图像质量和美学评估是计算机视觉领域中热点的研究问题,并且极具应用前景,可与众多实际应用深度结合。评价一张图片,主要从两个方向,一个是图像的质量,如像素、清晰度、有无噪声等,一个是图像的感觉,也就是美学,如构图、颜色、内容主体等。通过这两个方面就可以评价一张图片的好坏,通过计算机视觉算法,可以为图片自动评分,得分高的图片被认为较好,可以用于推荐和搜索等应用场景。本文主要聊聊一些关于图像质量和美学评估的数据集,是一篇综述类文章。
数据集在算法研发中至关重要,就像赛车比赛的赛道,好的车手,不仅要有优秀的车技,也需要对于赛道拥有绝对的理解,不同路况如何开好车。
其中,图像质量评价和图像美观评价的相关数据集,如下:
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| TID2013 | 图像质量评价 | 25张参考图像,24个失真类型 | 链接 |
| LIVE | 图像质量评价 | 29张参考图像,5个失真类型 | 链接 |
| MLIVE | 图像质量评价 | 15张参考图像,15个失真类型 | 链接 |
| WATERLOO | 图像质量评价 | 4744张参考图像,20个失真类型 | 链接 |
| photo.net | 图像美观评价 | 20,278张图像,打分[0,10] | 链接 |
| DPChallenge.com | 图像美观评价 | 16,509张图像,打分[0,10] | 链接 |
| AVA | 图像美观评价 | 255,500张图像,打分[0,10] | 链接 |
其中TID2013的网站可能无法访问。
TID2013
Image database TID2013: Peculiarities, results and perspectives
TID,即TAMPERE IMAGE DATABASE,Tampere来自于Tampere University of Technology。TID2013是用于全参考图像质量的视觉评价, 主要是评价图像质量评价模型与平均人类感知的匹配。例如,在TID2013中, PSNR(峰值信噪比)和平均人类感知(MOS,平均意见得分)的Spearman相关系数是0.69。
TIP2013是TIP2008的升级版本,包括25幅参考图像,3000幅失真图像,即25参考图像X24种失真×5失真水平。失真类型有24种,增加了包括:改变色彩饱和度、多重高斯噪声、舒适噪声、有损压缩、彩色图像量化、色差以及稀疏采样。
数据集包括:
- reference_images:25张参考图像
- distorted_images:3000张失真图像,即25张参考图像x24种失真×5失真水平
全部图像都以Bitmap格式,保存在数据库中,无需任何压缩。
- BMP:Bitmap
- JPEG:Joint Photographic Experts Group
文件命名iXX_YY_Z.bmp:第1位是图像编号、第2位是失真类型、第3位是失真等级。例如,”i03_08_4.bmp“意味着第3号图像、第8种失真类型、第4级失真。
失真类型(Types of distortion):
| 编号 | 失真类型 | 英文 |
|---|---|---|
| 1 | 高斯噪声 | Additive Gaussian noise |
| 2 | 在颜色分量中添加噪声,在亮度分量中添加噪声,且颜色强于亮度 | Additive noise in color components is more intensive than additive noise in the luminance component |
| 3 | 空间相关噪声 | Spatially correlated noise |
| 4 | 掩码噪声 | Masked noise |
| 5 | 高频噪声 | High frequency noise |
| 6 | 脉冲噪声 | Impulse noise |
| 7 | 量化噪声 | Quantization noise |
| 8 | 高斯模糊 | Gaussian blur |
| 9 | 图像去噪 | Image denoising |
| 10 | JPEG压缩 | JPEG compression |
| 11 | JPEG2000压缩 | JPEG2000 compression |
| 12 | JPEG2000压缩 | JPEG2000 compression |
| 13 | JPEG传输错误 | JPEG transmission errors |
| 14 | 非偏心模式噪声 | Non eccentricity pattern noise |
| 15 | 不同强度的局部块状扭曲 | Local block-wise distortions of different intensity |
| 16 | 平均移位(强度移位) | Mean shift (intensity shift) |
| 17 | 对比度变化 | Contrast change |
| 18 | 颜色饱和度的变化 | Change of color saturation |
| 19 | 乘法高斯噪声 | Multiplicative Gaussian noise |
| 20 | 舒适的噪声 | Comfort noise |
| 21 | 噪声图像的有损压缩 | Lossy compression of noisy images |
| 22 | 抖动的图像颜色量化 | Image color quantization with dither |
| 23 | 色差 | Chromatic aberrations |
| 24 | 稀疏采样和重建 | Sparse sampling and reconstruction |
具体效果:
MOS(Mean Opinion Score),平均主观意见分,三个评分文件:
- mos.txt:每个失真图像的平均意见得分
- mos_with_names.txt:相应失真图像的相同信息和文件名。
- mos_std.txt:每个失真图像的MOS标准偏差
该数据库的DMOS值由971观察者给出524340个数据统计得到,较高的MOS值,对应较高的图像视觉质量,分数范围0~9分。还有一些包含TID2008图像计算的一些质量指标的值。所有图像都以Bitmap格式保存在数据库中,没有任何压缩。
MOS是来自5个国家的观察员,进行的971次实验的结果,即:芬兰,法国,意大利,乌克兰和美国。
- 芬兰(Finland)116次
- 法国(France)72次
- 意大利(Italy)80次
- 乌克兰(Ukraine)602次
- 美国(USA)101次
971个观察者:
- 扭曲图像视觉质量的比较:visual quality of distorted images,524340次
- 图像对的相对视觉质量评估:evaluations of relative visual quality,1048680次
LIVE 和 MLIVE
LIVE,即Laboratory for Image & Video Engineering,图像视频工程库,由德克萨斯大学奥斯汀分校(The University of Texas at Austin)提供。LIVE提供多个图像和视频质量评估的数据库,参考。
图像和视频处理领域,通常处理用于需要用户消费的信息,例如网络上的图像或视频。在呈现给用户之前,图像或视频可能经历许多处理阶段,并且每个处理阶段可能引入可能降低最终显示质量的失真。例如,图像和视频由相机设备获取,这可能由于光学,传感器噪声,颜色校准,曝光控制,相机运动等而引入失真。在获取之后,图像或视频可以进一步通过压缩算法来处理,该算法减少了存储或传输的带宽要求。这种压缩算法通常被设计为通过使信号发生某些失真来实现更大的带宽节省。同样的,在通过信道传输图像时发生的比特错误或者在存储图像时(很少)发生比特错误也会引入失真。最后,用于渲染最终输出的显示设备可能会引入一些自身的失真,例如低再现分辨率,不良校准等。每个阶段可能添加的失真量主要取决于经济或设备的物理限制。
人们显然对能够测量图像或视频的质量,以及衡量在不同阶段,添加到失真感兴趣。确定图像或视频质量的一种显而易见的方法是征求人类观察者的意见。毕竟,这些信号是供人类消费的。然而,这种方法不可行,不仅是因为“外面”的图像和视频的剪切数较大量,而且,因为我们希望能够将质量测量技术嵌入到处理图像和视频的算法中,因此对于给定的一组资源,算法输出能力,可以最大化。
客观的图像质量评估,所研究的目标是开发能够自动预测感知图像质量的定量测量。一般而言,客观图像质量度量可以在广泛的应用中发挥重要作用,例如图像采集、压缩、通信、显示、打印、恢复、增强、分析和水印。具体:
- 可用于动态监控和调整图像质量。
- 可用于优化图像处理系统的算法和参数设置。
- 可以用于基准图像处理系统和算法。
简而言之,客观质量测量(与人类观察者的主观质量评估相反)旨在通过算法确定图像或视频的质量。客观质量评估(QA)研究的目标是设计算法,其质量预测与人类观察者的主观评分一致。
图像和视频QA算法可分为三大类:
- 全参考(Full-Reference,FR)QA方法:其中QA算法可以访问图像或视频的“完美版本”,以便与“扭曲版本”进行比较。“完美版本”通常来自高质量的采集设备,在被压缩伪像和传输错误扭曲之前。然而,参考图像或视频通常比失真版本需要更多的资源,因此,FRQA通常仅用作于设计用于实验室内,测试的图像和视频处理算法的工具,并且不能作为应用程序部署。
- 无参考(No-Reference,NR)QA方法:其中QA算法只能访问失真信号,并且必须在不知道“完美版本”的情况下估计信号质量。由于NR方法不需要任何参考信息,因此,可用于需要质量测量的任何应用中。然而,为这种灵活性支付的价格是根据算法进行准确质量预测的能力,或NRQA算法的有限范围(例如仅用于JPEG图像的NRQA等)。
- 简化参考(Reduced-Reference,RR)QA方法:其中提供了关于“完美版本”的部分信息。存在一个侧信道(称为RR信道),通过该信道可以使关于参考的一些信息可用于QA算法。RRQA算法使用该部分参考信息来判断失真信号的质量。
LIVE含有两个图像质量评估的数据集:
- LIVE Image Quality Assessment Database
- LIVE Multiply Distorted Image Quality Database
LIVE Image Quality Assessment Database
数据集:链接
图像和视频评估的简介,参考Image & Video Quality Assessment at LIVE。
图像和视频质量评估,研究强烈依赖于主观实验来提供校准数据以及测试机制。毕竟,所有的QA研究的目标是使质量预测,是在协议与人类观察者的主观意见。为了校准QA算法并测试算法的性能,需要一组质量已由人类受试者排序的图像和视频的数据集。可以在该数据集的一部分上训练QA算法,并在其余部分上进行测试。在LIVE中,进行了一项广泛的实验,以获得人类受试者对许多扭曲不同扭曲类型的图像的分数。获得这些图像是为了支持关于通用形状匹配和识别的研究项目。
图像质量评估数据集,链接,29张图片,5种失真类型:
| 失真类型 | 英文 | 文件夹 | 图片数 | info |
|---|---|---|---|---|
| JPEG2000 | JPEG2000 | jp2k | 227 | 比特率 |
| JPEG | JPEG | jpeg | 233 | 比特率 |
| 白化噪声 | White Noise | wn | 174 | 标准差 sigma |
| 高斯模糊 | Gaussian Blur | gblur | 174 | 标准差 sigma |
| 快速衰落瑞利(误码) | Fast Fading Rayleigh | fastfading | 174 | 失真强度 |
| 原图 | - | refimgs | 29 | - |
DMOS:Difference Mean Opinion Score (DMOS)
图像质量评价可以分为主观评价方法和客观评价方法,主观评价由观察者对图像质量进行主观评分, 一般采用:
- 平均主观得分(Mean Opinion Score, MOS)
- 平均主观得分差异(Direrential Mean Opinion Score, DMOS),即人眼对无失真图像和有失真图像评价得分的差异
数据集中包含两个文件:
- dmos.mat,评分值
- refnames_all.mat,图片引用
其中dmos.mat,得分越高,质量越差:
[Info] dmosdata 0: [0.] [Info] dmosdata 1: [28.00384536] [Info] dmosdata 2: [34.01073628] [Info] dmosdata 3: [65.13140971] [Info] dmosdata 4: [68.9113403] [Info] dmosdata 5: [65.15010253] [Info] dmos_data 6: [54.39726604] [Info] dmos_data 7: [44.3971449] [Info] dmos_data 8: [0.] [Info] dmos_data 9: [47.43001376]
其中refnames_all.mat:
[Info] ref_data 0: [array([‘buildings.bmp’], dtype=’<U13’)] [Info] ref_data 1: [array([‘studentsculpture.bmp’], dtype=’<U20’)] [Info] ref_data 2: [array([‘rapids.bmp’], dtype=’<U10’)] [Info] ref_data 3: [array([‘dancers.bmp’], dtype=’<U11’)] [Info] ref_data 4: [array([‘churchandcapitol.bmp’], dtype=’<U20’)] [Info] ref_data 5: [array([‘dancers.bmp’], dtype=’<U11’)] [Info] ref_data 6: [array([‘churchandcapitol.bmp’], dtype=’<U20’)] [Info] ref_data 7: [array([‘stream.bmp’], dtype=’<U10’)] [Info] ref_data 8: [array([‘cemetry.bmp’], dtype=’<U11’)] [Info] ref_data 9: [array([‘woman.bmp’], dtype=’<U9’)]
DMOS数据是MATLAB格式,数据(1, 982)
dmos=[dmos_jpeg2000(1:227) dmos_jpeg(1:233) white_noise(1:174) gaussian_blur(1:174) fast_fading(1:174)] 227 + 233 + 174 + 174 + 174 = 982
SciPy读取MATLAB数据,参考:
import os import scipy.io from root_dir import DATA_DIR def analyze_data(): dmos_path = os.path.join(DATA_DIR, ‘live’, ‘dmos.mat’) print(‘[Info] dmos path: {}’.format(dmos_path)) dmos_mat = scipy.io.loadmat(dmos_path) print(‘[Info] dmos keys: {}’.format(dmos_mat.keys())) dmos_data = dmos_mat[‘dmos’] print(‘[Info] dmos_data: {}’.format(dmos_data.shape))
输出:
[Info] dmos path: /Users/wangchenlong/workspace/IQA/data/live/dmos.mat [Info] dmos keys: dict_keys([‘__header‘, ‘__version‘, ‘__globals‘, ‘orgs’, ‘dmos’]) [Info] dmos_data: (1, 982)
LIVE Multiply Distorted Image Quality Database
数据集:链接
过去已经进行了主观研究,以获得对失真图像的视觉质量的人类判断,用于实现客观图像质量评估(IQA)的基准算法。现有的主观研究,主要是对图像的人类评级记录,这些图像仅被许多可能的失真中的一种。然而,用户可用的图像,通常在几个阶段(获取、压缩、传输和接收)之后得到。在这个管道中,可能遭受多次失真。为了扩大人类对视觉失真的反应记录的范围,我们最近对两种类型的多次失真图像进行了研究,以获得对这些图像的视觉质量的人类判断。
主观研究分两部分进行,以获得在两种多重失真情况下损坏的图像的人体判断:
- 图像存储,其中图像首先被模糊,然后由JPEG编码器压缩。
- 相机图像获取过程,其中图像由于窄景深或其他散焦而首先被模糊,然后被白高斯噪声破坏以模拟传感器噪声。
数据集包含两部分,在标有“Part1”和“Part2”的两个单独文件夹中:
- Part1是模糊的JPEG图像
- Part2是模糊的噪声图像
在每个部分中,含有一个文件夹,文件夹中是图像的模糊处理,第一个是JPEG模糊图像,第二个是噪声模糊图像。
其中,Imagelists.mat含有以下变量:
- refimgs:有序参考图像的名称
- allimgs:所有240张图像所属主题的名称
- ref4all:在该部分研究中,240个图像中每个图像的参考图像的名称
- allimgdistlevels:失真等级(0-3)是240x2的矩阵,第1列是240个图像的模糊级别。第2列是240个图像的JPEG(第1部分)或噪声(第2部分)的级别,列表的顺序与allimgs的顺序相同
- distimgs:提供给测试者的所有225个扭曲图像的名称
- ref4dist, distimgdistlevels:包含与refs4all和allimgdistlevels相同的信息,但仅适用于distimgs中列出的225个扭曲图像
其中,Scores.mat含有以下变量:
- DMOSscores:225x1矩阵,包含distimgs中列出的225个图像的计算DMOS值
- Zscores:225x1矩阵,包含distimgs中列出的225个图像的计算Z得分值
- ref_scores:单个测试者分配给参考图像的原始分数
- dist_rawscores:由单个主体分配给失真图像的原始分数
- dist_diffscores:为失真图像计算的差异分数
使用Python脚本读取的Imagelists.mat数据:
refimgs: (15, 1) distimgs: (225, 1) ref4dist: (225, 1) allimgs: (240, 1) ref4all: (240, 1) allimgdistlevels: (240, 2) distimgdistlevels: (225, 2)
Waterloo Exploration Database
链接,Waterloo,即University of Waterloo,滑铁卢大学。
真实世界数字图像的巨大内容多样性对图像质量评估(IQA)模型提出了巨大挑战,该模型传统上是在少数常用的IQA数据库上设计和验证的,内容变化非常有限。为了测试泛化能力并促进IQA技术在实际应用中的广泛使用,我们建立了一个名为Waterloo Exploration数据库的大型数据库,该数据库目前包含4,744个原始自然图像和94,880个由它们创建的失真图像。不是通过主观测试收集每个图像的平均意见得分,这是非常困难的,如果不是不可能的话,我们提出三个替代测试标准来评估IQA模型的性能,即原始/失真图像可辨性测试(D-测试),列表排序一致性测试(L-测试)和成对偏好一致性测试(P-测试)。我们使用提出的标准比较20个著名的IQA模型,这不仅在现有模型的更具挑战性的测试环境中提供更强的测试,而且还展示了使用所提出的数据库的额外好处。例如,在P检验中,即使对于性能最佳的无参考IQA模型,在超过10亿个测试对中自动“发现”超过600万个针对该模型的故障情况。此外,我们将讨论如何利用未来的创新方法利用新数据库,揭示现有IQA模型的弱点,提供有关如何改进模型的见解,以及阐明下一代IQA模型如何开发。
下载链接,约1.9GB,Paper链接
下载的数据集中,只含有原图,位于pristine_images文件夹中,调用
- support_functions/distortion_generator.m
生成失真图像,20种失真方式,即高斯模糊、白化噪声、JPEG压缩、JPEG2000压缩四类,每类5个级别,共20种,参考:
gblurlevel = [7,15,39,91,199]; wn_level = [-10,-7.5,-5.5,-3.5,0]; jpeg_level = [43,12,7,4,0]; jp2k_level = [0.46,0.16,0.07,0.04,0.02]; % bit per pixel_
评估数据集的算法:
具体参考,论文:
Waterloo Exploration Database: New Challenges for Image Quality Assessment Models
| 算法 | 论文 |
|---|---|
| PSNR | Peak signal to noise ratio |
| SSIM | Wang et al. Image quality assessment: from error visibility to structural similarity. TIP. 2004. |
| MS-SSIM | Wang et al. Multi-scale structural similarity for image quality assessment. Asilomar. 2003. |
| VIF | Sheikh et al. Image information and visual quality. TIP. 2006. |
| FSIM | Zhang et al. A feature similarity index for image quality assessment. TIP. 2011. |
| GMSD | Xue et al. Gradient magnitude similarity deviation: a highly efficient perceptual image quality index. TIP. 2014. |
| WANG05 | Wang et al. Reduced-reference image quality assessment using a wavelet-domain natural image statistic model. HVEI. 2005. |
| RRED | Soundararajan et al. RRED indices: Reduced reference entropic differencing for image quality assessment. TIP. 2012. |
| BIQI | Moorthy et al. A two-step framework for constructing blind image quality indices. SPL. 2010. |
| BLINDS-II | Saad et al. Blind image quality assessment: a natural scene statistics approach in the DCT domain. TIP. 2012. |
| BRISQUE | Mittal et al. No-reference image quality assessment in the spatial domain. TIP. 2012. |
| CORNIA | Ye et al. Unsupervised feature learning framework for no-reference image quality assessment. CVPR. 2012. |
| DIIVINE | Moorthy et al. Blind image quality assessment: from scene statistics to perceptual quality. TIP. 2011. |
| IL-NIQE | Zhang et al. A feature-enriched completely blind image quality evaluator. TIP. 2015. |
| LPSI | Wu et al. A highly efficient method for blind image quality assessment. ICIP. 2015. |
| M3 | Xue et al. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. TIP. 2014. |
| NFERM | Gu et al. Using free energy principle for blind image quality assessment. TMM. 2015. |
| NIQE | Mittal et al. Making a completely blind image quality analyzer. SPL. 2013. |
| QAC | Xue et al. Learning without human scores for blind image quality assessment. CVPR. 2013. |
| TCLT | Wu et al. Blind image quality assessment based on multichannel features fusion and label transfer. TCSVT. 2016. |
评估算法: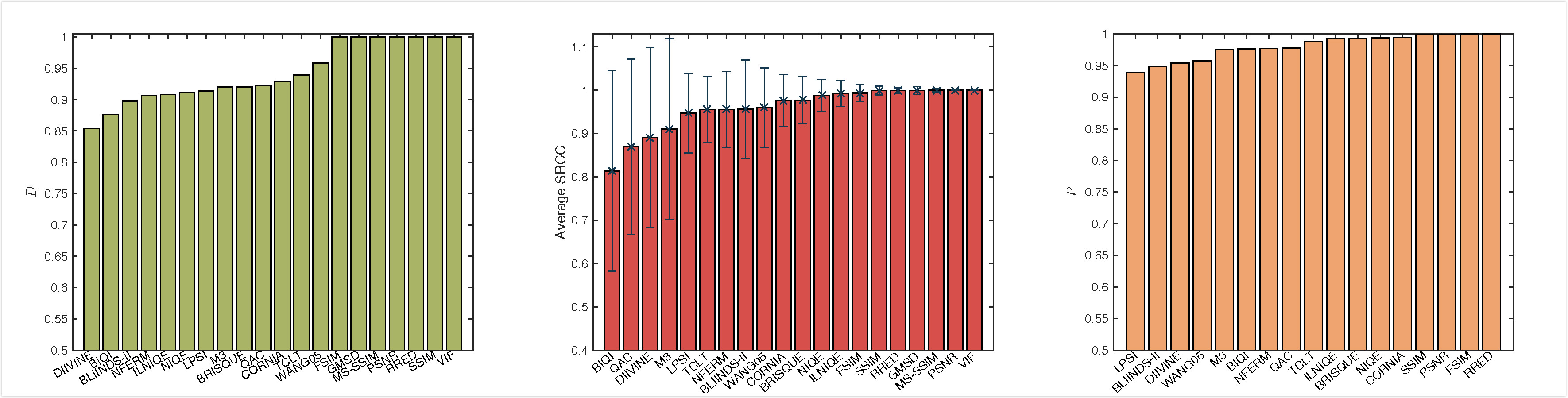
DAIE
DAIE,即Datasets for Aesthetics Inference Experiments,美学推理实验数据集。DAIE提供了一组可能用于美学推理实验的数据集。由于版权问题,图像本身不包括在数据集中,但描述了用于构造图像的URL的方法。通过爬行获取图像应该是直截了当的。请遵守适用的任何版权限制。
参考论文:
R. Datta, J. Li, and J. Z. Wang, Algorithmic Inferencing of Aesthetics and Emotion in Natural Images: An Exposition, Proc. IEEE ICIP, Special Session on Image Aesthetics, Mood and Emotion, San Diego, CA, 2008. PDF
其中包含两个数据集,图片来源不同:
- Photo.net
-
Photo.net
数据集的Paper:Algorithmic Inferencing of Aesthetics and Emotion in Natural Images: An Exposition
该数据集包含20,278个图像,是一个较大的数据集,并且只有那些已经收到至少10个评级的数据集中的照片。这确保了平均美学分数的更高稳定性。
请单击下面的链接并保存文件: - 描述文件
下载网站编号1008958图片的链接,查看网页结构,下载链接如下:
LOGO图片:https://www.photo.net/1008958-photo.jpg 原始图片:https://d6d2h4gfvy8t8.cloudfront.net/1008958-orig.jpg
网页链接,1008958.html
图片如下:
数据格式,如下:
1[索引] 1008958[照片ID] 18[评级数] 5.17[平均值] 0.583333333333339[标准差] 0 0 0 4 7 7 0 2 1009826 11 5.36 1.32231404958678 0 0 1 1 4 3 2 3 1010164 21 5.76 0.421487603305785 0 0 0 1 4 15 2 4 1010795 25 5.44 0.566400000000002 0 0 0 4 6 15 0 5 1010893 27 6.52 0.320153061224488 0 0 0 0 1 11 16
其中:
- 第1栏:索引
- 第2栏:照片ID
- 第3栏:收到的美学评级数量
- 第4栏:评级的平均值
- 第5栏:评级的标准偏差
- 第6-12列:美学评级的分布(计数),即1-7级,第6位是1,第12位是7。
注意:在极少数的情况下,只有平均值可用,个人评级不可用。在这些情况下,只有平均值可以使用,第5列到第12列都是-1。如果您的模型涉及评分的分布和标准差,请妥善处理这些示例。
照片的ID是唯一的,Photo.net服务器上,文件的真实URL可能会更改。获取图像URL的最佳方法可能是下载托管图像的html页面,并抓取该图像URL的html文件。
DPChallenge.com
该数据集包含16,509张图,AVA(Aesthetic Visual Analysis)数据集也是来源于这个网站。
下载网页链接,在网页中,查询图片链接,替换ID,10013,即可:
http://images.dpchallenge.com/images_challenge/0-999/50/1200/Copyrighted_Image_Reuse_Prohibited_10013.jpg
网页链接:image.php?IMAGE_ID=10013.html
图像:
数据集样本:
1[索引] 10007[照片ID] 89[收到的美学评级数] 5.8876404494382[评级的平均值] 3 0 7 12 13 20 16 10 5 3 2 10009 89 6.78651685393258 0 0 0 8 12 22 20 11 8 8 3 10010 183 4.80874316939891 11 9 23 36 42 27 22 7 4 2 4 10011 187 5.70588235294118 3 4 11 26 38 42 36 21 3 3 5 10012 89 5.78651685393258 1 0 6 11 20 26 12 6 6 1
数据集描述:
- 第1栏:索引
- 第2栏:照片ID
- 第3栏:收到的美学评级数
- 第4栏:评级的平均值
- 第5-14栏:质量等级的分布(计数)为1-10级,第5位是1,第14位是10。
很少一部分照片有0个等级 - 在这些情况下,平均值和分布列的虚拟值为-1。
AVA
AVA: A Large-Scale Database for Aesthetic Visual Analysis:![AVA]]([https://ata2-img.cn-hangzhou.oss-pub.aliyun-inc.com/917a89cc4d569537f0417a18721266e7.png) ](https://ata2-img.cn-hangzhou.oss-pub.aliyun-inc.com/917a89cc4d569537f0417a18721266e7.png))
](https://ata2-img.cn-hangzhou.oss-pub.aliyun-inc.com/917a89cc4d569537f0417a18721266e7.png))
NIMA,Neural Image Assessment所使用的数据集,2017年,由于其在各种应用中的有用性,例如评估图像获取管道(image capture pipelines),存储技术(storage techniques)和共享媒体(sharing media),因此最近自动学习的图像质量评估已成为热门话题。尽管存在这个问题的主观性质,但大多数现有方法仅预测由AVA和TID2013等数据集提供的平均意见得分(MOS)。NIMA的方法与其他方法的区别在于我们使用卷积神经网络预测人类意见得分的分布。NIMA的架构还具有比具有可比性能的其他方法简单得多的优点。NIMA所提出的方法,依赖于经过验证的、最先进的深度物体识别网络的成功。NIMA生成的网络不仅可以用于可靠地对图像进行评分,并且与人类感知具有高度相关性,还可以用于协助在摄影方向中对照片编辑/增强算法进行调整和优化。所有这些都是在不需要“完美”参考图像的情况下完成的,因此,算法支持单图像、语义方面和感知方面的无参考质量评估(No-Reference Quality Assessment)。
美学视觉分析(AVA)包含超过250,000张图像以及丰富的元数据,包括每个图像的大量美学分数,60多个类别的语义标签以及与高级图像质量相关的摄影风格标签分类。
AVA数据集,大约包含250,000张图片,这些照片是在DPChallenge.com)上获取。每张图片由78~549名评分者得分,分数范围为1到10。平均分作为每张图片的真值标签。数据集,根据每张图片的本文信息,为每张图片都标注了1至2个语义标签。整个数据集总共有66种文本形式的语义标签。出现频率较高的语义标签有:Nature,Black and White,Landscape,still-life等。AVA数据集中的图片还做了摄影属性标注,含有14个摄影属性,下面列出了部分属性以及包含该属性的图片数量:Complementary Colors (949), Duotones (1301), High Dynamic Range (396), Image Grain (840), Light on White (1199), Long Exposure (845)。
下图是每个类别展示,绿色是Top4,红色是Bottom4:
标签分布: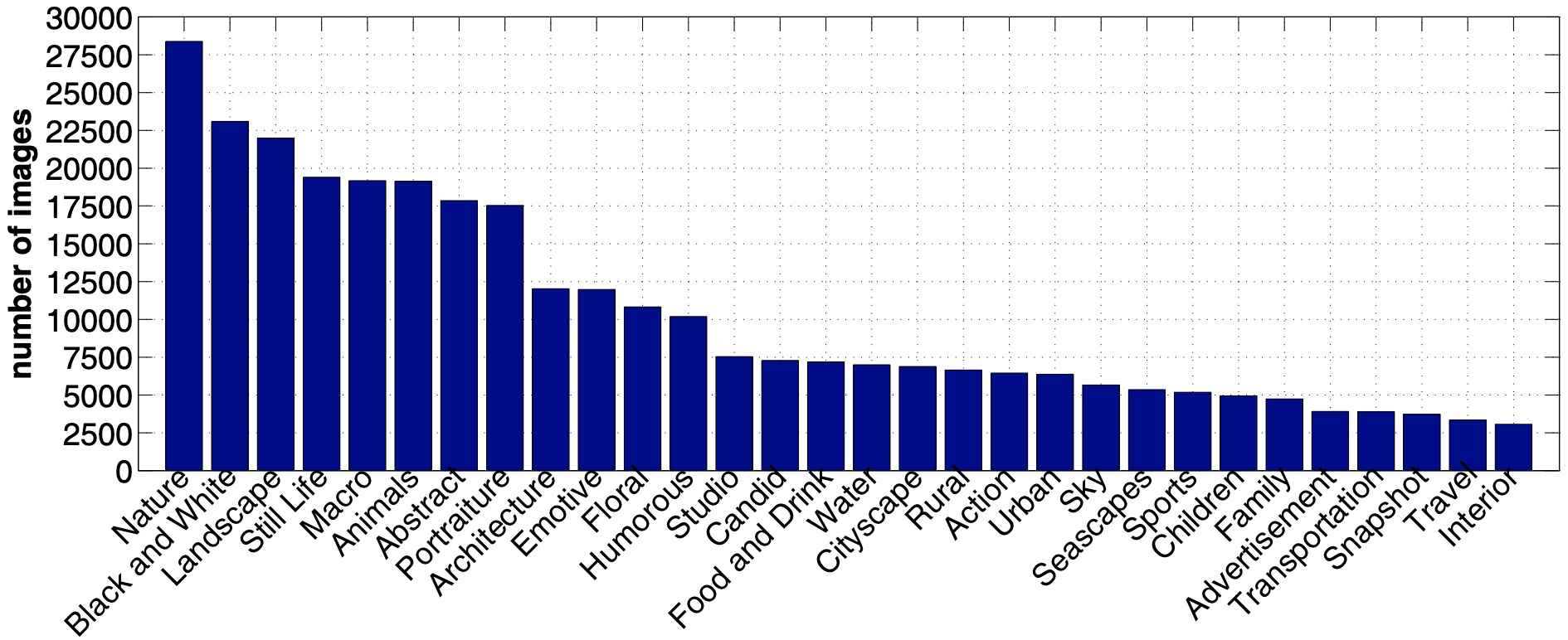
下载方式:AVA下载的GitHub
标注信息:
Place: 149 out of 159 Avg (all users): 4.0996 Avg (commenters): 4.5000 Avg (participants): 3.6607 Avg (non-participants): 4.2195 Views since voting: 760 Views during voting: 372 Votes: 261 Comments: 10 Favorites: 0
Paper汇总:
- Image database TID2013: Peculiarities, results and perspectives
- Waterloo Exploration Database: New Challenges for Image Quality Assessment Models
- Algorithmic Inferencing of Aesthetics and Emotion in Natural Images: An Exposition
- AVA: A Large-Scale Database for Aesthetic Visual Analysis
- RankIQA: Learning from Rankings for No-reference Image Quality Assessment
- NIMA: Neural Image Assessment
参考:

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}