从ECS(虚拟机)迁移到K8S后,POD为何频繁重启,到底是人性的泯灭还是道德的沦丧,亦或是技术太菜了.
由于技术栈大部分都是Java应用切换到容器之后,相比较ECS,不少业务同学频繁向我反馈POD重启较多
这里总结常规问题
- 磁盘问题 (常见度低)
- pod的磁盘配额到到阈值
- 宿主机的整体磁盘使用率超过85%(默认值)
- 内存问题 (一般是运行一段时间之后反复重启)
- 容器内存配置过少
- 应用存在内存泄露
- 进程之间内存配置不合理
- Java内存认知不足(比重高)
- 发布配置问题 (比较常见与发布变更的时候)
- 代码配置问题导致启动失败
- 项目启动时间过长心跳检测失败
- 其他
- CPU load过高
磁盘问题
业务同学反馈某台POD一直起不来,且其他宿主机上的POD正常启动中. 手动上机器
df -h# 发现磁盘将满
在磁盘使用超过85%时,POD就会启动不起来. 删除部分磁盘文件即可
如果给POD配置了磁盘上限,当POD达到了磁盘上限之后呢,就会被 驱逐
内存问题
内存问题出现在POD中的情况比较多. 因为我们使用的是JDK8,对于容器的支持还不够完善,并且对应JVM的内存理解不够申请,这个时候出现的比较多.
容器配置内存过少
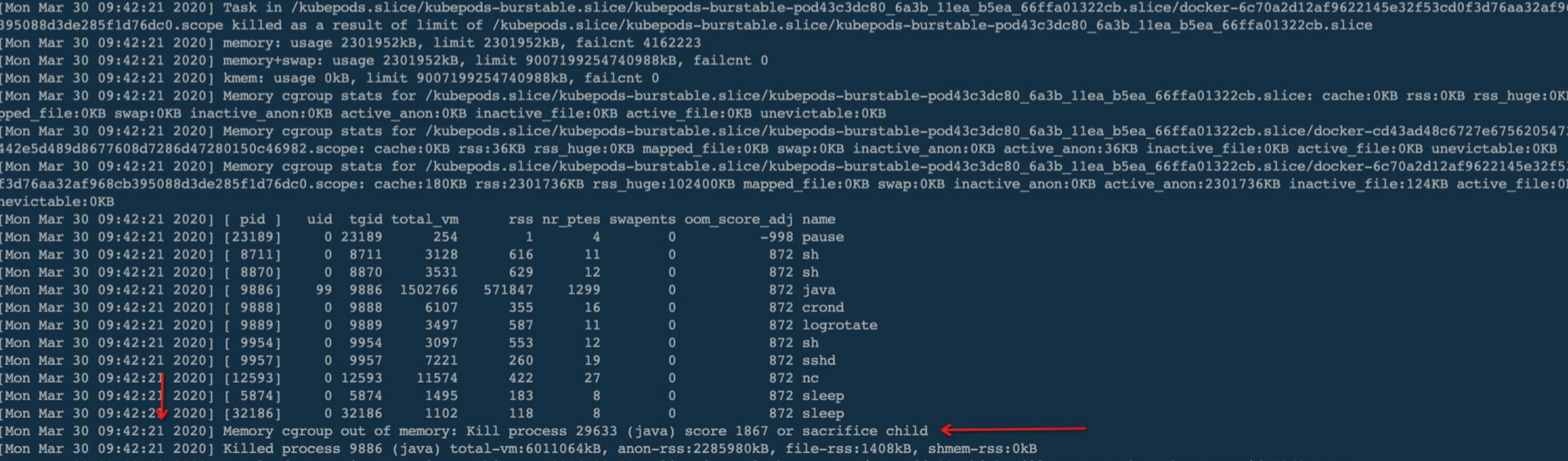
通过catalina.out和线上日志发现,Tomcat每每跑到一半就直接退出,日志也没有错误,一度怀疑是存在System.exit的情况,ps也没有发现java进程,可以通过dmesg -T 查看是否发生过oom killer 可以确定是否是内存过少.
应用内存泄漏
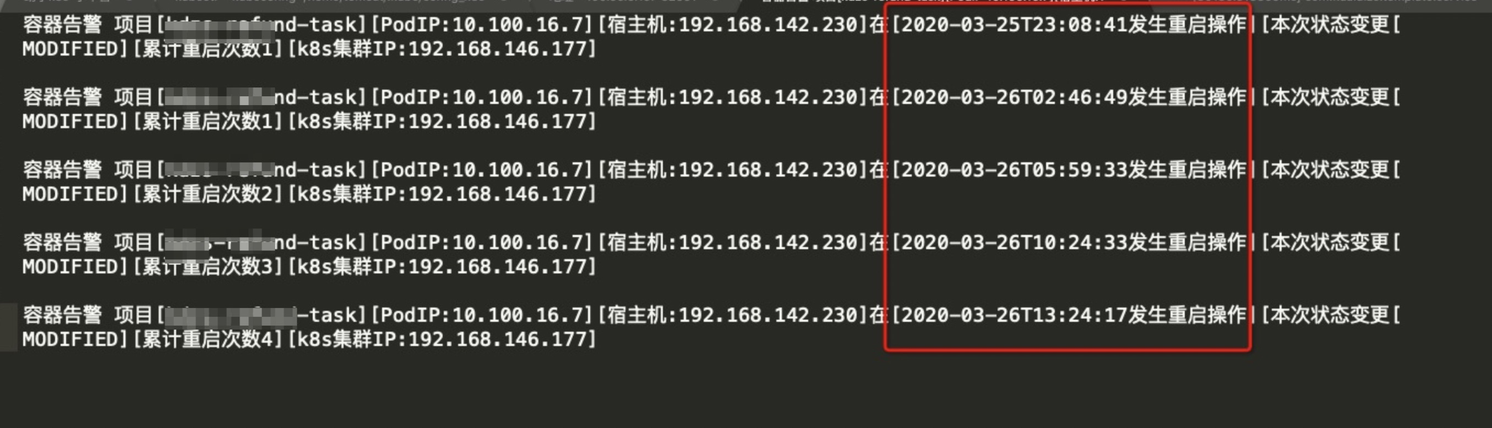
迁移到聚石塔容器以后,发现一个项目每隔3/4个小时进行重启,经过dump文件分析发现使用https导致了内存增长,修改成http走内网后,问题解决,业务反馈持续2天尚未发生过重启.
进程之间内存配置不合理
某个业务使用到一些作图工具生成图片,应用从ECS迁移到容器后,一个POD一天可以重启10多次,内存limit一度配置到了4296M,-Xmx配置了4G也不能解决重启问题. 后续在和业务方交流后,将Java进程内存配置为-Xmx712M,limit配置成2500M后解决重启问题,业务方反馈持续多天未重启
Java内存认知不足
在迁移之初,在ECS上-Xmx512M都能跑的好好的,可以到容器上就频繁重启
举个例子
Request:memory: 612Milimit:memory: 812Mi
这个是K8s的内存配置,设置最小612M,最大812M. 相比于我们平常跑的Java应用512M还是有余的.
-Xmx512M -Xms256M
以这种情况配置完运行后POD就开始重启不断了,厉害的时候可以跑到一天重启个7/8次.
在这种情况下开始了第一次调整. 首先将Yaml文件配置的Limit调大. 实验下来该动作确实有效,但过了一阵问题就开始暴露出来了,大家都将Limit调大,当大家一起用但时候,Limit会超出ECS的内存很多G. 经过我观察,超个2/3G是常有的事,晚上还好,一到高峰期,ECS就开始OOM Kill了
于是开启了第二次调整,首先要弄明白内存去哪里了. 为什么明明使用的很少,但是监控却显示我用了这么多,为什么top显示的比我配置要高很多.
- 明明就配置了-Xmx800M,为什么top显示RES 1G
先使用 Arthas 查看大盘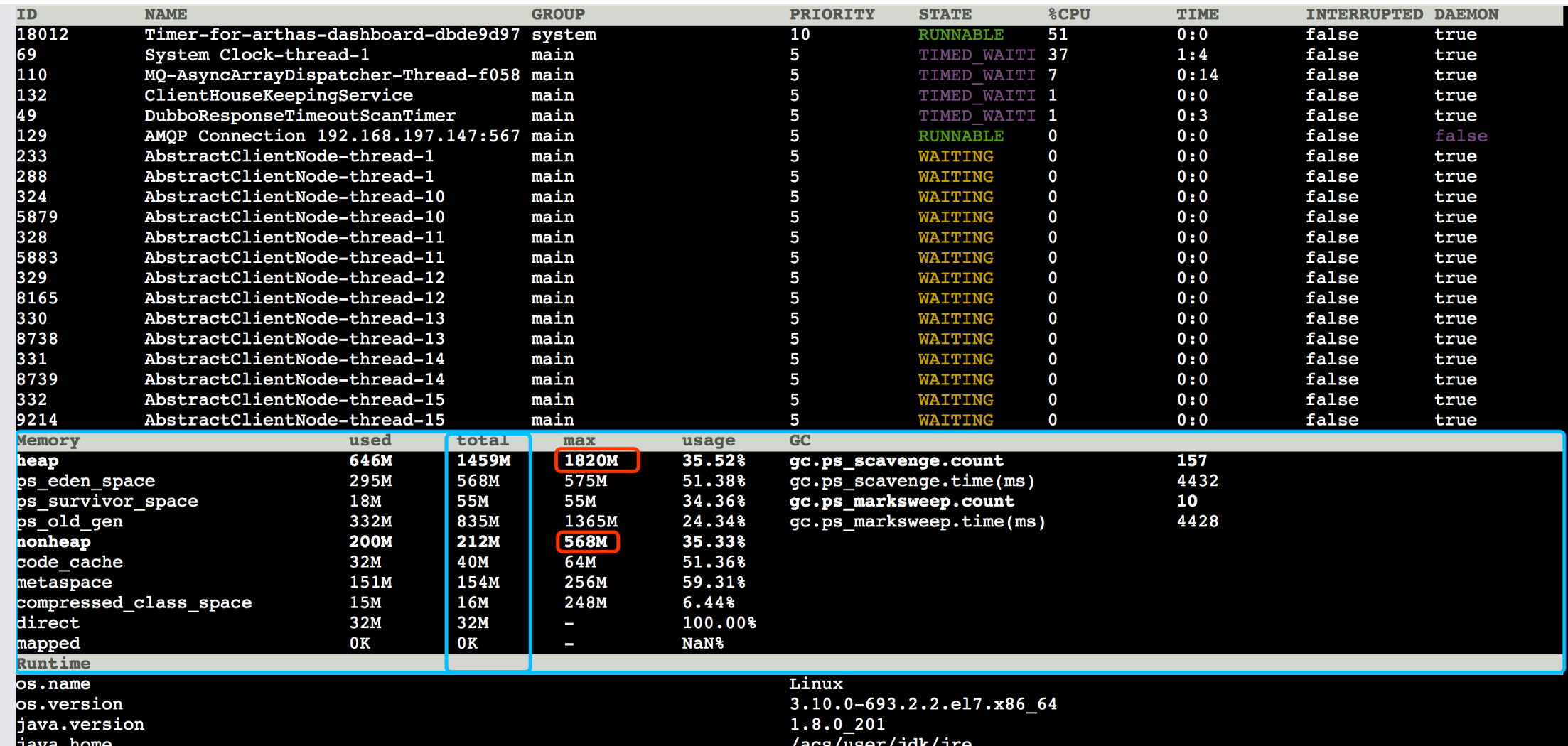
max和我配置无误. 为啥会有total和used的区别,通过翻看arthas源代码得知total==commited, 可以理解为JVM进程向操作系统申请了这么多. 一句话下来就是
最大可以申请1820M,已经申请了1459M,现在已经用了646M
被POD JVM占用的内存不会归还给操作系统了,total是向操作系统申请的,gc会释放但是不会归还给OS,就可以解释在系统运行之初内存缓步增涨,等达到限制之后就会稳定下来. 如果POD申请的内存不够会被OS 直接kill.
JVM实际占用的=图中的total(heap+nonheap) + 线程占用(默认1M)。
得知后在项目中添加了以下几个参数来对重启非常频繁的项目进行验证
部分参数是为了查看内存添加. 需谨慎使用.
-Xmx1024M -Xms128M -XX:MaxMetaspaceSize=128M -XX:ReservedCodeCacheSize=32M -Xss256k -XX:MaxDirectMemorySize=32M -XX:CompressedClassSpaceSize=32M -XX:NativeMemoryTracking=summary -XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics
经过元旦三天的运行,重启大大减少. 其中最严重的已经减少到1天1次重启了.
宿主机CPU load高
由于项目大部分属于内存型应用,默认配置的CPU是[100m,2],发现短时间内同一台宿主机上的项目发生多次重启. 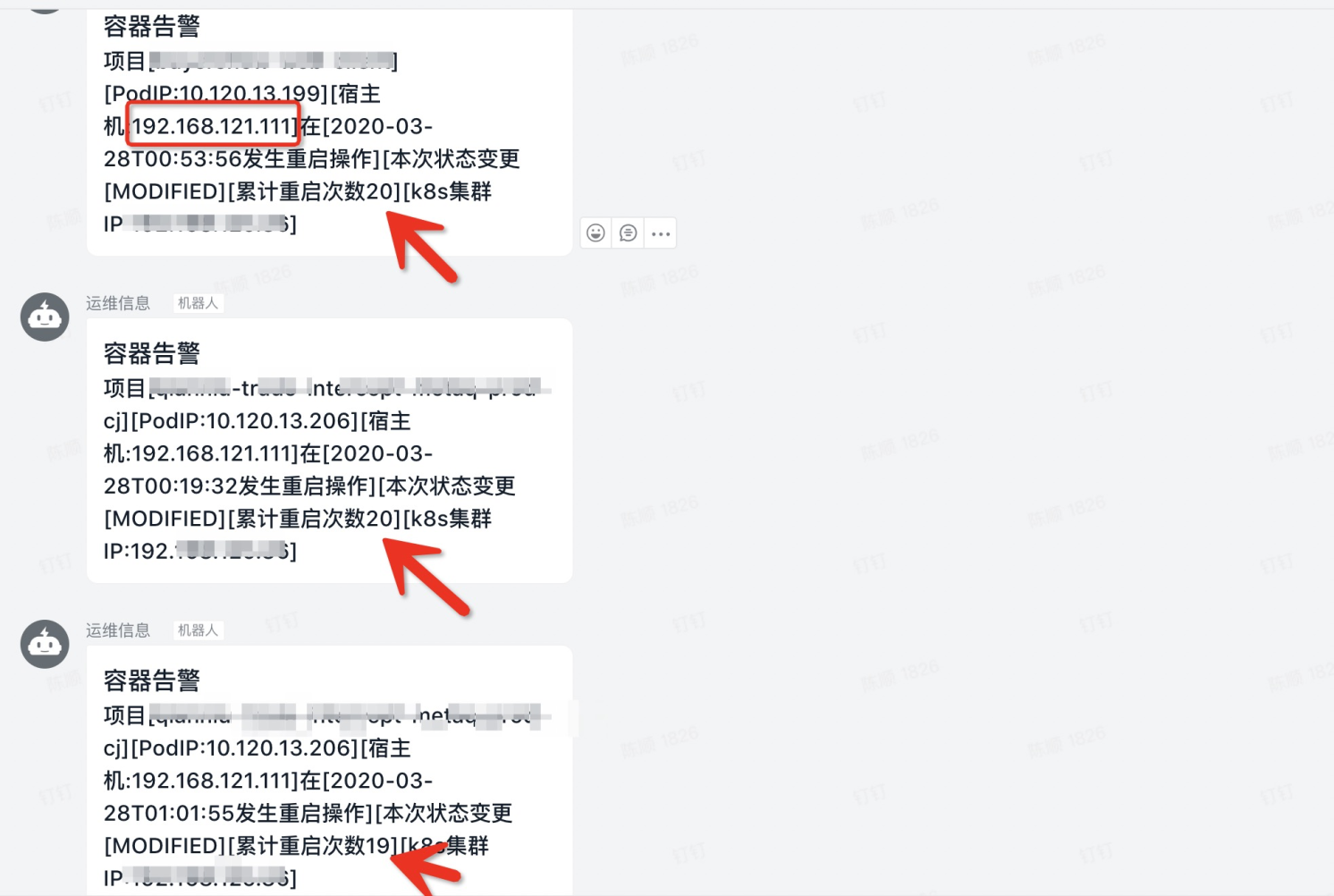
实践总结
还是对与k8s的一些机制不理解,内存到配置不合理,在迁移到过程中,可以适当到增大内存,首先还是让应用跑起来,然后在进行优化,尤其是内存问题,排除开宿主机load超高到问题外,CPU问题比较少.

若有收获,就点个赞吧
0 人点赞
