概念
链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址,通常记录下个结点地址的指针叫作后继指针。或者需要记录链行的上一个节点的地址,称为前继指针。
数据存储在节点Node中
头结点 :第一个结点叫作头结点,用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。
尾节点:
最后一个结点叫作尾结点,尾结点的指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
优点
链表结构可以充分利用计算机内存空间,实现灵活的内存动态
缺点:
1链表要想随机访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
2链表由于增加了结点的指针域,空间开销比较大
类别
单链表(Single-Linked List)
一个单链表的节点(Node)分为两个部分,第一个部分(data)保存或者显示关于节点的信息,另一个部分存储下一个节点的地址。最后一个节点存储地址的部分指向空值。
class Node{public E e;public Node next;}
go语言
type ListNode struct {Val intNext *ListNode}
Dummy Node
Dummy node 是链表问题中一个重要的技巧,中文翻译叫“哑节点”。
Dummy node 是一个虚拟节点,也可以认为是标杆节点。Dummy node 就是在链表表头 head 前加一个节点指向 head,即
dummy.next -> head。Dummy node 的使用主要为了对单链表没有前向指针的问题,保证链表的 head
不会在删除操作中丢失。一般的方法current = current.next 是无法删除 head
元素的,所以这个时候如果有一个dummy node在head的前面。
所以,当链表的 head 有可能变化(被修改或者被删除)时,使用 dummy node 可以很好的简化代码,最终返回 dummy.next 即新的链表。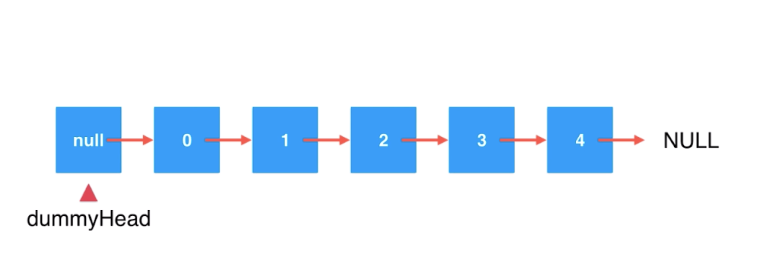
dummyHead存储的值是空,next指向链表中的头结点
func makeLinkedList(list []int)*ListNode{
dummyNode := &ListNode{} // 创建哑结点 指向头节点
curr := dummyNode
for i:=0;i<len(list);i++{
curr.Next= &ListNode{Val:list[i]}
curr = curr.Next
}
return dummyNode.Next
}
func main() {
head := makeLinkedList([]int{1,2,3,4,5})
}
循环链表
单链表的尾结点指针指向空地址,循环链表的尾结点指针是指向链表的头结点。
双向链表Doubly Linked List
双向链表支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
操作
dummyHead为链表设置虚拟节点
private Node dumyHead;
private int size;
public LinkedList(){
dumyHead = new Node(null);
size = 0;
}
public void add(int index, E e){
if (index<0 ||index>size){
return;
}
Node prev = dumyHead;
for(int i =0;i<index;i++){
prev = prev.next;
}
Node node = new Node(e);
node.next = prev.next;
prev.next = node;
//prev.next = new node(e.pre.next)
size++;
}
Get
链表查找元素不能像数组那样通过下标快速进行定位,只能从头结点开始向后一个个节点逐一查找
public E Get(int index){
if(index<0||index>=size){
throw new IllegalArgumentException("GET faile");
}
Node curr = dumyHead.next;
for (int i =0;i<index;i++){
curr = curr.next;
}
return curr.e;
}
update
public void set(int index,E e){
if(index<0||index>=size){
throw new IllegalArgumentException("GET faile");
}
Node curr = dumyHead.next;
for (int i =0;i<index;i++){
curr = curr.next;
}
curr.e = e;
}
contain
public boolean contain(E e){
Node curr = dumyHead.next;
while (curr!=null){
if (curr.e.equals(e)){
return true;
}
curr = curr.next;
}
return false;
}
delete
将该节点的上一个节点的next指向该节点的下一个节点。
public E remove(int index){
if(index<0||index>=size){
throw new IllegalArgumentException("GET faile");
}
Node prev = dumyHead;
for (int i =0;i<index;i++){
prev = prev.next;
}
Node delNode = prev.next;
prev.next = delNode.next;
delNode.next = null;
size--;
return delNode.e;
}
时间复杂度
space O(n)
prepend O(1)
append O(1)
lookup O(n)
insert O(1)
delete O(1)
链表指针的鲁棒性
综合上面讨论的两种基本操作,链表操作时的鲁棒性问题主要包含两个情况:
- 当访问链表中某个节点 curt.next 时,一定要先判断 curt 是否为 null。
- 全部操作结束后,判断是否有环;若有环,则置其中一端为 null。
p->next = x; // 将 p 的 next 指针指向 x 结点;
x->next = p->next; // 将 x 的结点的 next 指针指向 b 结点;
p->next 指针在完成第一步操作之后,已经不再指向结点 b 了,而是指向结点 x。第 2 行代码相当于将 x 赋值给 x->next,自己指向自己。因此,整个链表也就断成了两半
快慢指针
一个环形跑道上,两个运动员在同一地点起跑,一个运动员速度快,一个运动员速度慢。当两人跑了一段时间,速度快的运动员必然会从速度慢的运动员身后再次追上并超过,原因很简单,因为跑道是环形的。
快慢指针也是一个可以用于很多问题的技巧。所谓快慢指针中的快慢指的是指针向前移动的步长,每次移动的步长较大即为快,步长较小即为慢,常用的快慢指针一般是在单链表中让快指针每次向前移动2,慢指针则每次向前移动1。快慢两个指针都从链表头开始遍历,于是快指针到达链表末尾的时候慢指针刚好到达中间位置,于是可以得到中间元素的值。快慢指针在链表相关问题中主要有两个应用:
- 快速找出未知长度单链表的中间节点 设置两个指针
*fast、*slow都指向单链表的头节点,其中*fast的移动速度是*slow的2倍,当*fast指向末尾节点的时候,slow正好就在中间了。 - 判断单链表是否有环 利用快慢指针的原理,同样设置两个指针
*fast、*slow都指向单链表的头节点,其中*fast的移动速度是*slow的2倍。如果*fast = NULL,说明该单链表 以NULL结尾,不是循环链表;如果*fast = *slow,则快指针追上慢指针,说明该链表是循环链表。
参考

若有收获,就点个赞吧
0 人点赞
