万物在计算机眼中都是 0 和 1,本文将介绍二进制代表各种数据的方式。重点介绍文本字符串和二进制编码的关系,理解并解决乱码问题。
二进制计算方式
这里只强调十进制转二进制,注意最终结果与余数顺序的关系。
补码:首先是解决了 0 有两种原码表示方式,另外是便于计算,结合反码实现加法电路复用。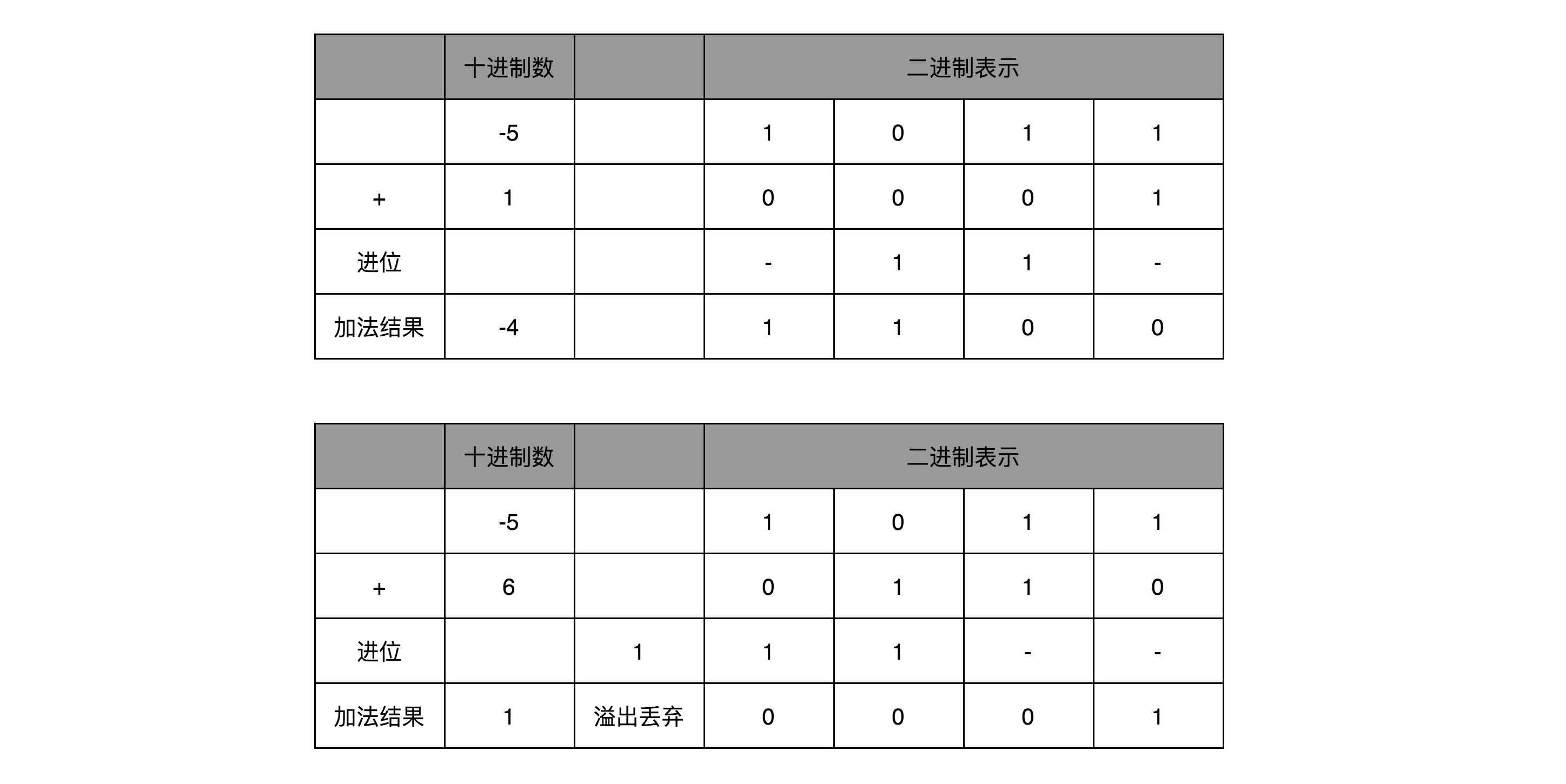
字符串表示
ASCII 码(American Standard Code for Information Interchange,美国信息交换标准代码)。使用八位二进制即一字节,表示英文字符和一些特殊的标点符号。对于数值来说,使用二进制序列话比文本存储要节省内存空间。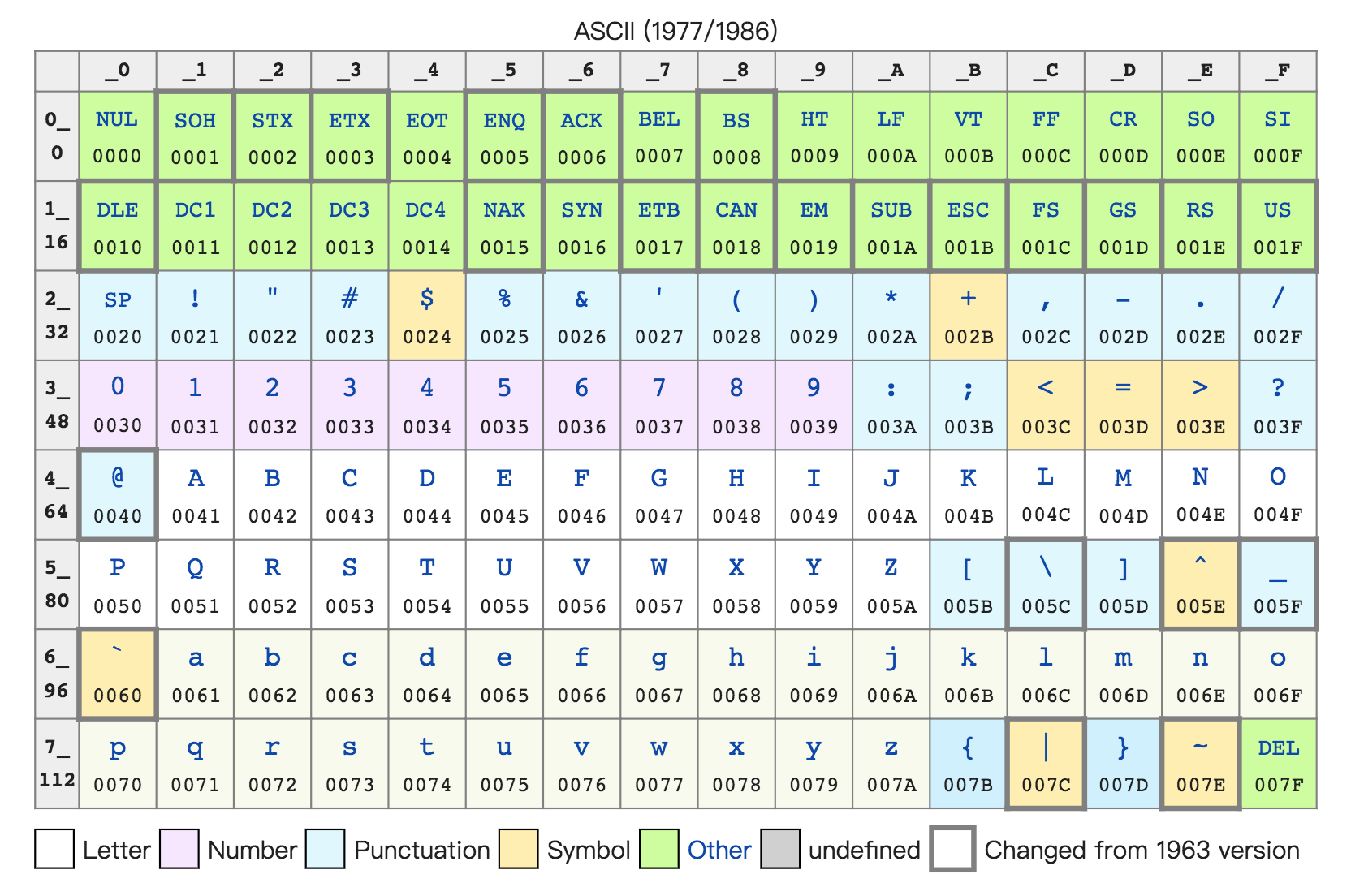
为扩展计算机可表示字符的范围,计算机工程师创建各种字符集和字符编码。前者确定字符范围,后者确定字符与二进制表示的对应方式。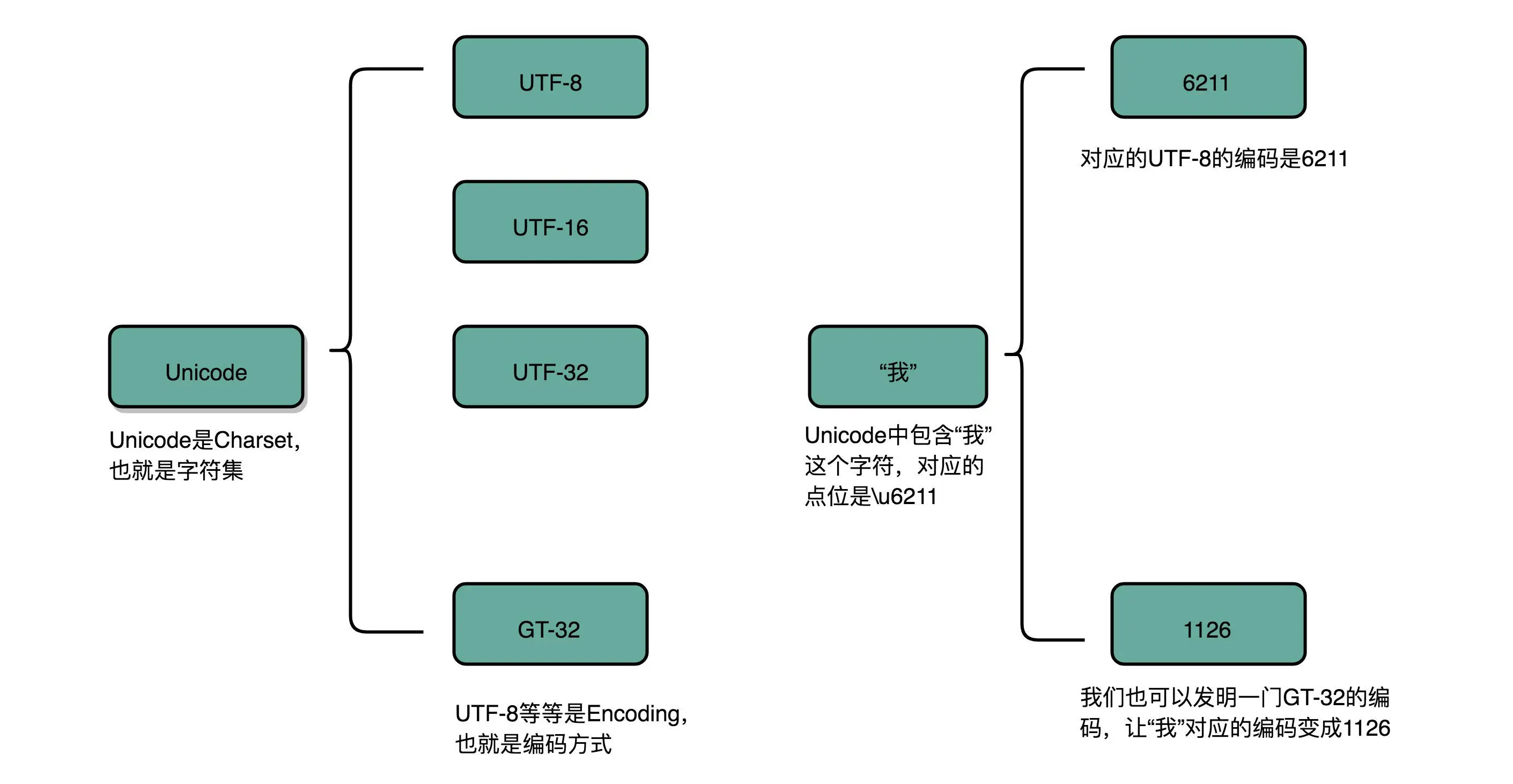
乱码:同样的文本,采用不同的编码存储下来。而另外一个程序,用一种不同的编码方式来进行解码和展示,这是就会出现乱码。
经典案例:“手持两把锟斤拷,口中疾呼烫烫烫”。
首先,“锟斤拷”的来源是这样的。如果我们想要用 Unicode 编码记录一些文本,特别是一些遗留的老字符集内的文本,但是这些字符在 Unicode 中可能并不存在。于是,Unicode 会统一把这些字符记录为 U+FFFD 这个编码。如果用 UTF-8 的格式存储下来,就是\xef\xbf\xbd。如果连续两个这样的字符放在一起,\xef\xbf\xbd\xef\xbf\xbd,这个时候,如果程序把这个字符,用 GB2312 的方式进行 decode,就会变成“锟斤拷”。这就好比我们用 GB2312 这本密码本,去解密别人用 UTF-8 加密的信息,自然没办法读出有用的信息。
而“烫烫烫”,则是因为如果你用了 Visual Studio 的调试器,默认使用 MBCS 字符集。“烫”在里面是由 0xCCCC 来表示的,而 0xCC 又恰好是未初始化的内存的赋值。于是,在读到没有赋值的内存地址或者变量的时候,电脑就开始大叫“烫烫烫”了。
总结延伸

若有收获,就点个赞吧
0 人点赞
