Higher-order function
把别的函数当参数的函数
高阶函数基础:
变量指向函数
函数本身和变量一样可以相互赋值 “即函数也等同于变量”
def func(a):print("function")return 0c = funcc(10)print(type(c))#===================================#outputfunction<class 'function'>
实际写代码时,像下面这样操作
def func(a):print("function")return 0func = 5 # 当整数赋值给函数func时# 已经从<class 'function'>变成<class 'int'>try:func(10)except TypeError:print("func():TypeError")print("func:",func)print("func-type:",type(func))#===================================#outputfunc():TypeErrorfunc: 5func-type: <class 'int'>
简单高阶函数
当一个函数可以接收 另一个函数作为参数时, 这个函数就是高阶函数
def func1(f):print("function1")f()return 0def func2():print("function2")return 0func1(func2)#===================================#outputfunction1function2
python内置高阶函数
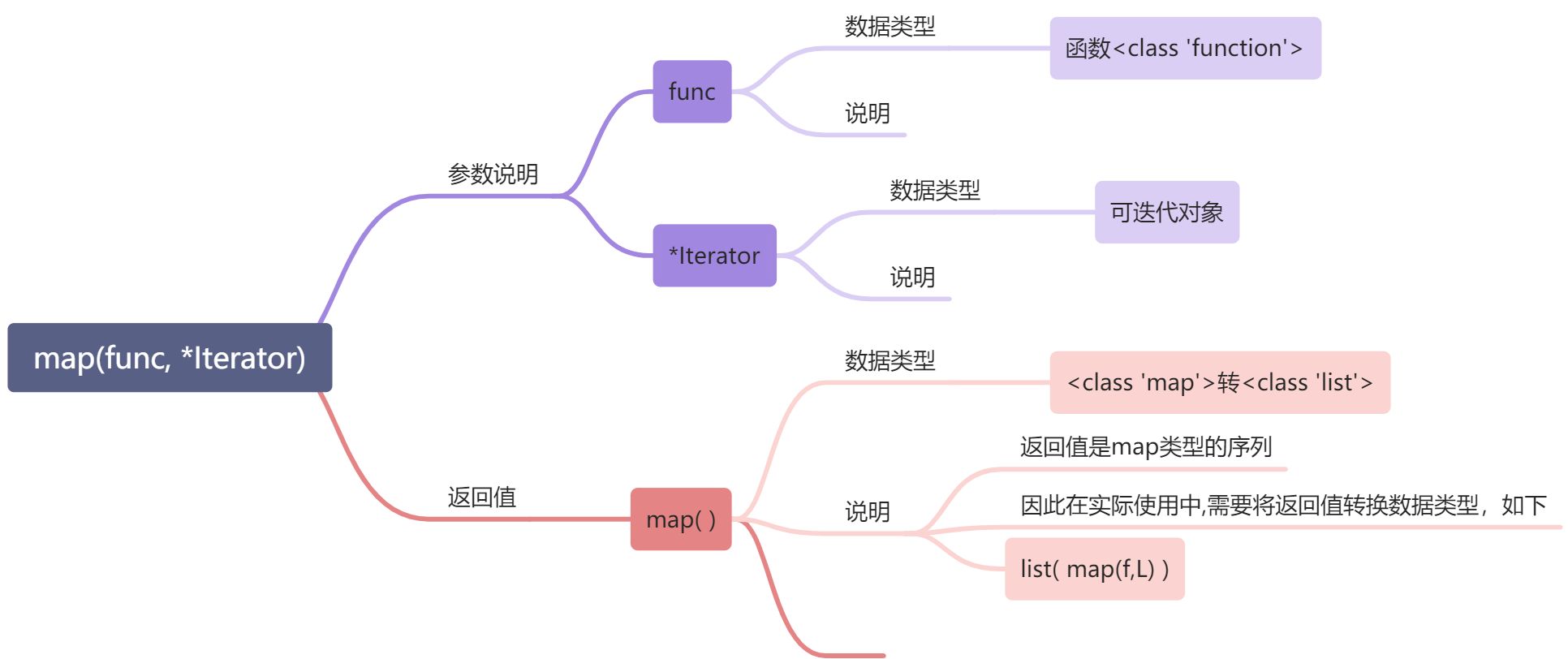
映射器:map( )
map() 的功能就是将序列 “L” 中的所有元素,放进f(x)中遍历一次, 并生成新的序列,形成一 一对应的映射关系
# map()基本原理#============================def f(x): #map()接受的第一个参数"函数"return x+xL = [1,2,3,4,5] #map()接受的第二个参数"序列"L_done = [] #map()的实现部分for x in L: #L_done就是map()的返回值f(x)L_done.append(f(x))print(L)print(L_done)#============================#output[1, 2, 3, 4, 5][2, 4, 6, 8, 10]
 ```python
def f(x): #map()接受的第一个参数”函数”
return x+x
```python
def f(x): #map()接受的第一个参数”函数”
return x+x
L = [1,2,3,4,5] #map()接受的第二个参数”序列”
D = map(f,L)
D2 = list(D) #注意: map的返回值的数据类型是
# 需要转换成其他的数据类型例如<class 'list'>
print(type(D)) print(D)
print(type(D2)) print(D2)
=================================
output
---<a name="rHlRA"></a>#### 累加器:reduce( )> > “initial”默认值是“None”,则‘function’> 接受的第一个参数为 “sequence” 的一个元素 “L[0]” ,“L[1]” 则为第二个参数。> 【即:function(L[0], L[1])】>> “initial”如果不是默认值,则‘function’> 接受的第一个参数为 “initial” ,“L[0]” 则为第二个参数。> 【即:function(initial, L[0])】>> 而函数“function”的返回值将做为下一次“function”执行的第一个参数,> 第二个参数则为‘L[2]’> 【f=function(L[0], L[1])】> 【function(f, L[2])】>> 直至遍历整个“sequence”,最后function的返回值即为reduce( )的返回值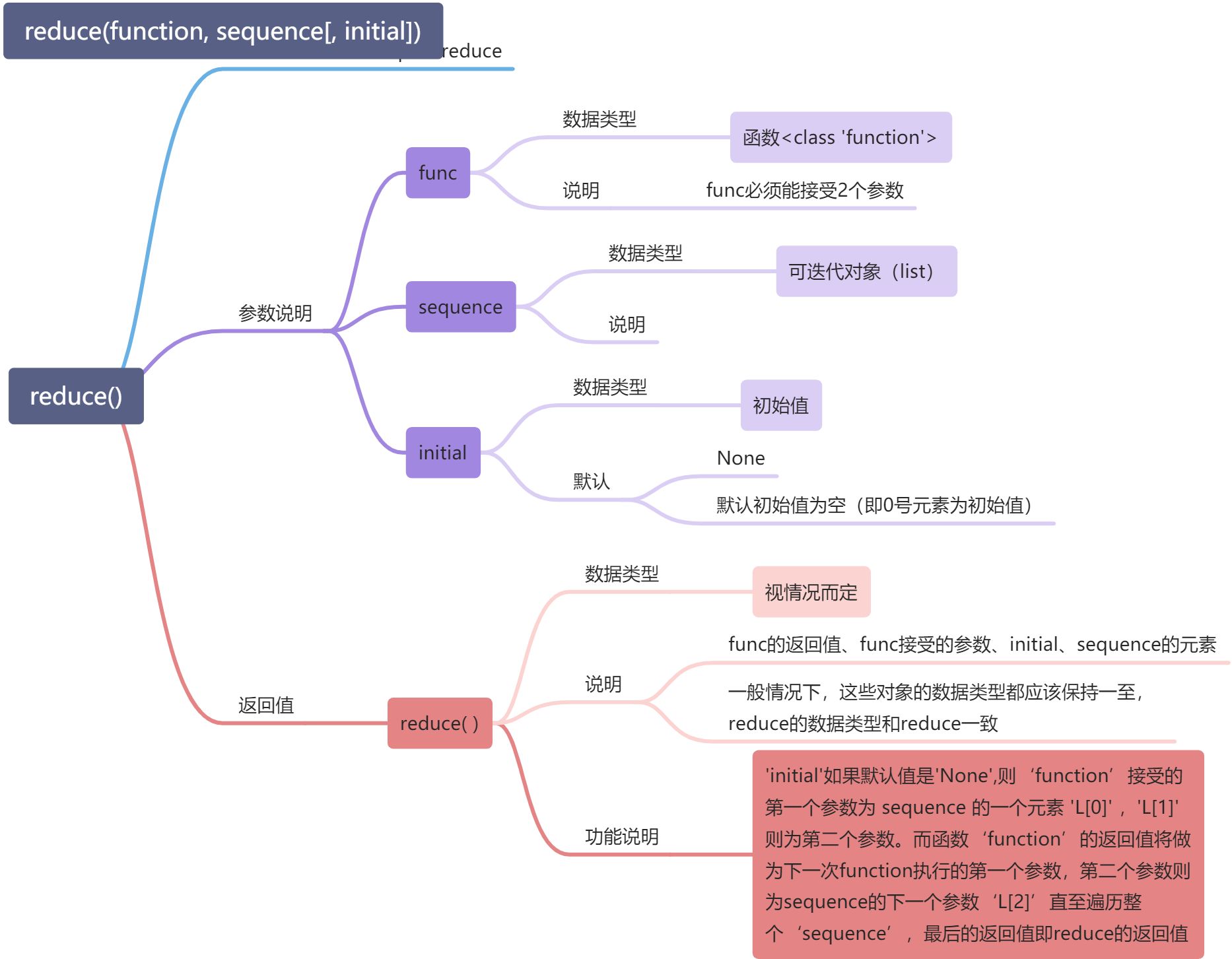```python基本原理下面两个案例具有相同的结果#================================# 案例1def f(x,y):if x == None:return yelse:return x + yL = ["A","B","C","D","E"]initial = NoneoutputA = f(f(f(f(f(initial, L[0]), L[1]), L[2]), L[3]), L[4])print(outputA)#=================================# 案例2from functools import reducedef f(x,y):return x + yL = ["A","B","C","D","E"]outputA = reduce(f,L)print(outputA)outputA = reduce(f,L,None)print(outputA)#=================================
from functools import reducedef f(x, y):print("x:",x)print("y:",y)return x+yL = ["A","B","C","D","E"]Ld = reduce(f,L,"F-")print("reduce:",Ld)#=================================# Outputx: F-y: Ax: F-Ay: Bx: F-ABy: Cx: F-ABCy: Dx: F-ABCDy: Ereduce: F-ABCDE
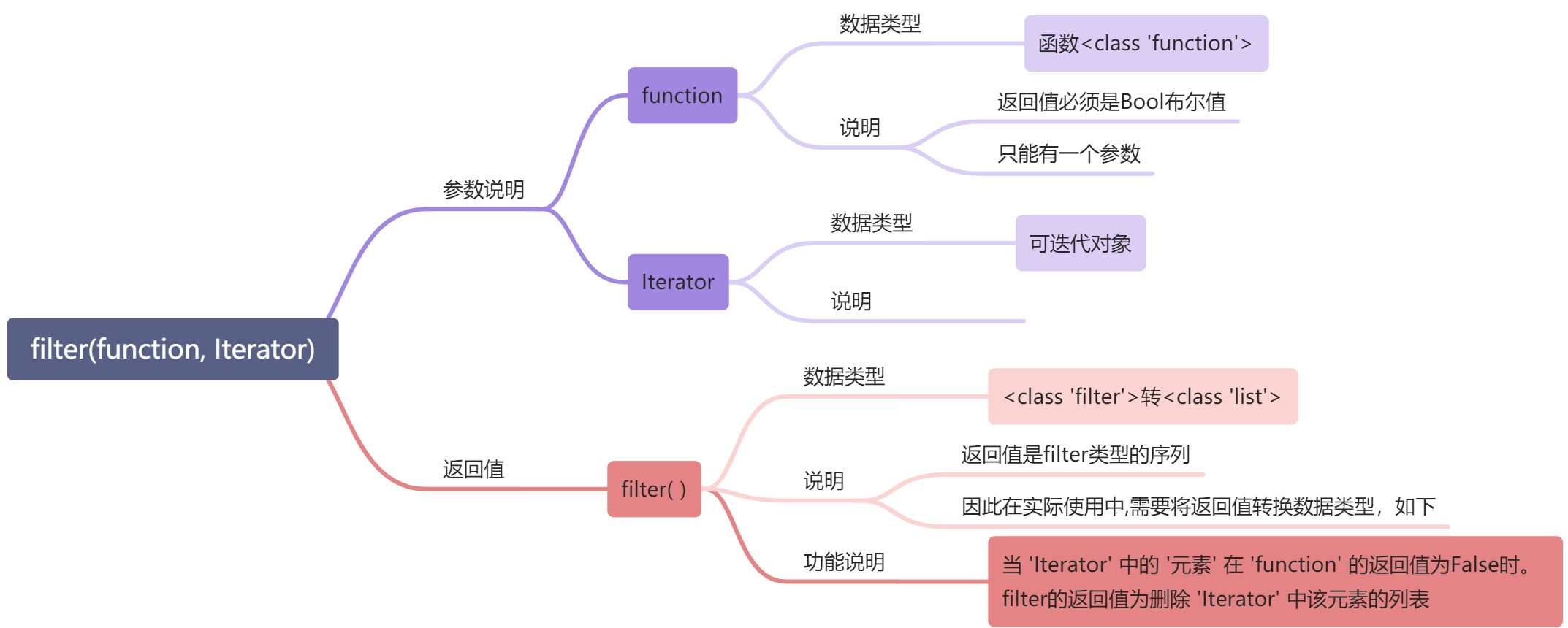
筛选器:filter( )
可以根据一些规则f(x)去筛选列表 语法和map( )相似 如果函数的返回值是False就会被剔除
 ```python
```python
用于判断是否为偶数的函数
def f(x):
if x%2 != 0:
print(“Save”,x)
return True
else :
print(“Delete:”,x)
return False
L = [1, 2, 3, 4, 5, 6, 7, 8, 9]
D = filter(f,L) D = list(D) print(D)
=================================
Output
Save 1 Delete: 2 Save 3 Delete: 4 Save 5 Delete: 6 Save 7 Delete: 8 Save 9 [1, 3, 5, 7, 9]
---<a name="yIXVo"></a>#### 排序器:sorted( )> 事实上,之前在学 **序列容器 **的时候提到过类似的函数> **L.sort(key=None, reverse=False) **这个函数其实也是个高阶函数>> Sorted的工作原理:> sorted会给每一个Iterator中的每一个元素一个Key(类似Dict数据类型)> sorted默认情况下是以自身为Key> sorted会通过判单key的大小进行排序,默认是从小到大>> key也可以接受一个函数f(x)作为排序规则> Iterator会将元素做为参数x,f(x)返回的值将作为key值进行判断大小> 和之前一样,通过判断大小进行排序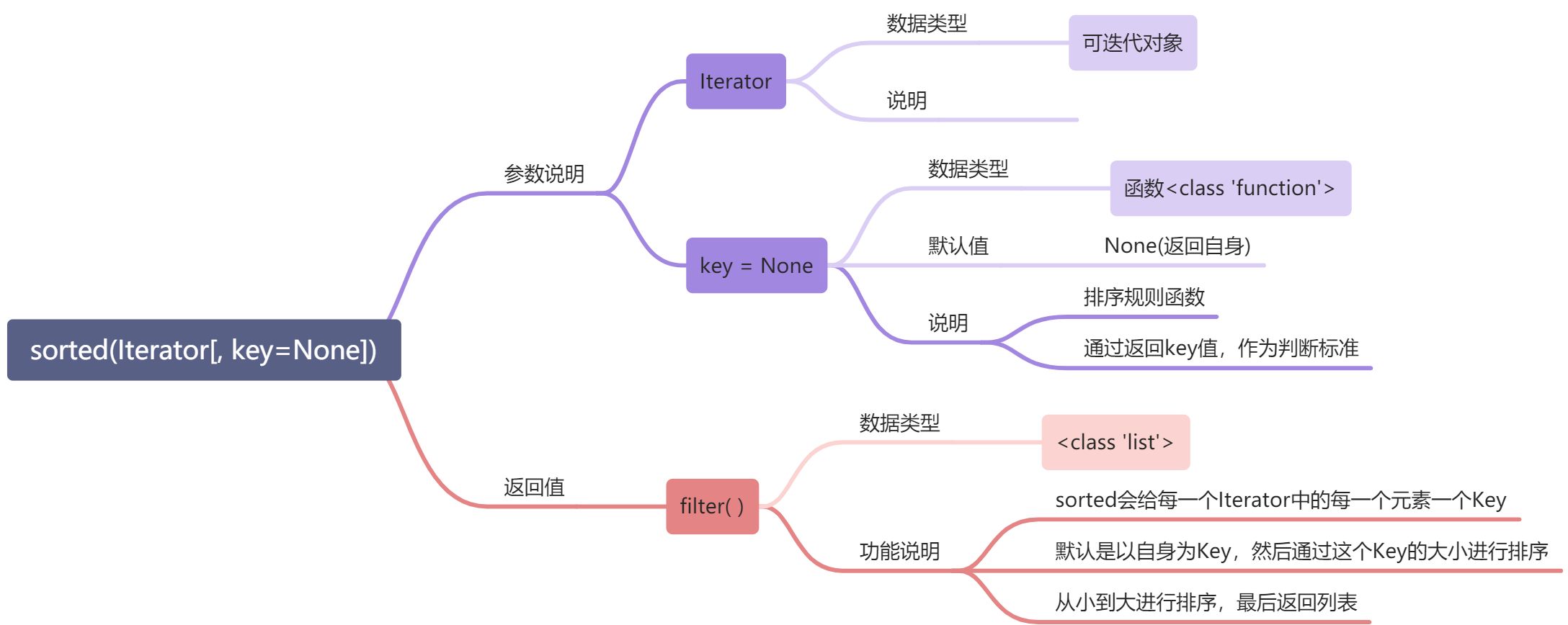```pythonL=["A", "D", "C", "B"]def f(x):if x == "A":return 1elif x == "B":return 2elif x == "C":return 3elif x == "D":return 4else:return 0L2 = sorted(L, key=f)print(L2)#=================================# Output['A', 'B', 'C', 'D']
# 如果将返回值顺序调整一一下#=================================L=["A", "D", "C", "B"]def f(x):if x == "A":return 2elif x == "B":return 1elif x == "C":return 4elif x == "D":return 3else:return 0L2 = sorted(L, key=f)print(L2)#=================================# Output['B', 'A', 'D', 'C']

若有收获,就点个赞吧
0 人点赞
