
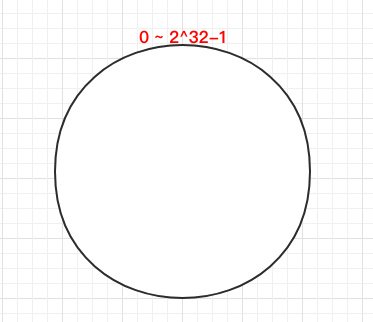
一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 0 ~ 2^32-1。如下图:
之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 hash(key),散列之后如下:
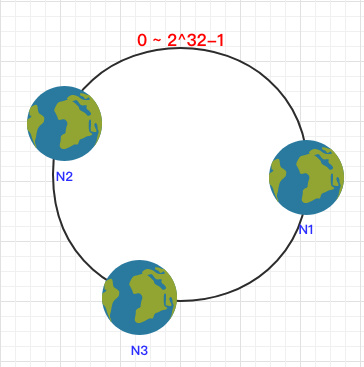
之后需要将数据定位到对应的节点上,使用同样的 hash 函数 将 Key 也映射到这个环上。
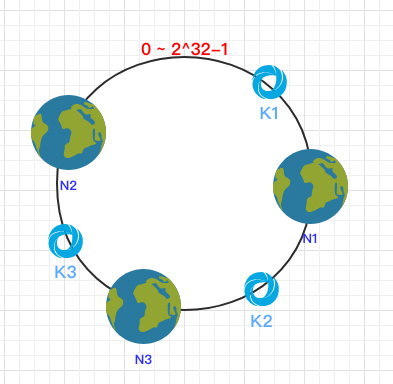
这样按照顺时针方向就可以把 k1 定位到 N1节点,k2 定位到 N3节点,k3 定位到 N2节点。
容错性这时假设 N1 宕机了: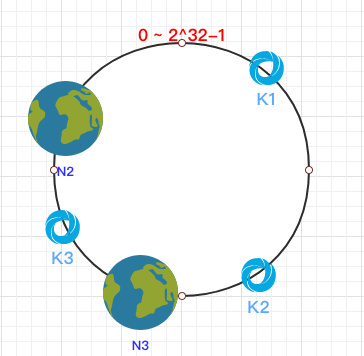
依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
拓展性当新增一个节点时:
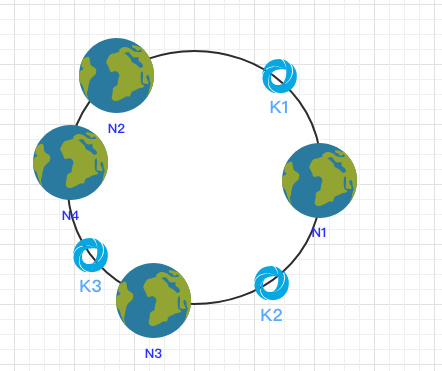
在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受印象的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
hash偏斜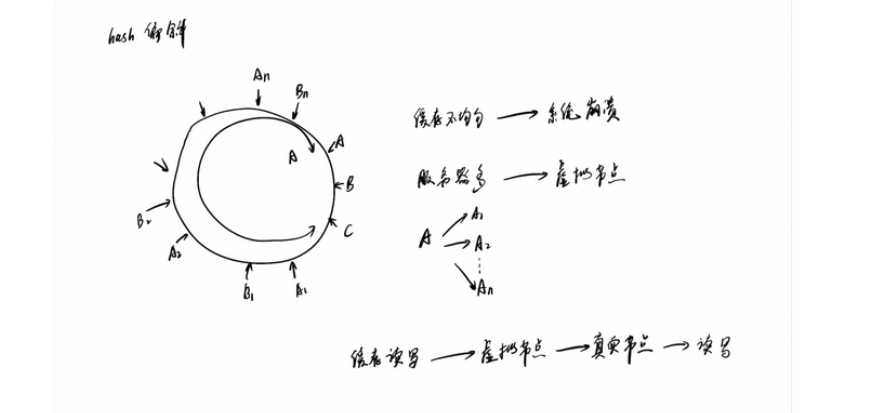
当节点较少时会出现数据分布不均匀的情况: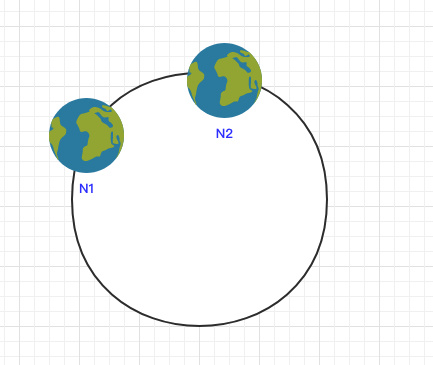
都在 N1 节点,只有少量的数据在 N2 节点。
为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点: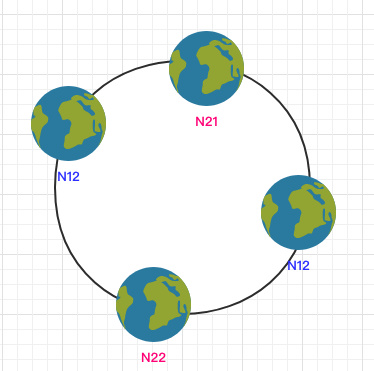
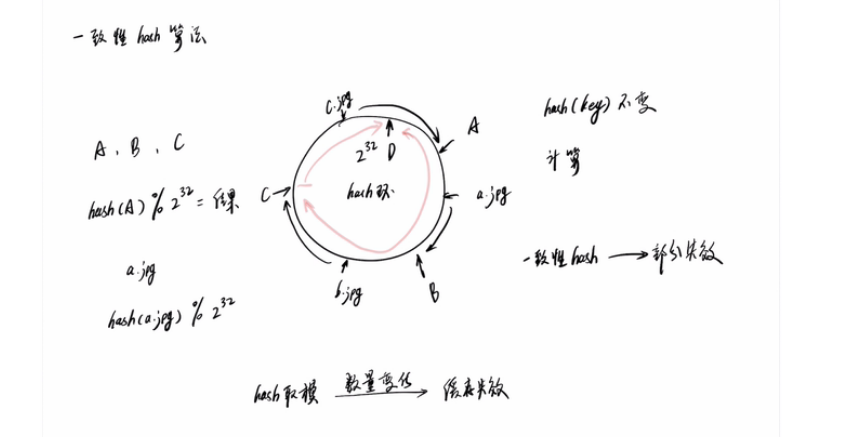
一致性哈希算法
假设我们有k个机器,数据的哈希值的范围是 [0, MAX] 。我们将整个范围划分成 m 个小区间( m 远大于 k ),每个机器负责 m/k 个小区间。当有新机器加入的时候, 我们就将某几个小区间的数据,从原来的机器中搬移到新的机器中。这样,既不用全部重新哈希、搬移数据,也保持了各个机器上数据数量的均衡。
一致性哈希解决分布式存储结构下增加和删除节点所带来的问题
1 首先,我们把全量的缓存空间当做一个环形存储结构。环形空间总共分成2^32个缓存区,在Redis中则是把缓存key分配到16384个slot。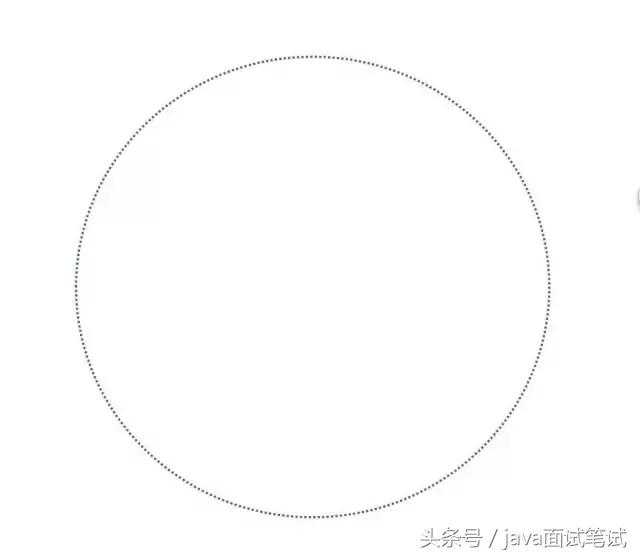
2.每一个缓存key都可以通过Hash算法转化为一个32位的二进制数,也就对应着环形空间的某一个缓存区。我们把所有的缓存key映射到环形空间的不同位置。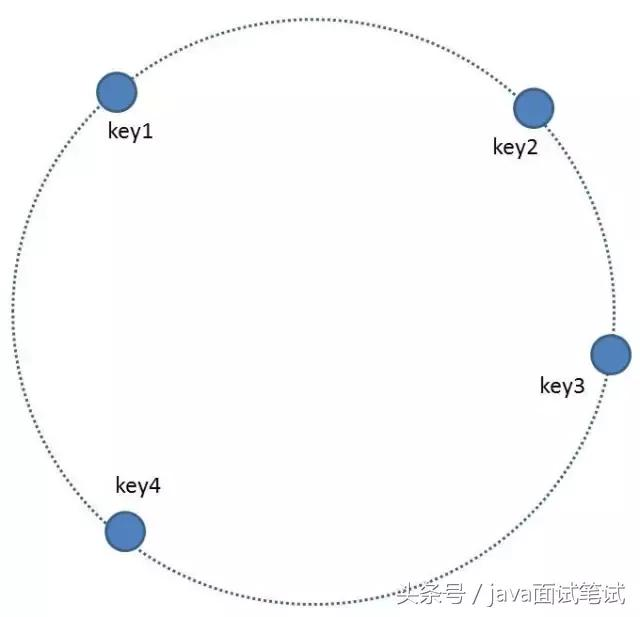
3.我们的每一个缓存节点(Shard)也遵循同样的Hash算法,比如利用IP做Hash,映射到环形空间当中。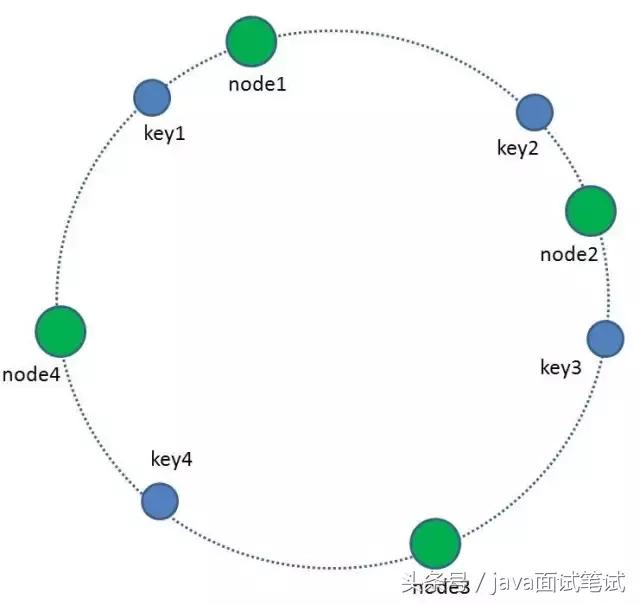
4.如何让key和节点对应起来呢?很简单,每一个key的顺时针方向最近节点,就是key所归属的存储节点。所以图中key1存储于node1,key2,key3存储于node2,key4存储于node3。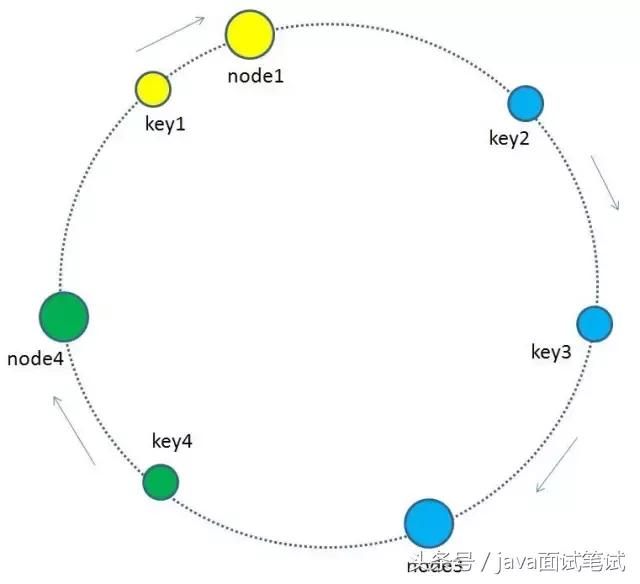
增加节点
当缓存集群的节点有所增加的时候,整个环形空间的映射仍然会保持一致性哈希的顺时针规则,所以有一小部分key的归属会受到影响。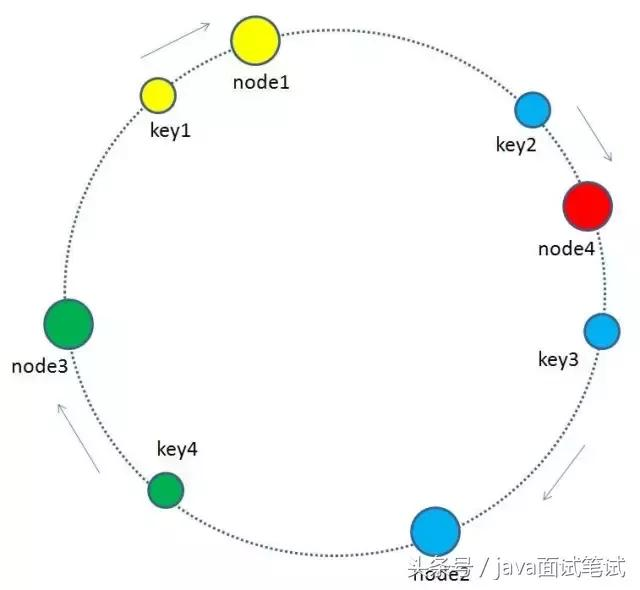
图中加入了新节点node4,处于node1和node2之间,按照顺时针规则,从node1到node4之间的缓存不再归属于node2,而是归属于新节点node4。因此受影响的key只有key2。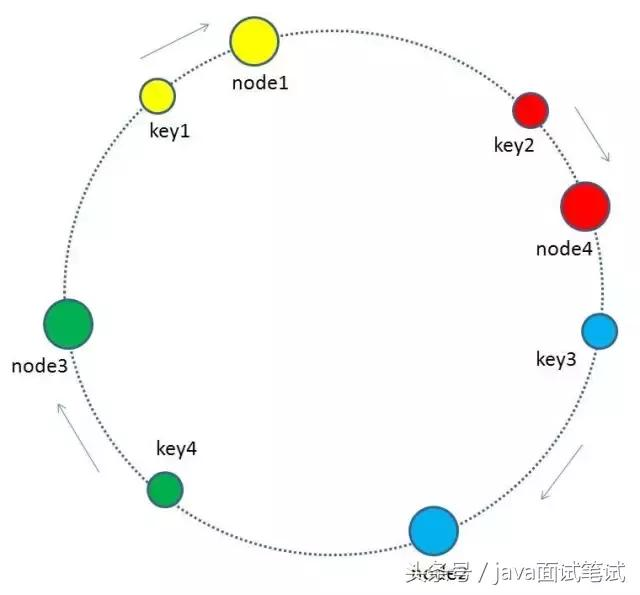
删除节点
当缓存集群的节点需要删除的时候(比如节点挂掉),整个环形空间的映射同样会保持一致性哈希的顺时针规则,同样有一小部分key的归属会受到影响。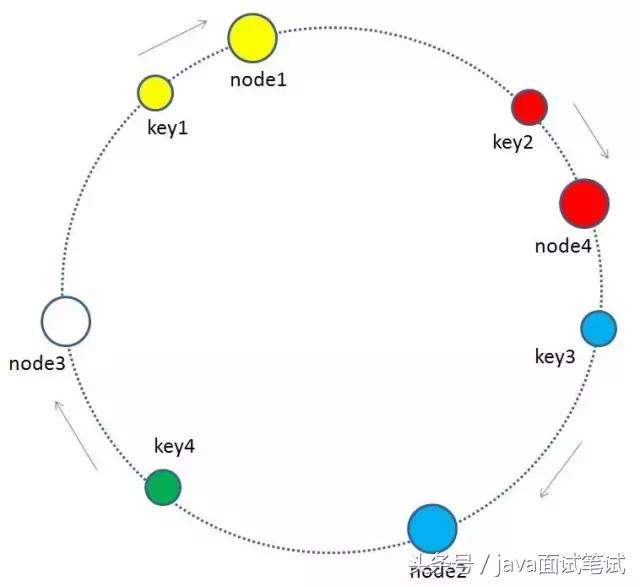
虚拟节点
基于原来的物理节点映射出N个子节点,最后所有的子节点映射到环形空间上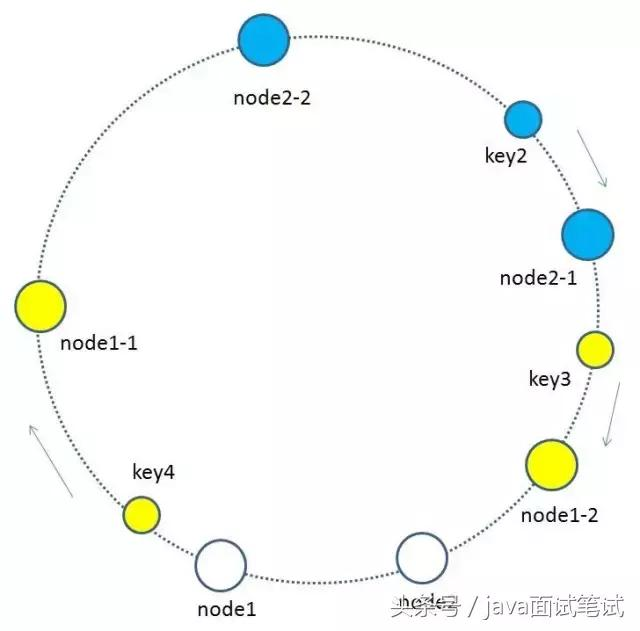
参考
https://blog.csdn.net/xaccpJ2EE/article/details/82993120
https://www.bilibili.com/video/av25184175?from=search&seid=10220130562591473572
https://zhuanlan.zhihu.com/p/57988082

若有收获,就点个赞吧
0 人点赞
