https://zyzypeter.github.io/2017/07/26/Python-machine-learning-in-action-ch3-decision-tree/
资料来源参考:
人民邮电出版社 Peter Harrington《机器学习实战》第三章
清华大学出版社 周志华 《机器学习》 第四章 决策树
我的博客 机器学习 第六章 决策树
数据集来源 Github:Peter Harrington
本章数据集来源:Ch3
设计决策树
在实际上手构造之前,我们首先要确定我们的决策树是一种什么样的结构,并确定它的保存方式。我这里直接使用了python内置的词典来构造决策树,优点是方便快捷,缺点就是数据集如果太大,时间和空间开销也会比较大。
但为了方便起见,这里还是不从头写一个树形结构而是直接开始构造我们的决策树比较好。
因此,我们设计的决策树的架构就是词典的层层嵌套,用图形来表示,就是这样: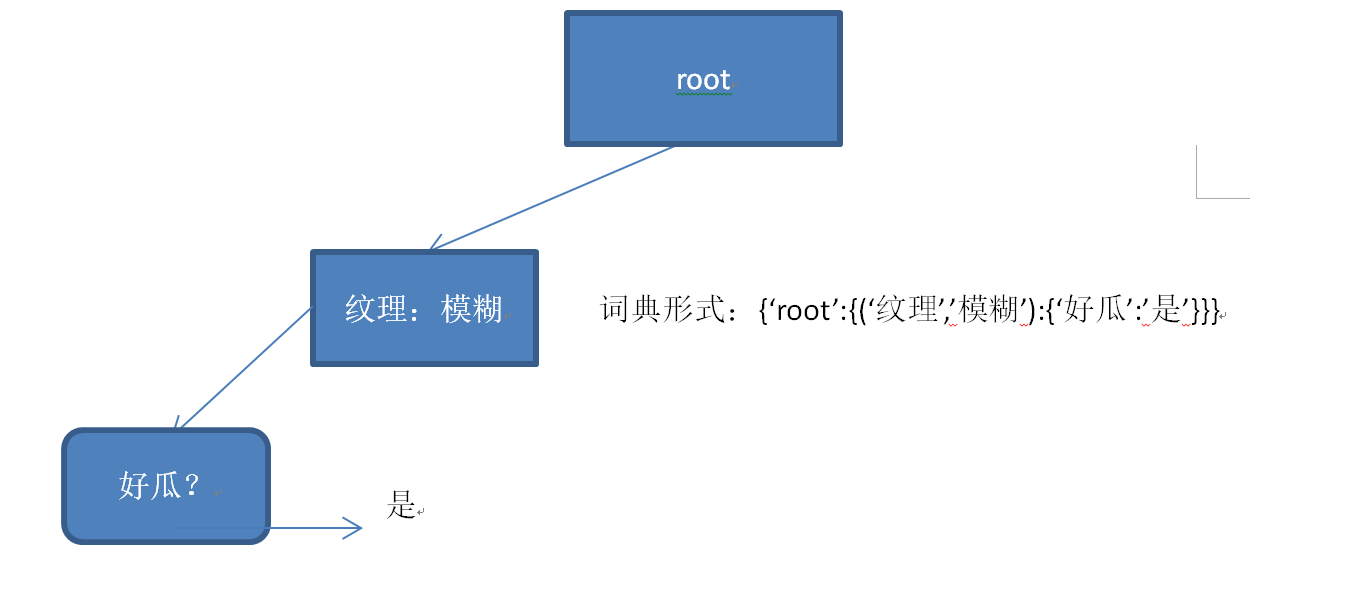
在确定决策树的架构之后,我们就可以开始着手构造了。
构造决策树
获取数据
老样子,要构建模型,我们需要先获取训练样本集合。
这里,我们用的数据集是《机器学习》(周志华著)中的西瓜数据集2.0: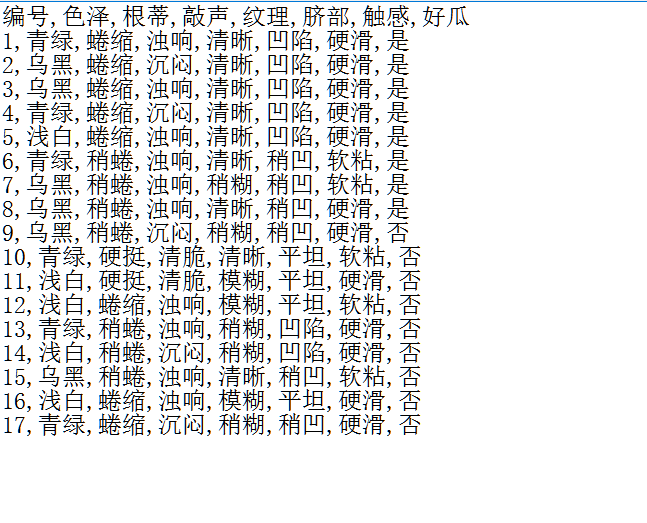
获取数据的函数:
import pandas as pd def loadDataSet(): dataSet=pd.read_csv(r’data\watermalon\2.0.txt’,encoding=‘gb2312’) return dataSet
这里我使用了pandas库,它是一个基于NumPy构建的第三方库,在数据处理方面,pandas的效果会比直接使用NumPy更佳。
代码中第一行是对本地数据集的提取操作,我们设置编码格式encoding=’gb2312’是因为这一次我们读取的数据是中文的。这行读取代码可以直接将读取而来的数据集转化为pandas中DataFrame的格式,接下来我们也将会使用比较多的pandas库的内容。
DataFrame取出来的数据集格式如下
编号 色泽 根蒂 敲声 纹理 脐部 触感 好瓜 0 1 青绿 蜷缩 浊响 清晰 凹陷 硬滑 是 1 2 乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是 2 3 乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是 3 4 青绿 蜷缩 沉闷 清晰 凹陷 硬滑 是 4 5 浅白 蜷缩 浊响 清晰 凹陷 硬滑 是 5 6 青绿 稍蜷 浊响 清晰 稍凹 软粘 是 6 7 乌黑 稍蜷 浊响 稍糊 稍凹 软粘 是 7 8 乌黑 稍蜷 浊响 清晰 稍凹 硬滑 是 8 9 乌黑 稍蜷 沉闷 稍糊 稍凹 硬滑 否 9 10 青绿 硬挺 清脆 清晰 平坦 软粘 否 10 11 浅白 硬挺 清脆 模糊 平坦 硬滑 否 11 12 浅白 蜷缩 浊响 模糊 平坦 软粘 否 12 13 青绿 稍蜷 浊响 稍糊 凹陷 硬滑 否 13 14 浅白 稍蜷 沉闷 稍糊 凹陷 硬滑 否 14 15 乌黑 稍蜷 浊响 清晰 稍凹 软粘 否 15 16 浅白 蜷缩 浊响 模糊 平坦 硬滑 否 16 17 青绿 蜷缩 沉闷 稍糊 稍凹 硬滑 否
计算给定样本集的信息熵
决策树的一大重点就是计算样本集的信息增益来作为划分数据集的依据,而在这之前,就需要我们先计算数据集的信息熵。计算信息熵的公式为: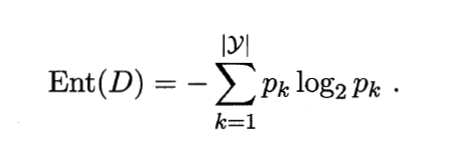
然后,这是我写的一个计算数据集信息熵的函数:
def calcEntropy(dataSet, nodeName): # 接收数据集和节点名作为参数 goodSet = dataSet[dataSet[u’好瓜’].str.contains(u’是’)] badSet = dataSet[dataSet[u’好瓜’].str.contains(u’否’)] # 将好瓜与坏瓜分组 goodCounts = {} badCounts = {} totalCounts = {} ent = {} k = 0 for column in dataSet: if k == 0: # 跳过编码列 k = k + 1 continue totalCounts[column] = dataSet[column].valuecounts() # 对整个样本各属性的属性值计数 goodCounts[column] = goodSet[column].value_counts() # 对好瓜样本的属性值计数 badCounts[column] = badSet[column].value_counts() # 对坏瓜样本的属性值计数 ent[column] = {} group = dataSet.groupby(column) # 对当前样本集按照属性分组 for name, content in group: if nodeName == name and len(ent) != 0: # 如果是当前节点所代表的列则直接跳过 continue goodNum = 0 badNum = 0 totalNum = 0 if nodeName == column: totalNum = totalCounts[column].sum() else: totalNum = totalCounts[column][name] if name in goodCounts[column]: goodNum = float(goodCounts[column][name]) else: goodNum = totalNum if name in badCounts[column]: badNum = float(badCounts[column][name]) else: badNum = totalNum entropy = 0 - (float(goodNum / totalNum * math.log(goodNum / totalNum, 2)) + float( badNum / totalNum * math.log(badNum / totalNum, 2))) ent[column][name] = entropy # 这一段应该有比我更好的写法,我的写法相当臃肿_ return ent
calcEntropy函数通过接收当前节点上包含的训练样本集和当前节点的名字来计算所有在该节点上的属性的信息熵。
goodSet = dataSet[dataSet[u’好瓜’].str.contains(u’是’)]这个语句是一个pandas提供的筛选语句,它返回一个包含所有属性“好瓜”值为“是”的DataFrame。实际上这是一个比较麻烦的写法,并且限制很大(像这里,因为明确写出了数据集的属性,所以这一块就会导致只能对该数据集生效,若是更改数据集,这个地方就要重写),我这里只是做了一个尝试,后面用groupby()函数能够更加方便地对DataFrame进行分组。而且要注意的是,对DataFrame的分组和索引切片都不改变原来的DataFrame,并且,被赋值的变量(如上面举的例子中的“goodSet”)都是对原先的DataFrame的一部分进行的深拷贝,这能很大程度上节约计算开销。
value_counts也是pandas提供的一个相当方便的计数函数,它能够对指定的DataFrame属性列下所有的属性值进行统计,像是本例中对西瓜的颜色,这个函数就可以分别统计出“青绿”西瓜的数量,“乌黑”西瓜的数量以及“浅白”西瓜的数量,并且以这三个属性(青绿,乌黑,浅白)为索引,对应的数量为值,构建并返回一个DataFrame。
然后是groupby()函数,它能够将DataFrame按照指定的属性值分组。在对DataFrame结构的拆分与聚合中起到非常重要的作用。
令我比较难受的是计算信息熵的公式部分写的相当的冗杂,但我也暂时没有想到什么好的办法对它进行缩减。
计算给定节点的信息增益
计算信息增益的公式: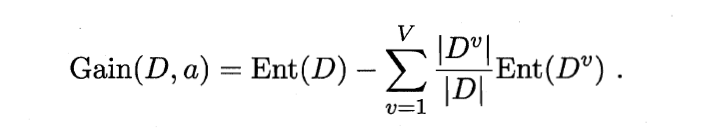
以及代码,并不复杂。它接收当前节点的样本集合,节点名称以及属性集合(就是有多少属性需要用来计算信息增益)作为参数,并返回一个包含所有属性的信息增益的词典:
def calcGain(dataSet, nodeName, attributeSet): ent = calcEntropy(dataSet, nodeName) length = len(dataSet) gain = {} for column in attributeSet: sumResult = 0 group = dataSet.groupby(column) for name, content in group: sumResult = sumResult + float(len(content)) / length * ent[column][name] if isinstance(nodeName, unicode): # 如果是根节点 gain[column] = ent[nodeName][u’是’] + ent[nodeName][u’否’] - sumResult elif isinstance(nodeName, tuple): # 如果不是根节点 gain[column] = ent[nodeName[0]][nodeName[1]] - sumResult return gain
我们这里用了isinstance来判断当前结点是不是根节点,如果是根节点,则需要用“好瓜”属性的信息熵作为计算信息增益的当前节点信息熵。
另外,我们只计算属性集里面的属性的信息增益,因为在生成子节点的过程中,子节点相比父节点会少一个属性,因此我们需要通过属性集来传递这种随着节点生成,要计算信息增益的属性渐渐变少的变化。
类似于计算信息熵的函数,这个函数,会返回一个包含当前节点所有属性(即属性集内的属性)的信息增益的字典,格式为{attribute:value}。
划分节点
得到一个节点的所有属性的信息增益后,我们就可以根据信息增益来对节点进行划分:
def chooseDataSet(dataSet, nodeName, attributeSet): gain = calcGain(dataSet, nodeName, attributeSet) bestAttribute = None bestGainValue = 0 for attribute, gainValue in gain.iteritems(): if attribute in attributeSet and gainValue > bestGainValue: # 选择使信息增益最大的属性 bestGainValue = gainValue bestAttribute = attribute return bestAttribute
函数接收样本集合,节点名字和属性集合,它内部调用的calcGain函数就是我们用来算信息增益的函数。然后经过比较,挑选出信息增益最大的属性的名字,放入bestAttribute并返回。
树体构建
创建树
这是创建一棵树的代码:
def createTree(): dataSet = loadDataSet() # 读取数据 root = {} # 初始化根节点 attributeSet = set() nodeNameList = [] dataSet = loadDataSet() data = dataSet.ix[:, 1:-2] for column in data: attributeSet.add(column) for column in dataSet: nodeNameList.append(column) nodeName = nodeNameList[-1] root[‘root’] = treeGenerate(dataSet, attributeSet, nodeName) return root
代码中使用的dataSet.ix[:, 1:-2]也是DataFrame提供的一个用于切片DataFrame的方式,注意[]中的第二个参数是左右包含的,也就是说这里是选取样本集合DataFrame第一列到倒数第二列的全部内容,以方便我们将样本集中除了“编号”和“好瓜”属性之外所有的属性名称放入属性集合中。
函数treeGenerate是构建树节点的函数,这是我们接下来要写的。
创建节点
一般来说,我们都会用递归来实现创建树形结构的节点,具体内容如下:
def treeGenerate(dataSet, attributeSet, nodeName): “”” :type attributeSet: tuple ,dataSet: DataFrame “”” node = {} nameSet = set() if dataSet is None: return # 样本集为空,直接返还 i = 0 name = None resultCount = {} group = dataSet.groupby(dataSet.ix[:, -1]) for name, content in group: i = i + 1 resultCount[name] = len(content) if i == 1: node[dataSet.ix[:, -1].name] = name return node # 如果dataSet中样本全部属于同一类别,那么返回叶节点 if len(attributeSet) == 1 or len(attributeSet) == 0: node[dataSet.ix[:, -1].name] = max(resultCount) return node # 如果属性集合中只剩下编码列或为空,返回叶节点 bestAttribute = chooseDataSet(dataSet, nodeName, attributeSet) if bestAttribute is None: node[dataSet.ix[:, -1].name] = max(resultCount) return node # 获取最佳划分属性 group = dataSet.groupby(dataSet[bestAttribute]) # 按照属性分组 attributeSet = copy.copy(attributeSet) attributeSet.remove(bestAttribute) # 从属性集合中删除划分过的属性 for name, content in group: node[(bestAttribute, name)] = treeGenerate(content, attributeSet, (bestAttribute, name)) # 根据划分创建分支节点 return node
这里,我们参照的编写方式是《机器学习》(周志华著)中的树的基本算法:
至此,我们就算是完整地构造了一棵决策树,可以用下面的代码试着查看一下我们的决策树:
tree = createTree() print tree
构造注解树
一棵树用字典的表示形式还是比较难以理解的,因此为了能够更直观地表现我们的决策树,我们可以用matplotlib构图的形式来绘制一棵决策树。
用 matplotlib注解 绘制节点
matplotlib提供了一个用于编写注解的工具“annotations”,它可以在数据图形上添加文本注释。
藉由它,我们就可以编写一个带有箭头指向的节点,如图: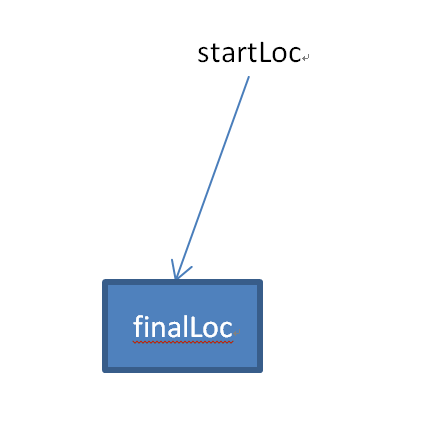
创建一个节点的函数如下:
def plotNode(nodeName, finalLoc, startLoc, nodeType): createPlot.ax1.annotate(nodeName, xy=startLoc, xycoords=‘axes fraction’, xytext=finalLoc, textcoords=‘axes fraction’, bbox=nodeType, arrowprops=arrowargs) # startLoc 箭头起点 ,finalLoc 箭头指向的终点_
createPlot.ax1是由createPlot函数提供的一个类型为matplotlib画板的全局变量,这个函数我们将在后面编写。
先看到annotate,这就是用于创建注解的函数,它与绘制散点图的scatter或者绘制直方图的barh等绘图函数用的地方相同。
第一个参数接受节点的名字,这个名字会被放在上图中的”finalLoc”的位置,即箭头指向的位置。
参数xy接收一个tuple (x,y)作为箭头起点的坐标,xytext则接收一个tuple作为箭头指向终点的坐标。
xycoords接受表示起点坐标的坐标系,axes fraction表示(0,0)作为左下角,(1,1)作为右上角。textcoords同理。
bbox接受箭头终点节点在图上的形状的类型,我们这里设置了两个类型:
decisionNode = dict(boxstyle=“square”, fc=“0.8”) leafNode = dict(boxstyle=“round4”, fc=“0.8”)
第一个是子节点的形状,第二个是叶节点的形状。
arrowprops则接受箭头类型:
arrow_args = dict(arrowstyle=“<-“)
获取叶节点的数目与树的层数
在绘制之前,我们还需要构造两个用于计算绘制点坐标的函数。一个是计算叶节点数目的函数,用来计算横坐标,一个是计算树的层数的函数,用来计算纵坐标。
计算叶节点的数目
计算当前节点下叶节点数目的函数如下:
def getNumLeafs(tree): numLeafs = 0 for key in tree.keys(): secondDict = tree[key] if isinstance(secondDict, dict): numLeafs += getNumLeafs(secondDict) else: numLeafs += 1 return numLeafs
计算树的层数
然后是当前节点下树的层数的函数:
def getTreeDepth(tree): maxDepth = 0 for key in tree.keys(): secondDict = tree[key] if isinstance(secondDict, dict): thisDepth = 1 + getTreeDepth(secondDict) else: thisDepth = 1 if thisDepth > maxDepth: maxDepth = thisDepth return maxDepth
如果想测试下自己写的函数的效果,我们可以手动编写一个小型的测试用的树,其实就是一个多层嵌套的词典,这里我就不再赘述。
绘制树
绘制树的主要函数有两个,一个以递归形式调用绘制节点函数来绘制整个树,一个作为主函数整合绘制函数。
绘制函数
def plotTree(tree, startLoc, nodeName): numLeafs = float(getNumLeafs(tree)) # 得到当前节点要占的宽度 depth = float(getTreeDepth(tree)) # 得到当前节点要占的高度 finalLoc = (plotTree.xOff + (1.0 + numLeafs) / 2.0 / plotTree.totalW, plotTree.yOff) # 计算当前节点的位置 plotNode(nodeName, finalLoc, startLoc, decisionNode) # 绘制当前节点 plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD # 减少y偏移 for node in tree.keys(): # 检索当前节点的分支 if isinstance(tree[node], dict): # 如果是子节点 text = ‘’ if isinstance(node, tuple): # 判断是否是根节点 text=node[0].encode(‘utf-8’)+‘:’+node[1].encode(‘utf-8’) #将原本是unicode类型的节点键编码为‘utf-8’格式的str类以方便显示图表 else: text = ‘root’ plotTree(tree[node], finalLoc, text) else: # 如果是叶节点 plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW if tree[node] == u’是’: tree[node] = u’好瓜’ else: tree[node] = u’坏瓜’ plotNode(tree[node], (plotTree.xOff, plotTree.yOff), finalLoc, leafNode) plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
中间编码unicode的部分还需要我们导入并重写sys包的内置函数:
import sys reload(sys) sys.setdefaultencoding(‘utf-8’)
(详细内容参考Python中的str与unicode处理方法)
这里采用的计算绘制坐标的计算方式来自《机器学习实战》(Peter Harrington著),我们会在下一个函数后面讲解一下这个计算方式。
主函数
def createPlot(tree): fig = plt.figure(1, facecolor=‘white’) fig.clf() createPlot.ax1 = plt.subplot(111, frameon=False) plotTree.totalW = float(getNumLeafs(tree)) plotTree.totalD = float(getTreeDepth(tree)) plotTree.xOff = -0.5 / plotTree.totalW plotTree.yOff = 1 plotTree(tree, (0.5, 1.0), ‘’) plt.show()
主函数提供了上面几个函数用到的全局变量,包括决策树的宽(plotTree.totalW),高(plotTree.totalD),画板(createPlot.ax1)等等。清屏函数clf用来将画板上可能有的之前绘制的内容清除掉,如果是脚本形式编写这个函数用处不大,但如果是交互式编写那么就很有必要了。
绘制函数绘制树形图的原理大致如下,首先将画布水平中心垂直顶部作为起始位置(0.5,1.0),用1/plotTree.totalD作为决策树一层的高度,也就是说,从最高点开始,绘制完一层节点后用它来控制绘制的下一层节点的位置(语句plotTree.yOff-1.0/plotTree.totalD使得绘制点下降一层)。函数利用递归原理,先绘制一个节点便直接垂直下降一层,直到绘制完该节点的所有子节点后再垂直上升,切换到同一层的下一个节点。叶节点的水平位置也是用同样的方式控制(1/plotTree.totalD便是每个叶节点的宽度)。
plotTree.xOff = -0.5 / plotTree.totalW设置了绘制点的初始水平位置,之所以这样设置,是为了保证根节点的绘制能够在决策树的中上方。因为我们用于计算每个节点的横坐标的方式是通过绘制点的水平推移:
x(下一个节点的位置)=x(当前节点的位置)+w(当前节点下的叶节点数)2W(总叶节点数)x(下一个节点的位置)=x(当前节点的位置)+w(当前节点下的叶节点数)2W(总叶节点数)
因此,为了保证第一个绘制的根节点能在所有叶节点的中央,需要有:
x(根节点位置)=−0.5W+1+w2W=w2Wx(根节点位置)=−0.5W+1+w2W=w2W
最后,我们就可以看到我们的决策树的图形表示了: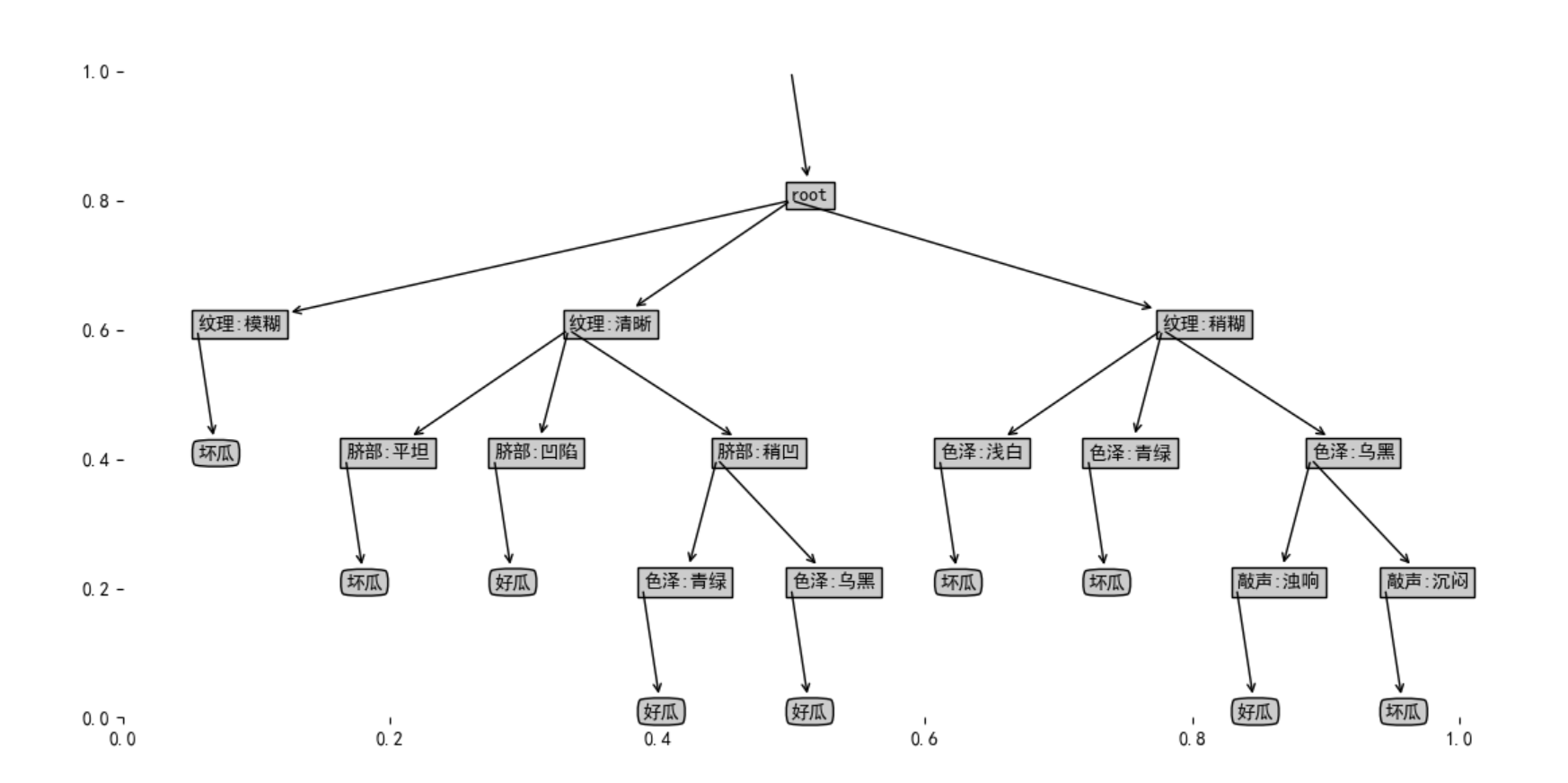
源代码可以在我的github里面找到:Machine-Learning-in-action

若有收获,就点个赞吧
0 人点赞
