所有非标准编码的pdf均可使用此OCR软件转换
比如:下面这个pdf由于选中一侧栏文字的时候,对侧栏文字一起选中,导致翻译异常。这个pdf需要用OCR软件转换。

打开Abbyy FineReader15 ,然后工具菜单,OCR编辑器。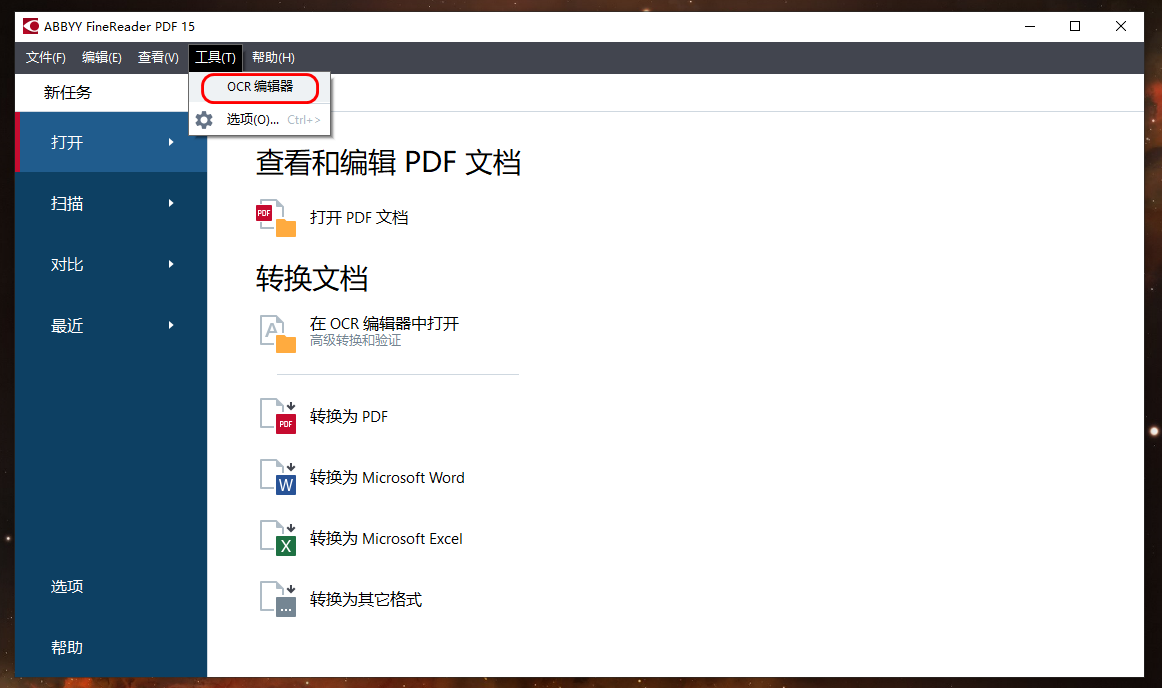
在打开的OCR编辑器窗口中,先确保选择了正确的OCR语言,如下图。大部分中文或英文的文档都可以选中“简体中文和英语”,包括存英文的文档。
然后点击工具栏上的“打开”按钮。打开要进行OCR转换的非标准编码PDF文档。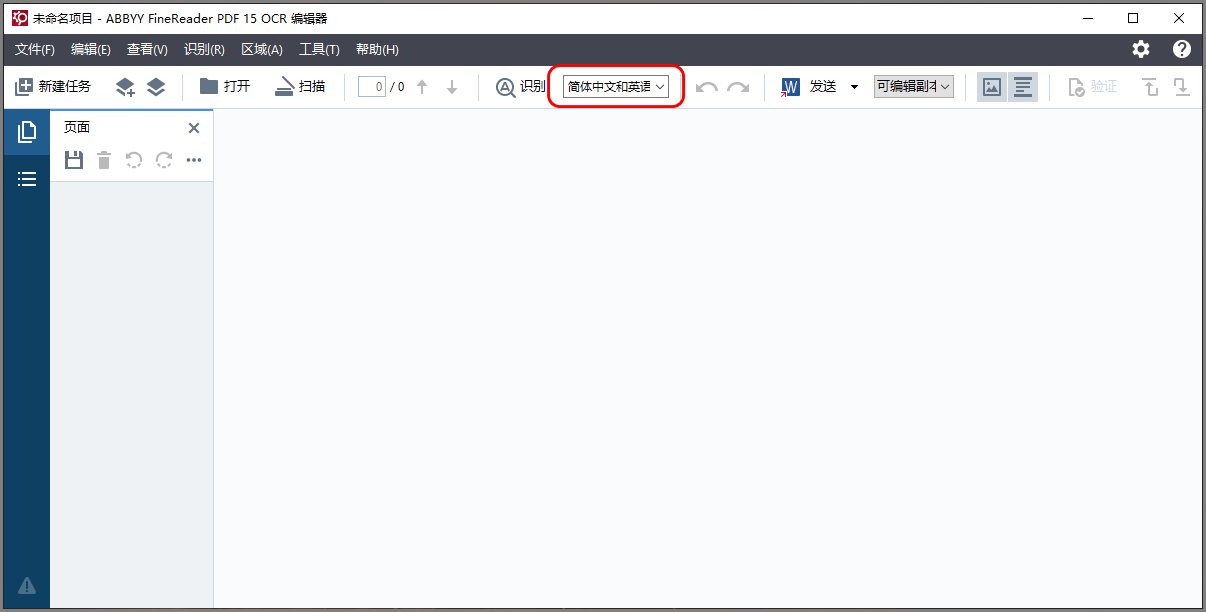
软件会立即开始转换。时间长度和电脑配置及文档页数有关系。但一般10几页的文献时间很短,不会超过1分钟。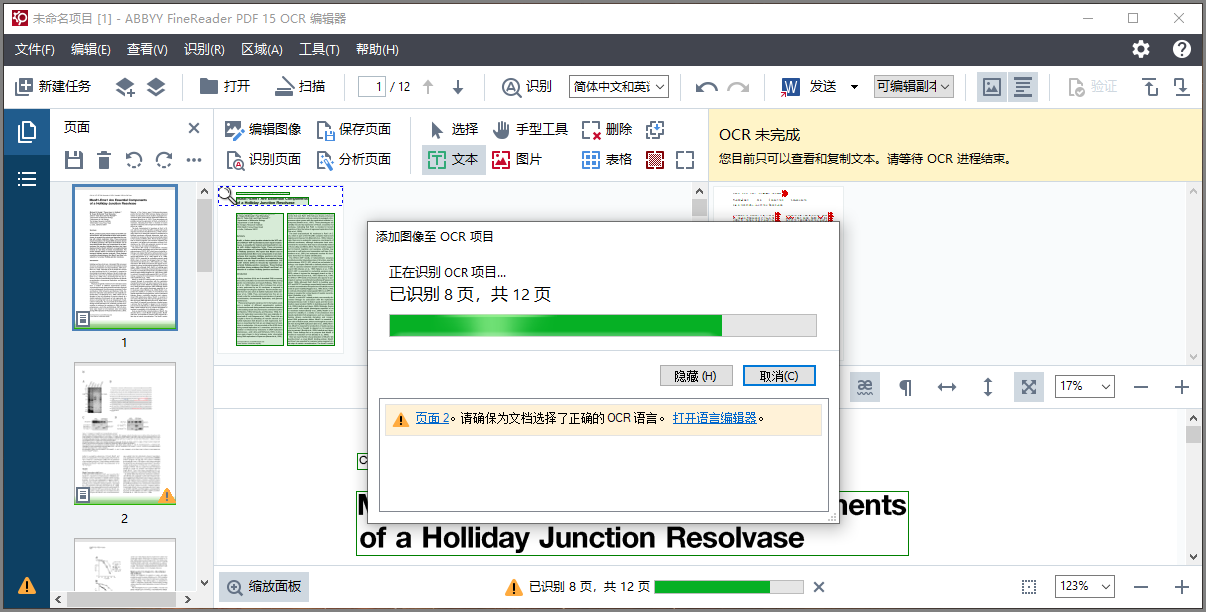
转换完成后按下图点击,点击“另存为可搜索的PDF文档”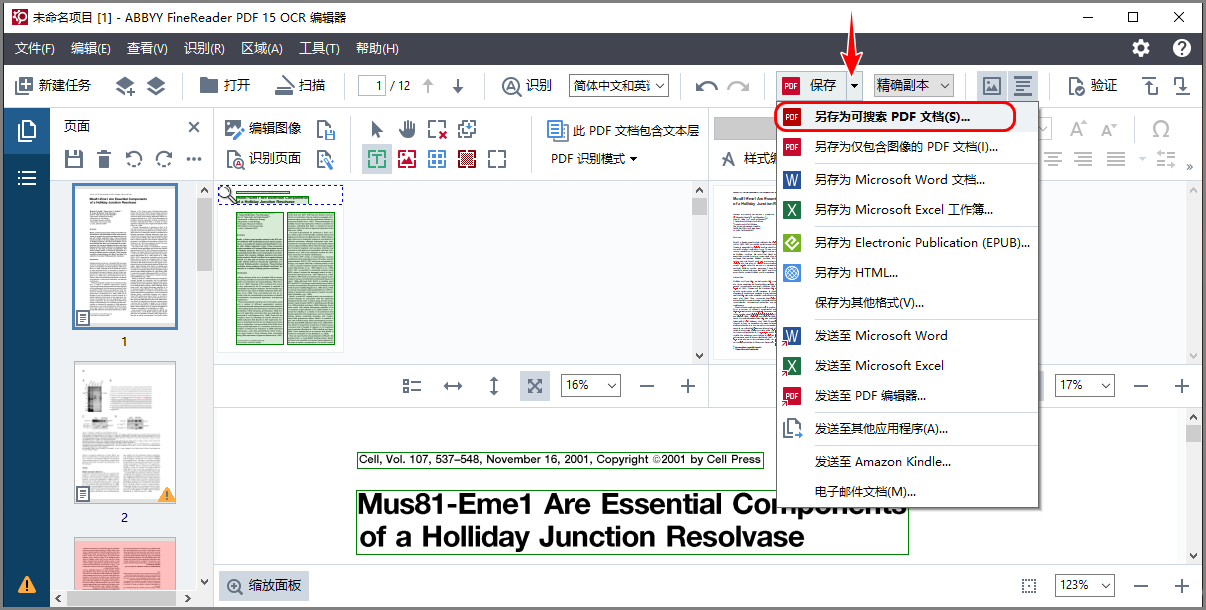
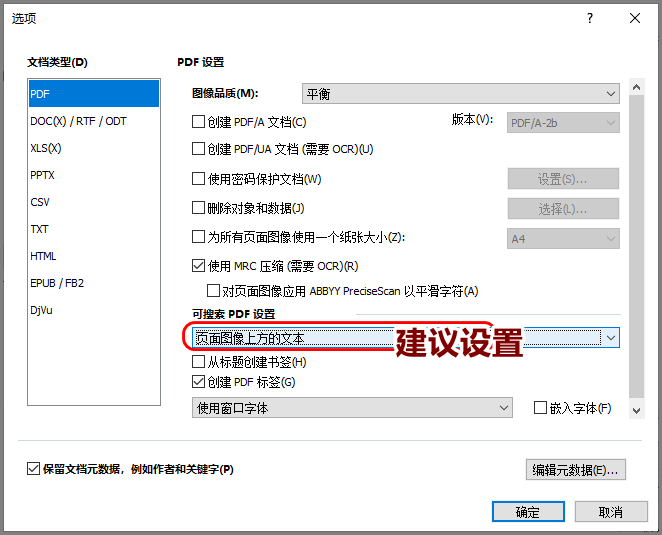
在弹出的保存窗口中,自己命名文件。另外在“选项”按钮中点开,建议设置“页面图像上方的文本”,意思是把OCR识别的标准文本放在PDF的最上层。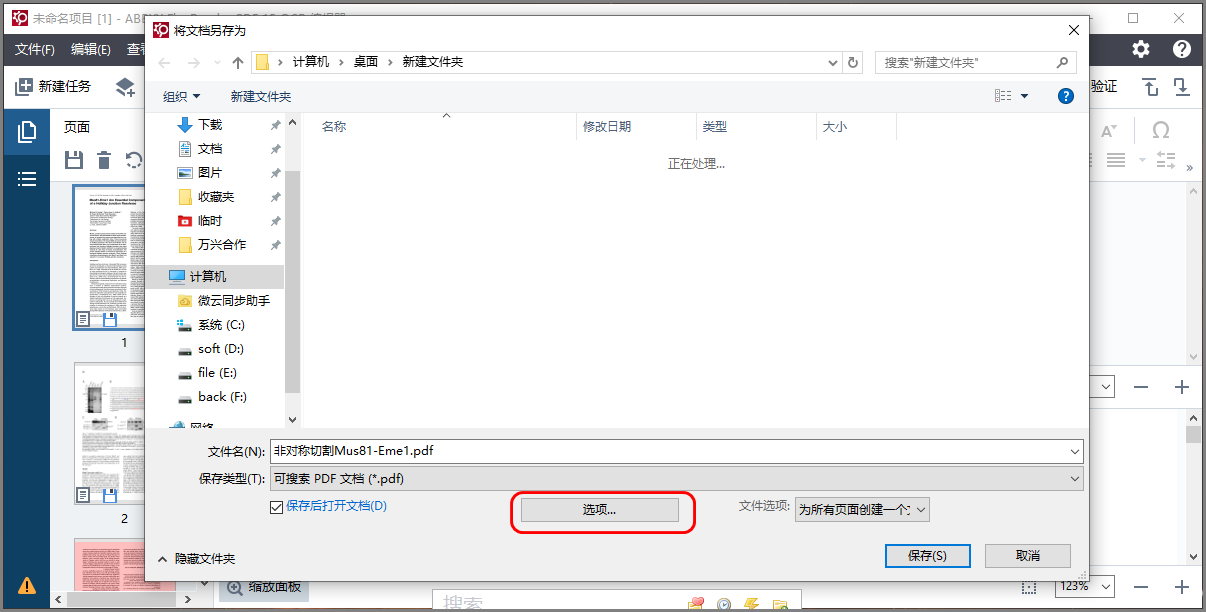
下图是默认(左侧)和设置为“页面图像上方的文本”的对比。下图左侧 pdf文字有毛刺感。右侧文字显示更加圆滑。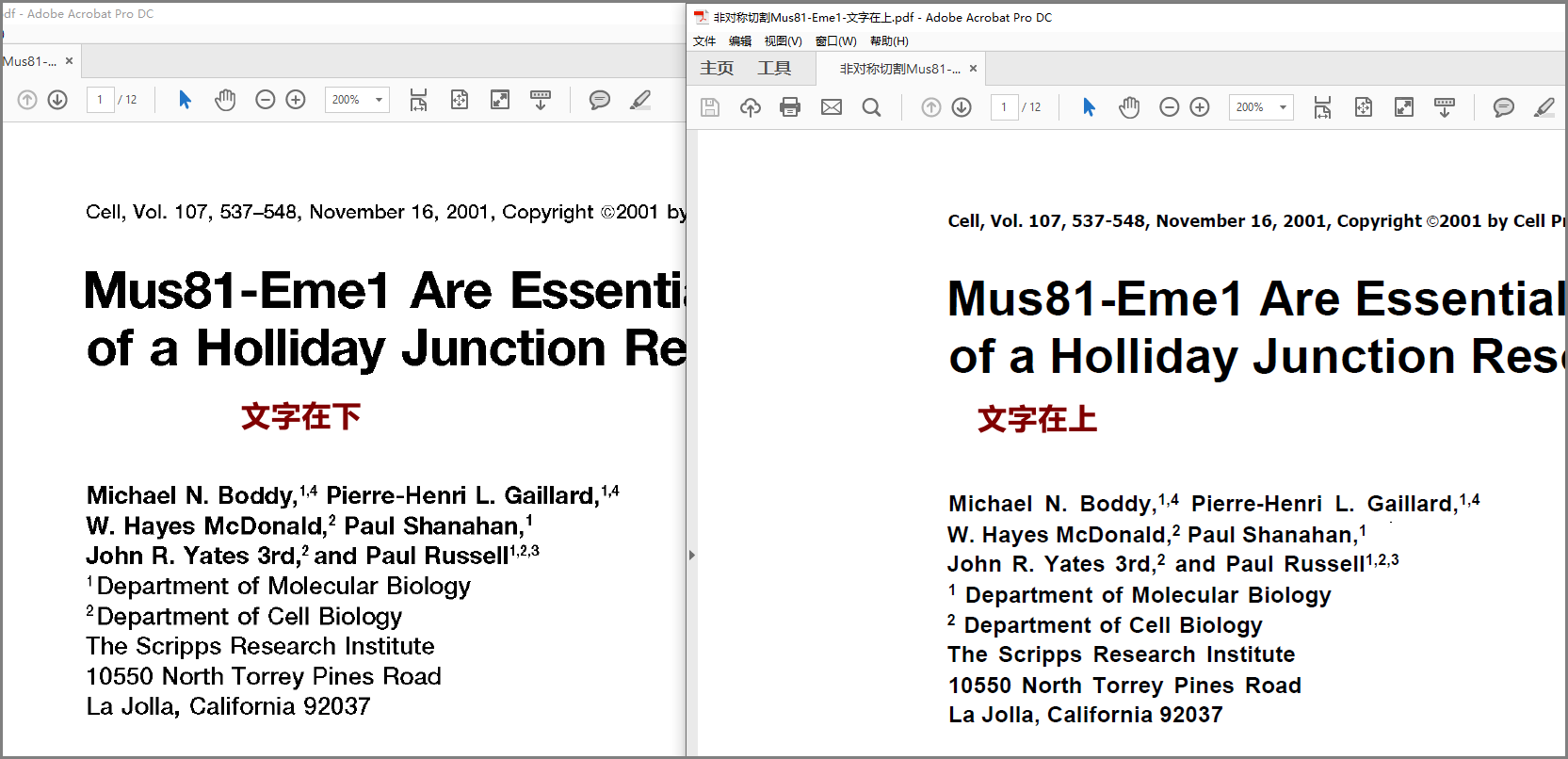
将转换另存的pdf文档用知云文献翻译打开阅读翻译: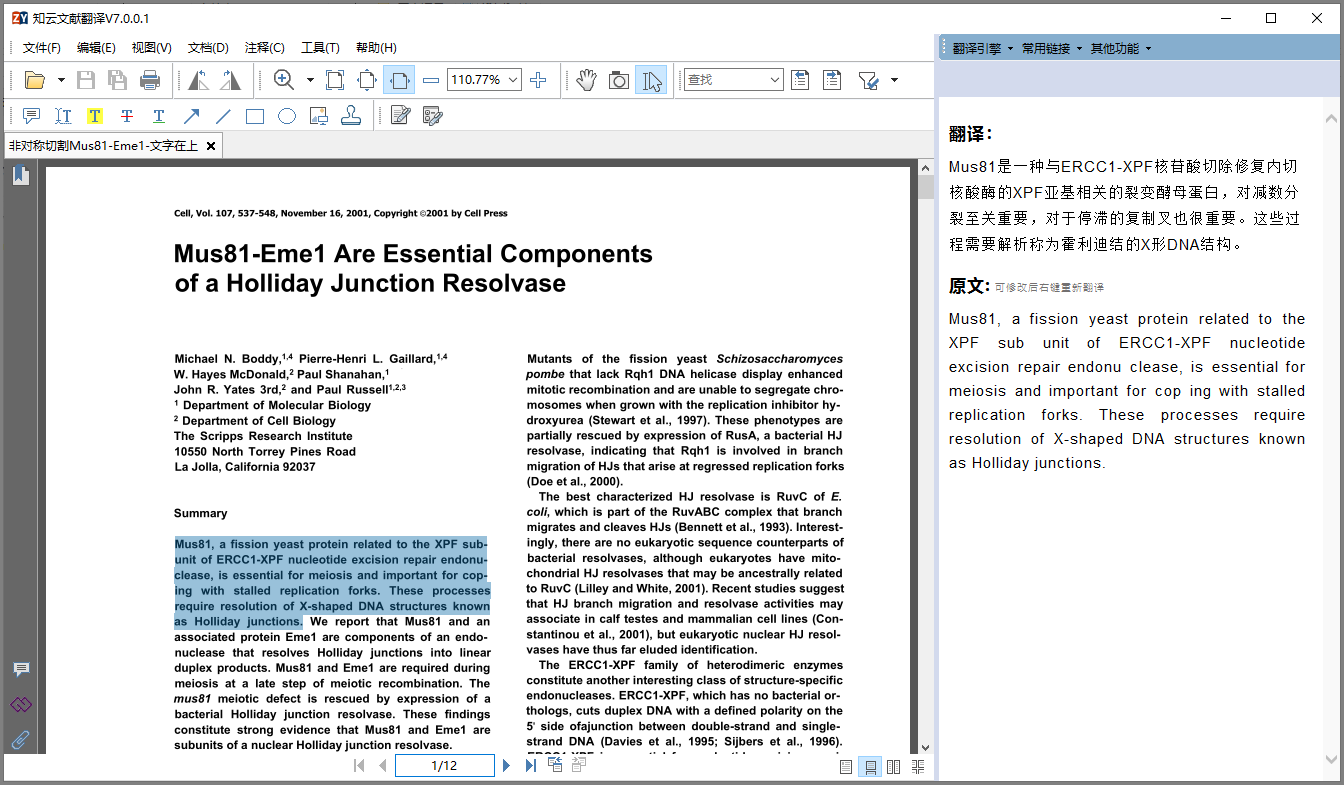
新建软件左上角的“新建任务”,可以开始另外一个pdf文件的OCR转换。

若有收获,就点个赞吧
0 人点赞
