为什么需要程序栈
#include <stdio.h>int static add(int a, int b){return a+b;}int main(){int x = 5;int y = 10;int u = add(x, y);}int static add(int a, int b){0: f3 0f 1e fa endbr644: 55 push rbp5: 48 89 e5 mov rbp,rsp8: 89 7d fc mov DWORD PTR [rbp-0x4],edib: 89 75 f8 mov DWORD PTR [rbp-0x8],esireturn a + b;e: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]11: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]14: 01 d0 add eax,edx}16: 5d pop rbp17: c3 ret0000000000000018 <main>:int main(){18: f3 0f 1e fa endbr641c: 55 push rbp1d: 48 89 e5 mov rbp,rsp20: 48 83 ec 10 sub rsp,0x10int x = 5;24: c7 45 f4 05 00 00 00 mov DWORD PTR [rbp-0xc],0x5int y = 10;2b: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xaint u = add(x,y);32: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]35: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc]38: 89 d6 mov esi,edx3a: 89 c7 mov edi,eax3c: e8 bf ff ff ff call 0 <add>41: 89 45 fc mov DWORD PTR [rbp-0x4],eax44: b8 00 00 00 00 mov eax,0x0}49: c9 leave4a: c3 ret
add 函数编译之后,代码先执行了一条 push 指令和一条 mov 指令;在函数执行结束的时候,又执行了一条 pop 和一条 ret 指令。这四条指令的执行,其实就是在进行压栈(Push)和出栈(Pop)操作。
函数调用和 if…else 和 for/while 循环类似。它们两个都是在原来顺序执行的指令过程里,执行了一个内存地址的跳转指令,让指令从原来顺序执行的过程里跳开,从新的跳转后的位置开始执行。
区别在于 if…else 和 for/while 跳转之后便不在回来,就在跳转之后的新地址开始顺序执行指令。而函数调用的跳转,在对应的指令执行完成之后还要在跳转回来,继续执行 call 之后的指令。
为了记录跳转回来的地址,在内存中开辟了一段内存空间,使用栈这个后入先出(LIFO)的数据结构,每次调用函数之前,将返回值地址记录到栈中,叫做压栈,函数执行完场之后,从栈中清除该数据,这就是出栈。
在真实的程序里,压栈的不只有函数调用完成后的返回地址。比如函数 A 在调用 B 的时候,需要传输一些参数数据,这些参数数据在寄存器不够用的时候也会被压入栈中。整个函数 A 所占用的所有内存空间,就是函数 A 的栈帧(Stack Frame)。
注意栈底在上,栈顶在下,一层层压栈之后,栈顶的内存地址在逐渐变小而不是变大。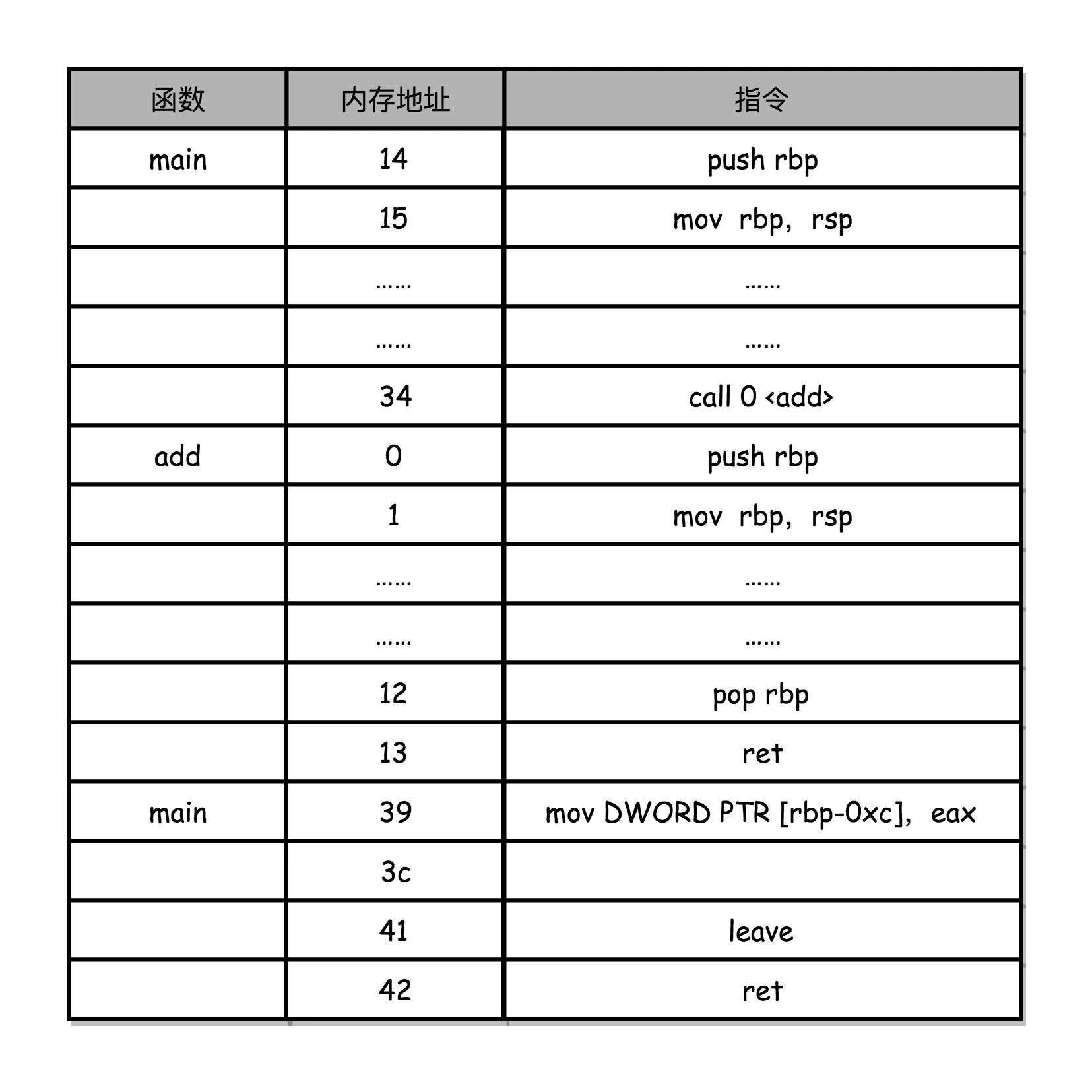
图中,rbp 是 register base pointer 栈基址寄存器(栈帧指针),指向当前栈帧的栈底地址。rsp 是 register stack pointer 栈顶寄存器(栈指针),指向栈顶元素。
对应上面函数 add 的汇编代码,我们来仔细看看,main 函数调用 add 函数时,add 函数入口在 0~1 行,add 函数结束之后在 12~13 行。
我们在调用第 34 行的 call 指令时,会把当前的 PC 寄存器里的下一条指令的地址压栈,保留函数调用结束后要执行的指令地址。而 add 函数的第 0 行,push rbp 这个指令,就是在进行压栈。这里的 rbp 又叫栈帧指针(Frame Pointer),是一个存放了当前栈帧位置的寄存器。push rbp 就把之前调用函数,也就是 main 函数的栈帧的栈底地址,压到栈顶。
接着,第 1 行的一条命令 mov rbp, rsp 里,则是把 rsp 这个栈指针(Stack Pointer)的值复制到 rbp 里,而 rsp 始终会指向栈顶。这个命令意味着,rbp 这个栈帧指针指向的地址,变成当前最新的栈顶,也就是 add 函数的栈帧的栈底地址了。
而在函数 add 执行完成之后,又会分别调用第 12 行的 pop rbp 来将当前的栈顶出栈,这部分操作维护好了我们整个栈帧。然后,我们可以调用第 13 行的 ret 指令,这时候同时要把 call 调用的时候压入的 PC 寄存器里的下一条指令出栈,更新到 PC 寄存器中,将程序的控制权返回到出栈后的栈顶。
注意:函数调用call指令时,(PC)指令地址寄存器会自动压栈,即返回地址压栈,函数返回ret指令时会自动弹栈,即返回地址赋值给PC寄存器
实现 stack overflow
栈的大小也是有限的。如果函数调用层数太多,往栈里压入它存不下的内容,程序在执行的过程中就会遇到栈溢出的错误,这就是大名鼎鼎的“stack overflow”。
int a()
{
return a();
}
int main()
{
a();
return 0;
}
除了无限递归,递归层数过深,在栈空间里面创建非常占内存的变量(比如一个巨大的数组),这些情况都很可能给你带来 stack overflow。
利用函数内联进行性能优化
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
srand(time(NULL));
int x = rand() % 5
int y = rand() % 10;
int u = add(x, y)
printf("u = %d\n", u)
}
$ gcc -g -c -O function_example_inline.c
$ objdump -d -M intel -S function_example_inline.o
return a + b;
5b: 01 da add edx,ebx
在汇编代码,并没有把 add 函数单独编译成一段指令顺序,而是在调用 u = add(x, y) 的时候,直接替换成了一个 add 指令。
内联带来的优化是,CPU 需要执行的指令数变少了,根据地址跳转的过程不需要了,压栈和出栈的过程也不用了。
不过内联并不是没有代价,内联意味着,我们把可以复用的程序指令在调用它的地方完全展开了。如果一个函数在很多地方都被调用了,那么就会展开很多次,整个程序占用的空间就会变大了。
总结延伸
通过加入了程序栈,我们相当于在指令跳转的过程种,加入了一个“记忆”的功能,能在跳转去运行新的指令之后,再回到跳出去的位置,能够实现更加丰富和灵活的指令执行流程。这个也为我们在程序开发的过程中,提供了“函数”这样一个抽象,使得我们在软件开发的过程中,可以复用代码和指令,而不是只能简单粗暴地复制、粘贴代码和指令。
博客园,详细介绍栈作用。

若有收获,就点个赞吧
0 人点赞
