ID3决策树是比较经典的决策树,在周志华的机器学习中,生成决策树的算法为:
算法的关键是如何选择最优划分属性,在ID3决策树中,用信息增益来指导决策树选择最优划分属性
首先定义信息熵为:
再定义信息增益为:
一般而言,信息增益越大,意味着使用属性a进行划分所获得的纯度提升越大,因此我们选择最大信息增益的属性作为最优划分属性。
Python实现思路
树的数据表示
既然要实现一棵树,首先要做的就是定义节点的数据结构,在C中,节点一般以结构体的形式存储,所以我们在Python中可以参考这一思路定义一个节点类:
class Node():"""ID3决策树的节点parent -- 父节点sons -- 子节点集合,即在该节点最优划分属性下每个属性值的分支attrs -- 该节点下的最优划分属性parent_attrs_value -- 表示该节点是父节点哪一个属性的分支label -- 如果这个节点是叶子节点,则存放标签"""def __init__(self, parent=None):self.parent = parentself.sons = []self.attr = Noneself.parent_attrs_value = Noneself.label = None
但在实际操作中,使用这一方法给代码的调试增加了难度,同时不利于后面用Graphviz包实现决策树的可视化,因此本文考虑使用另一种数据结构表示树,就是Python中的字典,我们先来看看对于西瓜书中给出的一颗决策树,用字典是如何表示的:
西瓜书中的一颗决策树: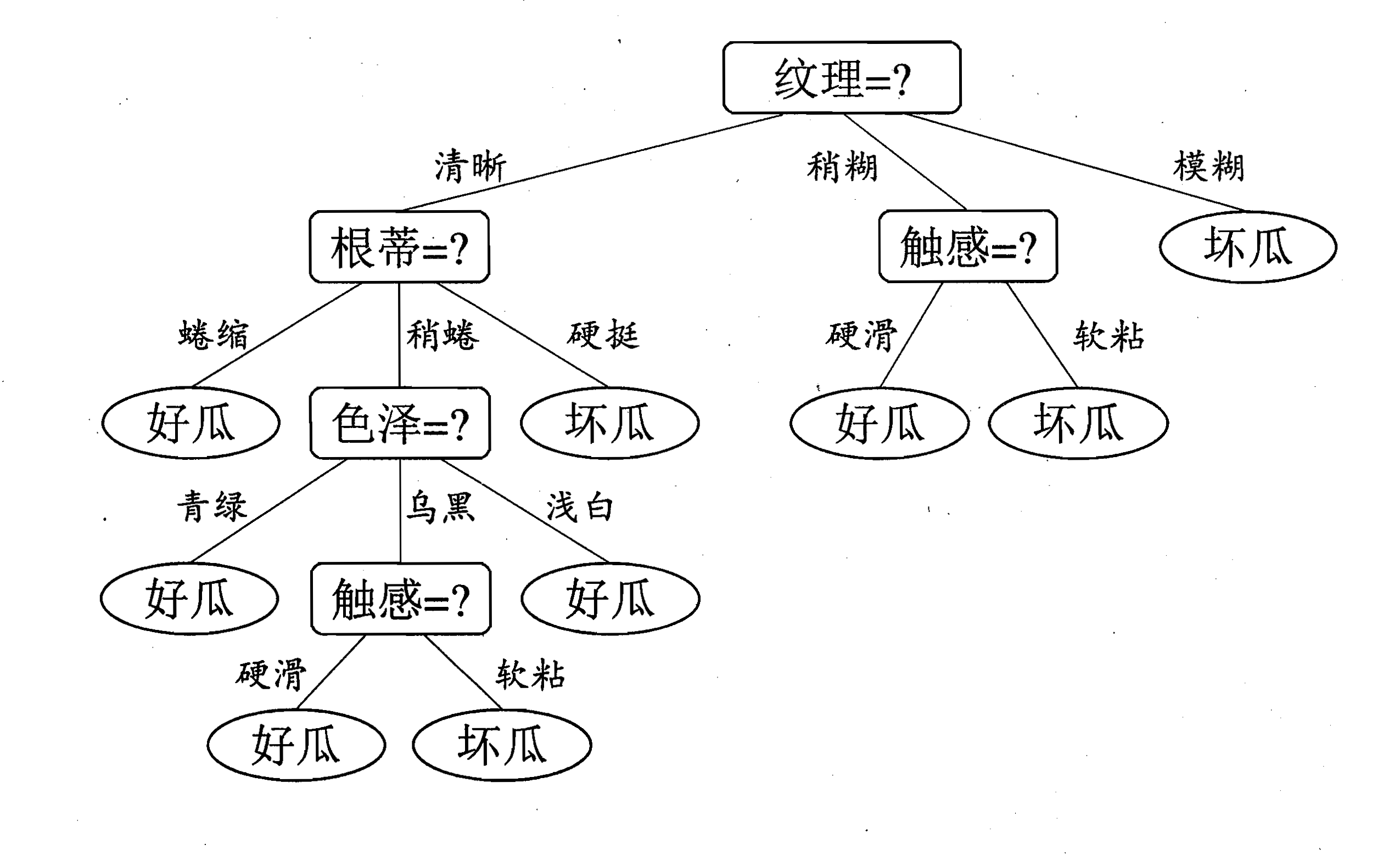
对应的Python字典表示:
tree = {<!-- -->'纹理':{<!-- -->'清晰':{<!-- -->'根蒂':{<!-- -->'蜷缩':{<!-- -->'label':'是'},'稍蜷':{<!-- -->'色泽':{<!-- -->'青绿':{<!-- -->'label':'是'},'乌黑':{<!-- -->'触感':{<!-- -->'硬滑':{<!-- -->'label':'是'},'软粘':{<!-- -->'label':'否'}}},'浅白':{<!-- -->'label':'是'}}},'硬挺':{<!-- -->'label':'否'}}},'稍糊':{<!-- -->'触感':{<!-- -->'硬滑':{<!-- -->'label':'否'},'软粘':{<!-- -->'label':'是'}}},'模糊':{<!-- -->'label':'否'}}}
如何可视化决策树
在本文中,使用Graphviz包进行决策树的可视化,这里是官网和文档
只需使用几条简单的代码便可将决策树的节点绘制出来:
g = graphviz.Digraph(name=,filename=, format='png')g.node(name=, label=, fontname="Microsoft YaHei", shape=)g.edge(tail_name, head_name, label=, fontname="Microsoft YaHei")g.view()
要注意,如果决策树的信息是中文的,要在fontname参数中指定中文字体,不然会出现乱码
Python代码
DecesionTree.py
import numpy as npimport scipy.io as siofrom collections import Counterfrom graphviz import Digraphclass DecisionTree():"""一个构建ID3决策树的类attrs -- 存放属性的字典, 字典中,键为属性名,值为属性的取值,最后一个属性为标签属性X -- 训练数据y -- 标签attr_idx -- 属性列索引tree -- 生成的决策树,用字典形式存放node_name -- 用于对决策树的可视化,在graphviz中对节点的命名"""def __init__(self):self.attrs = Noneself.X = Noneself.y = Noneself.attr_idx = Noneself.tree = {<!-- -->}self.node_name = "0"def get_attrs(self, data):"""对数据集进行处理,得到属性与对应的属性取值args:data -- 输入的数据矩阵, shape=(samples+1, features), dtype='<U?', 其中,第一行为属性,最后一列为标签returns:attrs -- 存放属性的字典, 字典中,键为属性名,值为属性的取值"""attrs = {<!-- -->}for i in range(data.shape[1]):attrs_values = sorted(set(data[1:, i]))attrs[data[0][i]] = attrs_valuesself.attrs = attrsreturn attrsdef generate_tree(self, data):"""生成决策树args:data -- 输入的数据矩阵, shape=(samples+1, features+label), dtype='<U?', 其中,第一行为属性,最后一列为标签"""self.X = data[1:, :-1]self.y = data[1:, -1]# 先创建一个不含label属性的纯变量属性字典pure_attrs = self.attrs.copy()del(pure_attrs['label'])# 构造一个只含属性名的列表attr_names = [attr_name for attr_name in pure_attrs.keys()]# 将属性名编号,方便查找其在数据中对应的列attr_idx = {<!-- -->}for num, attr in enumerate(attr_names):attr_idx[attr] = numself.attr_idx = attr_idx# 生成根节点self.tree['root_node'] = {<!-- -->}self._generate_tree(self.X, self.y, self.tree['root_node'], pure_attrs, attr_idx)self.tree = self.tree['root_node']def _generate_tree(self, X, y, node, attrs, attr_idx):"""递归生成决策树args:X -- 输入的数据矩阵, shape=(samples, features), dtype='<U?'y -- 标签, shape=(samples, )parent_node -- 父节点,此次递归函数是父节点的某一个属性值的递归attrs -- 属性字典, 即从父节点分支到现在的节点时,还没有被划分的属性attr_idx -- 属性在数据中列索引"""#--------- 如果训练集中样本全属于同一类别 ---------#if len(set(y.tolist())) == 1:node['label'] = y[0]return#-------- 如果属性集为空集或者训练集中样本在属性集上取值相同 ---------## 判断训练集样本在属性集中取值是否相同same = Truefor i in range(X.shape[1]):if len(set(X[:, i].tolist())) > 1:same = Falseif not attrs or same:y_counter = Counter(y)most_y = y_counter.most_common()[0][0]node['label'] = most_yreturn#--------- 选择最优属性生成分支 ---------## 选出最优划分属性optimal_attr = self.choose_optimal_attr(X, y, attrs, attr_idx)node[optimal_attr] = {<!-- -->}node = node[optimal_attr]# 对于最优划分属性下每个属性值for attr_value in attrs[optimal_attr]:# 生成分支node[attr_value] = {<!-- -->}# 令Dv表示X中在optimal_attr上取值为attr_value的样本子集Dv = X.copy()attr_value_idx = Dv[:, attr_idx[optimal_attr]] == attr_valueDv = Dv[attr_value_idx, :]y_Dv = y[attr_value_idx]Dv = np.delete(Dv, attr_idx[optimal_attr], 1)# 如果Dv为空if Dv.size == 0:# 将分支节点标记为叶节点,其类别标记为X中样本最多的类,即统计yy_counter = Counter(y)most_y = y_counter.most_common()[0][0]node[attr_value]['label'] = most_yelse:# 更新属性字典new_attrs = attrs.copy()del(new_attrs[optimal_attr])# 更新属性列索引new_attr_names = [new_attr_name for new_attr_name in new_attrs.keys()]new_attr_idx = {<!-- -->}for num, attr in enumerate(new_attr_names):new_attr_idx[attr] = numself._generate_tree(Dv, y_Dv, node[attr_value], new_attrs, new_attr_idx)def compute_Ent(self, y):"""计算给出属性名列表所对应的所有样本的信息熵args:y -- 标签数组, shape=(samples, )return:Ent -- 样本的信息熵"""Ent = 0m = np.size(y)for label in self.attrs['label']:pk = np.sum(y == label)pk = pk / mlog2pk = np.log2(pk + 1e-8) # 防止算得0,导致返回nanEnt -= pk * log2pkreturn Entdef choose_optimal_attr(self, X, y, attrs, attr_idx):"""选择最优划分属性 划分标准:属性的信息增益args:X -- 输入的数据矩阵, shape=(samples, features), dtype='<U?'y -- 标签, shape=(samples, )attrs -- 属性字典attr_idx -- 属性在数据中列索引returns:max_gain_attr -- 最大的信息增益对应的属性"""# 计算当前所含属性对应所有样本的信息熵Ent = self.compute_Ent(y)m = np.size(y)# 记录当前最大的信息增益以及对应的属性max_gain = 0max_gain_attr = None# 计算每一个属性的信息增益for attr, idx in attr_idx.items():x = X[:, idx]gain = Ent# 计算一个属性中每个属性值的信息熵for attr_value in attrs[attr]:_y = y[x==attr_value]if _y.size != 0:ent = self.compute_Ent(_y)else:ent = 0gain -= np.size(_y) / m * entif gain > max_gain:max_gain = gainmax_gain_attr = attrreturn max_gain_attrdef predict(self, predict_x):"""预测样本结果args:predict_x -- 预测样本数据矩阵 shape=(samples, features)returns:predict_y -- 样本的预测结果 shape=(samples, )"""s = predict_x.shape[0]predict_y = []for i in range(s):node = self.treewhile(1):if 'label' in node.keys():predict_y.append(node['label'])breakelif list(node.keys())[0] in self.attrs.keys():attr = list(node.keys())[0]idx = self.attr_idx[attr]node = node[attr]else:node = node[predict_x[i, idx]]return predict_ydef tree_traversal(self, g, parent_node, parent_node_name, parent_attr, parent_attr_value):"""对树进行遍历,生成可视化的节点g -- 要绘制的有向图parent_node -- 父节点parent_node_name -- 父节点在有向图中的代号parent_attr -- 父节点的属性parent_attr_value -- 父节点到该节点的属性值"""if (parent_attr and parent_attr_value) is None:if 'label' in parent_node.keys():g.node(name=self.node_name, label=parent_node['label'], fontname="Microsoft YaHei")returnelse:attr = list(parent_node.keys())[0]node = parent_node[attr]parent_node_name = "0"for attr_value in node.keys():self.tree_traversal(g, node[attr_value], parent_node_name, attr, attr_value)else:if 'label' in parent_node.keys():g.node(name=parent_node_name, label=parent_attr, fontname="Microsoft YaHei", shape='box')self.node_name = str(int(self.node_name) + 1)g.node(name=self.node_name, label=parent_node['label'], fontname="Microsoft YaHei")g.edge(parent_node_name, self.node_name, label=parent_attr_value, fontname="Microsoft YaHei")else:attr = list(parent_node.keys())[0]g.node(name=parent_node_name, label=parent_attr, fontname="Microsoft YaHei", shape='box')self.node_name = str(int(self.node_name) + 1)g.node(name=self.node_name, label=attr, fontname="Microsoft YaHei", shape='box')g.edge(parent_node_name, self.node_name, label=parent_attr_value, fontname="Microsoft YaHei")node = parent_node[attr]parent_node_name = self.node_namefor attr_value in node.keys():self.tree_traversal(g, node[attr_value], parent_node_name, attr, attr_value)def tree_visualize(self, file_name=None):"""将决策树可视化args:file_name -- 若给出该参数,则将决策树保存为file_name的图片"""if file_name:g = Digraph("Decision Tree", filename=file_name, format='png')else:g = Digraph("Decision Tree")self.tree_traversal(g, self.tree, None, None, None)g.view()if __name__ == "__main__":pass
主函数,以西瓜树的西瓜数据集为例生成决策树,原数据集是Matlab的cell数组,并以mat文件存放,因此需要预处理一下:
import numpy as npimport scipy.io as siofrom DecisionTree import DecisionTreedef preprocess():raw_data = sio.loadmat('watermelon.mat')raw_data = raw_data['watermelon']data = np.zeros(raw_data.shape, dtype='<U20')for i in range(data.shape[0]):for j in range(data.shape[1]):data[i, j] = raw_data[i, j][0]data[0, -1] = 'label'return datadef main_1():"""完整决策树"""data = preprocess()DTree = DecisionTree()attrs = DTree.get_attrs(data)DTree.generate_tree(data)DTree.tree_visualize('watermelob_tree')def main_2():"""留出两个样本作为测试集"""data = preprocess()train_idx = np.delete(np.arange(0, 18), [8, 17])test_idx = [8, 17]train_data = data[train_idx, :]test_data = data[test_idx, :]test_X = test_data[:, :-1]test_y = test_data[:, -1]DTree = DecisionTree()DTree.get_attrs(train_data)DTree.generate_tree(train_data)predict_y = DTree.predict(test_X)print(predict_y)DTree.tree_visualize('watermelon_tree_2')main_1()
最终生成的决策树图片为: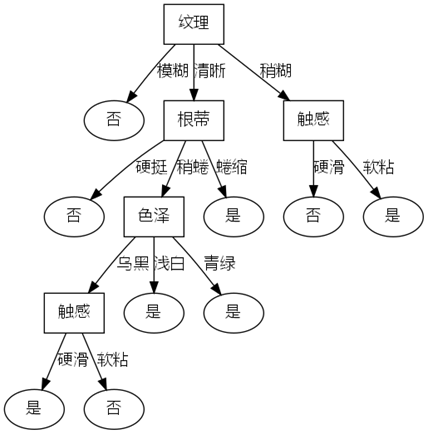
到这里我们就成功地用Python实现了ID3决策树!

若有收获,就点个赞吧
0 人点赞
