理论
基于统计特征的熵函数是衡量图像信息丰富程度的一个重要指标,有信息论可知,一幅图像 的信息量是由该图像的信息熵
的信息量是由该图像的信息熵 来度量:
来度量: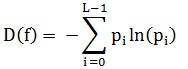
其中: 是图像中灰度值为
是图像中灰度值为 的像素出现的概率,
的像素出现的概率, 为灰度级总数(通常取值256)。根据Shannon信息论,熵最大时信息量最多。将此原理应用到对焦过程,
为灰度级总数(通常取值256)。根据Shannon信息论,熵最大时信息量最多。将此原理应用到对焦过程, 越大则图像越清晰。熵函数灵敏度不高,依据图像内容不同容易出现与真实情况相反的结果。
越大则图像越清晰。熵函数灵敏度不高,依据图像内容不同容易出现与真实情况相反的结果。
https://blog.csdn.net/Real_Myth/article/details/50827940
代码
def entropy(img):''':param img:narray 二维灰度图像:return: float 图像约清晰越大'''out = 0count = np.shape(img)[0]*np.shape(img)[1]p = np.bincount(np.array(img).flatten())for i in range(0, len(p)):if p[i]!=0:out-=p[i]*math.log(p[i]/count)/countreturn out
https://blog.csdn.net/Greepex/article/details/90183018
9. 熵函数
基于统计特征的熵函数是衡量图像信息丰富程度的一个重要指标,有信息论可知,一幅图像 f 的信息量是由该图像的信息熵 D(f) 来度量:
其中:Pi 是图像中灰度值为i的像素出现的概率,L为灰度级总数(通常取值256)。根据Shannon信息论,熵最大时信息量最多。将此原理应用到对焦过程,D(f)越大则图像越清晰。熵函数灵敏度不高,依据图像内容不同容易出现与真实情况相反的结果。
代码:
def Entropy(img):x, y = img.shapetemp = np.zeros((1,256))# 对图像的灰度值在[0,255]上做统计for i in range(x):for j in range(y):if img[i,j] == 0:k = 1else:k = img[i,j]temp[0,k] = temp[0,k] + 1temp = temp / (x * y)# 由熵的定义做计算D = 0for i in range(1,256):if temp[0,i] != 0:D = D - temp[0,i] * math.log(temp[0,i],2)return D
https://gist.github.com/JuneoXIE/d595028586eec752f4352444fc062c44

若有收获,就点个赞吧
0 人点赞
