一、实验目的
利用深度学习实现猫狗动物识别,采用Kaggle提供的公开数据集,训练深度学习模型,对测试集猫狗中的图片准确分类。通过该实验掌握深度学习中基本的CV处理过程。
二、实验原理
(1)采用用卷积神经网络训练
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
(2)卷积层
设 f(x),g(x) 是 R 上的两个可积函数,则卷积定义为:
离散形式定义为:
下图展示了一步计算的具体过程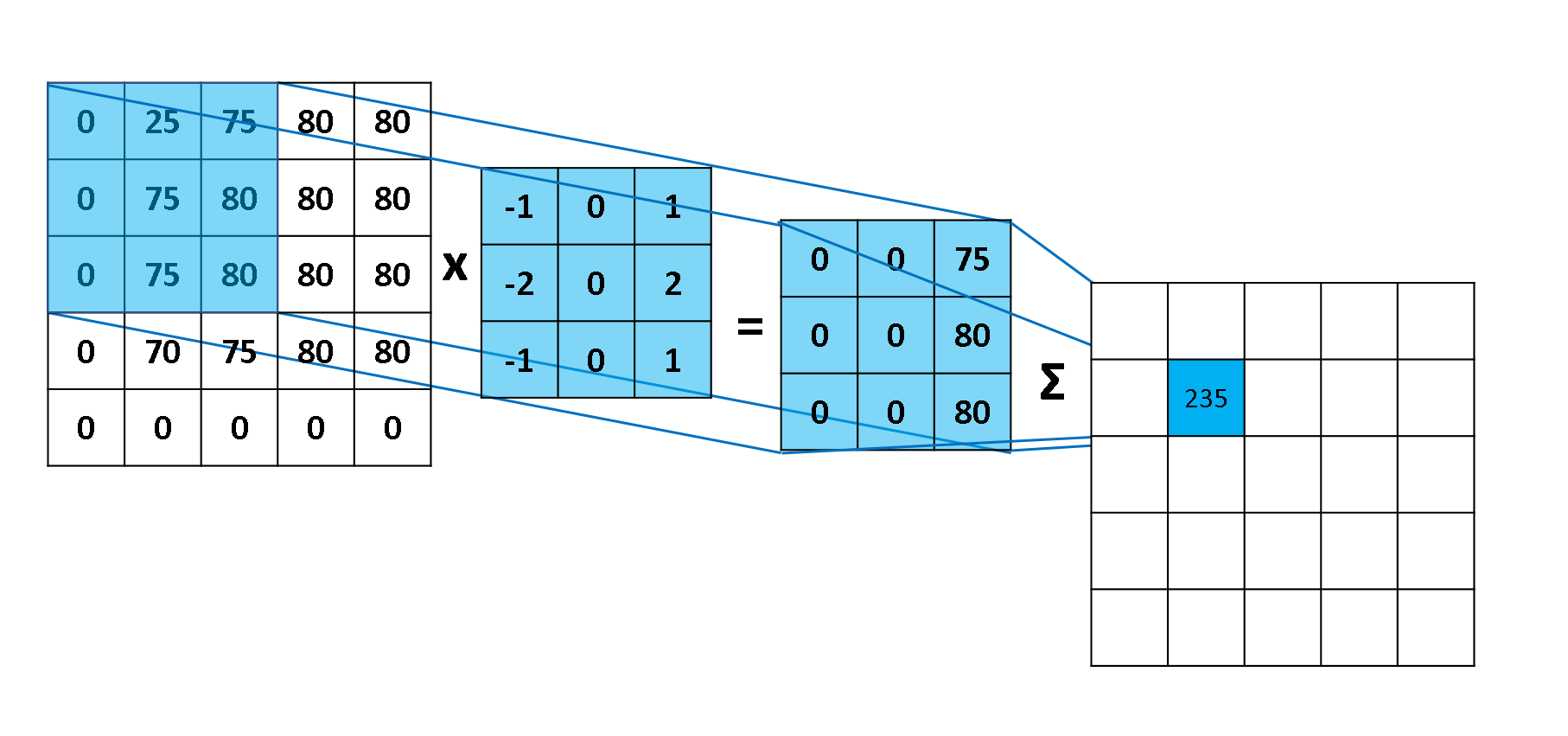
(3)非线性层
非线性层并不是 CNN 特有的网络层,一般情况下会使用 ReLU 作为模型的激活函数。
(4)池化层
池化层 是一个利用 池化函数 (pooling function) 对网络输出进行进一步调整的网络层。池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。常用的池化函数包括最大池化 (max pooling) 函数 (即给出邻域内的最大值) 和平均池化 (average pooling) 函数 (即给出邻域内的平均值) 等。但无论选择何种池化函数,当对输入做出少量平移时,池化对输入的表示都近似 不变 (invariant)。局部平移不变性 是一个很重要的性质,尤其是当我们关心某个特征是否出现而不关心它出现的位置时。
池化层同卷积层类似,具有三个比较重要的参数:pool_size,strides 和 padding,分别表示池化窗口的大小,步长以及是否对图像的外侧进行补零操作。池化层同时也能够提高网络的计算效率
(5)全连接层
全链接层 (Fully-connected or Dense Layer) 的目的就是将我们最后一个池化层的输出连接到最终的输出节点上。例如,最后一个池化层的输出大小为 [5×5×16],也就是有 5×5×16=400 个节点,对于手写数字识别的问题,我们的输出为 0 至 9 共 10 个数字,采用 one-hot 编码的话,输出层共 10 个节点。例如在 LeNet 中有 2 个全连接层,每层的节点数分别为 120 和 84,在实际应用中,通常全连接层的节点数会逐层递减。需要注意的是,在进行编码的时候,第一个全连接层并不是直接与最后一个池化层相连,而是先对池化层进行 flatten 操作,使其变成一个一维向量后再与全连接层相连。
(6)输出层
输出层根据具体问题的不同会略有不同,例如对于手写数字识别问题,采用 one-hot 编码的话,输出层则包含 10 个节点。对于回归或二分类问题,输出层则仅包含 1 个节点。当然对于二分类问题,我们也可以像多分类问题一样将其利用 one-hot 进行编码,例如 [1,0] 表示类型 0,[0,1] 表示类型 1。
三、实验内容
(1)训练模型
数据集:采用kaggle公开的猫狗数据集,文件名称是cat..jpg或dog..jpg
神经网络:卷积神经网络
损失函数:分类交叉熵
优化器:Adam
评价准则:准确率
Epochs:100
(2)测试模型
测试集:采用kaggle公开的猫狗测试集,没有标签
(3)环境
python 3.8 Tensorflow 2.3 numpy pandas matplotlib cv2
四、实验过程
(1)数据集的准备
猫狗识别的数据集依旧可以从Kaggle上下载,数据集下载链接:https://www.kaggle.com/c/dogs-vs-cats
用Python进行处理分类,文件夹train里面放着25000张图像,猫和狗的图像分别都是12500张,图像名称上都有标明类别。文件夹test里面放的是测试集,里面有12500张图像,都没有标签,要自己来预测分类。
import shutilimport osdef remove_file(old_path, new_path):print(old_path)print(new_path)filelist = os.listdir(old_path) # 列出该目录下的所有文件,listdir返回的文件列表是不包含路径的。# print(filelist)cat_n =0dog_n = 0for file in filelist:src = os.path.join(old_path, file)if not os.path.isfile(src):continueanimal_str = str(file).split('.')[0]if animal_str =='cat':if cat_n < 2500:cat_path = os.path.join('./validation/cat/', file)shutil.move(src, cat_path)cat_n +=1elif cat_n < 12500:cat_path = os.path.join('./train/cat/', file)shutil.move(src, cat_path)cat_n += 1else:os.remove(src)elif animal_str == 'dog':if dog_n < 2500:dog_path = os.path.join('./validation/dog/', file)shutil.move(src, dog_path)dog_n += 1elif dog_n < 12500:dog_path = os.path.join('./train/dog/', file)dog_n += 1shutil.move(src, dog_path)else:os.remove(src)else:continueif __name__ == '__main__':os.makedirs('./train/cat/')os.makedirs('./train/dog/')os.makedirs('./validation/cat/')os.makedirs('./validation/dog/')remove_file(r"./train/", r"./validation/")
把数据集目录整理成如下的形式
(2)数据集的导入
在训练前,先导入训练集和验证集。使用keras.preprocessing.image.ImageDataGenerator()做图像增强的数据预处理设置,再使用flow_from_directory()从文件路径中导入数据集,并设置图像大小、batch_size和是否shuffle等参数。
# import the data and make a augmentationtrain_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest',)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(width, height),batch_size=batch_size,seed=7,shuffle=True,class_mode='categorical')valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255,)valid_generator = valid_datagen.flow_from_directory(valid_dir,target_size=(width, height),batch_size=valid_batch_size,seed=7,shuffle=False,class_mode="categorical")
(3)搭建神经网络结构
搭建一个非常基础的卷积神经网络
model = keras.models.Sequential([keras.layers.Conv2D(filters=32, kernel_size=3,padding='same', activation='relu',input_shape=[width, height, channel]),keras.layers.Conv2D(filters=32, kernel_size=3,padding='same', activation='relu'),keras.layers.MaxPool2D(pool_size=2),keras.layers.Conv2D(filters=64, kernel_size=3,padding='same', activation='relu'),keras.layers.Conv2D(filters=64, kernel_size=3,padding='same', activation='relu'),keras.layers.MaxPool2D(pool_size=2),keras.layers.Conv2D(filters=128, kernel_size=3,padding='same', activation='relu'),keras.layers.Conv2D(filters=128, kernel_size=3,padding='same', activation='relu'),keras.layers.MaxPool2D(pool_size=2),keras.layers.Flatten(),keras.layers.Dense(128, activation='relu'),keras.layers.Dense(num_classes, activation='softmax')])
(4)模型训练
优化器使用adam,损失函数使用’categorical_crossentropy’ ,metrics参数填入accuracy,评估模型在训练和测试过程中的准确率。
model.compile(loss='categorical_crossentropy',optimizer='adam', metrics=['accuracy'])model.summary()# set path of saving modellogdir = './graph_def_and_weights'if not os.path.exists(logdir):os.mkdir(logdir)output_model_file = os.path.join(logdir,"catDog_weights.h5")print('Start training ...')# start trainingmode = input('Select mode: 1.Train 2.Predict\nInput number: ')if mode == '1':callbacks = [keras.callbacks.TensorBoard(logdir),keras.callbacks.ModelCheckpoint(output_model_file,save_best_only=True,save_weights_only=True),keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)]history = trainModel(model, train_generator, valid_generator, callbacks)plot_learning_curves(history, 'accuracy', epochs, 0, 1)plot_learning_curves(history, 'loss', epochs, 0, 5)
(5)模型预测
先读取文件夹test中的图像,使用 model.predict() 进行预测,再根据预测结果把图像进行分类,分别存储到 猫 和 狗 的文件夹中。
def predictModel(model, output_model_file):# load the weights of modelmodel.load_weights(output_model_file)os.makedirs('./save', exist_ok=True)os.makedirs('./save/cat', exist_ok=True)os.makedirs('./save/dog', exist_ok=True)test_dir = './test/' # 1-12500.jpgfor i in range(1, 12500):img_name = test_dir + '{}.jpg'.format(i)img = cv2.imread(img_name)img = cv2.resize(img, (width, height))img_arr = img / 255.0img_arr = img_arr.reshape((1, width, height, 3))pre = model.predict(img_arr)if pre[0][0] > pre[0][1]:cv2.imwrite('./save/cat/' + '{}.jpg'.format(i), img)print(img_name, ' is classified as Cat.')else:cv2.imwrite('./save/dog/' + '{}.jpg'.format(i), img)print(img_name, ' is classified as Dog.')
五、实验分析
(1)训练过程如下
Epoch 35/100313/313 [==============================] - 87s 279ms/step - loss: 0.2434 - accuracy: 0.8960 - val_loss: 0.2657 - val_accuracy: 0.8918Epoch 36/100313/313 [==============================] - 87s 279ms/step - loss: 0.2385 - accuracy: 0.8995 - val_loss: 0.1975 - val_accuracy: 0.9184Epoch 37/100313/313 [==============================] - 87s 279ms/step - loss: 0.2302 - accuracy: 0.9008 - val_loss: 0.2139 - val_accuracy: 0.9108Epoch 38/100313/313 [==============================] - 87s 279ms/step - loss: 0.2297 - accuracy: 0.9038 - val_loss: 0.1968 - val_accuracy: 0.9206Epoch 39/100313/313 [==============================] - 87s 279ms/step - loss: 0.2232 - accuracy: 0.9044 - val_loss: 0.1909 - val_accuracy: 0.9220Epoch 40/100313/313 [==============================] - 87s 279ms/step - loss: 0.2234 - accuracy: 0.9049 - val_loss: 0.1916 - val_accuracy: 0.9228Epoch 41/100313/313 [==============================] - 87s 279ms/step - loss: 0.2185 - accuracy: 0.9072 - val_loss: 0.2005 - val_accuracy: 0.9164Epoch 42/100313/313 [==============================] - 87s 279ms/step - loss: 0.2167 - accuracy: 0.9104 - val_loss: 0.2019 - val_accuracy: 0.9162Epoch 43/100313/313 [==============================] - 87s 279ms/step - loss: 0.2148 - accuracy: 0.9089 - val_loss: 0.2241 - val_accuracy: 0.9064Epoch 44/100313/313 [==============================] - 87s 279ms/step - loss: 0.2097 - accuracy: 0.9116 - val_loss: 0.1901 - val_accuracy: 0.9182
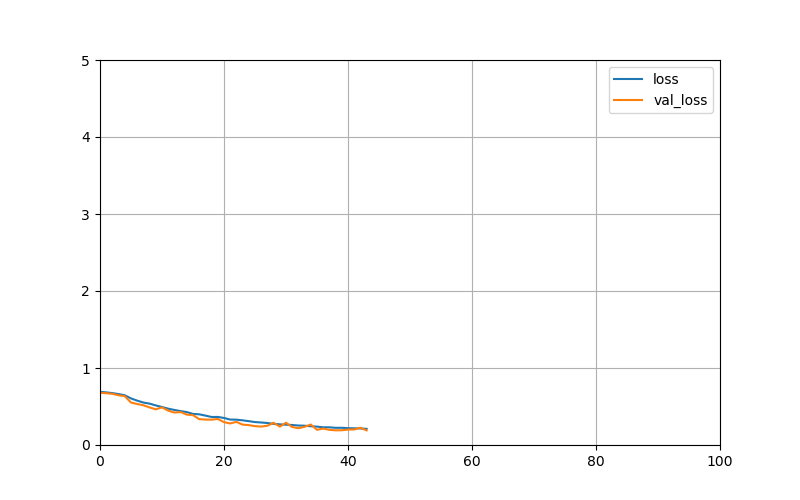
由于使用了EarlyStopping,当准确率在几个epochs内都没有提高超过一定幅度的话就会停止训练。由图可以看出,训练到40个epoch左右验证集的准确率达到91.16%多了。下面是训练过程的准确率和损失值变化曲线!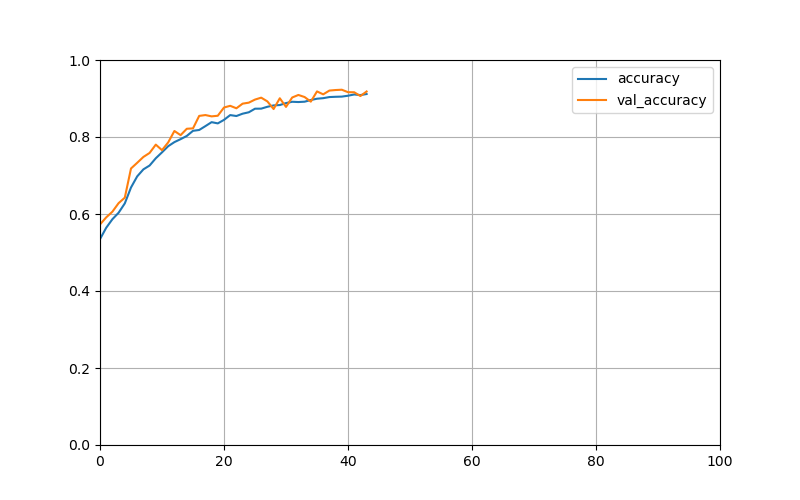
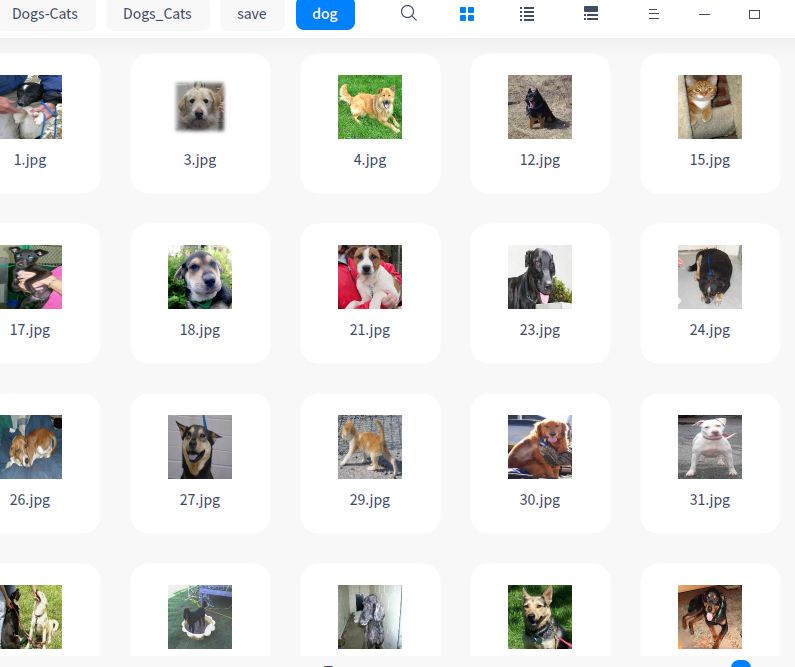
(2)模型测试
测试的数据会生成两个文件夹/save/cat和/save/dog,分别存储模型分类后的图片。因为并没有实际测试集的label,只能通过人工观察,还是有部分分类错误的图片。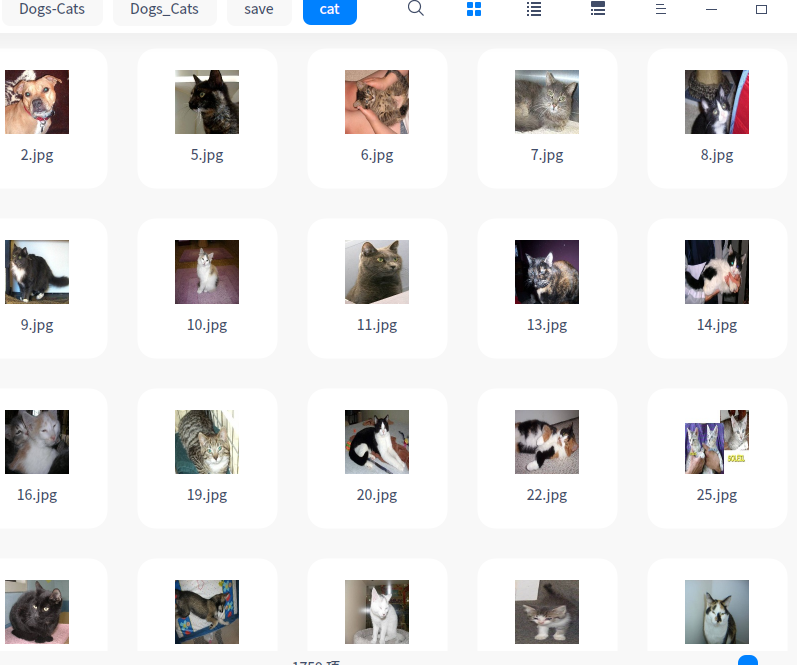
六、实验体会与心得
通过该案例的运行和分析,掌握了基本的CV,学会了一些数据处理的基本操作,包括对文件的处理。对Python和TensorFlow2.X 的keras API的使用更加熟练。

若有收获,就点个赞吧
0 人点赞
