的开销。keysWithBufferedRead.add(key);}// #9 尝试向SocketChannel中写入数据long nowNanos = channelStartTimeNanos != 0 ? channelStartTimeNanos : currentTimeNanos;try {attemptWrite(key, channel, nowNanos);} catch (Exception e) {sendFailed = true;throw e;}// #10 如果SocketChannel为非法,则主动关闭,避免资源泄漏if (!key.isValid())close(channel, CloseMode.GRACEFUL);} catch (Exception e) {String desc = channel.socketDescription();if (e instanceof IOException) {log.debug("Connection with {} disconnected", desc, e);} else if (e instanceof AuthenticationException) {boolean isReauthentication = channel.successfulAuthentications() > 0;if (isReauthentication)sensors.failedReauthentication.record();elsesensors.failedAuthentication.record();String exceptionMessage = e.getMessage();if (e instanceof DelayedResponseAuthenticationException)exceptionMessage = e.getCause().getMessage();log.info("Failed {}authentication with {} ({})", isReauthentication ? "re-" : "",desc, exceptionMessage);} else {log.warn("Unexpected error from {}; closing connection", desc, e);}if (e instanceof DelayedResponseAuthenticationException)maybeDelayCloseOnAuthenticationFailure(channel);elseclose(channel, sendFailed ? CloseMode.NOTIFY_ONLY : CloseMode.GRACEFUL);} finally {maybeRecordTimePerConnection(channel, channelStartTimeNanos);}}}
画了这个函数执行流程图: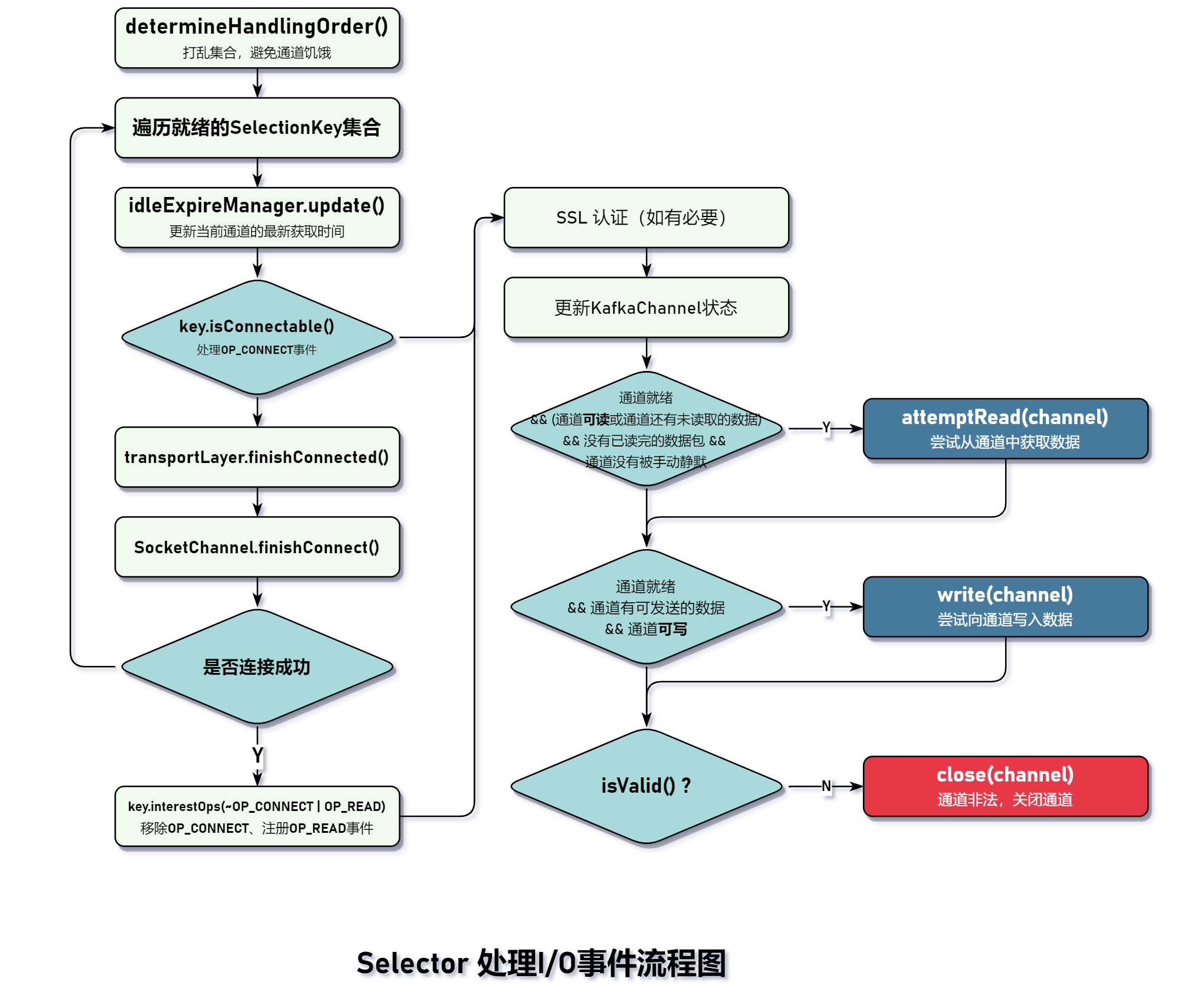
- 首先处理
OP_CONNECT事件,由于是非阻塞的 SocketChannel,因此,调用SocketChannel#connect()方法后会立即返回,运气好可能会秒连接,而 Kafak 针对秒连也做了相应处理(使用 immediatelyConnectedKeys 变量存储秒连接的 SelectionKey),一连来说,连接建立是需要一定时间,因此,通常#connect()方法会返回 false。需要等待下一轮调用SocketChannel#finishConnect()判断是否连接成功。如果连接成功,则返回 true,否则,继续在下一轮接着判断,直到抛出 IOException 异常或成功连接。当通道成功连接后,马上要做的事情就是移除OP_CONNETC事件和添加OP_READ事件。 - 紧接着更新 KafkaChannel 的状态,将状态变更为
READY,意味着通道可以接收和发送数据了。 - 其它就和正常的 NIO 编程一样,处理
OP_READ和OP_WRITE等 I/O 事件。
从源码中我们没有看到 Kafka 网络框架对 Epoll BUG 的修复,他们认为这是 JDK 的锅。
接收数据如何处理粘包问题?
Netty 解决粘包有四种方式:
- Fixed Length。定长的内容。这种解析很快,但协议不灵活。
- 特定分隔符。比如以
aaa结尾。 - 基于换行符
\n或\r\n对文件进行分割。 - 基于特定的长度字段。这种方式告诉接收方内容长度,接收方收到该长度的数据就可认为是完整的数据了。
Kafka 是使用第四种方式,基于特定的长度字段,因为是自己实现的 RPC 协议,所以定义也特别简单:前 4 个字节表示后面内容的长度。
二进制数据的读取操作是在 NetworkReceive#readFrom(SocketChannel) 方法中:
// org.apache.kafka.common.network.NetworkReceive#readFrom/*** 从 {@link SocketChannel} 通道中读取数据** @param channel* @return* @throws IOException*/public long readFrom(ScatteringByteChannel channel) throws IOException {// 本轮读取字节数int read = 0;// 如果「size」还有空位,说明未读满4个字节,继续从if (size.hasRemaining()) {// 继续填满「size」ByteBufferint bytesRead = channel.read(size);if (bytesRead < 0)// 抛出异常throw new EOFException();// 记录读取字节数read += bytesRead;// 如果「size」还有空位,说明还没有填满,只能下次再读了// 如果「size」没有空位,说明内容长度已经确定,我们读取数据就有目标值,// 这就是解决TCP粘包的关键步骤了if (!size.hasRemaining()) {size.rewind();// 读取后的内容长度值int receiveSize = size.getInt();if (receiveSize < 0)throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + ")");// 校验长度,屏蔽恶意请求if (maxSize != UNLIMITED && receiveSize > maxSize)throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + " larger than " + maxSize + ")");// 内容长度可能为0requestedBufferSize = receiveSize;if (receiveSize == 0) {buffer = EMPTY_BUFFER;}}}// 已确定内容长度,但还未给内容分配ByteBuffer对象以接收数据if (buffer == null && requestedBufferSize != -1) {// 向对象池申请ByteBufferbuffer = memoryPool.tryAllocate(requestedBufferSize);// 申请失败,说明当前内存吃紧,只能跳过,等待下一轮poll()方法的调用if (buffer == null)log.trace("Broker low on memory - could not allocate buffer of size {} for source {}", requestedBufferSize, source);}// 成功申请到ByteBuffer对象if (buffer != null) {// 从SocketChannel读取数据以填充ByteBuffer对象int bytesRead = channel.read(buffer);if (bytesRead < 0)throw new EOFException();read += bytesRead;}// 记录此次成功读取的字节数return read;}
- 首先,判断重要的表示内容长度的 4 个字节是否读取成功。变量
size就是用来存储这 4 个字节。成功读取的特征是size.hasRemaining() = false。如果没有读完,则继续读。必须知道内容长度才能进行下一步操作。 - 已知内容长度,那么就可以根据长度值向
MemoryPool对象池申请 ByteBuffer 对象,申请操作是有约束的,如果内存不够,则返回 null,本次读取操作就会跳过,等待下一轮Selector#poll()调用才能继续尝试从 SocketChannel 读取数据。 - 成功申请到 ByteBuffer,就直接调用
SocketChannel#read(ByteBuffer)将数据填满 ByteBuffer 对象。
那怎么才算得到一个完整的响应呢? 是通过 complete() 方法完成的:
/*** 判断是否成功得到一个完整的响应体** @return*/@Overridepublic boolean complete() {return !size.hasRemaining() // 4个字节读完&& buffer != null // ByteBuffer对象不能为空,即便是0负载的也会有指向EMPTY_BUFFER&& !buffer.hasRemaining(); // 负载ByteBuffer没有空闲位置,因为ByteBuffer大小等于内容长度}
总结
写了两天,终于把 kafka 客户端网络组件写完了。有些细节并没有讲清楚,比如如何进行 SSL 握手。不过这不影响理解 Kafka 客户端网络组件。本章单纯地涉及到网络相关的知识,对于 Kafka Producer 业务相关的没有讲太多。希望大家能从这篇文章中对 Kafka 客户端网络组件有个更宏观的认识。

若有收获,就点个赞吧
0 人点赞
