classpath 带和不带的区别
classpath*:/path/target.txtclasspath:/path/target.txt
- 带* , 读取全部的lib
- 不带*,仅读取classes目录下边的数据
对于classpath的处理过程是交给Spring处理的
举个例子
读取 classpath:type*.txt
因为没有加 * 号,所以会读取 classpath
具体的处理是
- 读取 “” 所在的路径. 因为我是idea启动所以是target下的classes目录
/Users/admin/open/boot-mybatis/target/classes然后读取这个目录下所有的文件与type*.txt进行比对.直接使用这种方式的读取是不能读取二级目录下的文件的. 如果需要读取,也要使用正则进行,例如 classpath:/*/type.txt 这样既能读取一级目录也能读取二级目录匹配的文件.
读取classpath*:type*.txt
加了 * 以后的读取会读取所有的lib. 这里的处理是交给JVM实现的.
- ClassLoader#getResource 读取一个文件
- ClassLoader#getResources 读取多个文件
总结
- 正则匹配的是由Spring进行处理
- 如果是classpath*, 会获取classes目录和所有的lib进行查找
- 如果是classpath,则只会获取classes目录进行获取.
- 具体的文件则是由JVM的ClassLoader进行读取
文件读取究竟是谁操作的
在Spring/SpringBoot中,读取文件分为以下几种情况
- new ClassPathResource(“classpath:type.txt”); 读取单个文件
- Thread.currentThread().getContextClassLoader().getResourceAsStream(“classpath:type.txt”) 单个文件
- ResourceUtils.getFile(“classpath:type.txt”); 单个文件
- new PathMatchingResourcePatternResolver() .getResources(“classpath:/**/type.txt”); 正则匹配并获取文件
根据上边的猜测可以肯定是 1,2,3应该是JVM的一个封装实现,直接使用的classLoader读取文件。 4则是根据classpath*的表现去决定.
看下来都是 classloader.getResourceAsStream(name) classloader是如何读取文件的呢
发现classloader内部都是依赖 ucp 实现的, URLClassPath , 码如其名,应该是加载的URL的一个集合,实际发现在 ucp 中读取文件其实是通过一些协议去读取文件内容的,如果是文件系统则是file协议,如果http开头的则是通过http协议。
在一些常见的攻击场景中,攻击者通常会注入一些第三方jar包到我们系统当中,这个第三方jar包就是通过http的方式进行加载的,如果我们保护系统不加载第三方jar包,可以通过字节码的技术在ucp加载jar包的时候判断如果是http协议的,就提示告警或者是加白名单.. 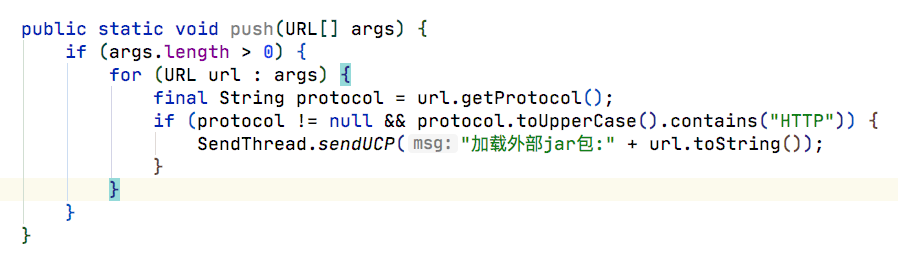

若有收获,就点个赞吧
0 人点赞
