早上线上出现502问题,页面直接出现了502的nginx页面,bad gateway,一直以来都只见过后端的502,哪里见识过前端静态资源也会502的我瞬间就进入懵逼状态了.
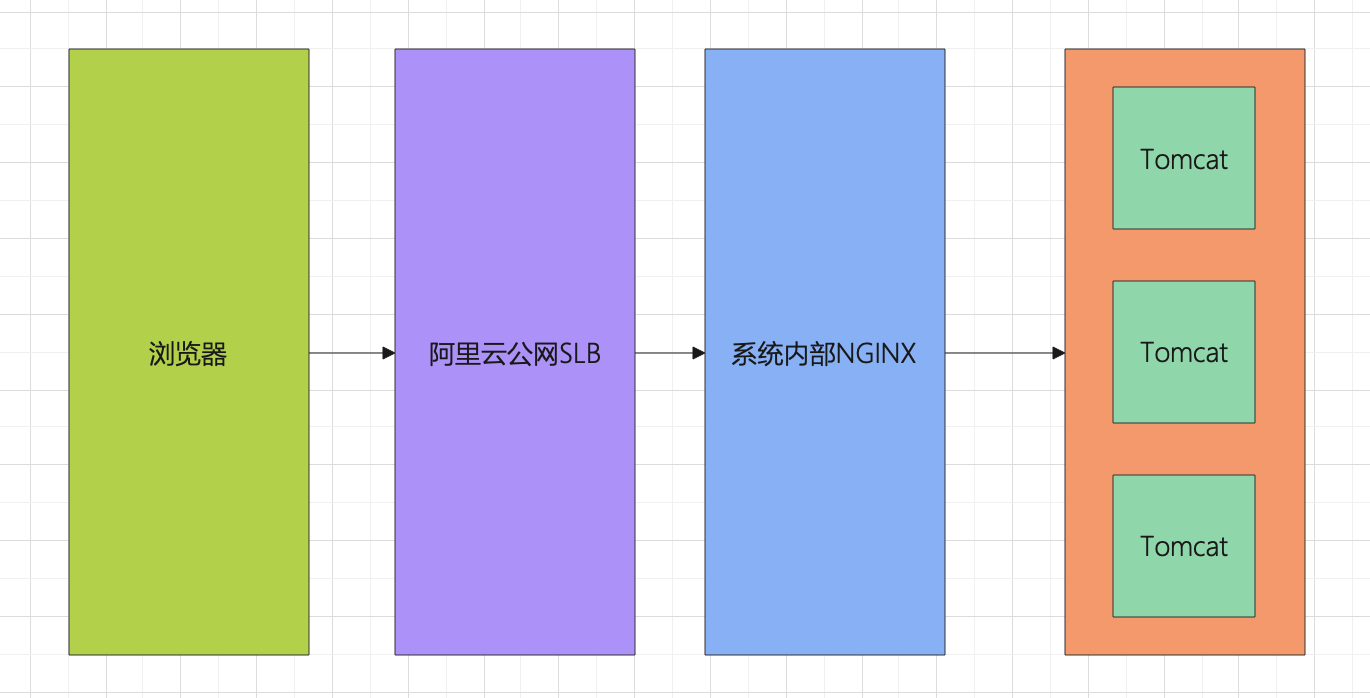
如上所示,这个是我们线上的一个网络示意图,当时我们第一时间是以为阿里云公网SLB带宽满了,其实当时看监控是正常的,以防万一,我们还是将SLB的规格升级了一档,事实证明这个操作不行,因为前端静态资源还是偶尔出现502。
同时发现内部系统NGINX CPU load很高,使用reload ,重启nginx均不能有效的降低load,为了使服务恢复只能通过
- 加机器【多加几台NGINX机器】
- 升级当前NGINX机器配置【由2C4G—->8C8G】,不过机器需要重启
权衡当时的背景【业务已经用不了的情况】,我们选择了第二项,升级配置后重启机器,升级后问题确实解决了,但是以往7天都是这样的机器配置,为什么今天就扛不住了呢
🤔
也许因为服务挂掉导致用户一直在刷导致出现的雪崩,因为出现该问题后,服务器的TCP连接数就明显上升到一个不能接受的数量了,导致公网SLB的请求直接被内核拒绝掉,页面展现出502的结果。
一开始的源头已经不可考了,也许是因为当时的定时任务导致服务器CPU高,影响到了NGINX,也许是因为用户把我们打挂了. 前者的概率大一点. 但是目前是不太重要了,看7天的监控,日常的CPU也到了50%,确实到了该升级的时候。
不过在这个过程中也暴露了几个问题
- 告警不及时,2C4G的机器load到了8竟然没有收到告警
- 响应太慢,还是对于网络拓扑掌握的不到位
解决方案
- 升级配置
- 添加机器
- 添加告警

若有收获,就点个赞吧
0 人点赞
