1 推荐系统简介
(1)含义:推荐系统会尝试捕捉这些模式 和类似行为,以帮助预测您可能喜欢的其他内容。
(2)举例:
- 购物推荐:电子书、书、电影…
- 在社交媒体上,网站,如 Facebook 或领英,定期推荐友谊。 推荐系统甚至可以用来个性化您的网络体验。
(3)驱动因素分类
- 基于内容的推荐系统(content-based)
- 推荐更多我之前喜欢的

- 协作过滤的推荐系统(collaborative filtering)
- 推荐我周围的人都喜欢的,是我没有见过的

(4)实施推荐系统分类
- 基于记忆(memory-based)
- 我们使用整个用户项目数据集生成推荐统。 它使用统计技术来估算用户或项目
- 技术包括:Pearib Correlation ,Cosine Similarity,Euclidean Distance(皮尔逊 相关性、余弦相似度和欧氏距离)
- 基于模型的(model-based)


(2)根据以上的User Profile计算推荐矩阵。
用User ProfileJ矩阵乘以候选电影(没有看过的电影)的类别矩阵,得到类别权重矩阵,再归一化。得到推荐矩阵
3 协作过滤推荐系统
3.1 基于用户的协作过滤(User-based)
(1)基于用户周围的邻居(user’s neighborhood)
通过与相似的邻居的关系,推荐邻居的电影
(2)算法介绍
推荐两个问号的电影。这可以通过几种不同的统计和矢量技术来完成,例如距离或相似度测量,包括欧氏距离,皮尔逊相关性,余弦相似度等。
- 创建打分权重矩阵
Ratrings Matrix subset :是对应人物的打分矩阵
Similarity Matrix:是第四位用户与前三位的相似度
Weighted Rating Matrix:得到的打分权重矩阵
得到打分和权重矩阵后除以权重和,得到最终的推荐矩阵。
3.2 基于项目的的协作过滤(Item-based)
基于项目点的相似度(Item‘s Similarity)
3.3 以上两者的区别
(1)(左图)在以用户为基础的方法中, 该推荐是根据与他或她有共同偏好的同一社区的用户提出的. 例如,由于user1 和user 3 都喜欢Item 3 和Item 4,我们认为它们是相似或邻居用户,并推荐用户 1 对用户 3 给予正面评级的项目 1。 说白了两个人是都喜欢同样的一些电影,才推荐给你的我喜欢看的。主语是人
(2)(右图)在基于项目的方法中, 类似的项目基于用户的行为构建邻域。 但是,请注意,它不是基于他们的内容。 例如,Item1 和Item 3 被视为邻居,因为user 1 和user 2 都给予了正面评价。 因此,item 1 可以推荐给user 3,因为他已经对项目 3 表现出兴趣。 因此,此处的推荐基于用户可能喜欢的邻域中的项目。说白了两个电影是邻居,就是大家都觉得其中一个电影好,就把邻居电影推荐给你。主语是电影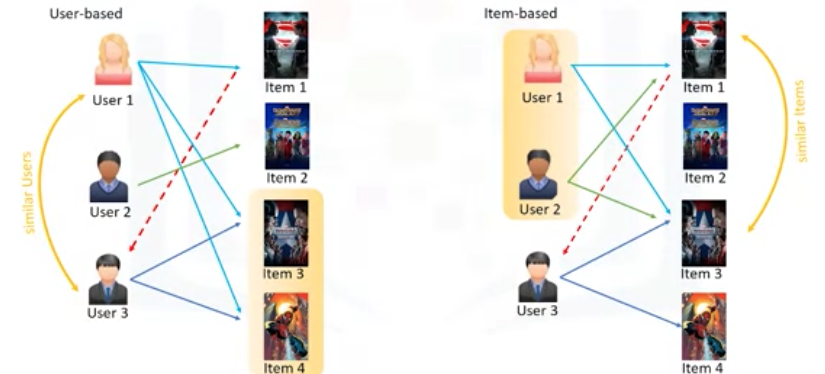
3.4 协作过滤的挑战
(1)Data Sparsity数据稀疏
当您拥有大量数据集的 用户通常只对有限数量的项目进行评级时,会发生数据稀疏性.
如前所述,基于协作的推荐者只有在有其他用户对项目进行评级时才能预测项目的评分。 由于稀疏,我们在用户项目 数据集中可能没有足够的评级,因此无法提供正确的推荐。
(2)Cold Start冷启动
冷启动 是指当有新用户时,推荐系统遇到的困难 ,因此他们还不存在这样的配置文件。 当我们有一个尚未获得评级的新项目时,也可能会发生冷启动。
(3)Scalability可扩展性
随着用户或项目数量的增加和数据量的扩大, 协作过滤算法的性能将开始下降,这仅仅是由于增长和相似性计算。
但是又混合推荐系统可以解决以上问题。

若有收获,就点个赞吧
0 人点赞
