事务流程概述
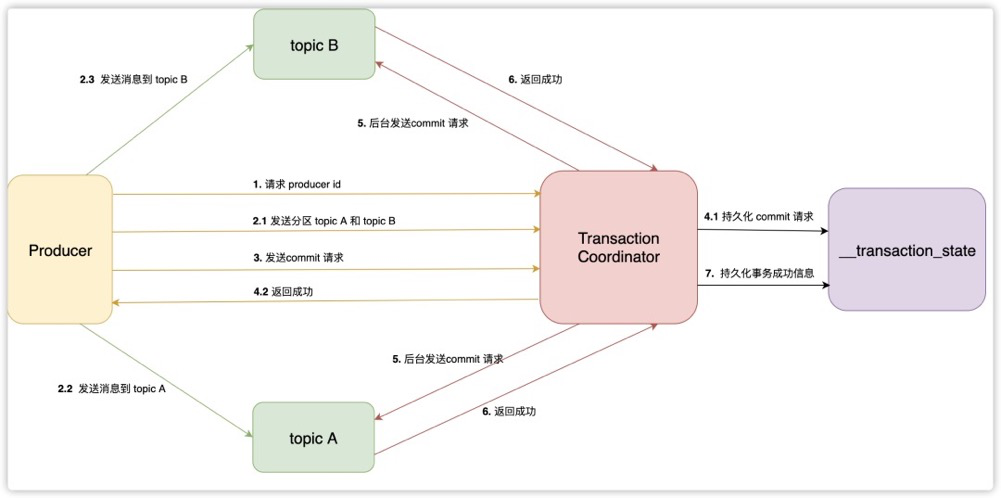
步骤说明:
- 首先需要获取
producer id,简称 pid。然后再向 TC 发送分区 topicA 和 topicB,让 TC 将 pid 和这两个分区进行绑定。 - 随后 producer 向 topicA 和 topicB 发送消息。发送完成后,再向 TC 发送 commit 请求(步骤 3)。
- TC 将 commit 元数据持久化至
__transaction_state内部主题中,并向 producer 返回成功。随后后台分别向 topicA 和 topicB 发送 commit 请求。 - topicA 和 topicB 分别向 TC 返回成功消息。TC 收到后再向
__transaction_state持久化事务成功的消息。
步骤总结:
- Producer:它需要发送 4 种类型的请求,分别是:① 向 TC 获取 PID 请求。② 向 TC 发送分区元数据。③ 向目标分区发送消息。④ 向 TC 发送 commit 请求。
- TC:它需要进行两次持久化元数据信息操作和一次发送 commit 请求操作。① 当收到 Producer 的 commit 消息,需要将这些元数据第一次持久化至内部主题
__transaction_state日志文件中。② 当收到本次事务关联的其它分区的成功消息后,需要持久化事务成功的消息。 涉及的主题:① 接收 Producer 消息。② 接收 TC 的 commit 消息并持久化至文件中,然后返回成功。
① Producer 如何寻找 TC
只有
transaction id(tid)是和 TC 绑定在一起的。如果已经存在tid,那么可以根据tid向 Kafka 集群中任意节点发送FindCoordinatorRequest请求,获取其对应的 TC。
如果示存在tid,则会随机分配一个 TC 负责管理这次事务操作。② 事务初始化
幂等需要 PID,事务需要 TID。这个值的获取都属于事务初始化。
事务 Producer 在initializeTransaction()方法中向 TC 发送InitPidRequest请求获取它分配的 PID。TC 在分配 PID 时会做以下判断:初始化或恢复 TID 之前状态(TransactionMetadata)。如果 TID 之前有事务状态,获取之前的状态,包括旧的 PID。否则,初始化事务元数据信息:① 分配一个新的 PID。② epoch = -1。
- 校验 TransactionMetadata 元数据(
prepareInitProducerIdTransit())。- 如果前面有状态转移正在进行,直接返回
CONCURRENT_TRANSACTIONS异常,表示出现并发事务。 - 先前状态为
PrepareAbort或prepareCommit,返回CONCURRENT_TRANSACTIONS异常。 - 先前状态为
CompleteAbort、CompleteCommit或Empty,那么先将状态变更为Empty,再更新epoch。 - 先前状态为
Ongoing,状态变更为PrepareEpochFence,然后再中止当前事务,返回CONCURRENT_TRANSACTIONS异常。 - 先前状态为
Dead或PrepareEpochFence,抛出FATAL异常。
- 如果前面有状态转移正在进行,直接返回
- 将 TID 和 相应的 TransactionMetadata 元数据持久化至事务日志中。持久化的数据主要是 TID 和 PID 关系信息。
③ 发送消息
Producer 在接收 PID 后,还需要将相关元数据信息上传到 TC 中,待成功后才可以向目标 topic 发送消息。消息与普通消息不同,内部有一个字段标识这是事务消息。④ 发送 commit 请求
Producer 发送完消息后,如果认为事务可被提交,就会发送 commit 请求到 TC 服务。TC 服务收到 commit 请求后,会将提交信息持久化至事务 topic。随后立即发送成功响应给 producer。然后再找到该事务涉及到所有的分区,为每个分配生成提交请求,存到队列等待发送。后台线程会不停地从队列中获取请求并发往对应的分区。分区收到请求后,会将结果到日志文件中,并且返回成功响应。当 TC 服务收到所有分区的成功响应后,生成一条事务完成的消息并持久化至事务 topic。至此,一个完整的事务消息发送流程就结束了。
Transaction Log
和位移主题 __consumer_topic 一样,Kafka 也是使用日志文件存储 Kafka 事务数据,__transaction_state 也是 Kafka 内部主题之一,默认有 50 个分区,每个分区拥有 3 个副本,通过 hash(txn.id) 计算每个事务 ID 位于哪个分区上。__transaction_state 主题是由 TransactionCoordinator 管理,常见的操作是写入数据和读取日志恢复恢复状态,这样就能保证跨会话、跨分区的能力,使得 Kafka 事务拥有比幂等更强的数据一致性。
Key => Version TransactionalIdVersion => 0 (int16)TransactionalId => StringValue => Version ProducerId ProducerEpoch TxnTimeoutDuration TxnStatus [TxnPartitions] TxnEntryLastUpdateTime TxnStartTimeVersion => 0 (int16)ProducerId => int64ProducerEpoch => int16TxnTimeoutDuration => int32TxnStatus => int8TxnPartitions => [Topic [Partition]]Topic => StringPartition => int32TxnLastUpdateTime => int64TxnStartTime => int64
Demo
// 创建 Producer 实例,并且指定 transaction idKafkaProducer producer = createKafkaProducer(“bootstrap.servers”, “localhost:9092”,“transactional.id”, “my-transactional-id”);// 初始化事务,这里会向 TC 服务申请 producer idproducer.initTransactions();// 创建 Consumer 实例,并且订阅 topicKafkaConsumer consumer = createKafkaConsumer(“bootstrap.servers”, “localhost:9092”,“group.id”, “my-group-id”,"isolation.level", "read_committed");consumer.subscribe(singleton(“inputTopic”));while (true) {ConsumerRecords records = consumer.poll(Long.MAX_VALUE);// 开始新的事务producer.beginTransaction();for (ConsumerRecord record : records) {// 发送消息到分区producer.send(producerRecord(“outputTopic_1”, record));producer.send(producerRecord(“outputTopic_2”, record));}// 提交 offsetproducer.sendOffsetsToTransaction(currentOffsets(consumer), "my-group-id");// 提交事务producer.commitTransaction();}
运行原理
客户端
TransactionManager 负责维护 Producer 侧的事务状态。上图就是 Produer 事务状态机转换示意图。 TransactionManager 类会向 TC 申请 PID 请求、上传消息分区请求和事务提交请求。每完成一步,TransactionManager 都会更新自身状态。
服务端
TC 服务为每个 transaction id(以下简称 tid)都维护了元数据,使用 TransactionMetadata 对象存储:
/**** @param producerId Producer ID* @param lastProducerId 最后分配给生产者的 producer id* @param producerEpoch 生产者版本号* @param lastProducerEpoch 最后的生产者版本号* @param txnTimeoutMs 事务超时时间* @param state 当前事务状态* @param topicPartitions 参与本次事务的所有主题分区* @param txnStartTimestamp 事务开始时间:第一个分区添加时间* @param txnLastUpdateTimestamp 事务元数据更新时间*/@nonthreadsafeclass TransactionMetadata(val transactionalId: String,var producerId: Long,var lastProducerId: Long,var producerEpoch: Short,var lastProducerEpoch: Short,var txnTimeoutMs: Int,var state: TransactionState,val topicPartitions: mutable.Set[TopicPartition],@volatile var txnStartTimestamp: Long = -1,@volatile var txnLastUpdateTimestamp: Long) extends Logging {
对于服务羰,每个步骤也会有对应的状态:
事务的开始是 TC 收到来自 Producer 发送的第一个分区的请求。TC 会更新分区列表,更新此次的事务开始时间为当前时间,并且会将更新后的元数据持久化到事务 topic,最后将事务状态变更为 Ongoing。
高可用分析
TC 服务
Kafka 集群运行多个 TC 服务,每个 TC 服务负责事务 topic 的一个分区读写,也就是这个分区的 Leader。所以 TC 服务是具备高可用的。
Producer 根据 transaction id 的哈希值来决定这个事务属于事务 topic 的哪个分区,然后再找到该分区的 Leader 位置,也就找到了 TC 。
消息持久化
TC 服务支持重启后仍然可以恢复到之前的状态,主要依赖将每次将重要的数据都会持久化至日志主题中,并且设置 ack=all。这样每次 TC 服务启动时,都会从事务 topic 读取之前的状态并加载到缓存里。比如 TC 在客户端事务提交请求后,还未来得及向和分区发送事务结果请求,就宕机了。之后 TC 服务重启,先加载事务 topic,发现事务的最后状态为 PrepareCommit,并且事务数据包含分区列表。这样 TC 服务会继续执行未完成事务的剩余流程:向各个分区发送事务结果请求。
超时处理
TC 服务有一个线程专门定期检查处理 Ongoing 状态的事务。如果该事务的开始时间和当前时间差值超过了指定的超时时间,那么 TC 服务就会回滚该事务,更新和持久化事务的状态,并且向分区列表发送事务回滚。
源码分析
客户端
下面是 Producer 与事务相关的接口:
public interface Producer<K, V> extends Closeable {// 初始化事务,包括申请 producer idvoid initTransactions();// 开始事务,这里会更改事务的本地状态void beginTransaction() throws ProducerFencedException;// 提交消费位置, offsets表示每个分区的消费位置, consumerGroupId表示消费组的名称void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws ProducerFencedException;// 发送事务提交请求void commitTransaction() throws ProducerFencedException;// 发送事务回滚请求void abortTransaction() throws ProducerFencedException;}
实现类比较简单,都是调用了 TransactionCoordinator 类中的方法。下面表格是请求类型与处理类关系图:
| 请求类型 | 请求类 | 响应处理类 |
|---|---|---|
| 寻找 TC 服务地址 | FindCoordinatorRequest | FindCoordinatorHandler |
| 事务初始化请求 | InitProducerIdRequest | InitProducerHandler |
| 消费位置提交请求 | TxnOffsetCommitRequest | TxnOffsetCommitHandler |
| 事务分区上传请求 | AddPartitionsToTxnRequest | AddPartitionsToTxnHandler |
| 事务提交或回滚 | EndTxnReqeust | EndTxnHandler |
TransactionCoordinator 发送的请求类,都有一个对应的类来处理响应。这些处理类都是继承 TxnRequestHandler 类,它封装了共同的错误处理,比如连接断开,api 版本不兼容等。子类需要实现 handleResponse 方法,负责处理具体的响应内容。
我们知道Producer发送消息,都是先将消息发送到缓存队列里,最后是由Sender线程发送出去 。Producer 如果开启了事务, 它在发送消息到缓存之前,会将消息所在的分区保存在 TransactionCoordinator 里。然后Sender线程在发送消息之前,会去从 TransactionCoordinator 检查是否需要上次分区到 TC 服务,如果有就先上次分区,随后才发送消息。
服务端
这里需要提下延迟任务 DelayedTxnMarker,它负责检查是否收到所有分区的响应。它设置的延迟时间达到 365 天,所以可以认为次任务几乎不会过期。
Transaction Marker 机制
Produer 发送 Commit 请求给 TransactionCoordinator,然后 TransactionCoordinator 向其涉及的分区 leader 发送 Transaction Marker 相关标记数据(优化一:共享 TCP 连接)。Leader 收到数据后正常写入日志中,当收到 Transaction Marker 相关数据后,也将该数据直接写入日志上。当消费者消费时,可以根据这个标记做相应处理。
ControlMessageKey => Version ControlMessageTypeVersion => int16ControlMessageType => int16TransactionControlMessageValue => Version CoordinatorEpochVersion => int16CoordinatorEpoch => int32
事务状态
客户端
- UNINITIALIZED:Transactional Producer 初始化时的状态,此时还没有事务处理;
- INITIALIZING:Transactional Producer 调用 initTransactions() 方法初始化事务相关的内容,比如发送 InitProducerIdRequest 请求;
- READY:对于新建的事务,Transactional Producer 收到来自 TransactionCoordinator 的 InitProducerIdResponse 后,其状态会置为 READY(对于已有的事务而言,是当前事务完成后 Client 的状态会转移为 READY);
- IN_TRANSACTION:Transactional Producer 调用 beginTransaction() 方法,开始一个事务,标志着一个事务开始初始化;
- COMMITTING_TRANSACTION:Transactional Producer 调用 commitTransaction() 方法时,会先更新本地的状态信息;
- ABORTING_TRANSACTION:Transactional Producer 调用 abortTransaction() 方法时,会先更新本地的状态信息;
- ABORTABLE_ERROR:在一个事务操作中,如果有数据发送失败,本地状态会转移到这个状态,之后再自动 abort 事务;
- FATAL_ERROR:转移到这个状态之后,再进行状态转移时,会抛出异常;
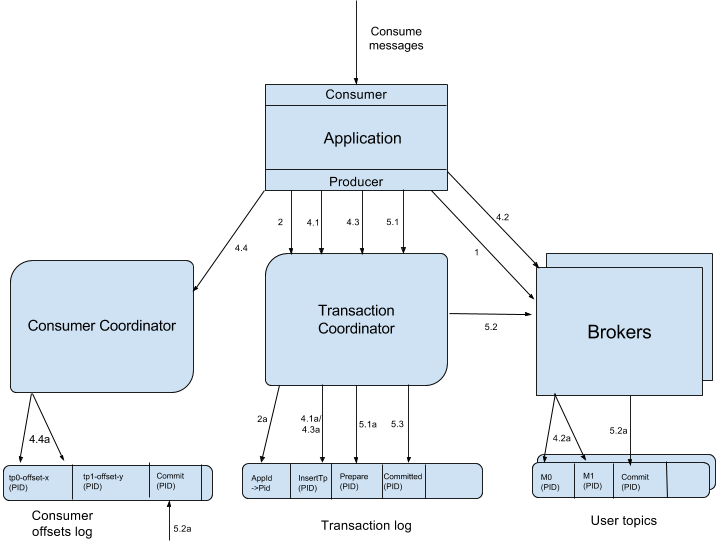
- 向负载节点最小的 Broker 发送
FindCoordinatorRequest请求:寻找一个事务协调器。 - 向事务协调器发送
InitPidRequest请求:获取一个 PID(producer ID)。获取 PID 的过程会出现以下两种情况:- 如果 TransactionId 指定,那么
InitPidRequest请求会带上这个值。事务协调器会将这个值在日志文件中进行匹配(2a)并获取与 TransactionId 对应的 PID。当 Producer 宕机重启后可以获得相同的 PID 以便恢复或回滚之前未完成的事务。InitPidRequest请求的处理是同步的,一旦返回,生产者可以发送数据并开始事务。除了返回 PID 值以外,请求InitPidReqeust还会完成以下任务- 将 PID 的版本号
+1,避免 zombie Producer。 - 恢复(前滚或回滚)前一个生产者实例未完成的任何事务。
- 将 PID 的版本号
- 如果 TransactionId 未指定,事务协调器会给该 Producer 生成一个新的 PID,该生产者只能拥有幂等语义和单会话事务语义。
- 如果 TransactionId 指定,那么
- 开启一个事务:
beginTransaction()。对 Producer 来说,会变更本地事务状态(设置为IN_TRANSACTION),但对事务协调器而言,它只会在收到第一个记录后才会变更相应事务的状态。 - consume-transform-produce 循环
- AddPartitionToTxnRequest:Producer 调用
Producer#send()方法时会将 TopicPartition 信息添加到本地事务管理器 TransactionManager 缓存中,随后将这个信息通过AddPartitionToTxnRequest请求发送给事务协调器。事务协调器会将这个分区列表更新到txn.id对应的 TransactionMetadata 中,并且持久化至事务日志中(4.1a)。 ProducerReqeust:和正常的生产者写入消息是一样的。主要区别是在持久化消息时会在消息头部放入一个事务标识,表示该条消息是事务Producer发送过来的。AddOffsetsToTxnRequst:这个请求是在consumer-transform-producer场景中才会用到。目的是构造端到端的 EOS。当 Producer 调用sendOffsetsToTransaction()方法时,- 向事务协调器发送相应的
AddOffsetsToTxnRequest请求。 - 事务管理器收到该请求后,将这个
group.id对应的__consumer_offsets的分区保存到事务对应的 TransactionMetadata 中,再持久化至本地日志中。
- 向事务协调器发送相应的
- TxnOffseetsCommitRequest:Producer 收到
AddOffsetsToTxnRequest响应后,会两次发送TxnOffsetsCommitRequest请求给消费组协调器(GroupCoordinator),消费组协调器收到请求后,会将 offset 信息持久化到__consumer_offset日志文件中,并包含对应的 PID 信息,此时不会更新缓存,除非这个事务提交。这样就能保证这个 offset 信息对 consummer 是不可见的。
- AddPartitionToTxnRequest:Producer 调用
- 提交或回滚一个事务。在一个事务操作完成后,Producer 需要调用
commitTransaction()或者abortTransaction()方法来提交或回滚事务操作。EndTxnRequest:无论提交或回滚都是由这个 RPC 请求发送的。里面有一个标识位标识这次请求是提交还是回滚操作。- 事务协调器收到
EndTxnRequest扣,会做以下处理:- 更新该事务的元数据信息。① 事务状态变更为
PREPARE_COMMIT或PREPARE_ABORT,并将事务状态持久化至事务日志中。 - 根据事务元数据信息,向其涉及到的所有分区的 Leader 发送
Transaction Marker信息(即 WriteTxnMarkerRequest 请求)。 - 最后将事务状态变更为
COMMIT或ABORT,并将事务的元数据信息持久化到事务日志中。
- 更新该事务的元数据信息。① 事务状态变更为
WriteTxnMarkerRequest:主要告诉本次事务所涉及的分区 Leader 该事务已经可以提交或回滚了,分区 Leader 收到该请求后会将将事务结果持久化到本地日志文件中。这样消费者消费这个数据时就知道事务是已提交或已回滚。- Writing the Final Commit or Abort Message:当这个事务涉及到所有分区都已经把这个 marker 标记信息持久化到本地日志文件后,事务协调器会将这个事务的状态变更为
COMMIT或ABORT,并持久化到事务日志文件中。到这一步,这个事务才算真正完成。相关缓存数据可以被移除。
多个 Producer 使用同一个 txn.id 会出现最后一个启动正常,其余抛出致命异常并退出程序。
Fencing 机制:在分布式场景中,在某一时刻,系统会出现脑裂。出现脑裂情况使用版本号屏蔽旧的生产者或事务协调器发送的消息。
消费者是如何消费事务消息
首先,消费者端有一个与隔离级别相关的配置参数 isolation.level。目前 Kafka 支持以下两种配置选项:
read_committed:只消费非事务消息或已提交的事务消息。按位移顺序消费。read_uncommitted:按位移顺序消费所有可获取的消息。这是默认设置。
主要难点在于 read_committed 的实现,Kafka 为了实现这一隔离级别引入了 Last Stable Offset 变量。
The LSO is defined as the latest offset such that the status of all transactional messages at lower offsets have been determined (i.e. committed or aborted). 小于 lSO 的数据被认为是全部已经确定的数据。在 LSO 偏移量之前的事务操作都是已经完成的事务。
Broker 收到 read_committed 消费者的 FETCH 请求
Broker 只会返回 LSO 之前的数据,在 LSO 之后的数据是不会返回的,因此,关于 Borker 端是如何维护 LSO 变量就变得十分重要。
消费者如何过滤 Abort 事务数据
存在消费者收到数据和 marker 分离的场景,如果消费者缓存数据直到收到 marker 标志后再处理数据,这会有 OOM 风险。因此,由 Broker 管理数据发放进度是一个比较合理的方案。那 Kafka 是怎么做的呢?
Kafka 在 Broker 端会追踪每个分区涉及到的中止事务(abort transaction),分区的每个 log segment 都会有一个单独的只写的文件(append-only file)来存储中止事务元数据。持久化至磁盘主要是为了保证高可用。文件以 .txnindex 结尾,存储的数据格式如下:
TransactionEntry =>Version => int16PID => int64FirstOffset => int64LastOffset => int64LastStableOffset => int64
有了这个中止事务元数据之后就好办了,Broker 会将这批消息所涉及到的所有 abort transaction 信息都返回给消息者(通过对比 offset 范围),消费者拿到这些数据后就可以进行相应过滤。
这部分的实现确实有些绕(有兴趣的可以慢慢咀嚼一下),它严重依赖了 Kafka 提供的下面两种保证:
- Consumer 拉取到的数据,在处理时,其 offset 是严格有序的;
- 同一个 txn.id(PID 相同)在某一个时刻最多只能有一个事务正在进行;
参考

若有收获,就点个赞吧
0 人点赞
