数据结构
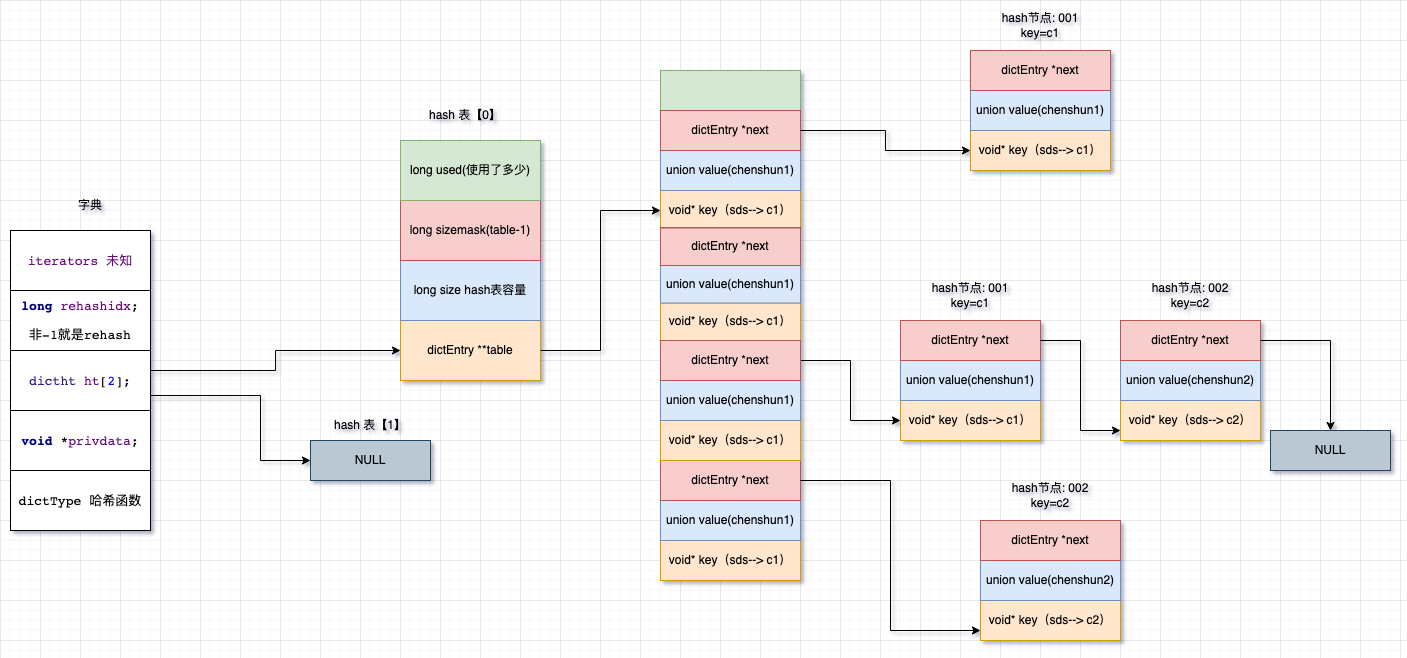
数据操作
初始化
int _dictInit(dict *d, dictType *type, void *privDataPtr) {_dictReset(&d->ht[0]);_dictReset(&d->ht[1]);d->type = type;d->privdata = privDataPtr;d->rehashidx = -1;d->iterators = 0;return DICT_OK;}//----static void _dictReset(dictht *ht){ht->table = NULL;ht->size = 0;ht->sizemask = 0;ht->used = 0;}
增加(替换)
int dictReplace(dict *d, void *key, void *val){dictEntry *entry, *existing, auxentry;/* Try to add the element. If the key* does not exists dictAdd will succeed. */entry = dictAddRaw(d,key,&existing);if (entry) {//添加成功,设置hash节点的valuedictSetVal(d, entry, val);return 1;}/* Set the new value and free the old one. Note that it is important* to do that in this order, as the value may just be exactly the same* as the previous one. In this context, think to reference counting,* you want to increment (set), and then decrement (free), and not the* reverse. */auxentry = *existing;//设置新的value值dictSetVal(d, existing, val);//释放老的节点dictFreeVal(d, &auxentry);return 0;}
删除(hash获取数组下标 && 链表移除节点,直接释放内存/后台释放内存)
/* Search and remove an element. This is an helper function for* dictDelete() and dictUnlink(), please check the top comment* of those functions. */static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {uint64_t h, idx;dictEntry *he, *prevHe;int table;if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;//执行rehashif (dictIsRehashing(d)) _dictRehashStep(d);//获取数组索引下标h = dictHashKey(d, key);for (table = 0; table <= 1; table++) {idx = h & d->ht[table].sizemask;he = d->ht[table].table[idx];prevHe = NULL;while(he) {//找到了keyif (key==he->key || dictCompareKeys(d, key, he->key)) {//key在链表中if (prevHe)prevHe->next = he->next;else//key在数组中d->ht[table].table[idx] = he->next;if (!nofree) {//根据配置释放直接释放内存dictFreeKey(d, he);dictFreeVal(d, he);zfree(he);}d->ht[table].used--;return he;}prevHe = he;he = he->next;}if (!dictIsRehashing(d)) break;}return NULL; /* not found */}
渐进式哈希
在rehashIndex!=-1的时候进入,rehashIndex就是数组的下标,每次都取走n个bucket的数据(n个bucket+bucket链表的数据),将其插入到第二个hash表上,采用头插法的方式进行。
/* Performs N steps of incremental rehashing. Returns 1 if there are still* keys to move from the old to the new hash table, otherwise 0 is returned.** Note that a rehashing step consists in moving a bucket (that may have more* than one key as we use chaining) from the old to the new hash table, however* since part of the hash table may be composed of empty spaces, it is not* guaranteed that this function will rehash even a single bucket, since it* will visit at max N*10 empty buckets in total, otherwise the amount of* work it does would be unbound and the function may block for a long time. */int dictRehash(dict *d, int n) {int empty_visits = n*10; /* Max number of empty buckets to visit. */if (!dictIsRehashing(d)) return 0;while(n-- && d->ht[0].used != 0) {dictEntry *de, *nextde;//跳过数组下标为null的节点while(d->ht[0].table[d->rehashidx] == NULL) {d->rehashidx++;if (--empty_visits == 0) return 1;}//获取第一个节点de = d->ht[0].table[d->rehashidx];/* Move all the keys in this bucket from the old to the new hash HT */while(de) {uint64_t h;//获取下一个节点nextde = de->next;/* Get the index in the new hash table *///获取新索引值h = dictHashKey(d, de->key) & d->ht[1].sizemask;//通过头插法进行插入,这里只是更新节点下标,不需要释放节点内存de->next = d->ht[1].table[h];d->ht[1].table[h] = de;d->ht[0].used--;d->ht[1].used++;de = nextde;}//一个bucket就解决了d->ht[0].table[d->rehashidx] = NULL;d->rehashidx++;}//检查是否已经处理完了整个hash表/* Check if we already rehashed the whole table... */if (d->ht[0].used == 0) {zfree(d->ht[0].table);d->ht[0] = d->ht[1];_dictReset(&d->ht[1]);d->rehashidx = -1;return 0;}/* More to rehash... */return 1;}
图解







若有收获,就点个赞吧
0 人点赞
