赛题背景
影像科医生在工作时会观察医学影像(如CT、核磁共振影像),并对其作出描述,这些描述中包含了大量医学信息,对医疗AI具有重要意义。本任务需要参赛队伍根据医生对CT的影像描述文本数据,判断身体若干目标区域是否有异常以及异常的类型。初赛阶段仅需判断各区域是否有异常,复赛阶段除了判断有异常的区域外,还需判断异常的类型。判断的结果按照指定评价指标进行评测和排名,得分最优者获胜。
赛题描述及数据说明
sample数据
医生对若干CT的影像描述的明文数据,及描述中有异常区域与异常类型的label。样本数量为10份数据集小,以便使参赛队伍对比赛数据有直观的了解(Sample数据只是为了增进参赛选手对医疗影像描述的直观了解,实际训练与测试数据不一定与Sample数据具有相同特征或分布)。
每份样本占一行,使用分隔符“|,|”分割为3列,为不带表头的CSV数据格式。
| 列名 | 类型 | 示例 |
|---|---|---|
| report_ID | int | 1 |
| description | string,影像描述 | 右下肺野见小结节样影与软组织肿块影 |
| label | 由两部分组成。第一部分为若干异常区域ID,用空格分割。第二部分为若干异常类型ID,用空格分割。两部分用逗号“,”分割。若定义中所有区域均无异常,则两部分均为空,此项为“,”。 | 4,1 2 |
需要预测的人体区域有17个,复赛中需要判断的异常类型有12种输出类别12个。由于数据安全需要,不会告知具体区域与类型的名称,只会以ID表示,区域ID为0到16,类型ID为0到11。每个影像描述中可能有零个、一个或多个区域存在异常;若此描述有异常区域,则可能包含一个或多个异常类型。多个输出
Training数据
脱敏(又称数据漂白、数据去隐私化或数据变形。是对核心业务数据中敏感的信息,进行变形、转换、混淆,使得对业务数据中的身份、组织等隐私敏感信息进行去除或掩盖,以保护数据能被合理、安全地利用)后的影像描述与对应label。影像描述以字为单位脱敏,使用空格分割。初赛只进行各区域有无异常的判断标签,label只有异常区域ID。复赛除了判断各区域有无异常,还需要判断各区域异常的类型,因此label包含异常区域ID与异常类型ID。初赛Training集规模为10000例样本,复赛Training集规模为20000例样本。Training数据用于参赛选手的模型训练与预估。
初赛Training数据格式(不同列使用分隔符“|,|”分割): | 列名 | 类型 | 示例 | | :—-: | :—-: | :—-: | | report_ID | int | 1 | | description | 脱敏后的影像描述,以字为单位使用空格分割 | 101 47 12 66 74 90 0 411 234 79 175 | | label | 由多个异常区域ID组成,以空格分隔。若此描述中无异常区域,则为空 | 3 4 |
复赛Training数据格式(不同列使用分隔符“|,|”分割): | 列名 | 类型 | 示例 | | :—-: | :—-: | :—-: | | report_ID | int | 1 | | description | 脱敏后的影像描述,以字为单位使用空格分割 | 101 47 12 66 74 90 0 411 234 79 175 | | label | string,由两部分组成。第一部分为若干异常区域ID,用空格分割。第二部分为若干异常类型ID,用空格分割。两部分用逗号“,”分割。若定义中所有区域均无异常,则两部分均为空,此项为“,”。 | 3 4,0 2 |
Test数据
脱敏后的影像描述,脱敏方法和Training相同。Test数据用于参赛选手的模型评估和排名。初赛Test集分为AB榜,规模均为3000。复赛Test集规模为5000。
Test数据格式(不同列使用分隔符“|,|”分割):
| 列名 | 类型 | 示例 |
|---|---|---|
| report_ID | int | 1 |
| description | 脱敏后的影像描述,以字为单位使用空格分割 | 101 47 12 66 74 90 0 411 234 79 175 |
提交说明
对于Test数据report_ID,description,选手应提交report_ID,prediction,其中prediction是预测结果。初赛中prediction是17维向量,值在0到1之间,表示各区域有异常的概率,使用空格分割。复赛中prediction是29维向量,值在0到1之间,前17个值表示17个区域有异常的概率,后12个值表示此描述包含各异常类型的概率。每个label的概率
初赛提交数据格式(不同列使用分隔符“|,|”分割): | 列名 | 类型 | 示例 | | :—-: | :—-: | :—-: | | report_ID | int | 1 | | Prediction | 17维向量 | 0.68 0.82 0.92 0.59 0.71 0.23 0.45 0.36 0.46 0.64 0.92 0.66 0.3 0.5 0.94 0.7 0.38 |
复赛提交数据格式(不同列使用分隔符“|,|”分割): | 列名 | 类型 | 示例 | | :—-: | :—-: | :—-: | | report_ID | int | 1 | | Prediction | 29维向量(中间不需要使用逗号分隔) | 0.68 0.82 0.92 0.59 0.71 0.23 0.45 0.36 0.46 0.64 0.92 0.66 0.3 0.5 0.94 0.7 0.38 0.05 0.97 0.71 0.5 0.64 0.0 0.54 0.5 0.49 0.41 0.06 0.07 |
评估标准
在Test数据上将对选手提交结果使用ROC曲线的AUC(Area Under Curve)作为评估标准。
- 在初赛阶段,一个样本对应17个预测值,在计算AUC时,这17个预测值被看作17个不同的样本。即对N个测试样本看作17N个样本进行AUC计算。具体来说,对应某阈值T,所有预测值大于T的预测即为阳性,反之为阴性。由此得到真阳性TP、假阳性FP、真阴性TN、假阴性FN,此四个值和为17N。对应真阳性率TPR、假阳性率FPR分别为
 ,以FPR为横坐标,TPR为纵坐标,改变阈值T即得ROC曲线。计算其曲线下面积AUC即为最终评价指标。
,以FPR为横坐标,TPR为纵坐标,改变阈值T即得ROC曲线。计算其曲线下面积AUC即为最终评价指标。 - 在复赛阶段,分数由两部分组成。第一部分与初赛相同,对预测值的前17维结合真实值计算AUC,得到
 。第二部分为对所有实际存在异常区域的测试样本,对其预测值后12维结合真实异常类型计算AUC,方法与第一部分相同,若N个测试样本中有M个实际有异常区域,则将对12M个样本进行AUC计算(实际无异常的样本不参与第二部分计算),得到
。第二部分为对所有实际存在异常区域的测试样本,对其预测值后12维结合真实异常类型计算AUC,方法与第一部分相同,若N个测试样本中有M个实际有异常区域,则将对12M个样本进行AUC计算(实际无异常的样本不参与第二部分计算),得到 。复赛最终分数 :
。复赛最终分数 : 
下面以复赛分数为例,举例说明分数计算方法。为了便于说明,这里假设区域有3个而不是17个,异常类型有2个而不是12个。设真实值和选手提交的预测值分别如下:
| 真实值Ground Truth | 预测值Prediction |
|---|---|
| 0 1 0 1 0 | 0 0.6 0.7 0.5 0 |
| 0 0 1 1 0 | 0 0.6 0.8 0.1 0.2 |
则第一部分分数为对以下数据计算AUC:
| 真实值 | 0 | 1 | 0 | 0 | 0 | 1 |
|---|---|---|---|---|---|---|
| 预测值 | 0 | 0.6 | 0.7 | 0 | 0.6 | 0.8 |
ROC曲线如下所示,计算其AUC得到S_1_S_1=0.8125。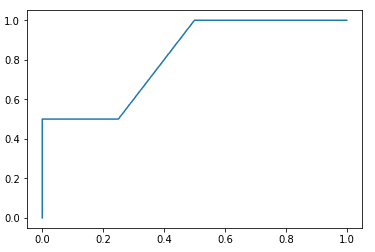
同理,对类型预测部分的22=4个样本进行AUC计算,得到S_2_S_2=0.75。因此复赛阶段分数为0.60.8125+0.4*0.75=0.7875。
比赛规则

若有收获,就点个赞吧
0 人点赞
