概述
在上一节对 Controller 的网络组件、网络模型以及管理的元数据进行讲解,也看了部分重要的源码。本章着重对 Controller 功能进行讲解,包括:
- Controller 是如何感知集群事件的?
- Controller 是如何处理集群事件的?
- Controller 故障转移
Controller 如何感知事件
这个问题回答起来十分简单:通过 Zookeeper 的 watch 机制感知集群元数据的变化。假设现在集群已经有一个稳定的 Controller,此刻集群新增了一个 Broker 节点,有趣的事情发生了:
- 新增的 Broker 节点会在 Zookeeper 的
/brokers/ids/节点下创建一个临时子节点。 - Zookeeper 通知 Controller:有人创建了一个临时节点
/brokers/ids/0,节点数据是{"features":{},"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://192.168.217.128:9092"],"jmx_port":-1,"port":9092,"host":"192.168.217.128","version":5,"timestamp":"1623963938447"}。 - Controller 将 Zookeeper 事件转换为 Controller 内部事件
BrokerChange,然后再交给KakfaChannel完成处理逻辑。
那么问题又来了,到底什么时候向 Zookeeper 注册相关数据节点的 watch 呢? 这一部分是和 Controller 选举相关。当竞选 Controller 成功后,就会执行 Controller 上任逻辑,其中就包括向 Zookeeper 注册数据节点的 watch。
当 Controller 收到来自 Zookeeper 的 watch 事件后,需要转换为 Controller 的内部事件,转换逻辑在 ZookeeperClient#process(WatchedEvnet) 方法中。
组件
好了,在说完 Controller 为会么会有这么强大的能力后,现在我们熟悉与 Controller 相关的组件吧。和 Controller 有关的源码位于文件夹 kafka.controller 下,如下图所示:
文件看起来不多,但是 Scala 语言在一个文件内会定义多个类。ControllerContext 组件上一节已经讲过了,它是存储整个集群无数据的地方。当集群发送变动,这个缓存会第一时间更新。其它 Broker 也是从这个缓存对象中获取所需要的元数据信息。
在早期,其实并没有 Controller 组件的:每个 Broker 和 Zookeeper 直接打交道,包括元数据获取、感知其它 Broker 变化情况等。当集群数量较小时工作很好,但是当数据量大了的时候就出现严重问题:
- 惊群效应。一旦某个 Broker 宕机,集群内其它 Broker 都会收到该 Watch 事件。比较网络 I/O 存在较大延迟,因此,也增加集群处于不稳定状态的时间。
- Zookeeper 脑裂。这会造成数据严重不一致。
于是,kafka 提出使用 Controller 来做集群元数据管理器,所有的 Broker 和 Controller 打交道:向 Controller 获取元数据。Controller 和 Zookeeper 打交道。这样,Controller 相当于是集群推选出来的一个总代理,借助 Zookeeper 的 watch 机制拥有迅速感知集群的元数据变化,然后主动向相关 Broker 发送 Controller 请求。这一架构减轻了 Zookeeper 压力,降低集群的延迟。但是,当整个集群拥有百万 Topic 还是会存在以下问题:
- 首先一点,Zookeeper 不适合大量的写操作,而 Zookeeper 存储整个集群所有的元数据,可想而知 Zookeeper 的写压力很变得非常大。
- 其次,Controller 故障转移后需要和 Zookeeper 进行大量的 I/O 交互,拉取集群所有元数据,导致集群不可用时间变长。虽然现在社区已经优化了,但是招架不了这庞大的数量呀。
而基于 Raft 算法就可以解决前面的问题。一是每个 Broker 相当于持有账本,Controller 往上面写了什么,其它人跟着写什么(同步)。当发生 Controller 故障转移后,新的 Controller 在历史记录的基础上添加新的 Controller 记录。这样就可以不用全量同步数据,集群的不可用时间大大缩短。
Controller 单线程事件队列处理模型
下图是对 Broker 离线事件的流程处理示意图。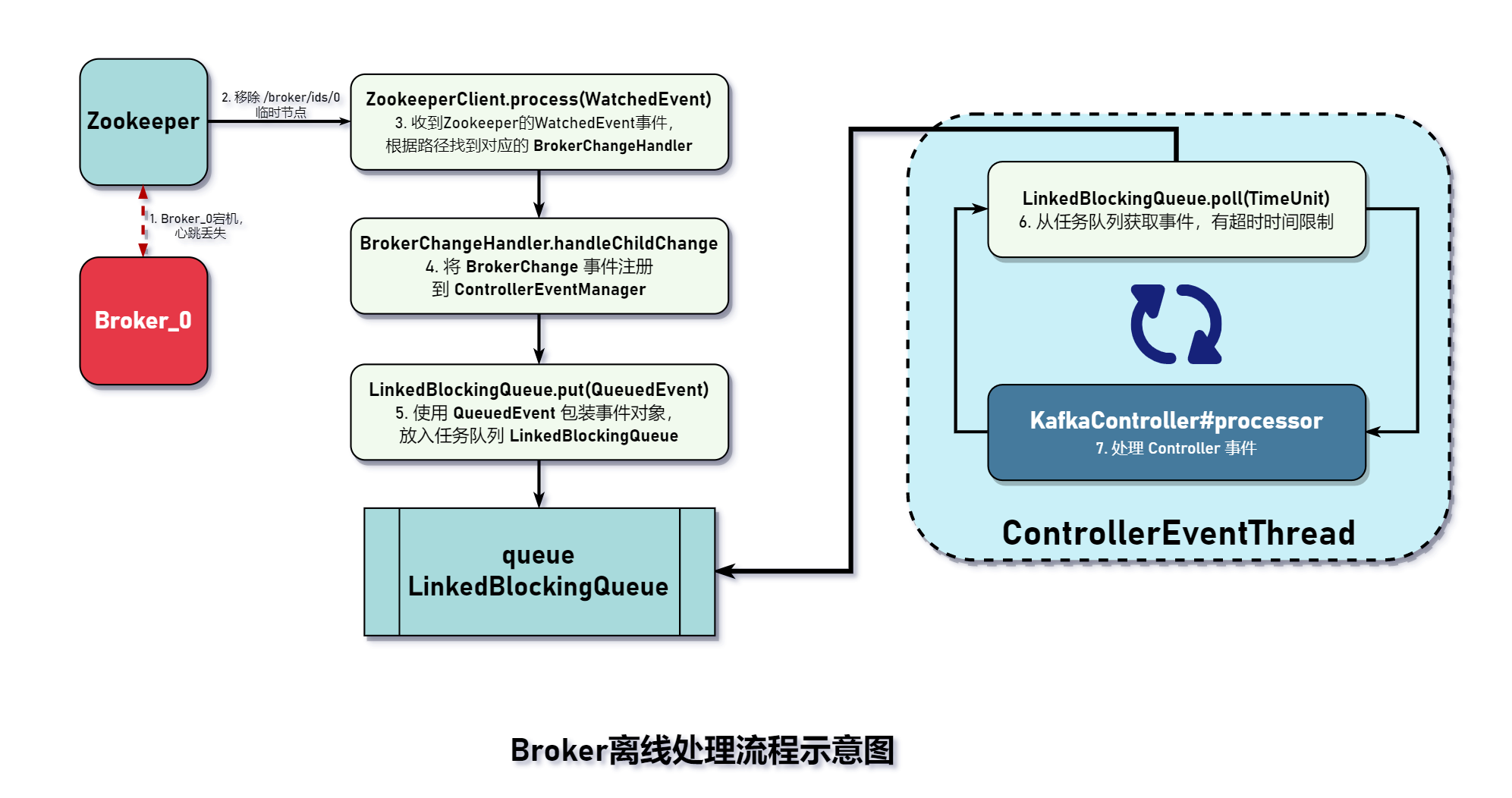
这一幅图已经将 Controller 单线程处理相关的组件都描述出来了。步骤 4 是将 Zookeeper 事件转换为 Controller 内部事件。步骤 7 是 Controller 事件的核心处理逻辑,比如 Controller 选举、Broker 离线等处理逻辑都由这个类完成。
ZookeeperClient
封装了对 Zookeeper 相关 API,比如创建节点、创建节点并添加 Watch、删除节点和判断节点是否存在等等便捷的方法。它是 Kafka 和 Zookeeper 交流的类。我们只需要知道这一点就好了。这里只贴出重要的变量和方法。
// kafka.zookeeper.ZooKeeperClient/*** 节点发生变化时触发的handler集合* key:Zookeeper对应的节点路径,value:路径变更后调用的处理方法*/private val zNodeChangeHandlers = new ConcurrentHashMap[String, ZNodeChangeHandler]().asScala/*** 子节点发生变化时触发的handler集合*/private val zNodeChildChangeHandlers = new ConcurrentHashMap[String, ZNodeChildChangeHandler]().asScala// 状态处理器,主要用于Zookeeper session 过期private val stateChangeHandlers = new ConcurrentHashMap[String, StateChangeHandler]().asScala
ZookeeperClient 有三个变量缓存不同类型的 ChangeHandlers。zNodeChangeHandlers 缓存节点变化的 Handlers,zNodeChildChangeHandlers 缓存子节点变化的 handlers,而 stateChangeHandlers 缓存 Zookeeper 状态处理器。比如和 Zookeeper Session 会话过期就会调用缓存的 stateChangeHandlers 做处理。
当创建 Zookeeper 对象时,需要传入一个 Watcher 实现类:
zooKeeper = new ZooKeeper(connectString, sessionTimeoutMs, ZooKeeperClientWatcher, clientConfig)
当 Zookeeper 节点发生变更时,就会执行 ZookeeperClientWatcher#process(WatchedEvent) 回调函数:
/*** Zookeeper监听器,继承Zookeeper提供的 {@link Watcher} 接口* 实现 {@link Watcher.processor} 方法*/private[zookeeper] object ZooKeeperClientWatcher extends Watcher {/*** 处理Zookeeper的事件,从相应集合中找到合适的Handler处理响应** @param event Zookeeper事件*/override def process(event: WatchedEvent): Unit = {debug(s"Received event: $event")// 核心步骤是根据 路径+EventType匹配HandlerOption(event.getPath) match {case None =>// 没有路径,表明是状态改变,比如认证失败,但最常见的是会话过期val state = event.getStatestateToMeterMap.get(state).foreach(_.mark())inLock(isConnectedOrExpiredLock) {isConnectedOrExpiredCondition.signalAll()}if (state == KeeperState.AuthFailed) {// 认证失败error("Auth failed.")stateChangeHandlers.values.foreach(_.onAuthFailure())// If this is during initial startup, we fail fast. Otherwise, schedule retry.val initialized = inLock(isConnectedOrExpiredLock) {isFirstConnectionEstablished}if (initialized)scheduleReinitialize("auth-failed", "Reinitializing due to auth failure.", RetryBackoffMs)} else if (state == KeeperState.Expired) {// 会话过期scheduleReinitialize("session-expired", "Session expired.", delayMs = 0L)}case Some(path) =>// 根据事件类型从缓存中获取对应的handler处理器并回调相关方法(event.getType: @unchecked) match {// 子节点数据变更事件case EventType.NodeChildrenChanged => zNodeChildChangeHandlers.get(path).foreach(_.handleChildChange())// 节点被创建事件case EventType.NodeCreated => zNodeChangeHandlers.get(path).foreach(_.handleCreation())// 节点被删除事件case EventType.NodeDeleted => zNodeChangeHandlers.get(path).foreach(_.handleDeletion())// 节点数据变更事件case EventType.NodeDataChanged => zNodeChangeHandlers.get(path).foreach(_.handleDataChange())}}}}
Zookeeper 提供的 WatchedEvent 对象包含丰富的监听信息:
// org.apache.zookeeper.WatchedEventpublic class WatchedEvent {// 连接状态:过期(Expired)、关闭(Closed)等等final private KeeperState keeperState;// 事件类型:创建节点(NodeCreated)、删除节点(NodeDeleted)、// 节点数据发生变化(NodeDataChanged)、子节点发生变化(NodeChildrenChanged)等等final private EventType eventType;// 产生事件的路径private String path;}
可以根据 KeeperState 判断当前会话状态,遇到认证失败或会话过期则执行相关逻辑,这里就不在细说。根据路径 path 和 EventType 事件类型从对应的 zNodeChildChangeHandlers 和 zNodeChangeHandlers 集合中获取处理器并调用相关方法。比如子节点 /broker/ids 数据发生删除事件,那么根据 /brokers/ids 从 zNodeChildChangeHandlers 获取 BrokerChangeHandler 处理器,然后根据事件类型 NodeChildrenChanged 调用 BrokerChangeHandler#handleChildChange() 方法。
StateChangeHandler
它是一个接口,定义了和状态相关的处理方法。
/*** Zookeeper节点变更就会触发相关回调方法*/trait ZNodeChangeHandler {/*** 对应Zookeeper的路径*/val path: String/*** 处理创建节点事件*/def handleCreation(): Unit = {}/*** 处理节点被删除事件*/def handleDeletion(): Unit = {}/*** 处理节点数据改变事件*/def handleDataChange(): Unit = {}}
一般会创建一个匿名内部类并实现方法方法,比如下面就是当启用 KafkaController 组件的时候就向 ZookeeperClient 注册一个 StateChangeHandler,不管当前 Broker 有没有当选 Controller,它都需要和 Broker 保持心跳连接,Broker 根据这个心跳连接判断是否离线。如果遇到 Zookeeper 会话过期了,Kafka 会重新创建一个 Zookeeper 客户端并建立新的连接。
// kafka.controller.KafkaController#startupdef startup() = {// #1 注册用于session过期后触发重新选举的handlerzkClient.registerStateChangeHandler(new StateChangeHandler {override val name: String = StateChangeHandlers.ControllerHandler/*** 在重新初始化session后做的操作:添加「RegisterBrokerAndReelect」事件*/override def afterInitializingSession(): Unit = {eventManager.put(RegisterBrokerAndReelect)}/*** 在重新初始化session前做的操作:添加「Expire」事件*/override def beforeInitializingSession(): Unit = {val queuedEvent = eventManager.clearAndPut(Expire)// Block initialization of the new session until the expiration event is being handled,// which ensures that all pending events have been processed before creating the new session// 阻塞等待时间被处理结束,session过期触发重新选举,必须等待选举这个时间完成Controller才能正常工作queuedEvent.awaitProcessing()}})// ...}
ZNodeChangeHandler
一个接口,这个接口定义了当 Zookeeper 节点发生数据变更而对应的处理方法。比如当创建一个新的节点就会调用 ZNodeChangeHandler#handleCreation(),节点被删除了调用 ZNodeChangeHandler#handleDeletion()。具体定义如下:
/*** Zookeeper节点变更就会触发相关回调方法*/trait ZNodeChangeHandler {/*** 对应Zookeeper的路径*/val path: String/*** 处理创建节点事件*/def handleCreation(): Unit = {}/*** 处理节点被删除事件*/def handleDeletion(): Unit = {}/*** 处理节点数据改变事件*/def handleDataChange(): Unit = {}}
实现类
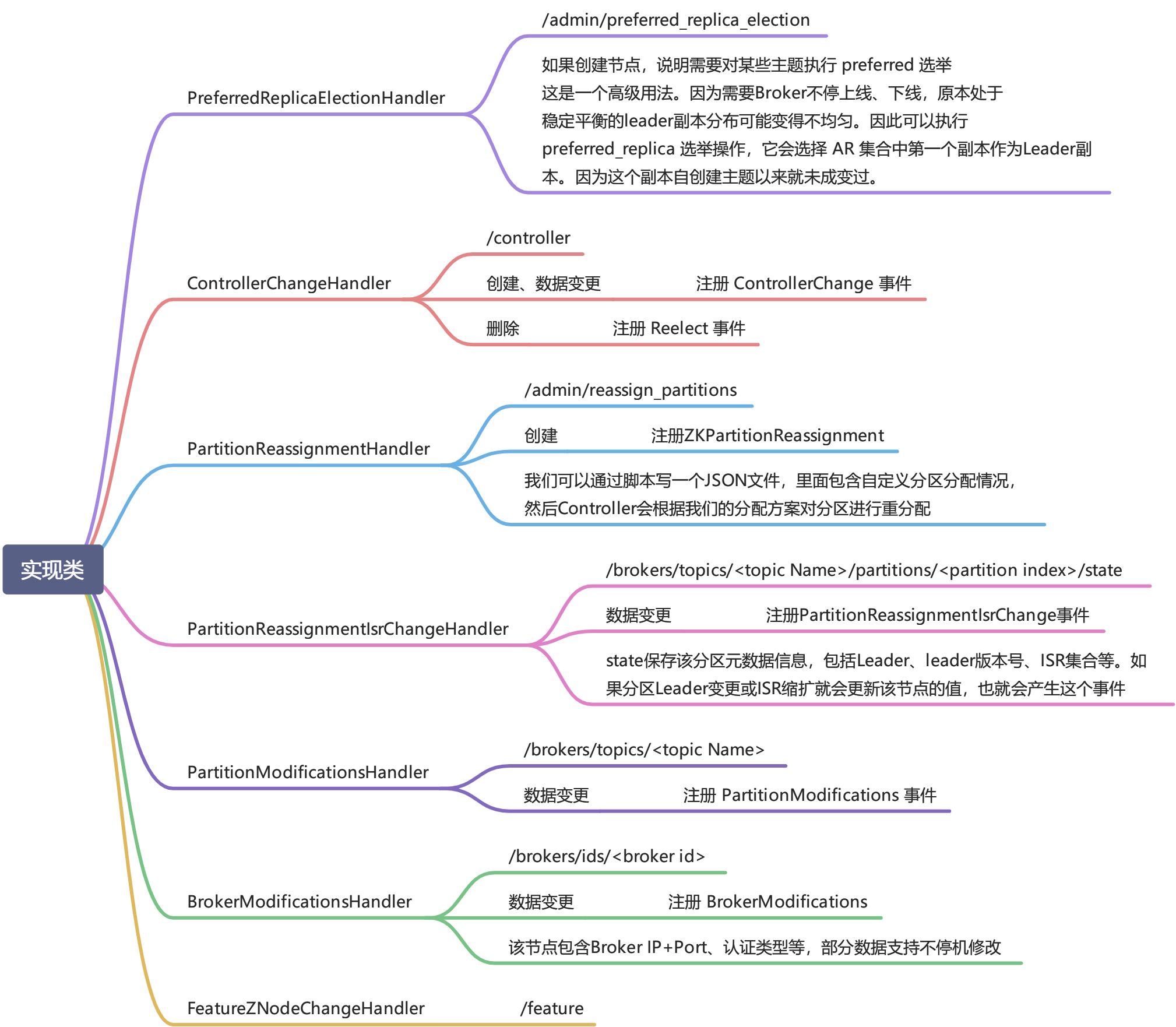
ZNodeChildChangeHandler
定义相关节点子节点发生事件所对应的回调方法:
/*** ZK中子节点变更触发器*/trait ZNodeChildChangeHandler {val path: String/*** 处理子节点变更事件*/def handleChildChange(): Unit = {}}
实现类
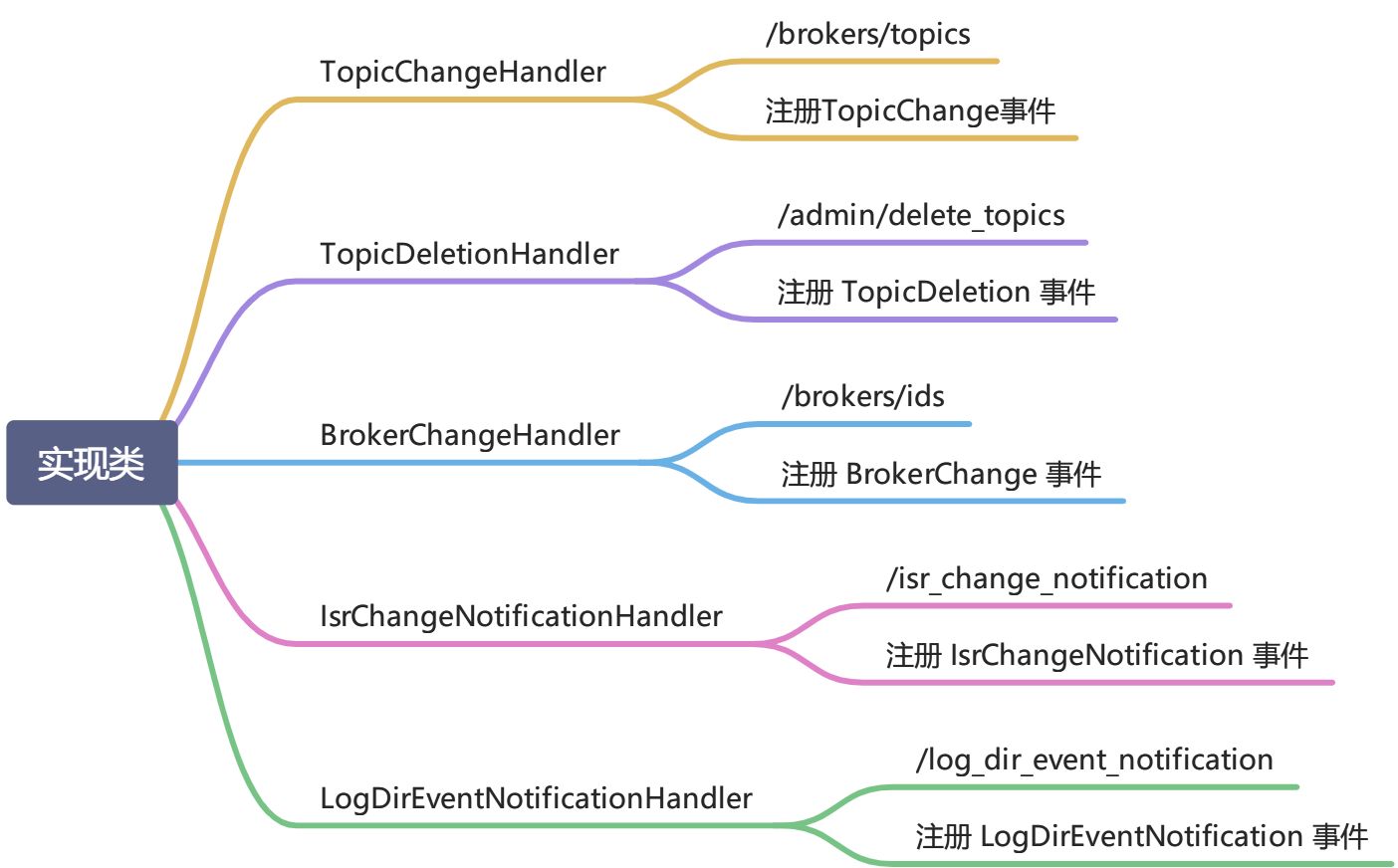
ControllerEventThread
ControllerEventThread 不断从队列中获取待处理事件,最后委托 KafkaController 完成事件处理。核心方法是 doWor() :
/*** Controller 事件处理线程核心方法:* ① 从任务队列中取出Controller事件* ② 判断事件类型是否为ShutdownEventThread,如果是,什么也不做* ③*/override def doWork(): Unit = {// #1 从事件队列中获取待处理的Controller事件(阻塞调用)val dequeued = pollFromEventQueue()dequeued.event match {// #2 如果是关闭线程事件,什么也不用做。关闭线程操作是由外部执行case ShutdownEventThread => // The shutting down of the thread has been initiated at this point. Ignore this event.case controllerEvent =>// #3 获取事件状态_state = controllerEvent.stateeventQueueTimeHist.update(time.milliseconds() - dequeued.enqueueTimeMs)try {def process(): Unit = dequeued.process(processor)rateAndTimeMetrics.get(state) match {case Some(timer) => timer.time {// #4 任务处理process()}case None => process()}} catch {case e: Throwable => error(s"Uncaught error processing event $controllerEvent", e)}_state = ControllerState.Idle}}
KafkaController
整个 Controller 最最核心的类,封装了 Controller 事件处理逻辑。相关变量源码解析如下:
/*** Controller 发送请求类型:它会给集群中所有Broker(包括它自己所在的Broker)机器发送网络请求。* Controller只会向Broker发送三类请求RPC:* ① LeaderAndIsr:告诉Broker相关主题各个分区的Leader副本位于哪台Broker、ISR位于哪些Broker。* 这是非常重要的且优先级最高的控制类请求。* ② StopReplica:告知指定的Broker停止它上面的副本对象,甚至还能删除副本底层的日志数据。* 主要的使用场景是:①分区副本迁移;②删除主题。这两个场景都涉及到停掉Broker上副本操作。* ③ UpdateMetadata:会更新Broker上的元数据缓存。集群上的所有元数据变更,都首先发生在Controller端,然后* 再经由请求广播给集群上的所有Broker。* Controller会为集群中的每个Broker创建一个对应的RequestSendTWhread线程,这个线程不断从阻塞队列中获取待发送的请求。** Controller单线程事件队列处理模型及基础组件:* ZookeeperWatcher线程/KafkaReqeustHandler线程/定时任务线程/其它线程->事件队列(一个)->ControllerEventThread线程** @param config 当前Broker配置信息* @param zkClient Zookeeper客户端* @param time 时间工具类* @param metrics 指标监控类* @param initialBrokerInfo 初始的Broker详情(从ZK中获取)* @param initialBrokerEpoch 初始的Broker版本号,用来隔离旧的Controller发送的数据,确* 保数据一致性* @param tokenManager* @param brokerFeatures* @param featureCache* @param threadNamePrefix*/class KafkaController(val config: KafkaConfig,zkClient: KafkaZkClient,time: Time,metrics: Metrics,initialBrokerInfo: BrokerInfo,initialBrokerEpoch: Long,tokenManager: DelegationTokenManager,brokerFeatures: BrokerFeatures,featureCache: FinalizedFeatureCache,threadNamePrefix: Option[String] = None)extends ControllerEventProcessor with Logging with KafkaMetricsGroup {this.logIdent = s"[Controller id=${config.brokerId}] "/*** Broker相关信息*/@volatile private var brokerInfo = initialBrokerInfo@volatile private var _brokerEpoch = initialBrokerEpochprivate val isAlterIsrEnabled = config.interBrokerProtocolVersion.isAlterIsrSupportedprivate val stateChangeLogger = new StateChangeLogger(config.brokerId, inControllerContext = true, None)/*** Controller 上下文:保存Controller元数据的容器,所有的元数据信息都封装在这个类中* 特别重要的一个类*/val controllerContext = new ControllerContext/*** 底层更接近网络层,可以理解为用于管理Controller和Broker连接的SocketChannel* 是一个微小的生产者-消费者模型(也就是有阻塞队列用于解耦)*/var controllerChannelManager = new ControllerChannelManager(controllerContext, config, time, metrics, stateChangeLogger, threadNamePrefix)// have a separate scheduler for the controller to be able to start and stop independently of the kafka server/*** 线程调度器:当前唯一负责定期执行分区重平衡Leader选举* 有一个单独的调度程序,Controller 能够独立于 kafka 服务器启动和停止*/private[controller] val kafkaScheduler = new KafkaScheduler(1)/*** Controller事件管理器,是事件处理环境所构建的生产者-消费者模型的一环* 主要是提供相关方法用于添加Controller事件(内部有一个队列存放Controller相关的事件)* 当其它线程(组件)感知到某个Controller事件发生,就会通过ControllerEventManager的API* 将事件放入到任务队列中,内部有一个单线程不断轮询并处理事件。*/private[controller] val eventManager = new ControllerEventManager(config.brokerId, this, time,controllerContext.stats.rateAndTimeMetrics)/****/private val brokerRequestBatch =new ControllerBrokerRequestBatch(config, controllerChannelManager, eventManager, controllerContext, stateChangeLogger)/*** 副本状态机:负责副本状态转换*/val replicaStateMachine: ReplicaStateMachine = new ZkReplicaStateMachine(config, stateChangeLogger, controllerContext, zkClient,new ControllerBrokerRequestBatch(config, controllerChannelManager, eventManager, controllerContext, stateChangeLogger))/*** 分区状态机:负责分区状态转换*/val partitionStateMachine: PartitionStateMachine = new ZkPartitionStateMachine(config, stateChangeLogger, controllerContext, zkClient,new ControllerBrokerRequestBatch(config, controllerChannelManager, eventManager, controllerContext, stateChangeLogger))/*** 主题移除管理器:负责删除主题及日志文件*/val topicDeletionManager = new TopicDeletionManager(config, controllerContext, replicaStateMachine,partitionStateMachine, new ControllerDeletionClient(this, zkClient))/*** 定义各种Handler,这些Handler会注册到Zookeeper的监听器。* Zookeeper第一时间感知节点发生变化,然后就会触发下面对应的Handler的执行*/// controller变更 ZK监听器:监听 /controller节点,包括创建、删除和数据变更等情况private val controllerChangeHandler = new ControllerChangeHandler(eventManager)// 「/brokers/ids」节点变更处理器private val brokerChangeHandler = new BrokerChangeHandler(eventManager)/*** Broker信息变更 ZK监听器,每个Broker对应一个BrokerModificationsHandler* 比如Broker的配置信息发生变化就会触发相关事件执行*/private val brokerModificationsHandlers: mutable.Map[Int, BrokerModificationsHandler] = mutable.Map.empty// 主题数量变更 ZK监听器private val topicChangeHandler = new TopicChangeHandler(eventManager)// 主题删除 ZK监听器:监听 /admin/delete_topics的子节点数量变更情况private val topicDeletionHandler = new TopicDeletionHandler(eventManager)// 分区变更 ZK监听器:监听主题分区数据变更的监听器,比如新增副本、分区Leader变更private val partitionModificationsHandlers: mutable.Map[String, PartitionModificationsHandler] = mutable.Map.empty/*** 分区重分配 ZK监听器:监听 /admin/reassign_partitions 节点是否被创建,如果创建则触发handler执行,* 当我们需要对Kakfa集群进行扩容以应对即将到来的大流量和业务尖峰,扩容后的Broker默认是不会有任何的分区副本,所以需要手动使用* kafka-reassign-partition.sh脚本将现有的分区副本挪一小部分到新创建的Broker中,使整个集群处于稳定的状态*/private val partitionReassignmentHandler = new PartitionReassignmentHandler(eventManager)/*** Preferred Replica选举 ZK监听器* 一旦发现新提交的任务,就为目标主题执行Preferred Leader选举*/private val preferredReplicaElectionHandler = new PreferredReplicaElectionHandler(eventManager)/*** ISR副本集合变更 ZK监听器:监听ISR副本集合变更,一旦触发,就需要获取ISR发生变更的分工列表,* 然后更新Controller端对应的Leader和ISR缓存元数据*/private val isrChangeNotificationHandler = new IsrChangeNotificationHandler(eventManager)// 日志路径变更 ZK监听器private val logDirEventNotificationHandler = new LogDirEventNotificationHandler(eventManager)// 统计相关的字段,有些监控是非常重要的// 当前Controller所在的BrokerID@volatile private var activeControllerId = -1// 离线分区数量@volatile private var offlinePartitionCount = 0// 满足Preferred Leader选举条件的总分区数量@volatile private var preferredReplicaImbalanceCount = 0// 集群主题总数@volatile private var globalTopicCount = 0// 集群分区总数@volatile private var globalPartitionCount = 0// 集群中待删除的主题总数@volatile private var topicsToDeleteCount = 0// 集群中待删除的副本总数@volatile private var replicasToDeleteCount = 0// 集群中暂时无法删除的主题总数@volatile private var ineligibleTopicsToDeleteCount = 0// 集群中暂时无法删除的副本总数@volatile private var ineligibleReplicasToDeleteCount = 0/*** 单线程调度器:用来定时删除过期的tokens*/private val tokenCleanScheduler = new KafkaScheduler(threads = 1, threadNamePrefix = "delegation-token-cleaner")//..}
炸一看,KafkaController 内部定义了茫茫多的变量,其实最重的几个变量解析如下:
| 变量名 | 说明 |
|---|---|
| controllerContext | 保存集群元数据的容器 |
| controllerChannelManager | Controller 的网络 I/O 层 |
| kafkaScheduler | 线程调度器,负责定期执行分区重平衡等操作 |
| eventManager | 事件管理器 |
| replicaStateMachine | 副本状态机,负责副本状态转换 |
| partitionStateMachine | 分区状态机,负责分区状态转换 |
核心方法当属 process(ControllerEvent):
// kafka.controller.KafkaController#processoverride def process(event: ControllerEvent): Unit = {try {event match {case event: MockEvent =>// Used only in test casesevent.process()case ShutdownEventThread =>error("Received a ShutdownEventThread event. This type of event is supposed to be handle by ControllerEventThread")case AutoPreferredReplicaLeaderElection =>processAutoPreferredReplicaLeaderElection()case ReplicaLeaderElection(partitions, electionType, electionTrigger, callback) =>processReplicaLeaderElection(partitions, electionType, electionTrigger, callback)case UncleanLeaderElectionEnable =>processUncleanLeaderElectionEnable()case TopicUncleanLeaderElectionEnable(topic) =>processTopicUncleanLeaderElectionEnable(topic)// ...}
这是一个路由方法,根据不同的 ControllerEvent 调用不同的方法处理该事件。这个方法可讲的东西太多了,后续会着重讲解:
- Broker 上线/下线。
- Controller 选举。
总结
本章节最主要的目的是熟悉 KafkaController 事件处理模型,了解 controller 通过 Zookeeper 的 watch 机制感知集群元数据变化,并通过各种 ChangeHandler 将 Zookeeper 事件转换为 Controller 内部事件,并注册到 ControllerEventManger。最终经过简易版的生产者-消费者模型,由 ControllerEventThread 线程调用KafkaChannel#process(ControllerEvent)处理 Controller 事件。附录
Zookeeper 节点数据
使用stat /controller得到以下结果:
| 字段名称 | 功能 | | —- | —- | | czxid | 创建该节点的事物ID | | ctime | 创建该节点的时间 | | mZxid | 更新该节点的事物ID | | mtime | 更新该节点的时间 | | pZxid | 操作当前节点的子节点列表的事物ID(这种操作包含增加子节点,删除子节点) | | cversion | 当前节点的子节点版本号 | | dataVersion | 当前节点的数据版本号 | | aclVersion | 当前节点的acl权限版本号 | | ephemeralOwner | 当前节点的如果是临时节点,该属性是临时节点的事物ID | | dataLength | 当前节点的d的数据长度 | | numChildren | 当前节点的子节点个数 |cZxid = 0x59ctime = Thu Jun 03 16:44:56 CST 2021mZxid = 0x5cmtime = Fri Jun 04 07:51:03 CST 2021pZxid = 0x59cversion = 0dataVersion = 1aclVersion = 0ephemeralOwner = 0x1000a0997b90007dataLength = 54numChildren = 0
使用 get [path] 命令获取节点数据内容:
get /controller{"version":1,"brokerid":1,"timestamp":"1622569390846"}
| 字段名称 | 功能 |
|---|---|
| version | Controller 版本号 |
| brokerid | Controller所在的Broker ID |
| timestamp | Controller 创建时间 |
ZK 上 /brokers/ids 节点状态:
cZxid = 0x5ctime = Thu Jun 03 16:36:22 CST 2021mZxid = 0x5mtime = Thu Jun 03 16:36:22 CST 2021pZxid = 0x6dcversion = 15dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 0numChildren = 1
ZK 上 /brokers/ids/1 节点数据:
{"features": {},"listener_security_protocol_map": {"PLAINTEXT": "PLAINTEXT"},"endpoints": ["PLAINTEXT://192.168.217.128:9092"],"jmx_port": -1,"port": 9092,"host": "192.168.217.128","version": 5,"timestamp": "1622653209620"}
ZK 上 /brokers/ids/1 节点状态:
cZxid = 0x6dctime = Fri Jun 04 14:14:28 CST 2021mZxid = 0x6dmtime = Fri Jun 04 14:14:28 CST 2021pZxid = 0x6dcversion = 0dataVersion = 1aclVersion = 0ephemeralOwner = 0x1000a0997b90009dataLength = 214numChildren = 0
ZK 上 /brokers/topics 节点状态:
cZxid = 0x6ctime = Thu Jun 03 16:36:22 CST 2021mZxid = 0x6mtime = Thu Jun 03 16:36:22 CST 2021pZxid = 0x21cversion = 1dataVersion = 0aclVersion = 0ephemeralOwner = 0x0dataLength = 0numChildren = 1
ZK 上 /brokers/topics 节点数据
[james]
ZK 上 /brokers/topics/james 节点状态:
cZxid = 0x21ctime = Thu Jun 03 16:37:00 CST 2021mZxid = 0x45mtime = Thu Jun 03 16:44:04 CST 2021pZxid = 0x22cversion = 1dataVersion = 1aclVersion = 0ephemeralOwner = 0x0dataLength = 116numChildren = 1
ZK 上 /brokers/topics/james 节点数据:
{"partitions": {"0": [1]},"topic_id": "yR4JWjUESDexyuZ9yIIFVg","adding_replicas": {},"removing_replicas": {},"version": 3}
当然,james 下面还包含子节点 /partitions/[分区ID号]/state,比如 /brokers/topics/james/partitions/0/state 节点数据为:
{"controller_epoch": 4,"leader": 1,"version": 1,"leader_epoch": 2,"isr": [1]}
节点 /brokers/topics/james/partitions/0/state 节点详情
cZxid = 0x24ctime = Thu Jun 03 16:37:00 CST 2021mZxid = 0x5amtime = Thu Jun 03 16:44:57 CST 2021pZxid = 0x24cversion = 0dataVersion = 2aclVersion = 0ephemeralOwner = 0x0dataLength = 72numChildren = 0

若有收获,就点个赞吧
0 人点赞
