发展历程
由于篇幅限制,再加上本人对 3A 大作游戏的喜爱,以及一直火热的“挖矿”,所以在此简单介绍一下显卡的发展,对游戏的影响以及对人工智能方面的影响。
GPU 是随着我们开始在计算机里面需要渲染三维图形的出现,而发展起来的设备。图形渲染和设备的先驱,第一个要算是 SGI(Silicon Graphics Inc.)这家公司。SGI 的名字翻译成中文就是“硅谷图形公司”。这家公司从 80 年代起就开发了很多基于 Unix 操作系统的工作站。它的创始人 Jim Clark 是斯坦福的教授,也是图形学的专家。后来,他也是网景公司(Netscape)的创始人之一。而 Netscape,就是那个曾经和 IE 大战 300 回合的浏览器公司,虽然最终败在微软的 Windows 免费捆绑 IE 的策略下,但是也留下了 Firefox 这个完全由开源基金会管理的浏览器。不过这个都是后话了。
到了 90 年代中期,随着个人电脑的性能越来越好,PC 游戏玩家们开始有了“3D 显卡”的需求。那个时代之前的 3D 游戏,其实都是伪 3D。比如,大神卡马克开发的著名 Wolfenstein 3D(德军总部 3D),从不同视角看到的是 8 幅不同的贴图,实际上并不是通过图形学绘制渲染出来的多边形。这样的情况下,游戏玩家的视角旋转个 10 度,看到的画面并没有变化。但是如果转了 45 度,看到的画面就变成了另外一幅图片。而如果我们能实时渲染基于多边形的 3D 画面的话,那么任何一点点的视角变化,都会实时在画面里面体现出来,就好像你在真实世界里面看到的一样。
而在 90 年代中期,随着硬件和技术的进步,我们终于可以在 PC 上用硬件直接实时渲染多边形了。“真 3D”游戏开始登上历史舞台了。“古墓丽影”“最终幻想 7”,这些游戏都是在那个时代诞生的。当时,很多国内的计算机爱好者梦寐以求的,是一块 Voodoo FX 的显卡。
如今各种型号显卡层出不穷,游戏、深度学习等进一步提出了对显卡性能的要求,一台好的主机,配上一块不错的显卡成为了很多热爱游戏的玩家们在经济独立后最先想要的,而对于深度学习的科研人员来说,机器学习,渲染等对显卡的要求更是不在游戏玩家之下。而且由于如今的比特币行情,使得显卡的价格飞涨,一卡难求成为常态。
图形渲染
通过多边形组合显示出 3D 画面而,这些人物在画面里面的移动、动作,乃至根据光线发生的变化,都是通过计算机根据图形学的各种计算,实时渲染出来的。
这个对于图像进行实时渲染的过程,可以被分解成下面这样 5 个步骤(图形流水线 Graphic Pipeline):顶点处理(Vertex Processing)图元处理(Primitive Processing)栅格化(Rasterization)片段处理(Fragment Processing)像素操作(Pixel Operations)
顶点处理:将建模图形在三维空间中的顶点转化为二维平面中的点,在线性代数中介绍过此类处理方法。其实转化后的顶点,仍然是在一个三维空间里,只是第三维的 Z 轴,是正对屏幕的“深度”。
图元处理:将转化到平面中的点连接起来变成多边形,然后进行剔除和裁剪(Cull and Clip),也就是把不在屏幕里面,或者一部分不在屏幕里面的内容给去掉,减少接下来流程的工作量。
栅格化:由于屏幕显示是依靠一个个像素点的,所以这一步是将图元像素化。图元的像素化和顶点处理有相同之处,那就是他们都是可以并行且独立处理的。
片段处理:并行独立的对每个片段上的元素点进行上色。
像素操作:将不同的片段混合在一起,根据图元的透明度,图元的遮盖等对重合部分进行计算处理。
粉末登场
通过上述五个步骤可以见到,想要晚上“真 3D”游戏,对当时的 CPU 来说已经可以占用到 50% - 90%的算力,所以 Voodoo FX 这样的图形显卡登上了历史舞台。
那个时候,整个顶点处理的过程还是都由 CPU 进行的,不过后续所有到图元和像素级别的处理都是通过 Voodoo FX 或者 TNT 这样的显卡去处理的。也就是从这个时代开始,我们能玩上“真 3D”的游戏了。
不过,无论是 Voodoo FX 还是 NVidia TNT。整个显卡的架构还不同于我们现代的显卡,也没有现代显卡去进行各种加速深度学习的能力。这个能力,要到 NVidia 提出 Unified Shader Archicture 才开始具备。
它们是用固定的处理流程来完成整个 3D 图形渲染的过程。因为不用像 CPU 那样考虑计算和处理能力的通用性,可以用比起 CPU 芯片更低的成本,更好地完成 3D 图形的渲染工作,而 3D 游戏的时代也是从这个时候开始的。
扩展阅读:The History of the Modern Graphics Processor
深度学习与 GPU
由于早期显卡不支持顶点处理,所以图形效果依然收到 CPU 性能的限制。所以,1999 年 NVidia 推出的 GeForce 256 显卡,就把顶点处理的计算能力,也从 CPU 里挪到了显卡里。然而整个图形渲染过程都是在硬件里面固定的管线来完成的。程序员只有改配置来实现不同的图形渲染效果。
于是程序员希望 GPU 也能有一定的可编程能力。这个编程能力不是像 CPU 那样,有非常通用的指令,可以进行任何希望的操作,而是在整个的渲染管线(Graphics Pipeline)的一些特别步骤,能够自己去定义处理数据的算法或者操作。于是,从 2001 年的 Direct3D 8.0 开始,微软第一次引入了可编程管线(Programable Function Pipeline)的概念。和片段处理(Fragment Processing)")
这些可以编程的接口,我们称之为 Shader,中文名称就是着色器。之所以叫“着色器”,是因为一开始这些“可编程”的接口,只能修改顶点处理和片段处理部分的程序逻辑。我们用这些接口来做的,也主要是光照、亮度、颜色等等的处理,所以叫着色器。
最开始由于顶点处理相较于片段处理稍加复杂,于是将两种 shader 分开设计使用,但是后来发现,虽然我们在顶点处理和片段处理上的具体逻辑不太一样,但是里面用到的指令集可以用同一套,而且由于分开处理,总会有闲置资源得不到使用,加上 GPU 在当时昂贵的价格等多种因素,统一着色器架构(Unified Shader Architecture)就应运而生了。
统一着色器架构,就在 GPU 里面放很多个一样的 Shader 硬件电路,然后通过统一调度,把顶点处理、图元处理、片段处理这些任务,都交给这些 Shader 去处理,让整个 GPU 尽可能地忙起来。这样的设计,就是现代 GPU 的设计。最先用到这一方式的并不是计算机,而是微软的一台游戏机,微软在技术上的前瞻性,洞察力以及执行力方面确实是一些公司和个人的榜样。
正是因为 Shader 变成一个“通用”的模块,才有了把 GPU 拿来做各种通用计算的用法,也就是 GPGPU(General-Purpose Computing on Graphics Processing Units,通用图形处理器)。而正是因为 GPU 可以拿来做各种通用的计算,才有了过去 10 年深度学习的火热。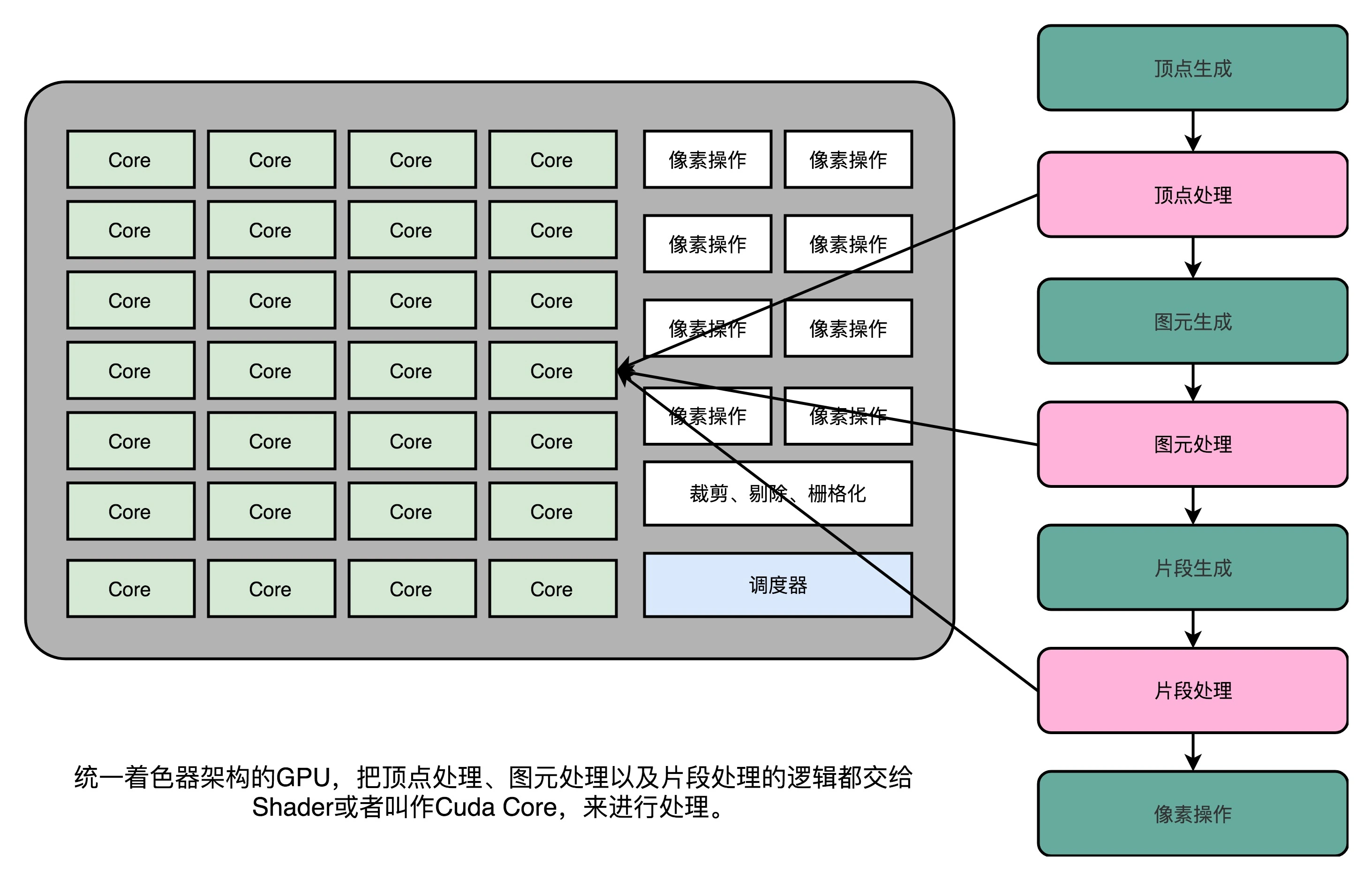
芯片瘦身,多核并行和 SIMT
GPU 的整个处理过程是一个流式处理(Stream Processing)的过程。因为没有那么多分支条件,或者复杂的依赖关系,对其进行简化只留下取指令、指令译码、ALU 以及执行这些计算需要的寄存器和缓存就好了。一般这些电路抽象成三个部分,即:取指令和指令译码、ALU 和执行上下文。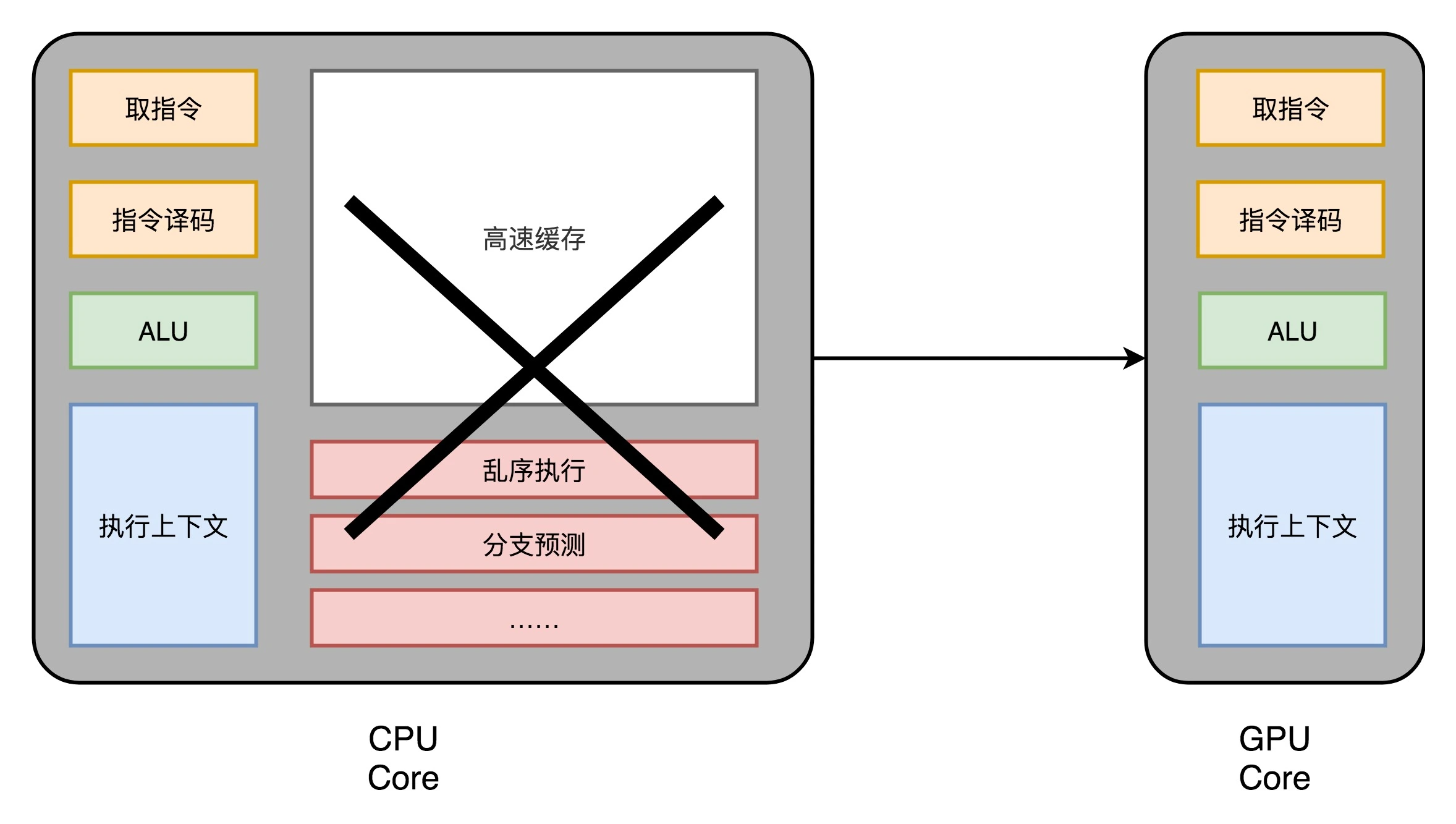
相较于 CPU ,GPU 运算天然并行,所以我们可以在一个 GPU 中加入塞入多个这样的计算单元实现多核并行。已知无论是对多边形里的顶点进行处理,还是屏幕里面的每一个像素进行处理,每个点的计算都是独立的。所以,简单地添加多核的 GPU,就能做到并行加速。为进一步提高性能,工程师将此与 CPU 中的 SIMD 联系起来,提出了更加灵活的 SIMT。在 SIMD 里面,CPU 一次性取出了固定长度的多个数据,放到寄存器里面,用一个指令去执行。而 SIMT,可以把多条数据,交给不同的线程去处理。
各个线程在相同流程的情况下,可能会因为数据不同,走到不同的分支,由此 GPU 设计进一步进化,也就是在取指令和指令译码的阶段,取出的指令可以给到后面多个不同的 ALU 并行进行运算。这样,一个 GPU 的核里,就可以放下更多的 ALU,同时进行更多的并行运算。
在通过芯片瘦身、SIMT 以及更多的执行上下文之后,GPU 更擅长并行进行暴力运算的。这样的芯片,正适合深度学习的使用场景。一方面,GPU 是一个可以进行“通用计算”的框架,我们可以通过编程,在 GPU 上实现不同的算法。另一方面,现在的深度学习计算,都是超大的向量和矩阵,海量的训练样本的计算。整个计算过程中,没有复杂的逻辑和分支,非常适合 GPU 这样并行、计算能力强的架构。
深度学习中的优势
这里借助 2080 显卡来展示 CPU 和 GPU 在图形处理方面的差别:
2080 一共有 46 个 SM(Streaming Multiprocessor,流式处理器),这个 SM 相当于 GPU 里面的 GPU Core,所以你可以认为这是一个 46 核的 GPU,有 46 个取指令指令译码的渲染管线。每个 SM 里面有 64 个 Cuda Core。你可以认为,这里的 Cuda Core 就是我们上面说的 ALU 的数量或者 Pixel Shader 的数量,46x64 呢一共就有 2944 个 Shader。然后,还有 184 个 TMU,TMU 就是 Texture Mapping Unit,也就是用来做纹理映射的计算单元,它也可以认为是另一种类型的 Shader。
2080 的主频是 1515MHz,如果自动超频(Boost)的话,可以到 1700MHz。而 NVidia 的显卡,根据硬件架构的设计,每个时钟周期可以执行两条指令。所以,能做的浮点数运算的能力,就是:(2944 + 184)× 1700 MHz × 2 = 10.06 TFLOPS对照一下官方的技术规格,正好就是 10.07TFLOPS
相比之下,最新的 Intel i9 9900K 的性能不到 1TFLOPS。而 2080 显卡和 9900K 的价格却是差不多的。所以,在实际进行深度学习的过程中,用 GPU 所花费的时间,往往能减少一到两个数量级。而大型的深度学习模型计算,往往又是多卡并行,要花上几天乃至几个月。这个时候,用 CPU 显然就不合适了。
如今,随着 GPGPU 的推出,GPU 已经不只是一个图形计算设备,更是一个用来做数值计算的好工具了。同样,也是因为 GPU 的快速发展,带来了过去 10 年深度学习的繁荣。
不过由于 20 年左右“挖矿”火爆,30 系显卡多被矿老板收走,导致一卡难求,很多高性能显卡售价常年都在定价的两倍左右,但是 22 年初,由于政策对“挖矿”的一系列限制,以及比特币的一些变化,挖矿逐渐不再有高回报,显卡价格逐渐降低,但市场上流动的大量矿卡,又使得玩家们在购买时心生顾虑。22 年或退出 40系显卡,拥有更高的性能已经更高的功耗,至于效果如何,还是拭目以待。

若有收获,就点个赞吧
0 人点赞
