过拟合与欠拟合
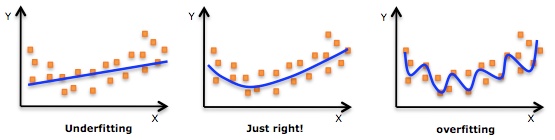
机器学习中一个重要的话题便是模型的泛化能力,泛化能力强的模型才是好模型,对于训练好的模型,若在训练集表现差,不必说在测试集表现同样会很差,这可能是欠拟合导致;若模型在训练集表现非常好,却在测试集上差强人意,则这便是过拟合导致的,过拟合与欠拟合也可以用 Bias 与 Variance 的角度来解释,欠拟合会导致高 Bias,过拟合会导致高 Variance,所以模型需要在 Bias 与 Variance 之间做出一个权衡。
使用简单的模型去拟合复杂数据时,会导致模型很难拟合数据的真实分布,这时模型便欠拟合了,或者说有很大的 Bias,Bias 即为模型的期望输出与其真实输出之间的差异;有时为了得到比较精确的模型而过度拟合训练数据,或者模型复杂度过高时,可能连训练数据的噪音也拟合了,导致模型在训练集上效果非常好,但泛化性能却很差,这时模型便过拟合了,或者说有很大的 Variance,这时模型在不同训练集上得到的模型波动比较大,Variance 刻画了不同训练集得到的模型的输出与这些模型期望输出的差异**。
模型处于过拟合还是欠拟合,可以通过画出误差趋势图来观察。若模型在训练集与测试集上误差均很大(如左),则说明模型的 Bias 很大,此时需要想办法处理 under-fitting ;若是训练误差与测试误差之间有个很大的 Gap(如右),则说明模型的 Variance 很大,这时需要想办法处理 over-fitting。
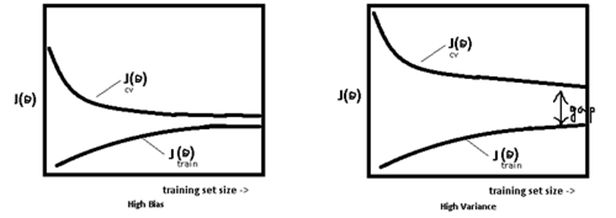
当模型效果很差时,应该检查模型是否处于欠拟合或者过拟合的状态,而不要一味的增多数据量,关于过拟合与欠拟合,这里给出几个解决方法。
常用解决办法
解决欠拟合的方法
- 增加新特征:可以考虑加入进特征组合、高次特征,来增大假设空间;
- 尝试非线性模型:比如核SVM 、决策树、DNN等模型;
- 如果有正则项可以较小正则项参数
 ;
; - Boosting:Boosting 往往会有较小的 Bias,比如 Gradient Boosting 等。
解决过拟合的方法
- 交叉检验:通过交叉检验得到较优的模型参数;
- 特征选择:减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间;
- 正则化:常用的有 L1、L2 正则。而且 L1正则还可以自动进行特征选择;
- 如果有正则项则可以考虑增大正则项参数 ;
- 增加训练数据可以有限的避免过拟合;
- Bagging:将多个弱学习器Bagging 一下效果会好很多,比如随机森林等。
DNN中常见的方法
- 早停策略:本质上是交叉验证策略,选择合适的训练次数,避免训练的网络过度拟合训练数据。
- 集成学习策略:而DNN可以用Bagging的思路来正则化。首先我们要对原始的m个训练样本进行有放回随机采样,构建N组m个样本的数据集,然后分别用这N组数据集去训练我们的DNN。即采用我们的前向传播算法和反向传播算法得到N个DNN模型的W,b参数组合,最后对N个DNN模型的输出用加权平均法或者投票法决定最终输出。不过用集成学习Bagging的方法有一个问题,就是我们的DNN模型本来就比较复杂,参数很多。现在又变成了N个DNN模型,这样参数又增加了N倍,从而导致训练这样的网络要花更加多的时间和空间。因此一般N的个数不能太多,比如5-10个就可以了。
- DropOut策略:所谓的Dropout指的是在用前向传播算法和反向传播算法训练DNN模型时,一批数据迭代时,随机的从全连接DNN网络中去掉一部分隐藏层的神经元。 在对训练集中的一批数据进行训练时,我们随机去掉一部分隐藏层的神经元,并用去掉隐藏层的神经元的网络来拟合我们的一批训练数据。使用基于dropout的正则化比基于bagging的正则化简单,这显而易见,当然天下没有免费的午餐,由于dropout会将原始数据分批迭代,因此原始数据集最好较大,否则模型可能会欠拟合。
L1和L2正则化方法
你也可以参考特征选择这部分内容中的正则化概念的介绍。
在这些方法中,重点讲解一下 L1 和 L2 正则化方法。L1 正则化和 L2 正则化原理类似,二者的作用却有所不同。
(1) L1正则项会产生稀疏解。
(2) L2正则项会产生比较小的解。
**
在 Matlab 的DeepLearn-Toolbox中,仅实现了 L2 正则项。而在 Keras 中,则包含了 L1 和 L2 的正则项。
假如我们的每个样本的损失函数是均方差损失函数,则所有的 m 个样本的损失函数为:

而 DNN 的L2正则化通常的做法是只针对与线性系数矩阵  ,而不针对偏倚系数
,而不针对偏倚系数  。利用我们之前的机器学习的知识,我们很容易可以写出 DNN 的 L2 正则化的损失函数:
。利用我们之前的机器学习的知识,我们很容易可以写出 DNN 的 L2 正则化的损失函数:

如果使用上式的损失函数,进行反向传播算法时,流程和没有正则化的反向传播算法完全一样,区别仅仅在于进行梯度下降法时, 的更新公式。回想我们在深度神经网络(DNN)反向传播算法(BP)中, 的梯度下降更新公式为:

则加入 L2 正则化以后,迭代更新公式变成:

注意到上式中的梯度计算中 m 我忽略了,因为  是常数,而除以 m 也是常数,所以等同于用了新常数 来代替
是常数,而除以 m 也是常数,所以等同于用了新常数 来代替 。进而简化表达式,但是不影响损失算法。类似的 L2 正则化方法可以用于交叉熵损失函数或者其他的 DNN 损失函数,这里就不累述了。
。进而简化表达式,但是不影响损失算法。类似的 L2 正则化方法可以用于交叉熵损失函数或者其他的 DNN 损失函数,这里就不累述了。
对于L1正则项,不同之处仅在于迭代更新公式中的后一项。将其改为 L1 范数的导数即可。而一范数的导数即 ,即将后一项改为
,即将后一项改为 即可。
即可。
Early stopping
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
Early
stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation
data的accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为validation
accurary不再提高了呢?并不是说validation
accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。**此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……
数据集扩增
在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。因为我们在使用训练数据训练模型,通过这个模型对将来的数据进行拟合,而在这之间又一个假设便是,训练数据与将来的数据是独立同分布的。即使用当前的训练数据来对将来的数据进行估计与模拟,而更多的数据往往估计与模拟地更准确。因此,更多的数据有时候更优秀。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。
通俗得讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:
- 从数据源头采集更多数据
- 复制原有数据并加上随机噪声
- 重采样
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等
Dropout
正则是通过在代价函数后面加上正则项来防止模型过拟合的。而在神经网络中,有一种方法是通过修改神经网络本身结构来实现的,其名为Dropout。该方法是在对网络进行训练时用一种技巧(trick)**,对于如下所示的三层人工神经网络:
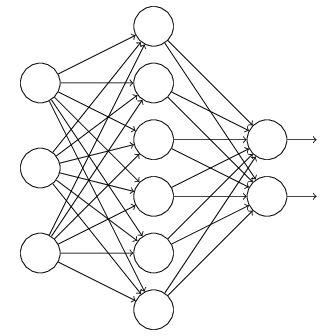
对于上图所示的网络,在训练开始时,随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变,这样便得到如下的ANN:
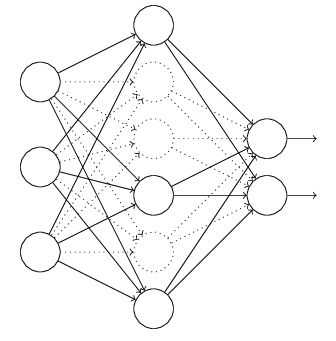
然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行瑕疵,直至训练结束。
Dropout方法是通过修改ANN中隐藏层的神经元个数来防止ANN的过拟合。
**
References

若有收获,就点个赞吧
0 人点赞
