假设我们现在有这么一个列表
[1, 2, 3, 4, 5]
我们最终想得到的是
[5, 4, 3, 2, 1]
怎么办?
第一种方式 list.reverse()
Python 的 list.reverse() 方法,会直接在原来的列表里面将元素进行逆序排列,不需要创建新的副本用于存储结果。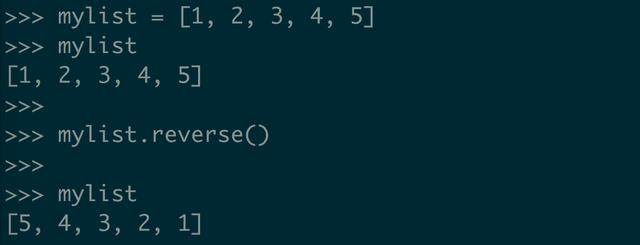
就像你看到的这样,调用 list.reverse() 的返回值是 None ,它逆序的结果直接体现在原来的列表里面。
这种方式,有好处也有坏处。好处是节省内存使用,因为我们不需要重新申请空间来保存最后的结果。坏处是,我们修改了原来的数据,如果我们后面要使用原数据的话不方便。(虽说再倒序一次就行,但毕竟使用了多余的操作)。
从可读性来说,我喜欢这种方式。这个方法从字面意思上就告诉了我们所做的操作,即使是 Python 新手不知道这个方法,也能大致清楚这个完成了什么功能。
第二种方式 使用切片 [::-1]
Python 的列表有一个特性叫做切片,你可以将它看作是方括号( [ ] )使用的扩展。
简单的说下切片的使用
mylist[start:end:step]
上面的操作表示取 mylist 的第 start 个(列表索引从 0 开始)到第 end 个元素(不包括第 end 个),其中每隔 step 个(默认 1 )取一个。
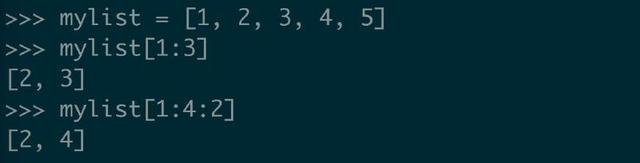
当然,start 、end 和 step 都是可选的。
mylist[:] 会返回 mylist 的副本
加上 step 的话也正常工作
而当 start 、end 和 step 为负时,表示从反方向遍历,看下面的例子就理解了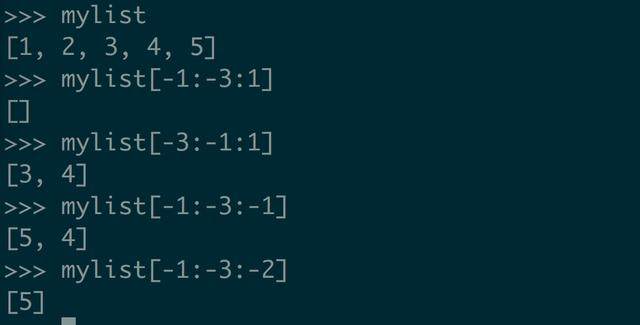
所以 mylist[::-1] 就能达到逆序的目的
相比于第一种方式,这种方式会另外创建副本来保存列表的所有元素,所以需要更多的内存空间。并且,由于使用了切片的特性,导致在可读性上也不如之前的方式。但是这种方式没有改变原来的列表,在某些情况下算是一种优势。
第三种方式 使用 reversed() 方法
reversed 方法会将列表逆序的结果存储到迭代器里面,这种方式不会改变原来的列表,也不会创建原来列表的完整副本,只会多出迭代器对象所占的空间,相对来说也比较高效。(不明白迭代器原理的同学可以看下我之前的一篇文章 一步一步带你理解 Python 迭代器)
如果要访问所有的元素,循环就好,就像这样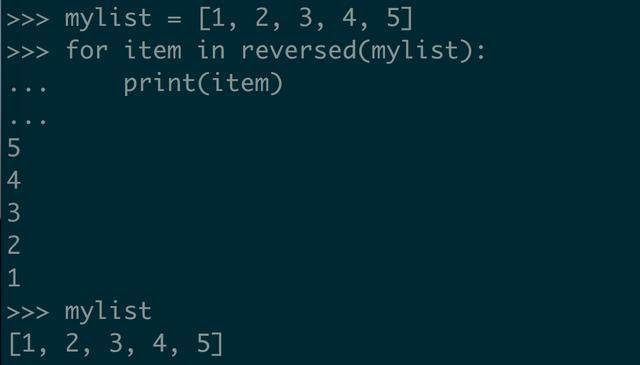
看了例子后,我们发现,这个的可读性也好,毕竟 reversed 字面意思已经体现出来了。
但是,如果我们想要一个列表呢,也简单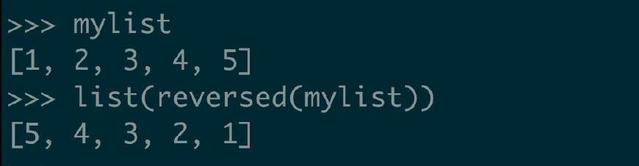
虽然这能达到目的,但是如果我们最终想要得到列表的话,这里使用 reversed 方法就没有意义了,因为这里我们又创建了 mylist 的副本。针对这种情况,用第一种或第二种方式更合适。
那么选择哪一种呢
1、显然,第一种是首选。毕竟高效、易读。如果不要保留原列表的数据,使用这种方式显然更有优势,否则选择后两种。
2、如果最后需要得到列表类型的结果,那么选第二种方式比较合理。否则,第三种方式更高效。
http://baijiahao.baidu.com/s?id=1596184962608889085&wfr=spider&for=pc

若有收获,就点个赞吧
0 人点赞
