1 读取数据
import numpy as npimport pandas as pdimport tensorflow as tfimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)train_data_file = './raw_data/track1_round1_train_20210222.csv'test_data_file = './raw_data/track1_round1_testA_20210222.csv'picture_file = './documentation/picture/'
2 统计词数
with open(train_data_file, 'r') as f:lines = f.readlines()train_texts, train_labels = [], []for id, line in enumerate(lines):line = line.strip().replace('|', '').split(',')text = line[1].strip().split(' ')text = [int(word) for word in text]train_texts.append(text)train_labels.append(line[2])with open(test_data_file, 'r') as f:lines = f.readlines()test_texts = []for id, line in enumerate(lines):line = line.strip().replace('|', '').split(',')text = line[1].strip().split(' ')text = [int(word) for word in text]test_texts.append(text)
(1)训练集的词数
vocab_size = max(max(text) for text in train_texts) - min(min(text) for text in train_texts) + 1print("训练集的vpcab_size: {}".format(vocab_size))
训练集的vpcab_size: 858
(2)测试集的词数
vocab_size = max(max(text) for text in train_texts) - min(min(text) for text in test_texts) + 1print("测试集的vocab_size: {}".format(vocab_size))
测试集的vpcab_size: 858
3 统计词频
word_count = np.zeros(vocab_size, dtype='int32')for text in train_texts:for word in text:word_count[word] += 1sorted_index = word_count.argsort()
(1)统计词频最低的top20
# 最小的词频for i in range(20):word = sorted_index[i]print(str(word) + "|" + str(word_count[word]))
236|18 466|18 246|19 82|19 29|19 263|20
451|21
849|22
804|22
384|22
684|23
360|23
714|23
210|23
275|24
157|24
678|24
186|24
696|24
467|24
(2)统计词频最高的top20
# 最大的词频for i in range(-1,-21,-1):word = sorted_index[i]print(str(word) + "|" + str(word_count[word]))
693|5477
328|4009
698|3592
380|3198
177|2844
415|2785
381|2699
809|2111
266|1501
623|1467
14|1434
852|1387
256|1344
842|1267
832|1245
172|1243
399|1155
204|1142
382|1135
582|1130
4 统计句子长度
df_train = pd.DataFrame()df_train['train_text'] = train_textsdf_train['train_label'] = train_labeldf_train['text_length'] = df.train_text.apply(len)df_train['disease_num'] = df.train_label.apply(lambda x:len(x.strip().split()))df_test = pd.DataFrame()df_test['test_text'] = test_textsdf_test['text_length'] = df_test.test_text.apply(len)text_length = [len(text) for text in train_texts]_ = plt.hist(text_length, bins=50, label='句长分布')_ = plt.legend()
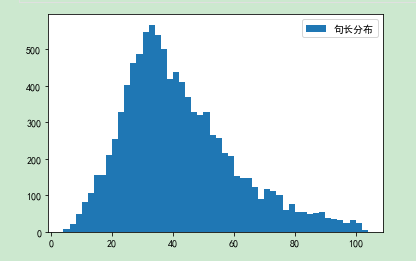
(1)训练集句子长度统计
df_train.text_length.describe()
count 10000.000000
mean 41.564800
std 18.349127
min 4.000000
25% 29.000000
50% 38.000000
75% 52.000000
max 104.000000
Name: text_length, dtype: float64
(2)测试集句子长度统计
df_test.text_length.describe()
count 3000.000000
mean 40.409667
std 17.695561
min 4.000000
25% 28.000000
50% 37.000000
75% 50.000000
max 102.000000
Name: text_length, dtype: float64
5 label类别分布
label_counts = np.zeros(17, dtype='int32')for labels in train_labels:labels = labels.strip().split(' ')for label in labels:if label != '':label_counts[int(label)]+=1_ = plt.bar(range(17), label_counts, label='各标签数量统计')for x, count in enumerate(label_counts):plt.text(x-0.5, count+20, "{}".format(count))_ = plt.xlabel("label")_ = plt.xticks(range(0,17))_ = plt.ylabel("频数")_ = plt.title("各个标签出现频数")plt.savefig(picture_file+'label_freq.jpg')
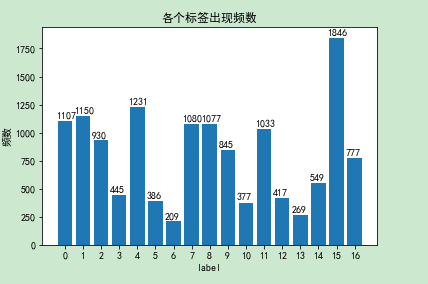
6 正负样本分布
total_num = df_train.shape[0]for id, count in enumerate(label_counts):print("{}|{}|{}|{:.2f}%".format(id, count, total_num-count, 100*count/total_num))
0|1107|8893|11.07%
1|1150|8850|11.50%
2|930|9070|9.30%
3|445|9555|4.45%
4|1231|8769|12.31%
5|386|9614|3.86%
6|209|9791|2.09%
7|1080|8920|10.80%
8|1077|8923|10.77%
9|845|9155|8.45%
10|377|9623|3.77%
11|1033|8967|10.33%
12|417|9583|4.17%
13|269|9731|2.69%
14|549|9451|5.49%
15|1846|8154|18.46%
16|777|9223|7.77%
7 缺失值
(1)text
无
(2)label
8 统计句子最后一个字符词频
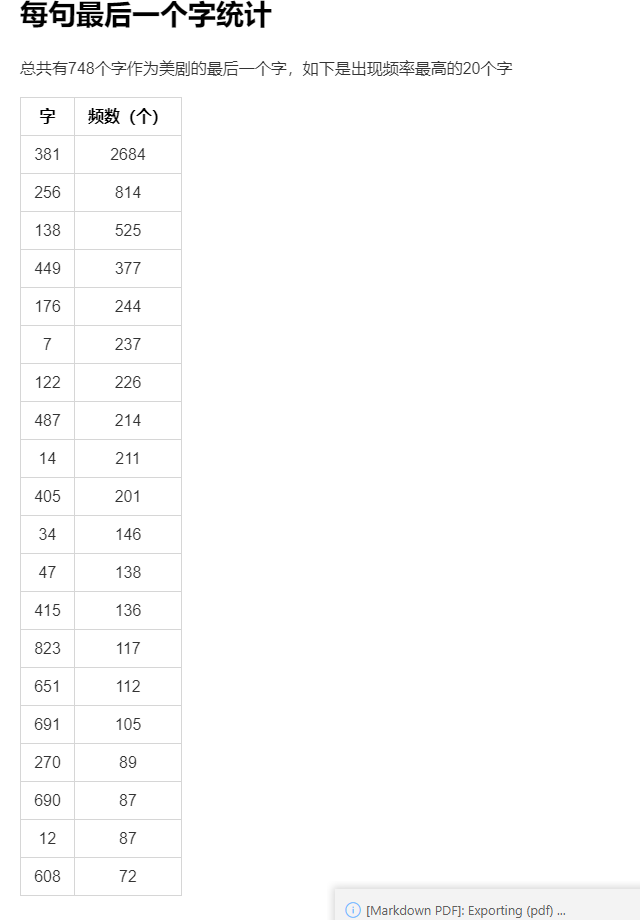
3

若有收获,就点个赞吧
0 人点赞
