全参考评价的设计指标就是与原视频无限接近才能够达到满分,这样不能反映人眼主观的MOS (Mean Opinion Score) 分数。
第一类是Full Reference (FR) vs Non Reference (NR),即有/无参考质量评估,Non Reference在应用场景中应用比例较高。
第二类是基于参考评价分为Traditional vs Deep Learning (DL),传统方法譬如信号处理PS3R,人的感官对于结构化更加敏感,透过人眼的喜好度进行MOS评分让打分机制进行学习,是通过Deep Learning (DL)实现。
第三类根据打分分为Distortion Generic vs General (Enhancement Included)、Coarse Grain vs Fine Grain和Image (IQA) vs Video (VQA)。Distortion Generic加了许多的噪声破坏(单调破坏),由于在其中某些东西是一直上升到MOS到达一定程度后又呈现下降趋势,所以目前很少能看到Distortion Generic的训练集。质量评估可以作为产品上线后的监督,也可以介入闭环的开发过程评估演算法。Image (IQA) vs Video (VQA)区别在图像和视频部分。
WaDIQAM(NR)
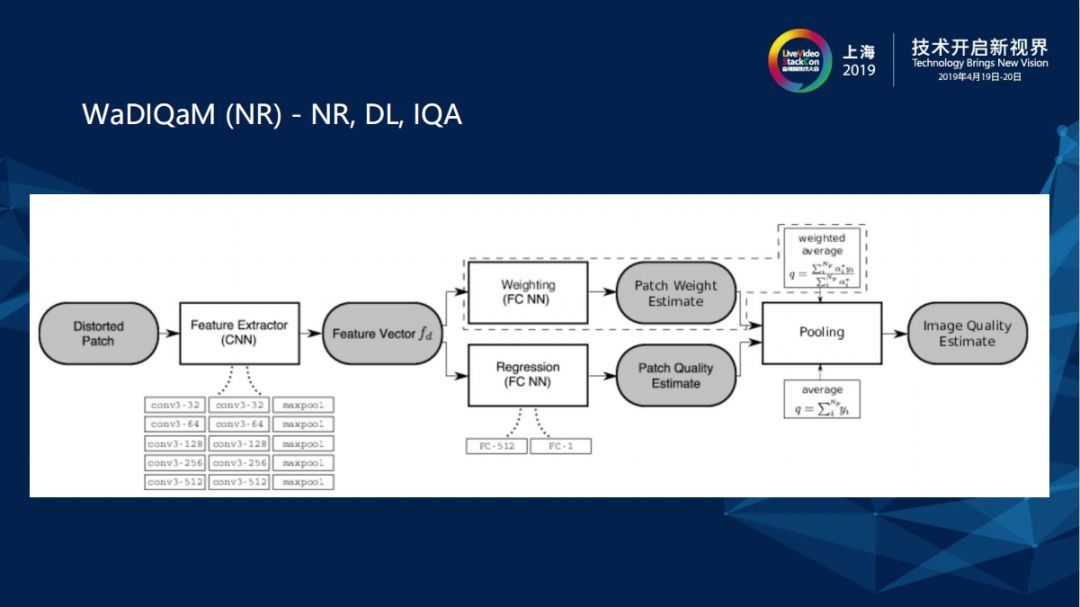
上图中有关Non Reference (NR)、Deep Learning (DL)、Image (IQA)图像质量评估可以看到,进来一张图通常会取N个Patch,每个块通过CNN深度学习网络找到Image 的feature,之后针对每个块的权重和特征来学习它的位置以及在质量评估中的比例(Patch Weight Estimate),Patch Quality Estimate是通过CNN抽取feature之后做 Regression,再通过线性回归得出MOS分数,最后将Patch Weight Estimate和Patch Quality Estimate做一个结合得到Image Quality Estimate。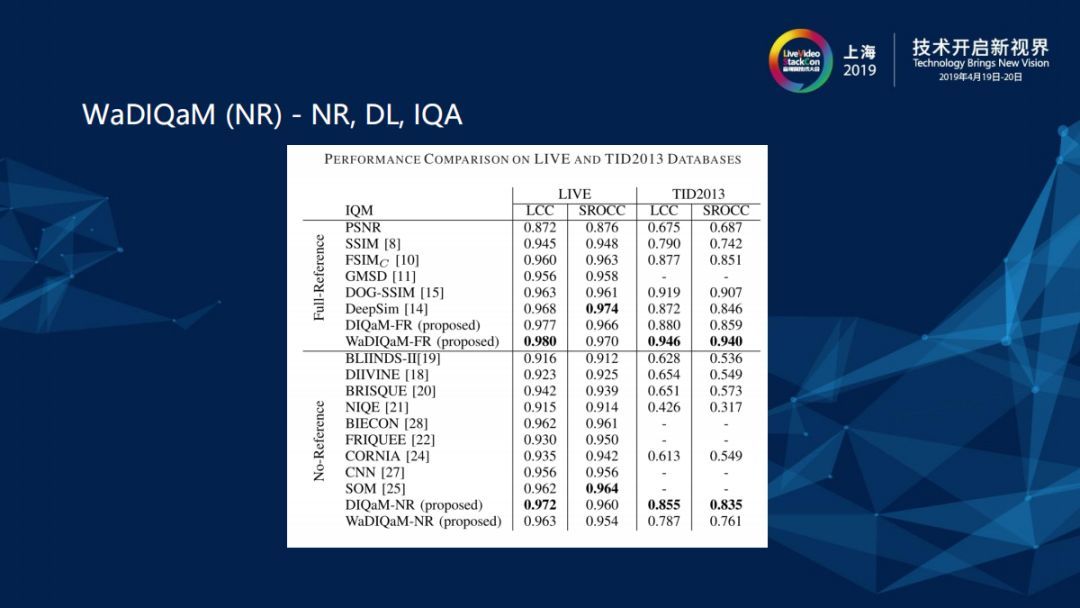
LIVE和TID2013是两个主观评价的训练集,包含各式各样的图片、Destruction和打分,LCC和SROCC是关于质量评估的两个指标,LCC是通过相关性和准确性衡量算法性能,SROCC是通过单调顺序性衡量算法性能,这两个指标越接近1越好。Non Reference (NR)Wa方法的表现还算不错,而且有对应的Full Reference (FR)版本,在大家的理解上普遍存在Non Reference (NR)方法比Full Reference (FR)稍差的概念。
DeepVQA
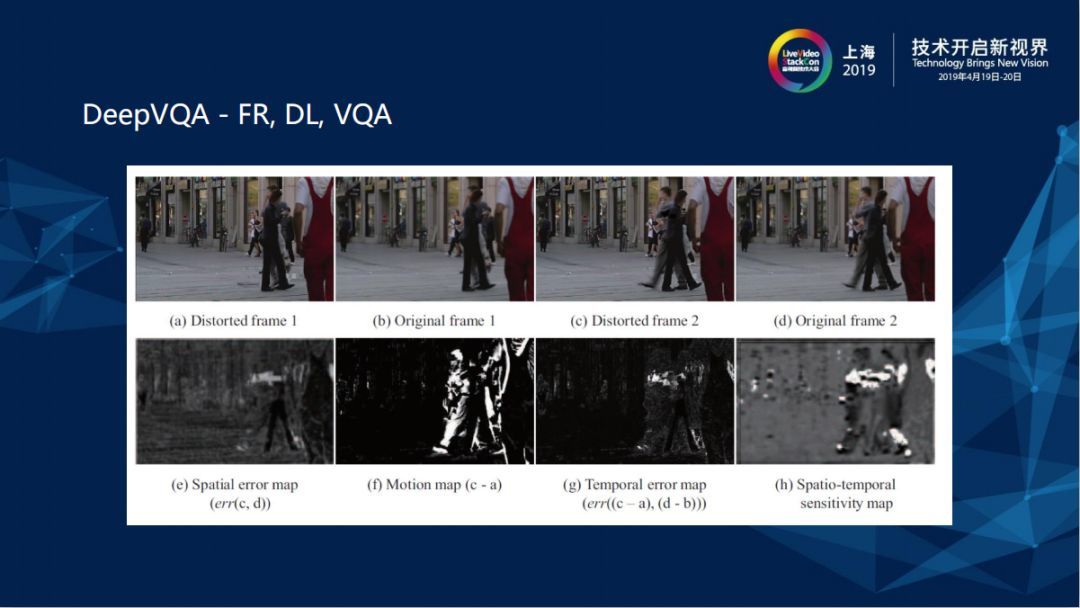
DQA相较于IQA多了一些时域上的信息,由上图可知,上层两张frame图是压缩破坏前的Original frame,下层显示的是压缩破坏后的图片,有frame1和frame2的motion map,所以是存在时域上的特征。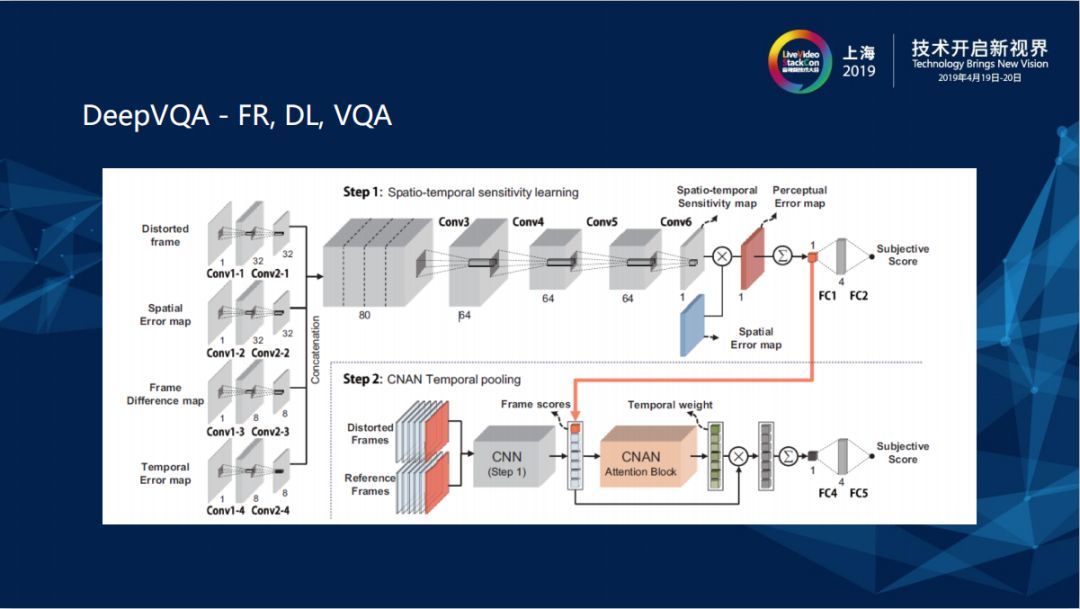
在网络里相当于是把四个东西concatenate在一起,它有衡量IQA输入的Distorted Image,也有motion上的Distortion 可以把frame1和frame2相减,它把Temporal Error map传输进去,也不止是把破坏过的图像传入进去,它是Full Reference (FR)但也把Reference 时域上的差距传进去建构CNN,最后得到Subjective Score。真正测试时会通过上层已经经过训练的网络,再通过某个Temporal weight和pooling把时域上的信息抽取出来。

若有收获,就点个赞吧
0 人点赞
