所有非标准编码的pdf均可使用此OCR软件转换。本软件转换英文文档效果很好,转换中文文档效果不佳。
比如下面这个pdf,获取的文本是乱码的导致翻译故障。需要将这个pdf进行ocr转换后再翻译。
打开PDF XChange Editor。
软件左上角打开图标点击打开要转换的pdf文件。然后再“转换”选项卡-“识别页面” ,
这个页面需要注意选择正确的文档语言。这个是英文文档。选中默认的English。下拉中没有中文,如果是中文文档,需要点击右侧 添加/更新语言 下载中文OCR包。
另外请去掉“忽略页面中存在的文本”的勾,如下图那样。
其余按我下图框选的选择。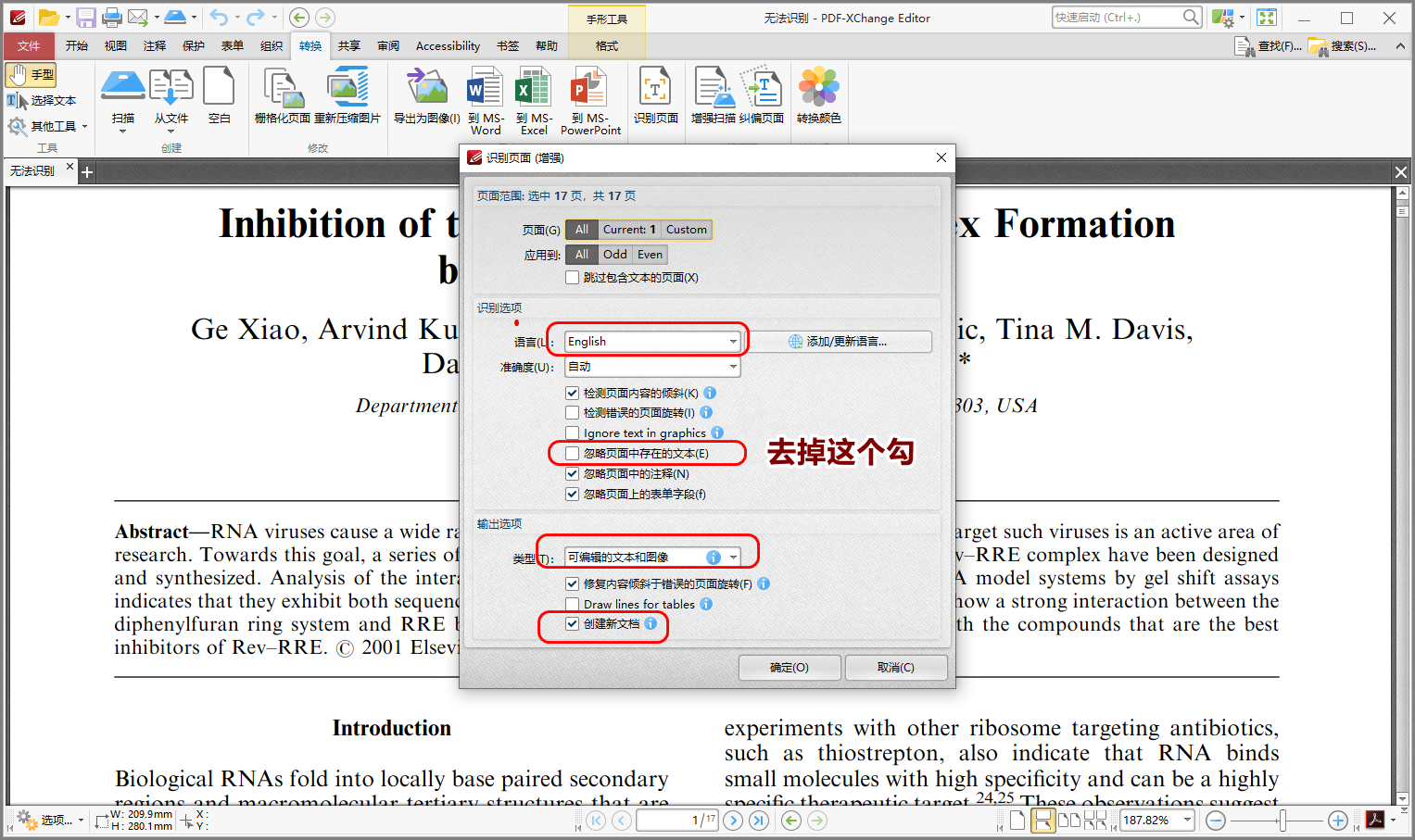
转换好后,点击保存按钮,保存转换好的pdf。
然后用知云文献翻译打开转换好的pdf,看正常了吧。

若有收获,就点个赞吧
0 人点赞
