封装的源码汇总
pytorch实现源码:https://github.com/649453932/Chinese-Text-Classification-Pytorch
1 FastText
1.1 相关资料
论文:《Bag of Tricks for Efficient Text Classification》 Keras实现源码:https://github.com/wayfair/fasttext-keras Tensorflow实现源码:https://github.com/apcode/tensorflow_fasttext
1.2 介绍
(1)简介
Fasttext是Facebook推出的一个便捷的工具,包含文本分类和词向量训练两个功能
Fasttext的分类实现很简单:把输入转化为词向量,取平均,再经过线性分类器得到类别。输入的词向量可以是预先训练好的,也可以随机初始化,跟着分类任务一起训练。 、
、
(2)优点
- 模型本身复杂度低,但效果不错,能快速产生任务的baseline
- Facebook使用C++进行实现,进一步提升了计算效率
- 采用了char-level的n-gram作为附加特征,比如paper的trigram是 [pap, ape, per],在将输入paper转为向量的同时也会把trigram转为向量一起参与计算。这样一方面解决了长尾词的OOV (out-of-vocabulary)问题,一方面利用n-gram特征提升了表现
- 当类别过多时,支持采用hierarchical softmax进行分类,提升效率
(3)适用场景
对于文本长且对速度要求高的场景,Fasttext是baseline首选。同时用它在无监督语料上训练词向量,进行文本表示也不错。不过想继续提升效果还需要更复杂的模型。
2 TextCNN
2.1 相关资料
论文《Convolutional Neural Networks for Sentence Classification》 Python 实现工具包:https://github.com/dmlc/gluon-nlp?utm_source=catalyzex.com Tensorflow实现文本分类:https://github.com/XqFeng-Josie/TextCNN
2.2 介绍
TextCNN是Yoon Kim在2014年提出的模型,开创了用CNN编码n-gram特征的先河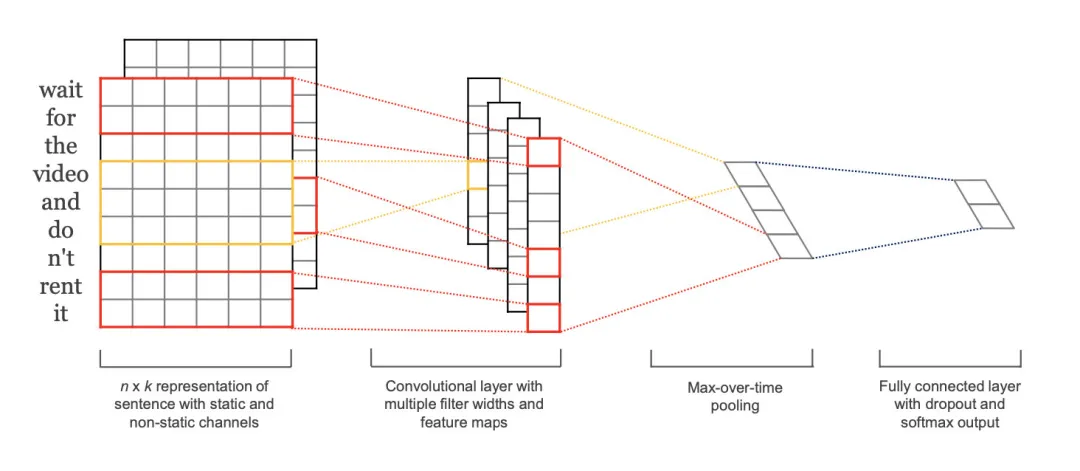
模型结构如图,图像中的卷积都是二维的,而TextCNN则使用「一维卷积」,即filter_size * embedding_dim,有一个维度和embedding相等。这样就能抽取filter_size个gram的信息。以1个样本为例,整体的前向逻辑是:
- 对词进行embedding,得到
[seq_length, embedding_dim] - 用N个卷积核,得到N个
seq_length-filter_size+1长度的一维feature map - 对feature map进行max-pooling(因为是时间维度的,也称max-over-time pooling),得到N个
1x1的数值,拼接成一个N维向量,作为文本的句子表示 - 将N维向量压缩到类目个数的维度,过Softmax
在TextCNN的实践中,有很多地方可以优化(参考这篇论文《A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification》):
- Filter尺寸:这个参数决定了抽取n-gram特征的长度,这个参数主要跟数据有关,平均长度在50以内的话,用10以下就可以了,否则可以长一些。在调参时可以先用一个尺寸grid search,找到一个最优尺寸,然后尝试最优尺寸和附近尺寸的组合
- Filter个数:这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。这里在100-600之间调参即可
- CNN的激活函数:可以尝试Identity、ReLU、tanh
- 正则化:指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小的dropout率(<0.5),L2限制大一点
- Pooling方法:根据情况选择mean、max、k-max pooling,大部分时候max表现就很好,因为分类任务对细粒度语义的要求不高,只抓住最大特征就好了
- Embedding表:中文可以选择char或word级别的输入,也可以两种都用,会提升些效果。如果训练数据充足(10w+),也可以从头训练
- 蒸馏BERT的logits,利用领域内无监督数据
- 加深全连接:原论文只使用了一层全连接,而加到3、4层左右效果会更好
TextCNN是很适合中短文本场景的强baseline,但不太适合长文本,因为卷积核尺寸通常不会设很大,无法捕获长距离特征。同时max-pooling也存在局限,会丢掉一些有用特征。另外再仔细想的话,TextCNN和传统的n-gram词袋模型本质是一样的,它的好效果很大部分来自于词向量的引入,因为解决了词袋模型的稀疏性问题
3 DPCNN
3.1 相关资料
论文《Deep Pyramid Convolutional Neural Networks for Text Categorization》 PyTorch实现源码:https://github.com/Cheneng/DPCNN?utm_source=catalyzex.com TensorFlow实现源码:https://github.com/HaishuoFang/DPCNN Keras实现源码:https://github.com/matemijolovic/dpcnn
3.2 介绍
2017年,腾讯提出了把TextCNN做到更深的DPCNN模型: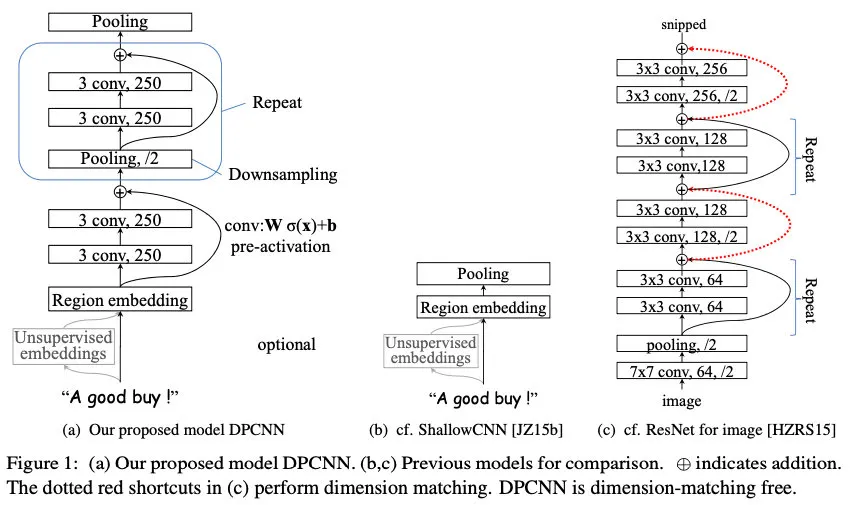
上图中的ShallowCNN指TextCNN。DPCNN的核心改进如下:
- 在Region embedding时不采用CNN那样加权卷积的做法,而是对n个词进行pooling后再加个1x1的卷积,因为实验下来效果差不多,且作者认为前者的表示能力更强,容易过拟合
- 使用1/2池化层,用size=3 stride=2的卷积核,直接让模型可编码的sequence长度翻倍(自己在纸上画一下就get啦)
- 残差链接,参考ResNet,减缓梯度弥散问题
凭借以上一些精妙的改进,DPCNN相比TextCNN有1-2个百分点的提升。
4 TextRCNN
4.1 相关资料
论文《Recurrent convolutional neural networks for text classification》 Pytorch实现源码:https://github.com/649453932/Chinese-Text-Classification-Pytorch Keras实现源码:https://github.com/vivianLL/textClassification_Keras Tensorflow实现源码:https://github.com/zhengwsh/text-classification
4.2 介绍
除了DPCNN那样增加感受野的方式,RNN也可以缓解长距离依赖的问题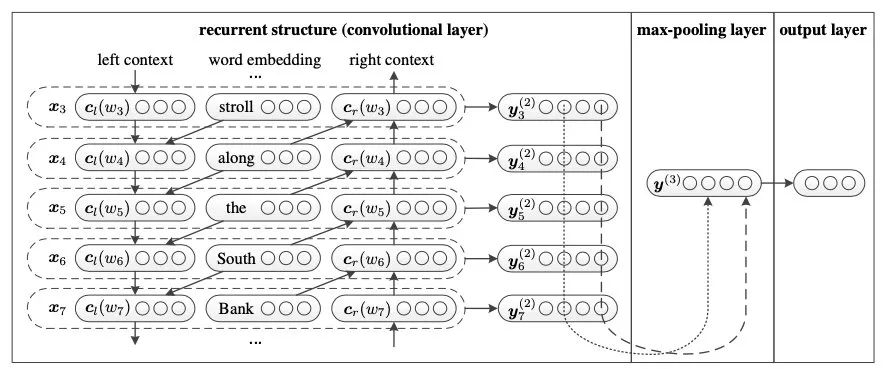
5 TextBiLSTM+Attention
5.1 相关资料
论文《Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification》 Pytorch实现源码:https://github.com/649453932/Chinese-Text-Classification-Pytorch Tensorflow实现源码:https://github.com/SeoSangwoo/Attention-Based-BiLSTM-relation-extraction Keras实现源码:https://github.com/PatientEz/CNN-BiLSTM-Attention-Time-Series-Prediction_Keras
5.2 介绍
从前面介绍的几种方法,可以自然地得到文本分类的框架,就是先基于上下文对token编码,然后pooling出句子表示再分类。在最终池化时,max-pooling通常表现更好,因为文本分类经常是主题上的分类,从句子中一两个主要的词就可以得到结论,其他大多是噪声,对分类没有意义。而到更细粒度的分析时,max-pooling可能又把有用的特征去掉了,这时便可以用attention进行句子表示的融合: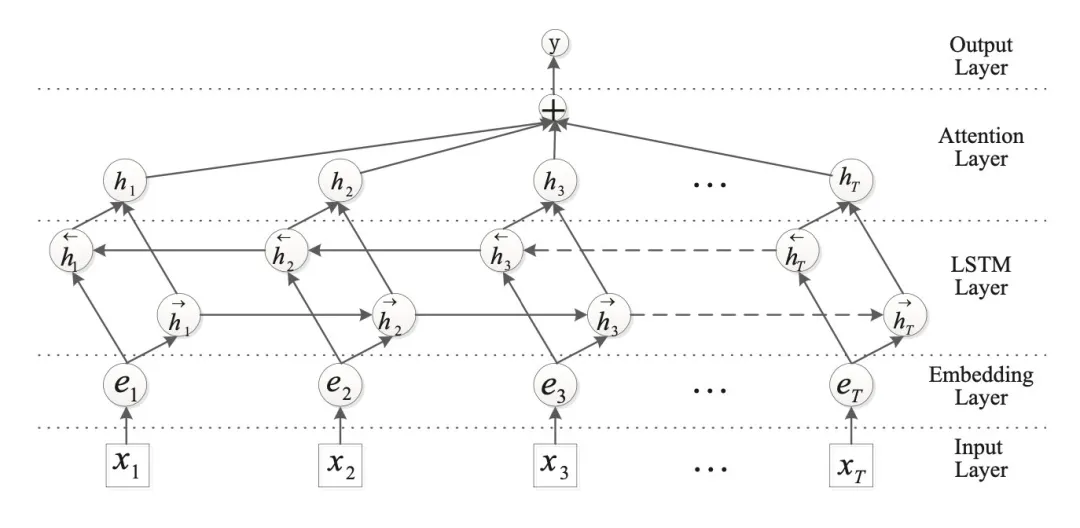
6 HAN
6.1 相关资料
论文《Hierarchical Attention Networks for Document Classification》 TensorFlow实现源码:https://github.com/ematvey/hierarchical-attention-networks?utm_source=catalyzex.com Keras实现源码:https://github.com/richliao/textClassifier
6.2 介绍
上文都是句子级别的分类,虽然用到长文本、篇章级也是可以的,但速度精度都会下降,于是有研究者提出了层次注意力分类框架,即Hierarchical Attention。先对每个句子用 BiGRU+Att 编码得到句向量,再对句向量用 BiGRU+Att 得到doc级别的表示进行分类: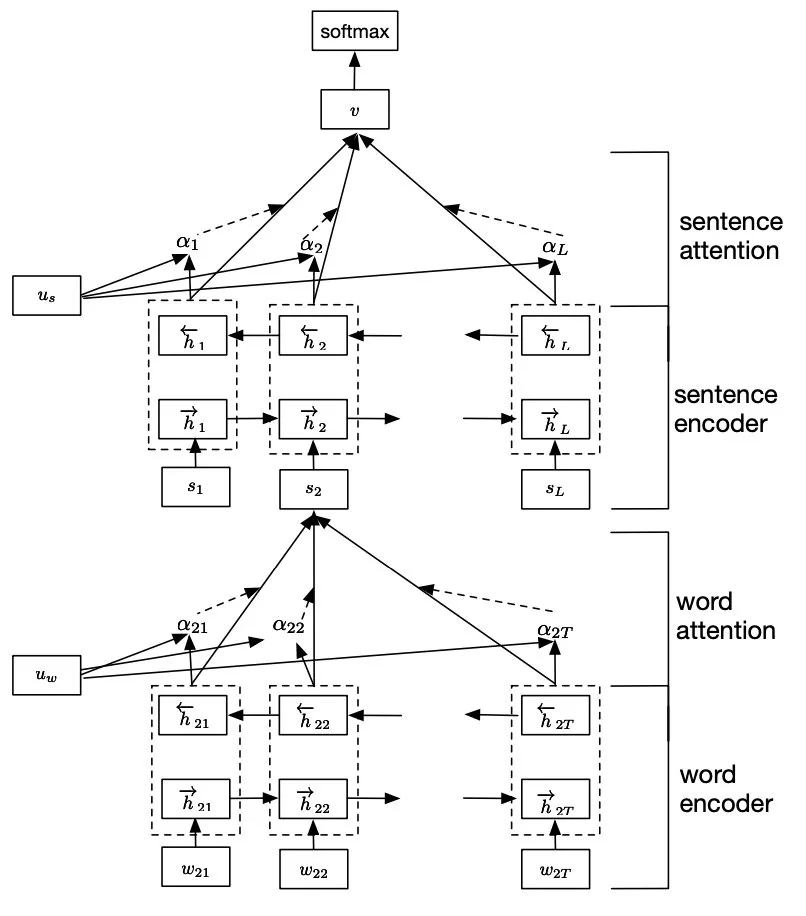
7 Bert
7.1 相关资料
7.2 介绍
BERT分类的优化可以尝试:
- 多试试不同的预训练模型,比如RoBERT、WWM、ALBERT
- 除了 [CLS] 外还可以用 avg、max 池化做句表示,甚至可以把不同层组合起来
- 在领域数据上增量预训练
- 集成蒸馏,训多个大模型集成起来后蒸馏到一个上
- 先用多任务训,再迁移到自己的任务

若有收获,就点个赞吧
0 人点赞
