概述
不管是散列还是哈希,这都是中文翻译的差别,英文其实就是 “Hash” 。所以,我们常听到有人把 “散列表 ” 叫作 “哈希表”“Hash 表 ” ,把 “哈希算法 ” 叫作 “Hash 算法” 或者 “散列算法 ”。散列表用的是数组支持下标随机访问数据的特性,它是数组的一种扩展。散列表中最重要的是散列函数和散列冲突。
原理
散列表用的是数组支持下标随机访问时时间复杂度时O(1)的特性。通过散列函数把元素的key映射到下标,然后将数据存储在数组中对应下标的位置。当我们按照键值key查询元素时,我们用同样的散列函数,将key转换为数组下标,从对应的数组下标的位置取数据。
哈希函数
哈希函数的作用就是把键转换成索引值,散列函数定义为hash(key),其中key表示元素的键值,hash(key)的值表示经过散列函数计算得到的散列值。散列函数设计的好坏决定了散列冲突的概率,也决定散列表的性能。
原则
1一致性 如果a==b 则hash(a)==hash(b)
2 高效性 计算高效简单
3 均匀性 哈希值均匀分布
hashcode
整型
小范围正整数直接使用
小范围负整数进行偏移
大整数
通常做法取模,也就是取大整数的后几位,容易出现分布不均匀。模一个素数
字符串
转换成整数处理
散列冲突
一个不同的key对应的散列值都不一样的散列函数是无法满足的,即使时署名的MD5,SHA,CRC等哈希算法也无法完全避免这种散列冲突。而且数组的存储空间有限,也会加大散列冲突的概率。
开放寻址法
核心思想:如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。
线性探测
当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
二次探测
和线性探测相似,线性探测的步长是1,hash(key)+0,hash(key)+1,…,hash(key)+n;二次探测的步长变成原来的二次方,探测下标序列是hash(key)+0,hash(key)+ ,hash(key)+
,hash(key)+ ,…,hash(key)+
,…,hash(key)+ )
)
双重散列
不只使用一个散列函数,而是使用一组散列函数hash1(key),hash2(key),…hashn(key) 先使用第一个散列函数,如果计算得到的存储位置已经被占用(即出现散列冲突),再使用第二个散列函数,以此类推,知道找到空闲的存储位置)。
负载因子
装载因子的计算公式是:装载因子=填入表中的元素个数/散列表的长度
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
散列表和数组一样,支持插入、查找和删除操作。这里需要注意的是,在做元素删除操作时候,将删除的元素特殊标记为deleted。所以桑线性探测查找的时候,遇到标记为deleted的空间,并非停下来,而是继续向下探测。
开放寻址法的优点:开放寻址法不像链表法,需要拉很多链表。散列表中的数据都存储在数组中,可以有效地利用CPU缓存加快查询速度。而且,这种方法实现的散列表,序列化起来比较简单。链表法包含指针,序列化复杂。
开放寻址法的缺点:用开放寻址法解决冲突的散列表,删除数据比较复杂,需要特殊标记已经删除掉的数据。而且,数据全部存储在一个数组中,比起链表冲突的代价更高。
所以开放寻址法适合数据量比较小,装载因子小的应用场景。
ThreadLocalMap通过线性探测的开放寻址法来解决冲突。
链表法
在散列表中的每个位置(一般我们称之为桶或者槽)都会对应一条链表,所有散列值相同的元素我们都会放在相同槽位对应的链表
Java中LinkedHashMap采用链表法解决冲突。
链表法的优点:对于内存的利用率比开放寻址要高,链表节点可以在需要的时候在创建,无需像开放寻址法那样事先申请。链表法比起开放寻址法,对于大转载因子的容忍度要高。开放寻址法只能使用装载因子小于1的情况,当装载因子接近于1时就可能会有大量的冲突,导致大龄的探测、再散列等,性能会下降很多。但对于链表来说,只要散列函数的值随机均匀,即使装载因子变成10,也就是链表长度变长了而已,虽然查找效率变慢,但相比顺序查找而言会快很多。
所以基于链表的散列冲突处理方法比较适合存储大独享、大数据量的散列表,而且比开放寻址法,他更加灵活,支持更多的优化策略,比如红黑树代替链表。
常见应用
安全
哈希算法是MD5(MD5 Message-Digest Algorithm,MD5 消息摘要算法)和 SHA (Secure Hash Algorithm,安全散列算法)。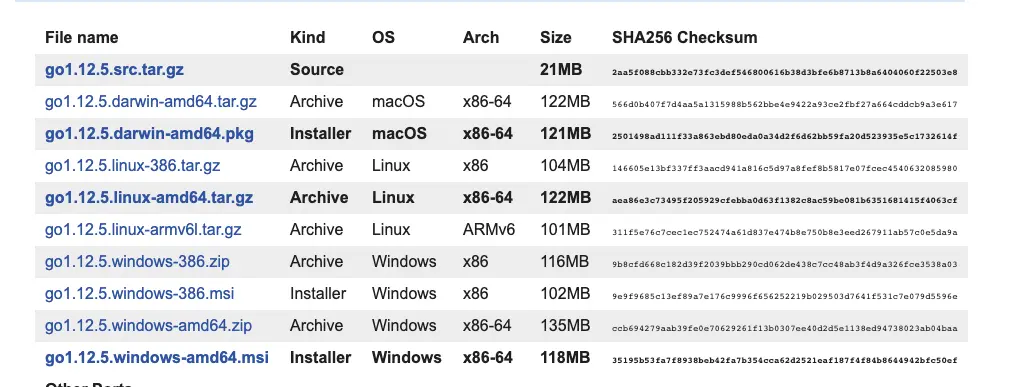
数据传输中的问题
A 向 B 发送的消息可能会在传输途中被 X 偷看(如右图)。这就是“窃听”。
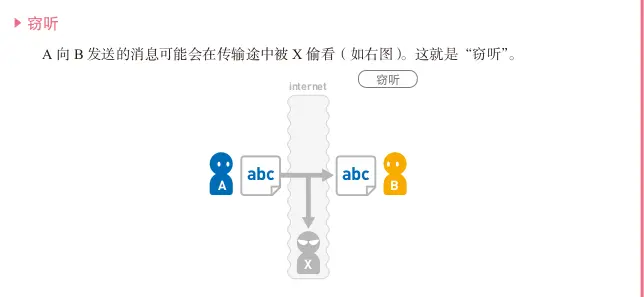
▶ 假冒
A 以为向 B 发送了消息,然而 B 有可能是 X 冒充的(如下页上图);反过来, B 以为从 A
那里收到了消息,然而 A 也有可能是 X 冒充的。这种问题就叫作“假冒”。
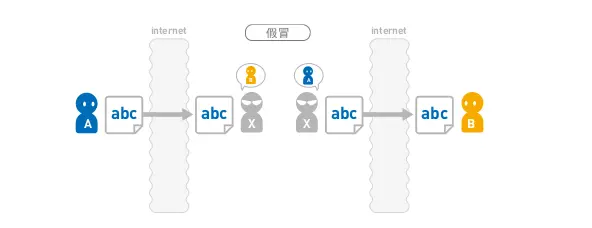
篡改
即便 B 确实收到了 A 发送的消息,该消息的内容在途中就被 X 更改了。
这种行为就叫作“篡改”。除了被第三者篡改外,通信故障导致的数据损坏也可能会使消息内容发生变化。
事后否认
B 从 A 那里收到了消息,但作为消息发送者的 A 可能对 B 抱有恶意,并在事后声称“这不是我发送的消息”
这种情况会导致互联网上的商业交易或合同签署无法成立。这种行为便是“事后否认”。
| 安全问题 | 解决方案 |
|---|---|
| 窃听 | 加密 |
| 假冒 | 数字签名/消息认证码 |
| 篡改 | 数字签名/消息认证码 |
| 事后否认 | 数字签名 |
唯一标示
我们可以从图片的二进制码串开头取 100 个字节,从中间取 100 个字节,从最后再取 100 个字 节,然后将这 300 个字节放到一块,通过哈希算法(比如 MD5 ),得到一个哈希字符串,用它作为图片的唯一标识。通过这个唯一标识来判定图片是否在图库 中,这样就可以减少很多工作量。
负载均衡
Hash 取模
余数总是在一个固定的范围内。
整数是没有边界的,它可能是正无穷,也可能是负无穷。但是余数却可以通过某 一种关系,让整数处于一个确定的边界内。
例如计算星期,2019年的6月3号是周一 那么30天之后的2019年7月3日是星期几
拿 30 除以 7(因为一个星期有 7 天),然后余 2,最后在今天的基础上加2天,这样你就能知道 30 天之后是星期三了。
index = hash(key) % N
其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
通过哈希算法,对客户端IP地址或者会话ID计算哈希值,将取得的哈希值与服务器列表的大小进 行取模运算,最终得到的值就是应该被路由到的服务器编号。 这样,我们就可以把同一个IP过来的所有请求,都路由到同一个后端服务器上。

若有收获,就点个赞吧
0 人点赞
