现象
运维反馈线上几台机器的 TIME_WAIT 比较严重,显示如下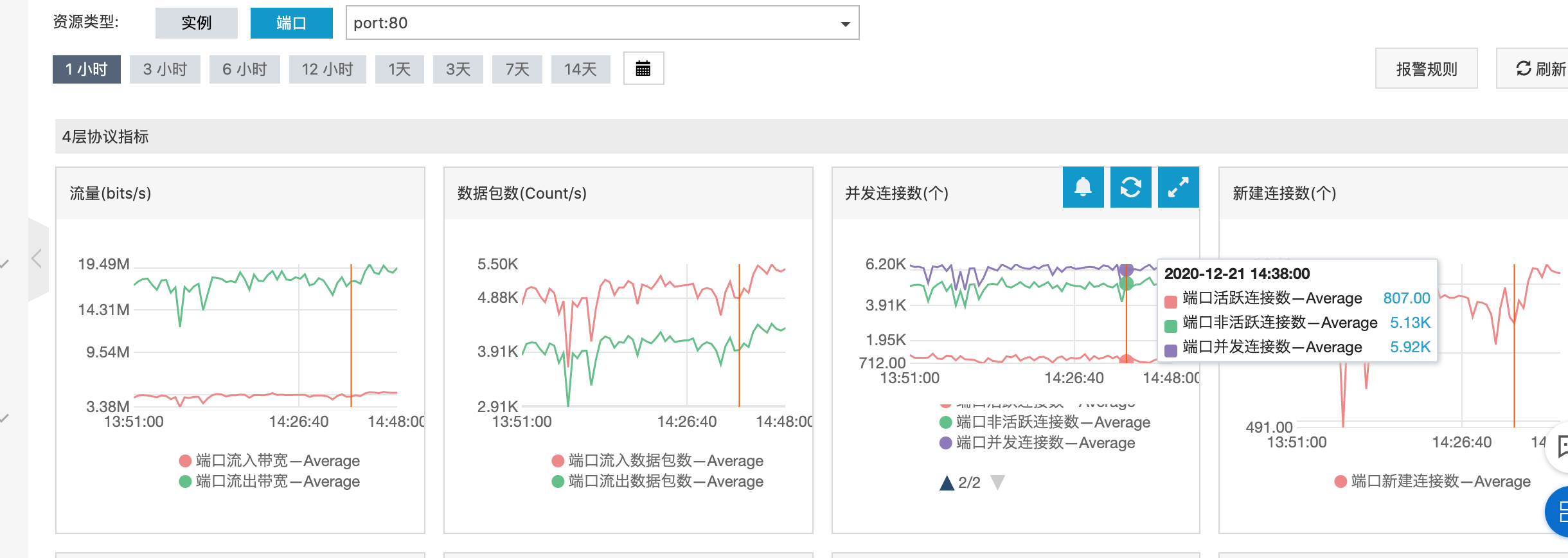
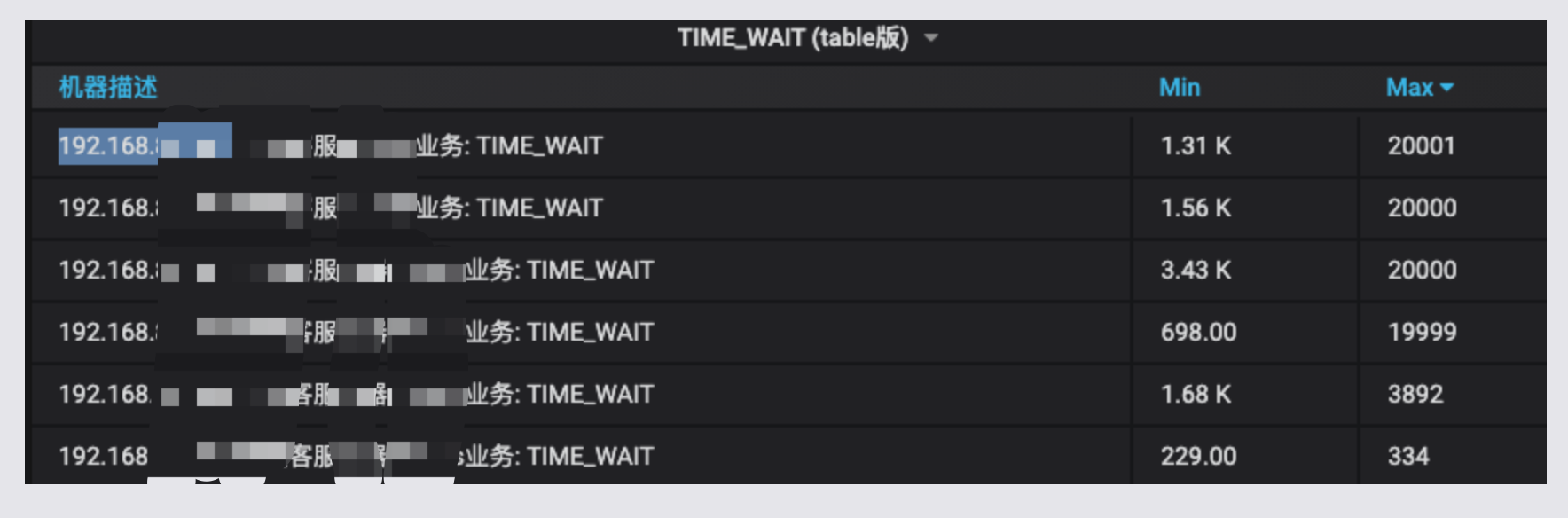
可以观察到前4台机器,TIME_WAIT 异常严重,同时阿里云告警持续不断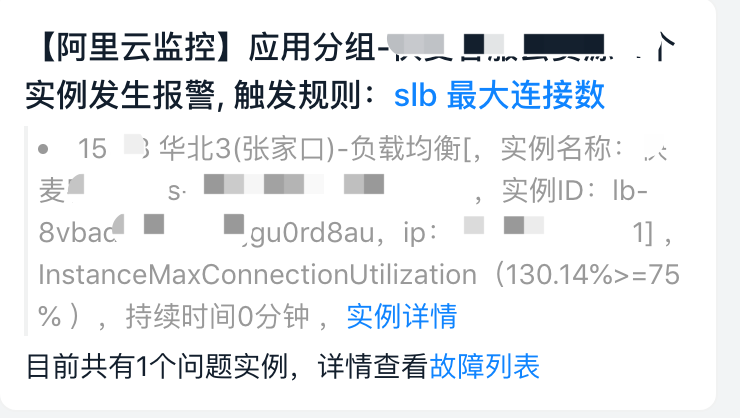
解决问题
本节描述IP皆为修改过后的IP. 但和线上实际的网络拓扑保持一致.
看到这个问题后,首先登录到了到一台线上机器 192.168.52.101 进行查看,使用 netstat -ant |grep TIME_WAIT |wc -l 发现,处于该状态的链接高达2w条记录. 主要集中在 192.168.52.54 和 192.168.52.53 以及 公网SLB 39.x 的交互上.
得知以上信息后,由 netstat/ /usr/sbin/lsof 定位到具体的项目 (project-z) ,由于对这里的部署不太熟悉,导致一开始并没有想清楚整个问题,走了一些弯路.
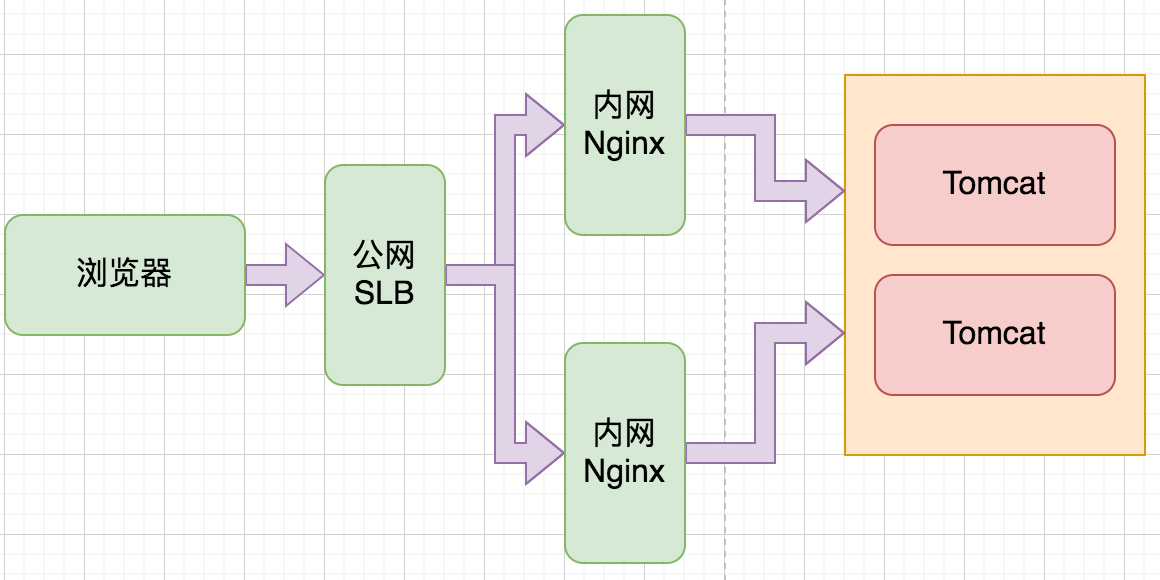<br />在tomcat所在宿主机开始抓包
# 8782 是tomcat的启动端口tcpdump -n port 8782 -w xxx.cap
抓包结果显示,这部分都是从 内网SLB 直接请求的 Tomcat 并没有什么特殊的地方,但是具体是什么 URL 并没有找到,于是又到 内网Nginx 机器上查看 nginx 日志,发现一个URL刷屏非常的多. 
到这一步可以解释为什么集中在 192.168.52.54 和 192.168.52.53 的TIME_WAIT的比较多,毕竟 tomcat 作为 nginx 的后端,如果频繁处理http请求的话,确实存在这个问题.
那么公网SLB 39.x 存在的上W链接又是哪里来的,他不是直接和2台内网Nginx进行交互的吗,此处百思不解.
此时继续对这个应用进行抓包
tcpdump -n (port 8782 and src host 39.x ) -w xxx.cap
下载抓包结果导入 wireshark 一查发现,没有这个IP对数据包.. 连续抓多次都没有,这就太奇怪了,难道没有和这里进行交互吗.
继续使用 netstat 看数据. 数据和下边的结果非常的相同
[root@iZbp11om21c05wzu8e4tx0Z ~]# netstat -ant |grep TIME_WAITtcp 0 0 172.16.254.90:49668 39.x:80 TIME_WAITtcp 0 0 172.16.254.90:41072 39.x:80 TIME_WAITtcp 0 0 172.16.254.90:35240 39.x:80 TIME_WAIT
使用的端口都是非常大的,按照这个数据现在的结果变成了这样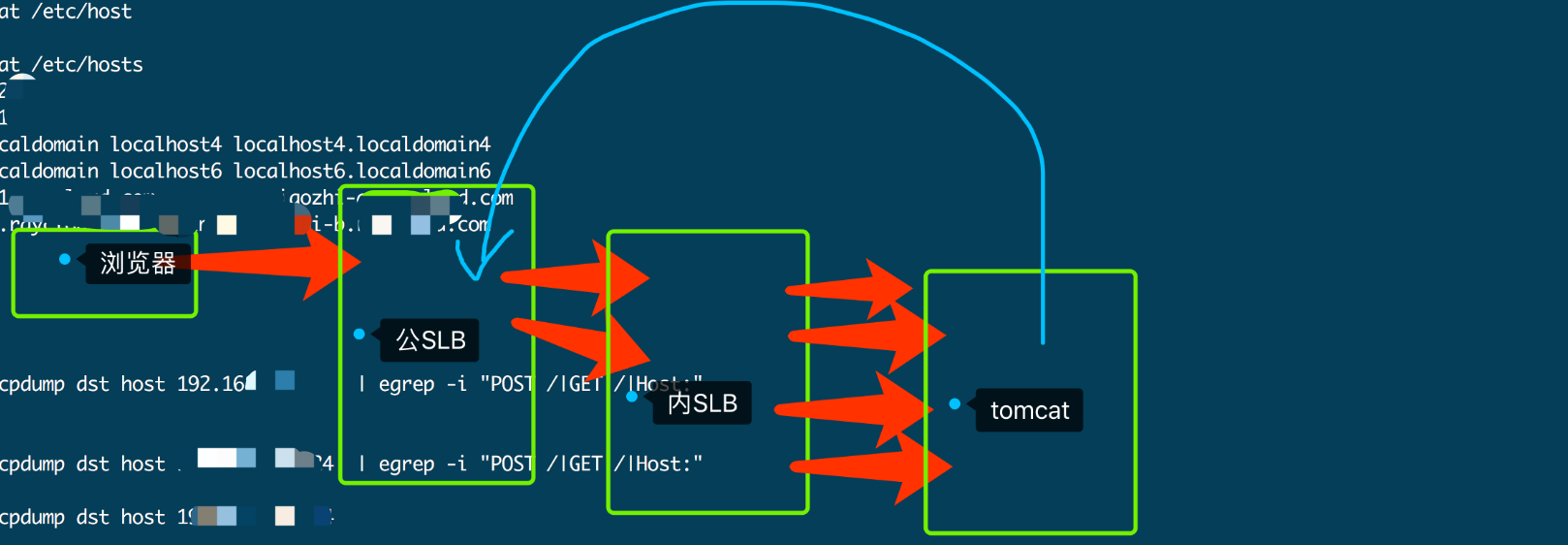
到这一步就有点明白为什么端口数会非常非常的大了,因为在 tomcat 内部执行 Http 请求的时候,是没有指定端口的(这个是很正常的),于是socket会自己选择一个临时端口(这个端口通常会很大)来执行http请求,而这个http请求呢又非常凑巧的请求到了 39.x:80 这个公网SLB上边去了.
抓包验证下
tcpdump -n host 39.x -w xxx.cap
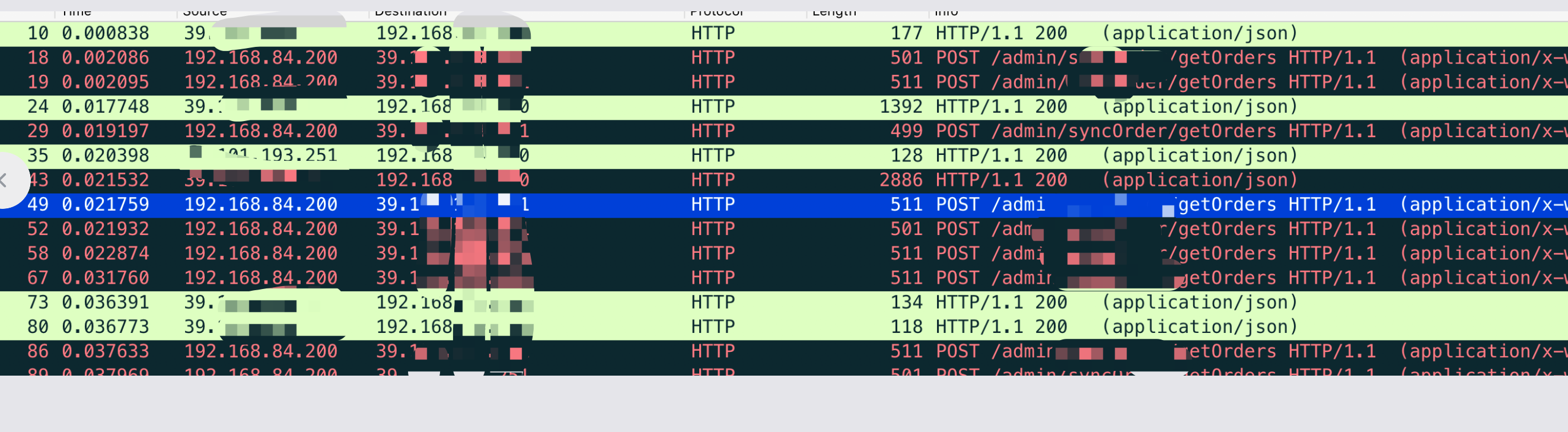
抓包结果显示就很简单了,经过和业务方确认,证实和我们得到猜测一致. 在一个for循环的内部,会一致调用 admin/syncOrder/getOrders 这个接口,但是它使用的URL其就是就是它本身,域名解析到公网SLB,后边跟着内网Nginx,最后流量还是回到了tomcat本身. 这样的巧合合并到一起,引发了这个 TIME_WAIT 的告警.
总结
引起这个问题的代码写法很简单,但是造成的问题和我们的排查其实不是这么简单,如果开发同学能够多掌握一点网络知识会排查的更快.
这里也体会到了一部分基础知识的重要性,例如Socket随机选择临时端口,如果不清楚这一层,怕是想不明白为什么的.

若有收获,就点个赞吧
0 人点赞
