
初始Kafka
Kafka 起初是由 Linkedin 公司采用 Scala 语言开发的一个多分区、多副本且基于 ZooKeeper 协调的分布式消息系统,现己被捐献给 Apache 基金会。目前 Kafka 已经定位为一个分布式流式 处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。它扮演三大角色:
- 消息系统。具备系统解稿、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。不提供消息顺序性保障及回溯消费的功能。
- 存储系统。Kafka 把消息持久化到磁盘,利用多副本机制可以把 kafka 作为长期的数据存储系统来使用。
-
体系结构
消息和批次
Kafka 的数据单元被称为消息,对 Kafka 而言没有特别之处,就是一串二进制数据。
-
主题(Topic)和分区(Partition)
主题是一个逻辑上的概念,它可以被分为多个分区,一个分区只属于单个主题。一般情况下会把分区称为主题分区(Topic-Partition)。同一主题下的不同分区包含的消息是不同的。所有分区加起来的消息才能成为一个主题的完整消息,即发往某个主题的消息会被分散到不同的分区中,这就是 Kafka 的水平扩展。
从数据存储层面看,可以被看作是一个可追加的日志文件(Log File),消息在被追加到分区日志文件时都会分配一个特定的偏移量(offset)。偏移量仅是消息在分区中的唯一标识。可以通过主题+分区 ID+偏移量确定 Kafka集群的某一条消息。 每一条消息被发送到 broker 之前,都会根据分区器选择存储在哪个具体的分区中。如果分区规则设定得合理,所有消息都可以均匀分配到不同的分区中。Kafak 将一个 Topic 拆成多个分区主题是解决机器 I/O 的瓶颈。可以增加分区实现水平扩展。但目前 Kafka 还不支持缩减分区数量。
- 用户指定 key:通过公式
murmur2(key)%numberOfPartition得到分区 ID。murmur2 是一种哈希算法。 - 用户未指定 key:默认通过黏性分区策略得到分区 ID。
- 用户指定 key:通过公式
- Kafka 引入多副本机制(Replica)实现高可用(CAP 中的 A)。通过增加副本数量可以提升容灾能力。但目前 Kafak 的多副本机制仅是为容灾设置,不会向外提供读功能。
注意:如果 key != null,那么计算得到的分区号是所有分区中的任意一个。如果 key == null,那么计算得到的分区号仅为可用分区中的任意一个。

副本与容灾
Kafka 引入多副本机制目的是解决灾备问题。
- 分区可以拥有多个副本,这在创建主题时指定。
- 副本之间是一主多从的关系,主副本被称为 Leader 副本,从副本被称为 Follower 副本。
- Leader 副本负责处理读/写请求,Follower 副本只负责同步 Leader 副本的消息。
当 Leader 副本由于其它原因导致不可用,Kafka 控制器会从 Follower 副本中重新选举新的 Leader 副本对外提供服务。Kafka 通过多副本机制实现了故障的自动转移,当 Kafka 集群中的某个 broker 节点失效后仍能对外提供服务。
AR、ISR、OSR
分区中的所有副本统称为 AR ( Assigned Replicas ) 。 所有与 leader 副本保持一定程度同步
的副本(包括 leader 副本在内)组成 ISR(In-Sync Replicas ) , ISR 集合是 AR 集合中的一个子
集。
消息会先发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步, 同步期间内 follower 副本相对于 leader 副本而言会有一定程度的滞后。 与 leader 副本同步滞后过多的副本(不包括 leader 副本)组成 OSR ( Out-of-Sync Replicas),由此可见, AR=ISR+OSR。 在正常情况下, 所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR, OSR 集合为空。
Leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态, 当 follower 副本落后
太多或失效时, leader 副本会把它从 ISR 集合中剔除。如果 OSR 集合中有 follower 副本追上了 leader 副本,那么 leader 副本会把它从 OSR 集合转移至 ISR 集合。
只有 ISR 集合中的副本才有资格被选举成为新的 leader。
水位
虽然读写操作都只经过 Leader 副本,但是消费者能读取哪条消息每个副本都有参与控制。Kafka 定义了 High Watermark, HW(高水位)概念,它表示一个特定的消息偏移量(offset)。消费者只能读取到这个 offset 之前的消息。
LEO:标识当前日志文件中下一条待写入消息的 offset(相当于日志分区中最后一条消息的 offset 值 + 1)。分区 ISR 集合中的每个副本都会维护自身的 LEO,而 ISR 集合中最小的 LEO 即为分区的 HW,消费者只能消费 HW 之前的消息。
简单总结:
- 只有当 Leader 的消息完全成功同步到其他副本时,该消息才可被消费者消费。
-
副本选举
Leader 副本不可用,Kafka 控制器会从 Follower 副本中重新选举新的 Leader 副本,这个选举也很简单:我们把记录的数据看作年纪,和 Leader 同步数据量越多,年纪越大。那我们进行选举也变得简单起来,谁的年纪越大(消息同步越多),谁就自动当选 Leader。如果年纪相同,谁速度快(抢先获取领导权)谁就当选。
生产者和消费者
生产者创建消息,在默认情况下把消息均匀地分布到主题的所有分区上。它有以下几种策略:
如果消息没有指定目标分区且没有 key 值,则随机
而不关心特定消息会被写入到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。通常是通过消息键和分区器来实现的。分区器为键生成一个散列值,并将其映射到指定的分区上。这样可以保证同一个键会被写到同一个分区上。
生产者可以自定义分区器,根据不同的业务规则将消息映射到分区。
消费者使用拉(pull)模式读取消息。消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量来定位下一条即将读取的消息的位置。偏移量是一种元数据,它是一个不断递增的整数值。在创建消息时,Kafka会把它添加到消息里。
在给定的分区里,每个消息的偏移量都是唯一的。消息者把每个分区最后读取的消息偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
消费者属于消费者群组的一员,一个主题可以拥有多个消费者。群组保证每一个分区只能被一个消费者使用。消费者和分区之间的映射通常被称为消费者对分区的所有权利关系。
broker 和集群
一个独立的 Kafka 服务器被称为 Broker。broker 作用:
- 接收生产者消息。
- 为消息设置偏移量
- 提交消息到磁盘保存
- 为消费者提供服务,响应读取分区的请求
- 返回已经提交到磁盘上的消息
单个 broker 可以轻松处理数千个分区以及每秒百万级的消息量。
每个集群都有一个 broker 同时充当了集群控制器的角色,它是自动从集群活跃成员中选举出来。主要工作有:
- 将分区分配给 broker
- 监控 broker
分区复制会为消息提供冗余备份,如果一个 broker 失效,其他 broker 可以接管领导权。相关的消费者和生产者都要重新连接到新的首领。
消息保留策略
- 保留一段时间,比如 7 天。
- 所保留的消息达到一定大小的字节数,比如 1GB
当所保存的消息达到这些上限时,旧消息就会过期并被删除。
主题可以配置自己的保留策略,可以将消息保留到不再使用它们为止。
序列化
生产者需要用序列化器( Serializer)把对象转换成字节数组才能通过网络发送给 Kafka。
常见的序列化工具:
- Avro
- JSON
- Thrift
- ProtoBuf
- Protostuff
-
分区器
生产者发送消息:消息->拦截器(interceptor)->序列化器(Serializer)->分区器(Partitioner)。消息经过序列化之后就需要确定它发往的分区:
如果消息 ProducerRecord 对象指定了
partition字段,那么就不需要分区器。如果没有指定
partition字段,则需要分区器:根据 key 字段计算paration的值。默认实现是org.apache.kafka.clients.producer.internals.DefaultPartitioner。按照某个规则过滤不符合要求的消息
- 修改消息内容
还可以用来发送回调逻辑前做一些定制化的需求:
- 统计相关工作
主要实现类 org.apache.kafka.clients.producer.internals.ProducerInterceptors
/*** 将要以下同种情况被回调:* ① 在消息被应答(ACKnowledgement)之前* ② 消息发送失败* 注意:如果这个方法将会被生产者的I/O线程执行,* 所以越简单越好,这样不会影响整体的吞吐量*/public void onAcknowledgement(RecordMetadata metadata, Exception exception);
消费者拦截器
生产者
生产者示例
生产者源码解析
整体架构图
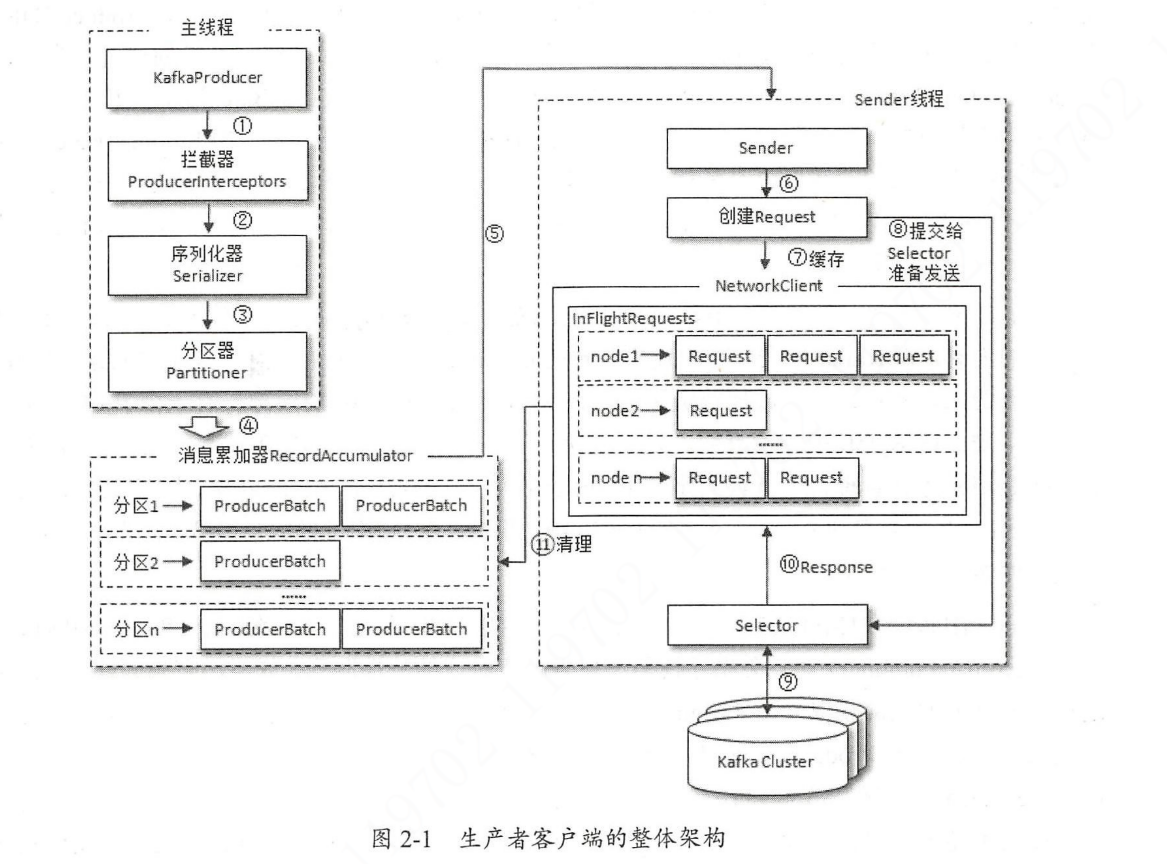
生产者架构相对比较简单,它只有两个线程分别是主线程负责产生消息,Sender 线程负责发送消息和元数据更新等相关操作。因此,会分为两部分讲解生产者源码。
主线程
由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化、分区器的作用之后将消息缓存到 RecordAccumulator 中。等待 Sender 线程抽取。因此,主线程的工作其他比较轻松。
RecordAccumulator 是 Kafka 生产者的核心类,它是消息发送阶段的第一步:RecordAccumulator 会将消息攒成一批批后才发送,进而减少网络传输的资源消耗从而提升性能。它在 RecordAccumulator 是以主题和分区号分类的。RecordAccumulator 缓存的大小可通过 buffer.memory 配置,默认值为 32MB。如果生产消息速度过快,导致缓冲区内存不够,此时 KafkaProducer#send() 方法会被阻塞,直到有缓存可用或超时(超时时间由 max.block.ms 配置,默认超时时间为 60S)。
主线程发送过来的消息都会被追加到一个合适的双端队列(Deque)中,RecordAccumulator 为每个分区(主题+分区号才能确定唯一分区)维护一个双端队列,存放 ProducerBatch,表示一批数据,新消息追加到队列的尾部。一个 ProducerBatch 可能包含多条消息,也可能只包含一条消息,这是由多种因素共同决定。当然,不能无限制向 ProducerBatch 添加消息,可以通过 batch.size 配置,默认大小为 16KB。
Sender 线程
Sender 线程负责从 RecordAccumulator 中抽取消息数据并将其发送到对应节点中:将 RecordAccumulator 以 <分区, Deque<ProducerBatch>> 形式保存的数据转换为 <Node, List<ProducerBatch>> 形式。因为对于底层网络而言,我们具体关心的是往哪一个节点发送数据,而节点包含多种分区。在第一次转换完成后,接下来还会根据相关协议转换为 <Node, Request> 形式。Request 就是 Kafka 制定的消息发送协议,这样就可以把 Request 发往到对应的节点。
从消息缓冲区中抽取可发送批次
如何保证单分区顺序性
方式一:max.in.flight.requests.per.connection=1
方式二:幂等生产者
元数据更新
leastLoadedNode,所有 Node 中负载最小的那一个。可应用于多种场合
- 元数据请求
- 消费者组播协议的交互
分区数量及 leader 副本的分布都会动态地变化, 客户端也需要动态地捕捉这些变化。
元数据是指 Kafka 集群的元数据,比如:
- 主题
- 主题的所有分区
- 分区的 leader 副本所在哪个节点上
- follower 副本所在哪个节点上
- AR、ISR 等集合包含哪些分区
- 集群节点
- 控制器节点
元数据更新逻辑:
- 客户端中没有需要使用的元数据信息时
- 超过
metadata.max.age.ms=5min时间没有更新元数据
重要的生产者参数
| 参数 | 说明 | 配置 |
|---|---|---|
| acks | 指定分区中必须要有多少个副本收到这条消息后生产者才认为写入成功 | - acks=1(default):只要分区 leader 写入就算成功。 - acks=0:不需要等待任务服务端响应。 - acks=-1:等待 ISR 集合中所有分区副本都成功写入后才算成功 |
| max.request.size | 限制生产者能发送消息的最大值 | - 1MB(default) - 不建议盲目增大,可能会引起其他并发异常 |
| retries/retry.backoff.ms | retries 用来配置生产者重试次数。retry.backoff.m 设定两次重试的时间间隔,避免无效且频繁重试 | - retries=0(default)。有些异常可以自恢复,比如网络抖动、leader 副本选举等。 - retry.backoff.ms=100 |
| connections.max.idle.ms | 指定在多久之后关闭限制的连接 | 默认值是 540000 ( ms ) ,即 9 分钟。 |
| linger.ms | 这个参数用来指定生产者发送 ProducerBatch 之前等待更多消息(ProducerRecord)加入 |
Producer Batch 的时间。生产者客户端会在 ProducerBatch 被填满或等待时间超过 linger.ms 值时发迭出去。增大这个参数的值会增加消息的延迟,但是同时能提升一定的吞吐量 | 默认值为 0
和 TCP 的 Nagle 算法有点像。 |
| receive.buffer.bytes | 这个参数用来设置 Socket 接收消息缓冲区(SO 阻CBUF)的大小 | 默认值为 32768,即 32 KB
-1:系统默认值 |
| send.buffer.bytes | 用来设置 Socket 发送消息缓冲区SO SNDBUF 的大小 | 默认值为 131072,即 128 KB
-1:系统默认值 |
| request.timeout.ms | 配置 Producer 等待请求响应的最长时间 | 默认值为 3 0000 ( ms)
注意这个参数需要比 broker 端参数 replica.lag.time.max.ms 的 值要大,这样可以减少因客户端重试而引起的消息重复的概率。 |
| | | |
kafka 可以保证同一个分区内消息有序。如果生产者按照一定顺序发送消息,那么这些消息也会顺序写入分区。但如果将 acks 设置为非零值,max.in.flight.request.per.connection 参数配置为大于 1 的值,则会造成乱序情况。一般而言,在需要保证顺序的场合建议把参数 max.in.flight.request.per.connection 配置为 1,而非把 ack 配置为 0 ,不过这样会影响吞吐量。
消费者
示例代码
public static void main(String[] args) {final String SERVER = "192.168.217.128:9092";final String TOPIC = "test3";Properties props = new Properties();// 节点地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, SERVER);// 所属的消费者组props.put(ConsumerConfig.GROUP_ID_CONFIG, "test3-group-1");// key和value的反序列化类props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 自动提供offset的时间间隔props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");// 会话超时时间props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");// 创建kafka生产者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 生产者订阅主题consumer.subscribe(Collections.singletonList(TOPIC));while (!Thread.currentThread().isInterrupted()) {// 从节点拉取消息,每次poll操作可以拉取多条消息ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));// 生产者消费消息逻辑for (ConsumerRecord<String, String> record : records) {System.out.println("receive record: " + record.value());}}}
传递语义
Kakfa 服务端并不会主动记录消费者的消费位移,因为:
- 如果 Kafka 服务端主动记录消费位移,如果消费者在消费数据过程中出现异常,那么这条消息永远不会被处理。
- 让消费者管理消费位移可以有更大的灵活性。
旧版本的消费者会将消费位移记录到 ZK 中,而新版本 Kafka 为了缓解 ZK 的压力,在 Kakfa 服务端中添加一个名为 __cnosumer_offsets 的内部主题,以下简称为 **OffsetsTopic**。当消费者上/下线程时会触发重平衡操作(rebalance),对分区进行重新分区,待重平衡操作完成后,消费者就可以读取 OffsetsTopic 中的记录的 offset 的值,并从此 offset 位置继续消费数据。
上面示例中我们设置 enable.auto.commit 为 true 开启自动提交功能,并设置 auto.commit.interval.ms 的值,它是指两次提交消费位移的时间间隔。消费者提交位移的时机非常重要,提交太频繁则会导致网络拥塞,提交不频繁则可能增大消息丢失的概率。KafkaConsumer 还提供了两个手动提交 offset 的方法,分别是 commitSync() 和 commitAsync(),它们可以提交指定的 offset 值,前者是同步提交,后者是异步提交。
Exactly once 语义是最难保证的,需要生产者和消费者两部分共同决定:
- 生产者保证不会产生重复的消息。
- 消费者保证不能重复拉取相同的消息。
实现 Exactly once 语义有两个可选方案:
- 每个分区只能一个生产者写入消息。当出现异常或超时情况时,生产者就要查询此分区的最后一个消息,用来决定后续操作是消息重传还是继续发送。
- 为每个消息添加一个全局唯一的主键,生产者不做其他特殊处理,按照之前方式进行重传。由消费者对消息进行去重。
消息异常场景
At least once
消费者从节点拉取消息,然后处理消息,最后提交 offset。如果消费者在处理完消息后、提交 offset 之前宕机,待消费者重新上线后,还会处理刚才未提交的那部分消息。这种情况导致消息被重复消费,对应 At least once 语义。At most once
消费者从节点拉取消息,然后先提交 offset,后处理消息。如果在处理消息过程中消费者宕机,待消费者重新上线后,就无法讲到刚才已经提交而未处理的这部分消息,对应 At most once。导致消息丢失并非只能这么一种情况,比如消息者组重平衡也可能导致消息丢失。Exactly once 方案
消费者关闭自动提交 offset,改用手动提交。消费者利用事务的原子性实现 Exactly once 语义。我们将消息处理和提交 offset 放在一个事务中,事务执行成功则认为消息被消息成功,否则事务回滚重新消息。当出现消费者宕机或 Rebalance 操作时,消费者可以从关系型数据库中找到对应的 offset,然后通过KakfaConsumer.seek()方法手机设置消费位移,从该位置继续消费消息。目前为止,消费者并不知道 Consumer Group 发送 Rebalance 操作,哪个分区分配给了哪个消费者消费。我们可以通过向 KafkaConsumer 添加 ConsumerRebalanceListener 接口来解决这个问题。 ```java onPartitionRevoked():调用时机是 Consumer 停止拉取数据之后、Rebalance 开始之前,我们可以在此方法中实现 手动提交 offset,这就避免Rebalance导致的重复消费的情况
onPartitionAssigned():调用时机是 Rebalance 完成之后、Consumer 开始拉取数据之前,我们可以在此方法中调整或自定义 offset 的值
<a name="N5lmS"></a>## 消费者和消费组Kakfa 有消费组的概念:在同一个消费者组(Consumer Group)中,同一个主题的不同分区会分配给消费者组内的不同消费者消费。<br />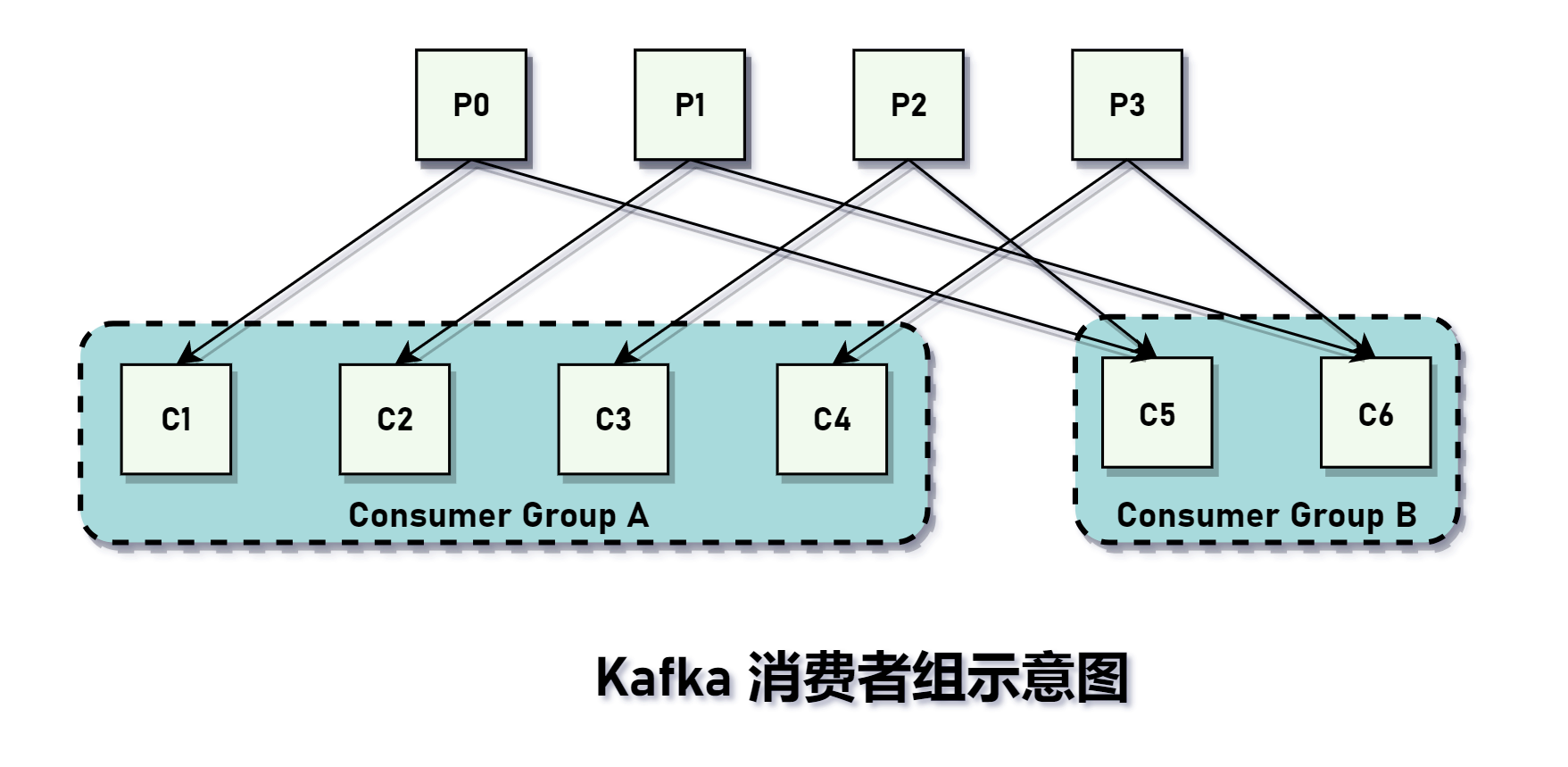- 消费者负责订阅 Kafka 中的主题(Topic),并从订阅的主题上拉取消息。- 每个消费者都有一个对应的消费组。当消息发布到主题后,只会投递给订阅它的每个消费组中的一个消费者。- 消费者和消费组这种模型可以让整体的消费能力具备横向伸缩性,我们可以增加(或减少)消费者的个数来提高(或降低)整体的消费能力。如果出现消费者的个数大于分区个数的情况,就会有消费者分配不到任何分区。- 以上是默认分区分区策略,用户可以通过消费者客户端参数 `partition.assignment.strategy` 来设置消费者与订阅主题之间的分区分配策略。- 消费中间件有两种消息投递方式- P2P,点对点模型。如果所有消费者都属于同一个消费组,则所有的消息都会被均衡地投递给每一下消费者。每条消息只会被一个消费者处理。- 发布/订阅模式。消费者隶属于不同的消费组,所有的消息都会被广播所有的消费者。- 消费者逻辑步骤- 配置消费者客户端参数及创建相应消费者实例- 订阅主题- 拉取消息并消费- 关闭消费者实例- `group.id` :消费者隶属的消费组的名称,默认为 `""`,一般这个参数需要设置成具有一定的国务意义名称。<a name="FNrC4"></a>## 消费者组重平衡(Consumer Group Rebalance)设计问题:1. 为消费者分配分区的操作是哪里完成的? 服务端还是客户端。1. 默认分区策略是什么? 如何扩展分区分配策略?<a name="vcq9q"></a>### 方案一Kafka 最开始的方案是基于 ZK 的 Watcher 机制实现的。每个 Consumer Group 在 ZK 中都维护一个 `/consumers/[group id]/ids` 路径,在此路径下使用临时节点记录属于此 Consumer Group 的消费者的 ID。它是由消费者启动时创建。还有两个与 ids 同级的节点,分别是 `owners` 和 `offsets`,分别记录分区与消费者的对应关系和此 Consumer Group 在某个分区上的消费位置。<br />每个消费者都会在 `/consumer/[group id]/ids` 和 `/brokers/ids` 路径上注册一个 Watcher。当 `/consumer/[group id]/ids` 路径的子节点发生变化时,表示 Consumer Group 中的消费者出现了变化。当 `/broker/ids` 路径的子节点发生变化时,表示节点出现增减。这样,通过这两个 Watcher,每个消费者就可以感知 Kafka 集群的状态。但是,这会严重依赖 ZK,带来两个比较严重的问题:1. **羊群效应(Herd Effect)**:会有多个消费者向 `/consumers/[group id]/ids` 和 `/brokers/ids` 注册 Watcher。一旦节点发生变化,导致大量的 Watcher 通知需要被发送给客户端,导致在通知期间其他操作延迟。出现了羊群效应。1. **脑裂(Split Brain)**:<a name="ZdsVN"></a>### 方案二由于上述两个原因,Kafka 对 Rebalance 操作进行重构。核心思想是:将全部的 Consumer Group 分成多个子集,每个 Consumer Group 子集在服务端对应一个 GroupCoordinator 对其进行管理,GroupCoordinator 是 KakfaServer 用于管理 Consumer Group 的组件。消费者不再依赖 ZK,而只有 GroupCoordinator 在 ZK 上添加 Watcher。消费者在加入或退出 Consumer Group 时会修改 ZK 中保存的元数据,此时会触发 Watcher,通知 GroupCoordinator 开始 Rebalance 操作。其实核心思想是分而治之。<br />方案二的设计能解决方案一的两个比较严重的问题,但也带来以下局限的地方:1. 分区分配操作是由 Kafka 服务端的 GroupCoordinator 完成的,因此服务端需要实现分区分配策略算法。当想要使用新的策略时,需要更新配置并重启服务端。1. 不同的 Rebalance 策略有不同的验证需求。当需要自定义分区分配策略和验证需求时,这又非常麻烦。<a name="s61lm"></a>### 方案三Kakfa 0.9 版本对消费者组重平衡进行重构。主要功能是将分区分配的工作放到消费者这一端进行处理,而 Consumer Group 管理的工作则依然由 GroupCoordinator 处理。这就实现了不同模块关注不同的业务,实现业务的切分和解耦。<br />总的来说,消费者组重平衡的发生是由以下事件所驱动:- 任何一个订阅的主题的分区数量发生变化。- 任何一个订阅的主题被创建或被删除。- 消费者组中的某个消费者被关闭或出现异常。- 新一新的消费者加入消费者组。其实就是分区变动或消费者变动都会导致重平衡发生。因此,我们在实际应用 Kafka 时应尽最大努力避免这些事情发生。<a name="kIs8J"></a>### 订阅主题与分区一个消费者可以订阅一个或多个主题。可以以集合的形式订阅,也可以以正则表达式的形式订阅特定模式的主题,相关 API 如下:```javapublic void subscribe(Collection<String> topics , ConsumerRebalanceListener listener);public void subscribe(Collection<String> topics);public void subscribe(Pattern pattern, ConsumerRebalanceListener listener);public void subscribe(Pattern pattern);
使用正则表达式的好处之一是:如果有新的符合正则规则的主题被添加,消费端是可以感知到并且可以消费新添加的主题中的消息。总结就是如果应用程序需要消费多个主题,并且可以处理不同的类型,那么这种订阅方式就十分有效。
除了 subscribe() 方法订阅主题之外,还可以通过 assign 手动指定特定分区。
public void assign(Collection<TopicPartition> partitions);
通过 subscribe() 方法订阅主题具有消费者自动再均衡的功能,在多个消费者的情况下可以根据分区分配策略来自动分配各个消费者与分区的关系。当消费组内的消费者增加或减少时,分区分配关系会自动调整,以实现消费者负载均衡及故障自动转移。而 assign() 方法订阅分区是不具备自动均衡功能。
查看分区信息:
public List<PartitionInfo> partitionsFor(String topic);
// org.apache.kafka.common.PartitionInfopublic class PartitionInfo {private final String topic; // 主题private final int partition; // 分区编号private final Node leader; // Leader节点信息private final Node[] replicas; // 分区AR集合private final Node[] inSyncReplicas; // 分区ISR集合private final Node[] offlineReplicas; // OSR集合// ...}
集合订阅的方式 subscribe(Collection)、正则表达式订阅的方式 subscribe(Pattem)和指定分区
的订阅方式 assign(Collection) 分表代表了 三 种 不 同 的 订 阅 状 态 : AUTO_TOPICS 、 AUTO PATTE卧J 和 USER ASSIGNED (如果没有订阅 , 那么订阅状态为 NONE)
推荐使用 Avro、JSON、Thrift、ProtoBuf 或 Protostuff 等通用的序列化工具来包装。
public class ConsumerRecord<K, V> {public static final long NO_TIMESTAMP = RecordBatch.NO_TIMESTAMP;public static final int NULL_SIZE = -1;public static final int NULL_CHECKSUM = -1;private final String topic; // 消息所属的主题private final int partition; // 分区编号private final long offset; // 分区的偏移量private final long timestamp; // 时间戳private final TimestampType timestampType; // 时间戳类型:createTime和LogAppendTimeprivate final int serializedKeySize; //private final int serializedValueSize;private final Headers headers;private final K key;private final V value;private final Optional<Integer> leaderEpoch;private volatile Long checksum;// ...}
消费消息
消费模型
Kafka 的消费模型属于拉模型。消费者主动向服务端发起请求获得消息。核心 API 如下:
// org.apache.kafka.clients.consumer.ConsumerConsumerRecords<K, V> poll(Duration timeout);
参数 timeout 的设置取决于应用程序对响应速度的要求。这个时间表示需要在多长时间内将控制权移交给执行轮询的应用线程。timeout=0 意味着 poll 会立即返回,而不管是否拉取到消息。如果应用线程唯一的工作就是从 Kafkaa 拉取并消费消息,可以将这个参数设置为 Long.MAX_VALUE 。
按分区消费
Kafka 并没有提供以分区为维度消费消息。但我们可能通过保存的主题列表来进行逻辑处理,示例代码如下:
// 创建kafka生产者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 生产者订阅主题List<String> topicList = Collections.singletonList(TOPIC);consumer.subscribe(topicList);while (!Thread.currentThread().isInterrupted()) {// 从节点拉取消息,每次poll操作可以拉取多条消息ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));// 以分区为维度进行消费for (String topic : topicList) {Iterable<ConsumerRecord<String, String>> recordsPerTopic = records.records(topic);// ...处理其它逻辑}}
应该注意 ConsumerRecords 相关 API。
- 批量获取消息进行迭代。
- 可以从 Leader 得到的消息中根据主题过滤。因为有可能消费者消费多个 Topic。
- 内部逻辑
- 消费位移
- 消费者协调器
- 组协调器
- 消费者的选举
- 分区分配的分发
- 再均衡的逻辑
- 心跳
位移提交
对于 Kafka 中的分区而言,它的每条消息都有唯一的偏移量,称之为 offset,用来表示消息在分区中对应的位置。对于消费者而言,它也有 offset 的概念,消费者使用 offset 来表示消费到分区中某个消息所在的位置,从消费者角度,offset 被称为位移。位移的提交保证任意消息不会被重复消费。
和位移相关的两个 API: ```java // org.apache.kafka.clients.consumer.Consumer /**- @param partition
- @return */ long position(TopicPartition partition);
/**
- @param partitions
- @return
/
Map
partitions); `` kafka 默认是**自动提交**,它属于**定期**提交,提交周期可通过配置auto.commit.interval.ms=5S实现(表示消费者每隔 5S 会将拉取到的每个分区中的最大的消息位移进行提交)。提交动作是在方法poll()` 中触发并完成。
在 Kafka 消费的编程逻辑中位移提交是一大难点,自动提交使得代码优雅简洁,避免了复杂的位移提交逻辑,但带来的问题是消息重复消费和*消息丢失消息重复消费
消费者从服务端拉取一批消息进行消费,在未提交位移信息之前,消费者宕机了。待重启后又从上一次提交的位移开始消息,这便发生了消息重复消费。简单总结就是已消费但未及时提交偏移量。Rebalance 导致的消息重复消费也是由于这种原因。消息丢失
消息丢失一般发生在多线程环境中,比如线程 A 不断poll从服务端拉取消息并放入一个BlockingQueue队列等待线程 B 消费消息,线程 A 提交位移的值大于线程 B 消费的消息的位移,假设线程 B 遇到致命异常退出,那么等待线程重启后就不会…手动提交
和手动提交消息有两个相关的 API: ```java void commitAsync(); void commitAsync(OffsetCommitCallback callback); void commitAsync(Map
void commitSync();
void commitSync(Duration timeout);
void commitSync(Map
提交方式可分为同步和异步方式。异步提交效率高,但会增大数据丢失的概率。<br />在实际应用中,更多时候是按照分区的粒度划分提交位移的界限。```javatry {while(true) {// pollconsumer.commitAsync();}} finally {try {consumer.commitSync();} finally {consumer.close();}}
控制或关闭消费
KafkaConsumer 提供流量控制方法,API 简介如下:
// 暂停某些分区在拉取操作时返回数据给客户端public void pause(Collection<TopicPartition> partitions);// 恢复某些分区向客户端返回数据的操作public void resume(Collection<TopicPartition> partitions);
wakeup() 方法是 KafkaConsumer 中唯一可以从其他线程里安全调用的方法。它可以使得 poll() 方法抛出 WeakupException 异常。
KafkaConsumer 是非线程安全的。
指定位移消费
如果没有指定位移,则根据参数 auto.offset.reset 来操作,默认为 latest,表示从分区末尾开始消费。earliest 会从起始处,即 0 处开始消费。
API seek 能让用户随意定位自己想要的起始位置,得以追前消费或回溯消费。
public void seek(TopicPartition partition, long offset);
示例:
KafkaConsumer<String , String> consumer = new KafkaConsumer<> (props);consumer.subscribe(Arrays.asList(topic));consumer.poll(Duration.ofMillis(lOOOO));①// 用来获取消费者所分配的分区信息Set<TopicPartition> assignment = consumer.assignment(); ②for (TopicPartition tp : assignment) {consumer.seek(tp , 10);}while (true) {ConsumerRecords<String , String> records = consumer.poll(Duration.ofMillis(lOOOO));//consume the record .}while(assignment.size == 0) {} // 如果不为0,则说明已经成功分配到了分区
基于时间 offsetsForTimes(Map<TopicPartition, Long>
再均衡
再均衡是指分区的所属权从一个消费者转移到另一个消费者的行为,它为消费组具备高可用性和伸缩性提供保障,使我们可以既方便又安全地删除消费组内的消费者或往消费组内添加消费者。在发生再均衡期间,消费组内的消费者是不可能消费消息的。必须等待再均衡后,完成分区分配后才能开始消费。简单来说,就是对消费组增、删操作引发的再均衡现象。
再均衡再来一个严重的问题:重复消费。当另一个分区被重新分配给另一个消费者时,消费者当前的状态也会丢失。如消费者来不及提交位移就发生了再均衡操作,之后这个分区又分配给了消费组内的另一个消费者,原来被消费完的那部分消息又重新消费了一遍,出现了重复消费。一般情况下,应尽量避免不必要的再均衡的发生。
ConsumerRebalanceListener 接口
// 在再均衡开始之前和消费者停止读取消息之后被调用。// 处理消费位移的提交,以避免一些不必要的重复消费现象发生// partitions表示再均衡前所分配到的分区void onPartitionsRevoked(Collection<TopicPartition> partitions);// 在重新分配分区之后和消费者开始消费之前被调用// partitions 表示再均衡后所分配到的分区void onPartitionsAssigned(Collection<TopicPartition> partitions);
消费者拦截器
在消费到消息或提交消费位移时进行一些定制化操作。
// org.apache.kafka.clients.consumer.ConsumerInterceptorpublic interface ConsumerInterceptor<K, V> extends Configurable, AutoCloseable {/*** 在 poll() 方法返回之前调用此方法。* 比如修改返回的消息内容、按照某种规则过滤消息。* 如果方法中抛出异常,将会被记录在日志中,而不会再向上传递* This is called just before the records are returned by* {@link org.apache.kafka.clients.consumer.KafkaConsumer#poll(java.time.Duration)}* <p>* This method is allowed to modify consumer records, in which case the new records will be* returned. There is no limitation on number of records that could be returned from this* method. I.e., the interceptor can filter the records or generate new records.* <p>* Any exception thrown by this method will be caught by the caller, logged, but not propagated to the client.* <p>* Since the consumer may run multiple interceptors, a particular interceptor's onConsume() callback will be called* in the order specified by {@link org.apache.kafka.clients.consumer.ConsumerConfig#INTERCEPTOR_CLASSES_CONFIG}.* The first interceptor in the list gets the consumed records, the following interceptor will be passed the records returned* by the previous interceptor, and so on. Since interceptors are allowed to modify records, interceptors may potentially get* the records already modified by other interceptors. However, building a pipeline of mutable interceptors that depend on the output* of the previous interceptor is discouraged, because of potential side-effects caused by interceptors potentially failing* to modify the record and throwing an exception. If one of the interceptors in the list throws an exception from onConsume(),* the exception is caught, logged, and the next interceptor is called with the records returned by the last successful interceptor* in the list, or otherwise the original consumed records.** @param records records to be consumed by the client or records returned by the previous interceptors in the list.* @return records that are either modified by the interceptor or same as records passed to this method.*/public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);/*** 提交偏移量时会被调用* 调用者将会忽略异常* Any exception thrown by this method will be ignored by the caller.** @param offsets A map of offsets by partition with associated metadata*/public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);/****/public void close();}
比如消息有效性 TTL 就可以通过拦截器功能处理。
使用拦截器注意:
拦截链某个拦截器执行失败,那么下一个拦截器会接着从上一个执行成功的拦截器继续执行
多线程实现
方案一:本地线程缓存 ThreadLocal
核心思想是:一个分区对应一个线程,所有的线程同属于一个消费组。
优点:代码较为简单,不需要考虑复杂的位移提交逻辑。缺点:并行度受限于分区数量。方案二:多个线程消费同一个分区
核心思想:通过
assign()、seek()等方法实现。
优点:并行度不受限于分区数量,可以极大提高吞吐量。
缺点:非常明显,对位移的提交和顺序控制处理变得十分复杂。
这种方案很少被应用。方案三:主从 Reactor 模式
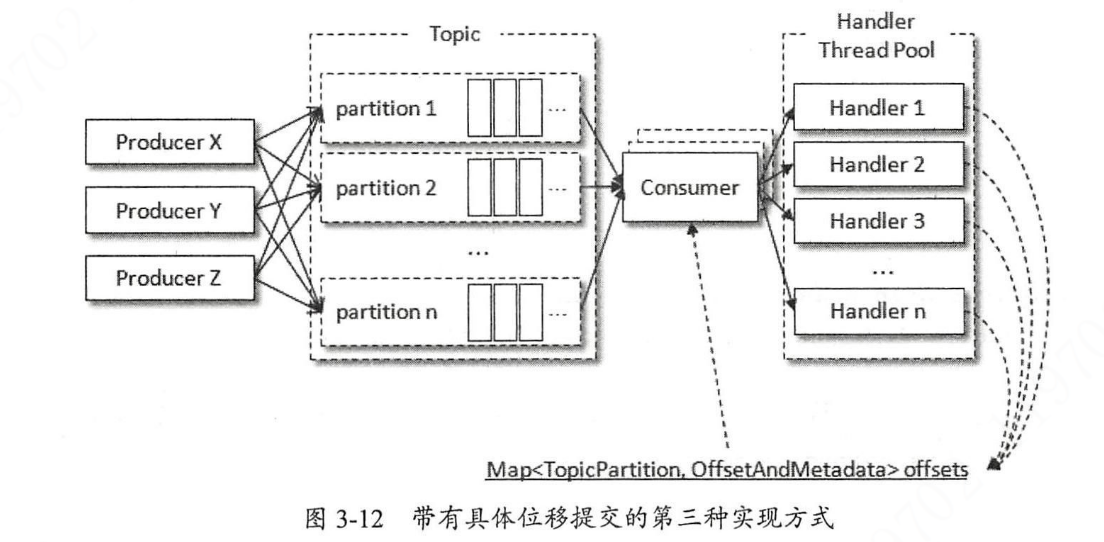
核心思想:线程 A 只负责从服务端拉数据,数据处理交给线程池完成。
优点:具有横向扩展能力,职责单一。
缺点:要保证消息的顺序处理变得十分困难。位移提交变得十分复杂。方案四:基于滑动窗口实现

核心思想:将拉取的消息暂存起来,多个消费线程可以拉取暂存的消息。用于暂存消息的缓存大小即为滑动窗口的大小。
对上图做解析:每个方格表示一个批次的消息。一个滑动窗口包含若干方格,方格大小和滑动窗口的大小同时决定了消费线程的并发数:一个方格对应一个消费线程。对于窗口大小固定的情况,方格越小并行度越高,对于方格大小固定的情况,窗口越大并行度越高。消息悬停
如果一个方格人的消息无法被标记为消费完成,那么造成
startOffset的悬停。为了能使窗口能继续向前滑动,那么就需要一个阈值,当startOffset县停一个方块表示一批消息。
- 每当 startOffset 指向的方格中的消息被消费完成,就可以提交这部分的位移,同时,窗口向前滑动一格,删除原来 startOffset 所指方格中对应的消息,并且拉取新的消息进入窗口。
- 方格大小和滑动窗口的大小同时决定了消费线程的并发数:一个方格对应一个消费线程。但窗口设置过大不仅增大内存的开销,而且发生异常的情况下也会引起大量的重复消费。
若方格内的消息无法被标记为消费完成,那么就会造成 startOffset 的悬停,为了能使窗口能继续向前滑动,那么就需要设定一个阈值,当 startOffset 悬停一定的时间后就对这部分的消息进行本地重试消费,如果重试失败就转入重试队列,如果还不成功则转入死信队列。
重要的消费者参数
fetch.min.bytes。
poll()方法所能获取的最小数据量,默认值1B。如果未满足则阻塞等待。- fetch.max.bytes。
poll()方法一次所能获取的最大数据量,默认值50MB。 - fetch.max.wait.ms。默认值
500ms。不能一直等待呀。 - max.partition.fetch.bytes。从每个分区里返回给 Consumer 的最大数据量。默认值
1MB。针对分区而言。 - max.poll.records。一次拉取请求中获得的最大消息数。默认值 500 条。
- connections.max.idle.ms。多久之后关闭限制的连接。默认值 9分钟。
- exclude.internal.topics。两个内部的主题:consumer_offsets 和 transaction_state。指定内部主题是否可以向消费者公开。默认值 true,那么只能使用 subscribe(Collection) 的方式订阅主题。
- receive.buffer.bytes。Socket 接收缓冲区 SO_RECBUF 的大小。默认值 64KB。
- send.buffer.bytes。SO_SNDBUF 大小,默认值 128KB。
- requet.timeout.ms。等待请求响应的最长时间,默认值 30000ms
- metadata.max.age.ms。配置元数据的过期时间,默认值 5分钟。如果在限定时间范围内没有更新,则会被强制更新。
- reconnect.backoff.ms。尝试重新连接主机之前的等待时间,也称退避时间。避免频繁连接主机。默认值 50ms。
- retry.backoff.ms。尝试重新发送失败的请求到指定的主题分区之间的等待(退避)时间,默认值 100ms。
- isolation.level。事件的隔离级别。read_uncommitted 和 read_committed。
- heartbeat.interval.ms。当使用kafka 的分组管理功能时,心跳到消费者协调器之间的预计时间。心跳用于确保消费者的会话活动状态,当有新消费者加入或离开组时方便重平衡。必须比 session.timeout.ms 小,通常不高于 1/3。默认值 3000
- max.poll.interval.ms
- auto.offset.reset
4. 主题与分区
主题作为消息的归类,可以细分为一个或多个分区,分区可看作对消息的二次归类。
分区的划分不仅为 kafka 提供了可伸缩性、水平扩展的功能,还通过多副本机制来为 kafka 提供数据冗余以提高数据可靠性。
主题的管理
创建主题
auto.create.topics.enable=true,当生产者向一个尚未创建主题发送消息,会自动创建一个分区数为 num.partitions 、副本因子 default.replication.factor 的主题。
很多时候,这种自动创建主题的行为都是非预期的,除非特殊需求,否则不建议设置为 true。
推荐使用 kafka-topics.sh 脚本创建主题。
kafka-topics.sh--bootstrap.server localhost:9092--create--topic topic-test--partitions 4--replication-factor 2
严谨地说,物理文件 <topic>_<partition> 对应的不是分区,分区同主题一样是一个的概念而没有物理存在。
还可以通过 ZK 查看集群中的各个 broker 的分区副本的分区情况。在创建一个主题时会在 ZK 的 /brokers/topics/ 目录下创建一个同名的实节点,该节点记录了主题的分区副本分配方案。
get /brokers/topics/topic-create{"version":1, "partitions":{"2":[1,2], "1":[0, 1]}}
表示分区 2 分配了两个副本,分别在 brokerid 为1 和 2 中。
分区副本的分配策略
默认分配
- 自定义分配策略
- 默认分配策略
- 基于机架信息分配。
- 不基于机架信息分配。
- 默认情况下创建主题时问题从编号为 0 的分区依次轮询进行分配
- 基于机架信息分配。
kafka-topic.sh 脚本中的 alter 指令提供修改功能。在增加分区数一定要三思而行。对于基于 key 计算的主题而言,建议在一开始就设置好分区数量,以避免以后对其进行调整。
只支持增加分区而不支持减少分区。
配置管理
kafka-config.sh 用来对配置进行操作的。在运行状态下修改原有的配置,以达到动态变更的目的。
kafka-config.sh --bootstrap.server localhost:9092--describe // 指定查看配置的指令动作--entity-type topics // 查看配置的实体类型,包含topics、brokers、clients、users--entity-name topic-config // 查看配置的实体名称
主题参数(Page120)
分区管理
包括
- 优先副本的选举
- 分区重分配
- 复制限流
- 修改副本因子
优化副本的选举
分区使用多副本机制来提升可靠性,但只有 leader 副本对外提供读写服务,而 follower 副本只负责在内部进行消息的同步。
原来 Leader 被替换,如果修复后重新加入集群时,它只能成为一个新的 follower 节点而不再对外提供服务。
为了能够有效地治理负载失衡的情况, Kafka 引入了优先副本(preferred replica) 的概念。即在 AR 集合列表中的第一个副本。理想情况下,优先副本就是该分区的 leader 副本。Kafka 要确保所有主题的优先副本在 Kafka 集群中均匀分布,这样就保证了所有分区的 leader 均匀分布。
Kafka 默认情况下是开启分区自平衡功能,它会启动一个定时任务,此任务会轮询所有的 broker 节点,计算每个 broker 节点的分区不平衡率(非优先副本的 leader 个数/分区总数)是否超过了leader.imbalance.per.broker.percentage参数配置的比值,默认值 10%,超过设定则会自动执行优先副本的选举动作以求分区平衡。周期由leader.imbalance.check.interval.seconds控制,默认时间为 5分钟。
生产环境不建议使用,因为这可能引起负责性能问题。可能导致客户端阻塞。两者,分区及副本的再均衡也不能完全确保集群整体的平衡。建议还是将掌控权把控在自己手中,可以针对此类相关的埋点指针设置相应告警,在合适的时机执行合适的操作,即手动执行分区平衡。kafka-perferred-replica-election.sh脚本提供了对分区 leader 副本进行重平衡的功能。优先副本的选举过程是一个安全的过程,Kafka 客户端可以自动感知分区 leader 副本的变更。
在优先副本的选举过程中,具体的元数据会被存入 ZK 的/admin/preferred_replica_election节点,如果这些数据超过 ZK 节点允许的大小,会选举失败。默认大小 1MB。分区重分配
当集群中新增 broker 节点时,只有新创建的主题分区才有可能被分配到这个节点上,而之 前的主题分区并不会自动分配到新加入的节点中,因为在它们被创建时还没有这个新节点,这样新节点的负载和原先节点的负载之间严重不均衡。
为了解决上述问题,需要让分区副本再次进行合理的分配,也就是所谓的分区重分配。 Kafka 提供了kafka-reassign-partitions.sh脚本来执行分区重分配的工作,它可以在集群扩容、 broker 节点失效的场景下对分区进行迁移。
3个步骤:
- 创建一个包含主题清单的 JSON 文件
- 根据主题清单和 broker 节点清单生成一份重分配方案
- 根据这份方案执行具体的重分配动作
原理:
- 先通过控制器为每个分区添加新副本,新的副本将从分区的 leader 副本那里复制所有数据。
- 根据分区的大小不同,复制过程需要花费时间。
- 在复制完成后,控制器将旧副本从副本清单里移除。
- 对于不均衡的负责,可以执行一次优先副本选举动作。
-
复制限流
减少重分配的粒度,以小批次的方式来操作是一种可行的解决思路。但在高峰期这是不足够的。因此,就这需要一个限流的机制,可以对副本间的复制流量加以限制来保证重分配期间整体服务不会受太大的影响。
kafka-config.sh
以动态配置的方式来达到限流的目的。有两个与复制相关的参数:
follower.replication.throttled.rate:设置 follower 副本复制的速度
leader.replication.throttled.rate:设置 leader 副本传输的速度。
kafka-reassign-partitions.sh
修改副本因子
如何选择合适的分区数
性能测试工具
kafka-consumer-perf-test.sh
消息中间件的性能一般是指吞吐量。会受到消息大小
- 消息压缩方式
- 消息发送方式(同步/异步)
- 消息确认类型(acks)
- 副本因子
一旦分区超过某个阈值,整体的吞吐量是不升反降的。即并不是分区数越多吞吐量越大。
分区数的上限
过多的分区会导致 Too many open files 异常。
# 查看进程processId所占用的文件描述符的个数ls /proc/processId/fd wc -l# 将上限提高到 65535,需要重启才能生效ulimit -n 65536
日志存储

- 向 Log 中追加消息时是顺序写入的,只有最后一个 LogSegment 才能执行写入操作,之前的都是不能写入数据。将最后一个 LogSegment 称为 activeSegment。
- 随着消息不断写入,activeSegment 也会被写满,就需要创建新的 activeSegment。
- 为了便于消息的检索,每个 LogSegment 中的日志文件(以 .log 结尾)都有对应的两个索引文件
- 偏移量索引文件(.index 结尾)
- 时间戳索引文件(.timeindex 结尾)
偏移量
-
V1
0.10.0 到 0.11.0 版本之前使用。和 V0 相比多了一个 timestamp 字段。
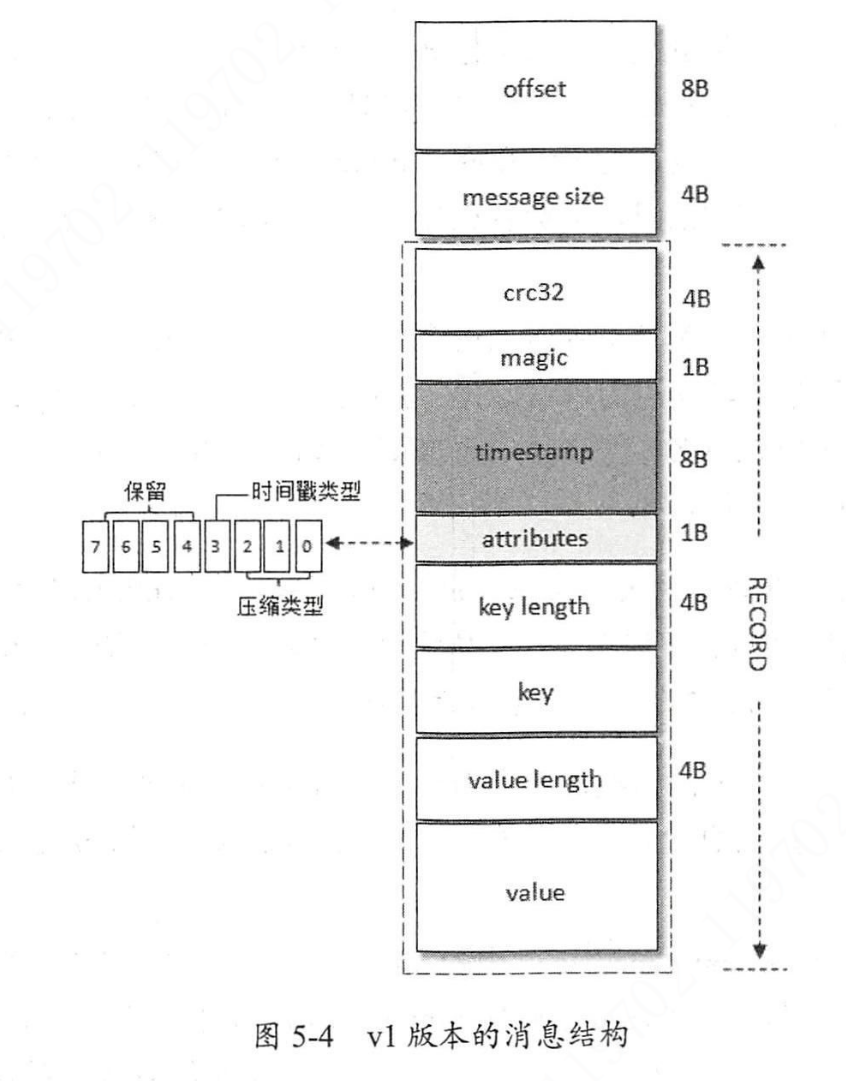
相比 V0,V1 的长度比 V0 大 8 个字节,即 22B。消息压缩
Kafka 是将多条消息一起进行压缩。在 broker 中保持压缩状态进行存储。
使用哪种方式是通过参数 compression.type 来配置,默认是 producer,表示保留生产者使用的压缩方式。不可以配置成 gzip、snappy、lz4。uncompressed 表示不压缩。

V2
Kafka 从 0.11.0 版本开始使用 V2 版本的消息格式,相对前两个版本改动很大。同时参考 Protocol Buffer 而引入变长整形(Varints) 和 ZigZag 编码。
Varints
Varints 使用一个或多个字节来序列化整数的一种方法:
- 数值越小,其占用的字节数就越少。
- Varints 中的每个字节都有一个位于最高位的 msb 位(most significant bit),除最后一个字节外,其余 msb 位都设置为 1,最后一个字节的 msb 位为 0。为 1 表示后面的字节和前面字节一起表示同一个整数。
- 剩余 7 位用于存储数据本身,这种表示类型又称为 Base 128。
- 采用小端字节序,即最小的字节放在最前面。
```shell
数字 1,只占用1个字节
0000 0001
数字 300,占用两个字节
256+32+8+4
1010 1100 0000 0010
1 去掉每个字节的 msb 位
010 1100 000 0010
2 字节翻转
000 0010 010 1100
3 填充
0000 0010 0010 1100(300)
Varints 可以用来表示 int32、int64、uint32、uint64、sint64、bool、enum 等类型。<br />为了使编码更加高效,Varints 使用了 ZigZag 编码方式<a name="xQNfW"></a>### ZigZagZigZag 编码以一种锯齿(zig-zags)的方式来回穿梭正负整数,将带符号整数映射为无符号整数,这样可以使绝对值较小的负数仍然享有较小的 Varints 编码。```shellsint32: (n << 1)^(n >> 31)sint64: (n << 1)^(n >> 63)
思想就是将一个大整数拆分成两部分,一部分用于存储>0的数,另一部分存储小于0的数。
V2 版本中的消息称为 Record Batch,而非之前的 Message Set,其内部也包含一条或全球通史消息。Record 头部不会被压缩,被压缩的是 records 字节中所有内容。
Record
- length:消息总长度
- timestamp delta 时间戳增量。占用 8 个字节,
- offset delta 位移增量。保存与 Recordbatch 起始位移的差值。
-
RecordBatch
producer id:PID,支持幂等和事务
- producer epoch:支持幂等和事务
- first sequence:支持幂等和事务
V2 版本不仅提供了更多的功能,比如事务、幂等性等,某些情况下还减少了消息的空间占用,总体性能提升很大。
日志索引
Kafka 中的索引文件以稀疏索引(sparse index)的方式构造,它并不保证每个消息在索引文件中都有对应的索引项。
每当写入一定量(log.index.interval.bytes=4KB)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索项。
稀疏索引通过 MappedByteBuffer 将索引文件映射到内存中,以加快索引的查询速度。
偏移量索引值单调递增,使用二分查找法快速定位偏移量的位置。如果指定偏移量不在索引文件中,则会返回小于指定偏移量的最大偏移量。
时间戳索引文件中的时间戳也保持严格的单调递增,查询指定时间戳时,也根据二分查找法查找不大于该时间戳的最大偏移量,要找到对应的物理文件位置还需要根据偏移量索引文件来进行再次定位。
使用稀疏索引方式是在磁盘空间、内存空间、查找时间等多方面的一个折中。
日志分段文件超过 broker 端参数 log.segment.bytes=1GB 后会进行切分
- 日志段大小超出 1GB
- 当前日志分段中消息的最大时间戳与当前系统差值大于 log.roll.ms 或 log.roll.hours。默认值 7天
- 偏移量或时间戳索引文件的大小达到 broker 端 log.index.size.max.bytes,默认值 10MB
- 追加的消息的偏移量与当前日志分段的偏移量之间的差值大于 Interge.MAX_VALUE。即要追加的消息的偏移量不能转变为相对偏移量(offset-baseOffset>Interger.MAX_VALUE)
旧的索引文件是只读的,而 activeSegment 是可读写。在索引文件切分时,Kafka 关闭当前正在写入的索引文件并置为只读模式,同时以可读写的模式创建新的索引文件。大小为 log.index.size.max.bytes。
偏移量索引
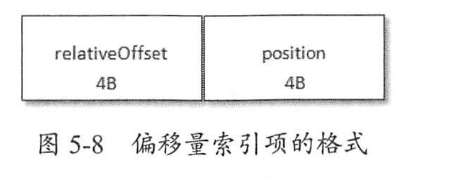
- relativeOffset:相对偏移量,表示消息相对于 baseOffset 的偏移量,占用 4 个字节,当前索引文件的文件名即为 baseOffset 的值。
- position:物理地址,也就是消息在日志分段文件中对应的物理地址,占 4 个字节。
索引项中没有直接使用绝对偏移量而改为使用 4 个字节的相对偏移量(relativeOffset=offset-baseOffset),这样可以减少索引文件占用的空间。
找到偏移量为 23 的消息:
- 通过二分法在偏移量索引文件中找到不大于 23 的最大索引项,即 [22, 656],然后从日志分段文件中的物理位置 656 开始顺序查找偏移量为 23 的消息。

在日志查找过程中是通过跳跃表的数据结构快速查找。Kafka 的每个日志中使用 COncurrentSkipListMap 来保存各个日志分段,每个日志分段的 baseOffset 作为 key,这样可以根据指定偏移量来快速定位到消息所在的日志分段。
Kafka 强制要求索引文件大小必须是索引项大小的整数倍。
时间戳索引
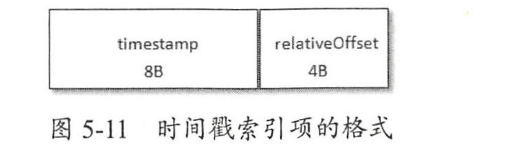
- timestamp:当前日志分段最大的时间戳
- relativeOffset:时间戳所对应的消息的相对偏移量
时间戳索引文件大小必须是索引项大小(12B) 的整数倍,如果不满足条件会进行裁剪。
我们己经知道每当写入一定量的消息时, 就会在偏移量索引文件和时间戳索引文件中分别增加一个偏移量索引项和时间戳索引项。
日志删除
日志分段的保留策略有 3 种:
- 基于时间的保留策略
- 基于日志大小的保留策略
- 基于日志起始偏移量的保留策略
日志压缩
日志压缩是指在默认的日志删除规则之外提供的一种清理过时数据的方式。
key 相同,可以只保留最新的一条记录。称 Log Compression。
Kafka 中的 Log Compaction 可以类比 Redis 中的 RDB 持久化模式。
Log Compaction 可以减少数据的加载量进而加快系统的恢复速度。cleaner-offset-checkpoint文件表示清理检查点文件,用来记录每个主题的每个分区中已清理的偏移量。通过清理检查点文件可以将 Log 分成两个部分
每个 broker 会启动log.cleaner.thread=1个日志清理线程负责执行清理任务,会选择污浊率最高的日志文件进行清理。
Kafka 用于保存消费者消费位移的主题dirtyRatio = dirtyBytes / (cleanBytes + dirtyBytes)
__consumer_offsets使用的就是Log Compaction策略。
使用 SkimpyOffsetMap 存储 key 和 value。
当需要删除一个 key 时,Kafka 提供了一个墓碑(tombstone)的概念,如果一个消息的 key 不为 null,但其 value 为 null,那么此消息就是墓碑消息。
日志清理线程发现墓碑消息时会先进行常规的处理,并保留墓碑消息一段时间,保留条件:当前墓碑消息所在的日志分段的最近修改时间 lastModifiedTime 大于 deleteHorizonMs(clean 部分中最后一个日志分段的最近修改时间减去保留阈值 deleteRetionMs(默认 24 小时))。
将多个日志段进行分组,一组内数据总和不超过 1GB,且对应的索引文件占用大小之和不超过 maxIndexSize(10MB),同一个组的多个日志分段清理过后,只会生成一个新的日志分段。磁盘存储
操作系统针对线性读写做深层次优化,比如
- 预读 read-ahead,提前将一个比较大的磁盘读入内存
- 后写 write-behind,将很多小的逻辑写操作合并起来组成一个大的物理写操作
Kafka 在设计时采用了文件追加的方式来写入消息,且不允许修改已写入的消息。
页缓存
读取磁盘文件内容(进程)->查看待读取的数据所在的页(page)是否在页缓存(pagecache)上(操作系统)->如果命中则直接返回数据,从而避免对物理磁盘 I/O 操作->未命中,则发出页中断,将数据页读入页缓存,之后再将数据返回给进程。
Linux vm.dirty_background_ratio 参数用来指定当脏页数量达到系统内存多少之后就会触发 pdflush/flush/kdmflush 等后台进程处理脏页,一般设置 < 10的数值即可。
Kafka 中大量使用了页缓存,这是 Kafka 实现高吞吐的重要因素之一。虽然数据先写入缓存,再由操作系统落盘,但是 Kafka 同样也提供了同步刷盘及间断性强制刷盘(fsync)功能。
磁盘I/O流程
写操作
进程调用 fwrite 把数据写入 IOBuffer 后就返回。内核并不会立即刷盘,会将多次小数据量相邻写操作进行合并,最后调用 write 函数一次性写入页缓存。数据到达页缓存后也不会立即落盘,内核有 pdflush 线程在不停地检测脏页,判断是否需要写回磁盘,如果是则发起磁盘 I/O 请求。
读操作
进程调用 fread 从 IOBuffer 中读取数据,如果成功则返回,否则到页缓存中读取数据,如果成功则返回,否则发起 I/O 请求,读取数据后缓存 Buffer 和 IOBuffer 并返回。
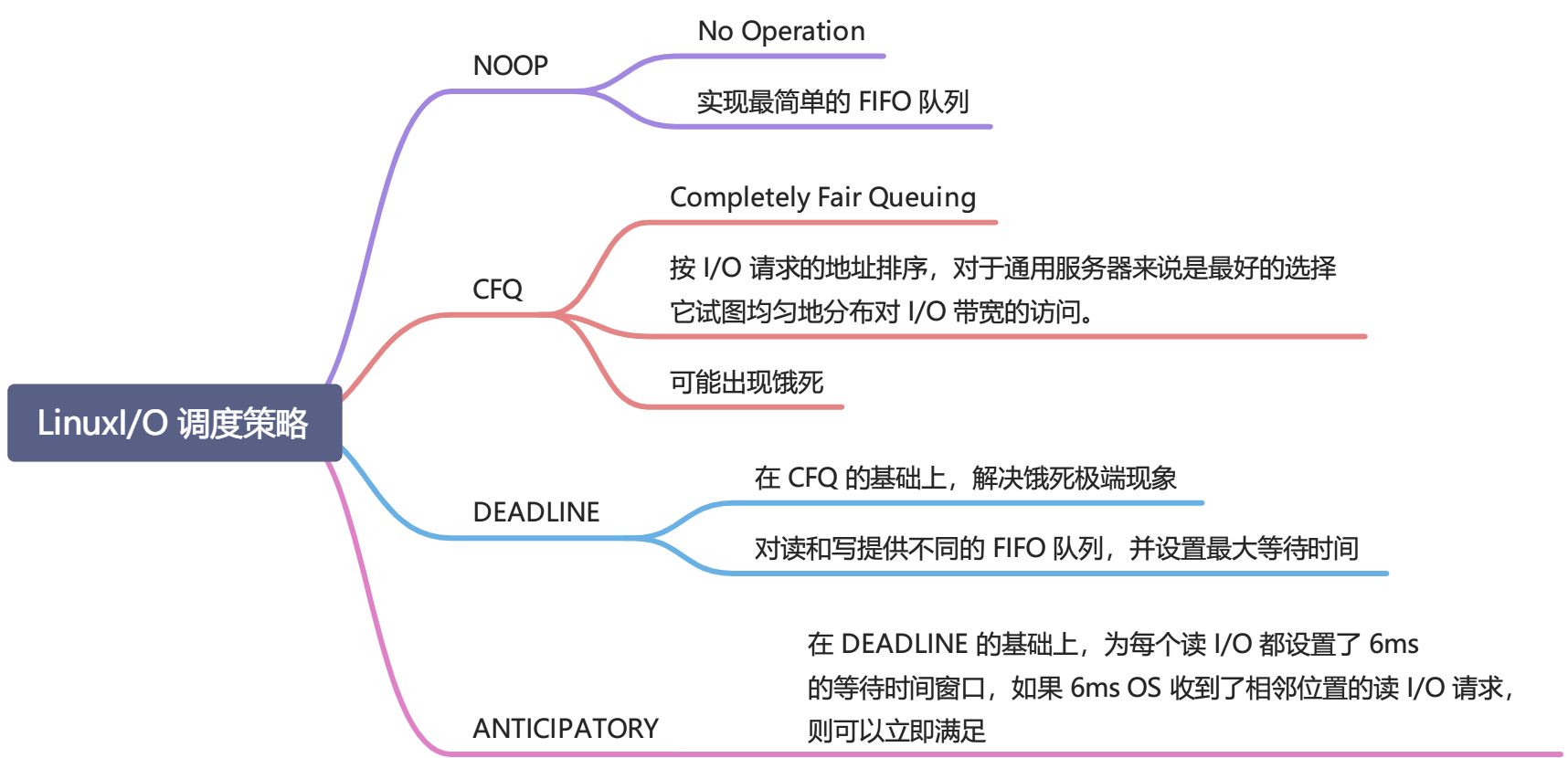
I/O 请求处理

I/O 调度策略有 4 种,分别是 NOOP、CFQ、DEADLINE 和 ANTICIPATORY,默认为 CFQ。
零拷贝
将数据直接从磁盘文件复制到网卡设备中,而不需要经过应用程序。
对 Linux 而言,依赖底层的 sendfile() 方法实现。而 Java 使用 FielChannel.transferTo() 方法包装 sendfile()。
普通 I/O
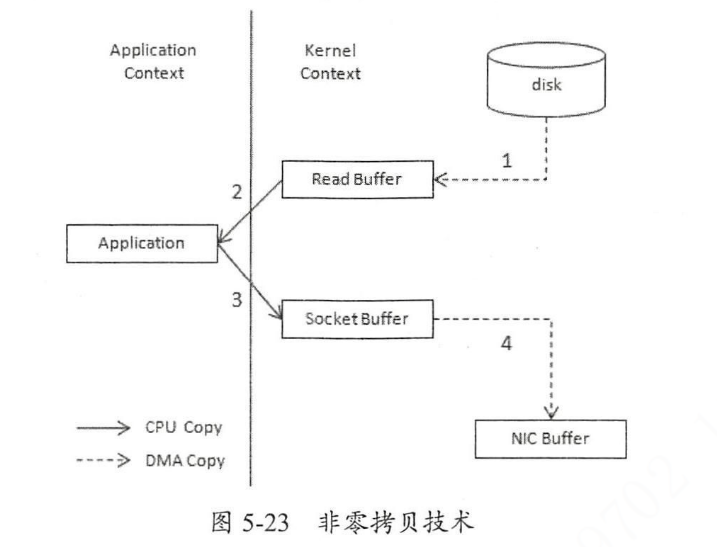
- 磁盘数据复制到内核的 ReadBuffer
- 将内核的 ReadBuffer 复制到应用程序
- 将应用程序中的数据复制到内核的 SocketBuffer
- 将 SocketBuffer 复制到网卡设备
调用是由处于用户态的应用程序发起,所以相关数据需要在用户态和内核态进行传输。但是我们发现用户态数据并不需要经过用户态。

零拷贝技术通过 DMA 技术将文件内容复制到内核模式下的 ReadBuffer,不过没有数据被复制到 SocketBuffer,只有包含数据的位置和长度的信息的文件描述符被加载到 SocketBuffer中。DMA 引擎直接将数据从内核模式上传递到网卡设备。

若有收获,就点个赞吧
0 人点赞
