示例
int[] arr = new int[64 * 1024 * 1024];// 循环1for (int i = 0; i < arr.length; i++) arr[i] *= 3;// 循环2for (int i = 0; i < arr.length; i += 16) arr[i] *= 3
按道理来说,循环 2 只访问循环 1 中 1/16 的数组元素,只进行了循环 1 中 1/16 的乘法计算,那循环 2 花费的时间应该是循环 1 的 1/16 左右。但是实际上,循环 1 在我的电脑上运行需要 50 毫秒,循环 2 只需要 46 毫秒。这两个循环花费时间之差在 15% 之内。
这 15% 的差异,正和接下来要介绍的 CPU Cache 有关。
为什么需要高速缓存
CPU 的访问速度远高于内存的访问速度,且两者的增长速度也相差很多,这使得 CPU 的性能和内存访问的性能的差距不断拉大,到今天来看,一次内存的访问,大约需要 120 个 CPU Cycle,这也意味着,在今天,CPU 和内存的访问速度已经有了 120 倍的差距。
为了弥补两者之间的性能差异,我们能真实地把 CPU 的性能提升用起来,而不是让它在那儿空转,我们在现代 CPU 中引入了高速缓存。
从 CPU Cache 被加入到现有的 CPU 里开始,内存中的指令、数据,会被加载到 L1-L3 Cache 中,而不是直接由 CPU 访问内存去拿。在 95% 的情况下,CPU 都只需要访问 L1-L3 Cache,从里面读取指令和数据,而无需访问内存。
要注意的是,这里我们说的 CPU Cache 或者 L1/L3 Cache,不是一个单纯的、概念上的缓存(比如之前我们说的拿内存作为硬盘的缓存),而是指特定的由 SRAM 组成的物理芯片。
在这一讲一开始的程序里,运行程序的时间主要花在了将对应的数据从内存中读取出来,加载到 CPU Cache 里。CPU 从内存中读取数据到 CPU Cache 的过程中,是一小块一小块来读取数据的,而不是按照单个数组元素来读取数据的。这样一小块一小块的数据,在 CPU Cache 里面,我们把它叫作 Cache Line/Block(缓存块)。
在我们日常使用的 Intel 服务器或者 PC 里,Cache Line 的大小通常是 64 字节。而在上面的循环 2 里面,我们每隔 16 个整型数计算一次,16 个整型数正好是 64 个字节。于是,循环 1 和循环 2,需要把同样数量的 Cache Line 数据从内存中读取到 CPU Cache 中,最终两个程序花费的时间就差别不大了。
Cache 的数据结构和读取过程
现代 CPU 进行数据读取的时候,无论数据是否已经存储在 Cache 中,CPU 始终会首先访问 Cache。只有当 CPU 在 Cache 中找不到数据的时候,才会去访问内存,并将读取到的数据写入 Cache 之中。当时间局部性原理起作用后,这个最近刚刚被访问的数据,会很快再次被访问。而 Cache 的访问速度远远快于内存,这样,CPU 花在等待内存访问上的时间就大大变短了。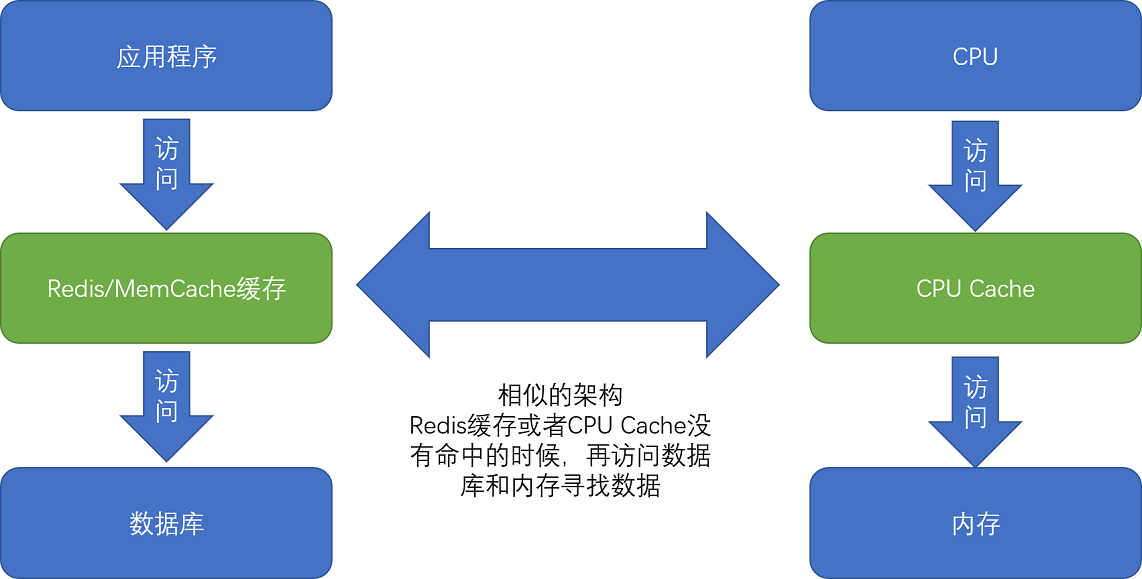
已知 CPU 访问内存数据,是一小块一小块数据来读取的。对于读取内存中的数据,我们首先拿到的是数据所在的内存块(Block)的地址。而直接映射 Cache 采用的策略,就是确保任何一个内存块的地址,始终映射到一个固定的 CPU Cache 地址(Cache Line/Block)。而这个映射关系,通常用 mod 运算(求余运算)来实现。
比如说,我们的主内存被分成 0~31 号这样 32 个块。我们一共有 8 个缓存块。用户想要访问第 21 号内存块。如果 21 号内存块内容在缓存块中的话,它一定在 5 号缓存块(21 mod 8 = 5)中。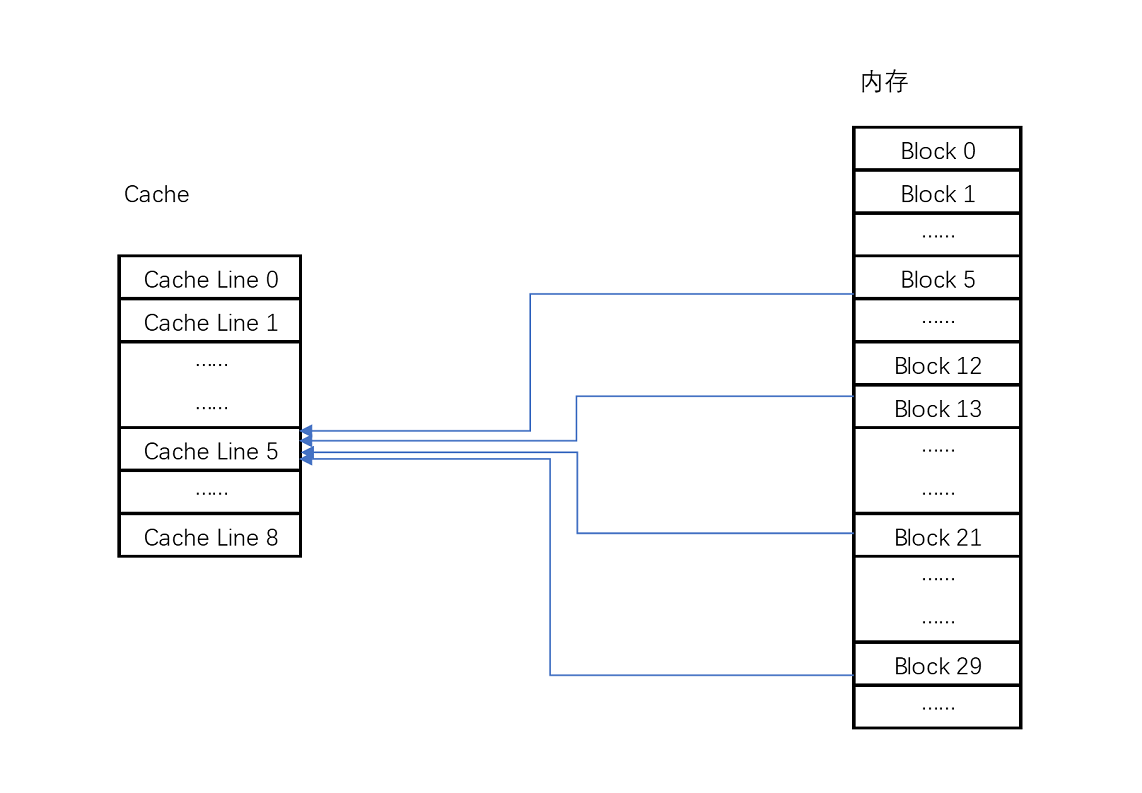
实际计算中,有一个小小的技巧,通常我们会把缓存块的数量设置成 2 的 N 次方。这样在计算取模的时候,可以直接取地址的低 N 位,也就是二进制里面的后几位。比如这里的 8 个缓存块,就是 2 的 3 次方。那么,在对 21 取模的时候,可以对 21 的 2 进制表示 10101 取地址的低三位,也就是 101,对应的 5,就是对应的缓存块地址。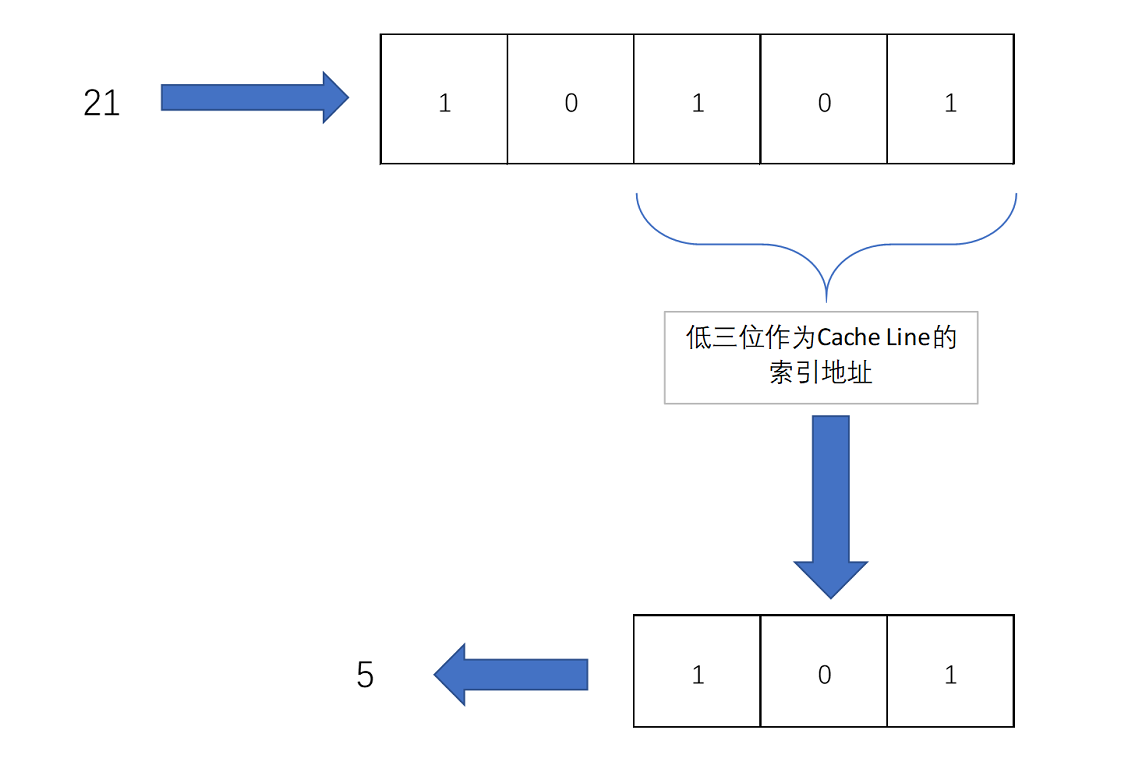
取 Block 地址的低位,就能得到对应的 Cache Line 地址,除了 21 号内存块外,13 号、5 号等很多内存块的数据,都对应着 5 号缓存块中。既然如此,假如现在 CPU 想要读取 21 号内存块,在读取到 5 号缓存块的时候,我们怎么知道里面的数据,究竟是不是 21 号对应的数据呢?
这个时候,在对应的缓存块中,我们会存储一个组标记(Tag)。这个组标记会记录,当前缓存块内存储的数据对应的内存块,而缓存块本身的地址表示访问地址的低 N 位。就像上面的例子,21 的低 3 位 101,缓存块本身的地址已经涵盖了对应的信息、对应的组标记,我们只需要记录 21 剩余的高 2 位的信息,也就是 10 就可以了。
除了组标记信息之外,缓存块中还有两个数据。一个是从主内存中加载来的实际存放的数据,另一个是有效位(valid bit)。所谓有效位就是用来标记对应的缓存块中的数据是否是有效的,如果有效位是 0,无论其中的组标记和 Cache Line 里的数据内容是什么,CPU 都不会管这些数据,而要直接访问内存,重新加载数据。
CPU 在读取数据的时候,并不是要读取一整个 Block,而是读取一个他需要的数据片段。这样的数据,我们叫作 CPU 里的一个字(Word)。具体是哪个字,就用这个字在整个 Block 里面的位置来决定。这个位置,我们叫作偏移量(Offset)。
总结一下,一个内存的访问地址,最终包括高位代表的组标记、低位代表的索引,以及在对应的 Data Block 中定位对应字的位置偏移量。
如果内存中的数据已经在 CPU Cache 里了,那一个内存地址的访问,就会经历这样 4 个步骤:
根据内存地址的低位,计算在 Cache 中的索引;
判断有效位,确认 Cache 中的数据是有效的;
对比内存访问地址的高位,和 Cache 中的组标记,确认 Cache 中的数据就是我们要访问的内存数据,从 Cache Line 中读取到对应的数据块(Data Block);
根据内存地址的 Offset 位,从 Data Block 中,读取希望读取到的字。
如果在 2、3 这两个步骤中,CPU 发现,Cache 中的数据并不是要访问的内存地址的数据,那 CPU 就会访问内存,并把对应的 Block Data 更新到 Cache Line 中,同时更新对应的有效位和组标记的数据。
“隐身的”变量
public class VolatileTest {private static volatile int COUNTER = 0;public static void main(String[] args) {new ChangeListener().start();new ChangeMaker().start();}static class ChangeListener extends Thread {@Overridepublic void run() {int threadValue = COUNTER;while ( threadValue < 5){if( threadValue!= COUNTER){System.out.println("Got Change for COUNTER : " + COUNTER + "");threadValue= COUNTER;}}}}static class ChangeMaker extends Thread{@Overridepublic void run() {int threadValue = COUNTER;while (COUNTER <5){System.out.println("Incrementing COUNTER to : " + (threadValue+1) + "");COUNTER = ++threadValue;try {Thread.sleep(500);} catch (InterruptedException e) { e.printStackTrace(); }}}}}
在这个程序里,我们先定义了一个 volatile 的 int 类型的变量,COUNTER。然后,我们分别启动了两个单独的线程,一个线程我们叫 ChangeListener。另一个线程,我们叫 ChangeMaker。
ChangeListener 这个线程运行的任务很简单。它先取到 COUNTER 当前的值,然后一直监听着这个 COUNTER 的值。一旦 COUNTER 的值发生了变化,就把新的值通过 println 打印出来。直到 COUNTER 的值达到 5 为止。这个监听的过程,通过一个永不停歇的 while 循环的忙等待来实现。
ChangeMaker 这个线程运行的任务同样很简单。它同样是取到 COUNTER 的值,在 COUNTER 小于 5 的时候,每隔 500 毫秒,就让 COUNTER 自增 1。在自增之前,通过 println 方法把自增后的值打印出来。最后,在 main 函数里,我们分别启动这两个线程,来看一看这个程序的执行情况。
程序的输出结果并不让人意外。ChangeMaker 函数会一次一次将 COUNTER 从 0 增加到 5。因为这个自增是每 500 毫秒一次,而 ChangeListener 去监听 COUNTER 是忙等待的,所以每一次自增都会被 ChangeListener 监听到,然后对应的结果就会被打印出来。
Incrementing COUNTER to : 1Got Change for COUNTER : 1Incrementing COUNTER to : 2Got Change for COUNTER : 2Incrementing COUNTER to : 3Got Change for COUNTER : 3Incrementing COUNTER to : 4Got Change for COUNTER : 4Incrementing COUNTER to : 5Got Change for COUNTER : 5
这个时候如果去掉第二行中的 volatile 关键字:
private static int COUNTER = 0;
ChangeMaker 还是能正常工作的,每隔 500ms 仍然能够对 COUNTER 自增 1。但是 ChangeListener 不再工作了。在 ChangeListener 眼里,它似乎一直觉得 COUNTER 的值还是一开始的 0。似乎 COUNTER 的变化,对于我们的 ChangeListener 彻底“隐身”了。
Incrementing COUNTER to : 1
Incrementing COUNTER to : 2
Incrementing COUNTER to : 3
Incrementing COUNTER to : 4
Incrementing COUNTER to : 5
接下来不再让 ChangeListener 进行完全的忙等待,而是在 while 循环里面等待上 5 毫秒:
static class ChangeListener extends Thread {
@Override
public void run() {
int threadValue = COUNTER;
while ( threadValue < 5){
if( threadValue!= COUNTER){
System.out.println("Sleep 5ms, Got Change for COUNTER : " + COUNTER + "");
threadValue= COUNTER;
}
try {
Thread.sleep(5);
} catch (InterruptedException e) { e.printStackTrace(); }
}
}
}
Incrementing COUNTER to : 1
Sleep 5ms, Got Change for COUNTER : 1
Incrementing COUNTER to : 2
Sleep 5ms, Got Change for COUNTER : 2
Incrementing COUNTER to : 3
Sleep 5ms, Got Change for COUNTER : 3
Incrementing COUNTER to : 4
Sleep 5ms, Got Change for COUNTER : 4
Incrementing COUNTER to : 5
Sleep 5ms, Got Change for COUNTER : 5
volatile 的作用如下:它会确保我们对于这个变量的读取和写入,都一定会同步到主内存里,而不是从 Cache 里面读取。
第一个使用了 volatile 关键字的例子里,因为所有数据的读和写都来自主内存。那么自然地,我们的 ChangeMaker 和 ChangeListener 之间,看到的 COUNTER 值就是一样的。
第二段去掉了 volatile 关键字。这个时候,ChangeListener 又是一个忙等待的循环,它尝试不停地获取 COUNTER 的值,这样就会从当前线程的“Cache”里面获取。于是,这个线程就没有时间从主内存里面同步更新后的 COUNTER 值。这样,它就一直卡死在 COUNTER=0 的死循环上了。
第三段代码里面,虽然还是没有使用 volatile 关键字,但是短短 5ms 的 Thead.Sleep 给了这个线程喘息之机。既然这个线程没有这么忙了,它也就有机会把最新的数据从主内存同步到自己的高速缓存里面了。于是,ChangeListener 在下一次查看 COUNTER 值的时候,就能看到 ChangeMaker 造成的变化了。
虽然 Java 内存模型是一个隔离了硬件实现的虚拟机内的抽象模型,但是它给了我们一个很好的“缓存同步”问题的示例。也就是说,如果我们的数据,在不同的线程或者 CPU 核里面去更新,因为不同的线程或 CPU 核有着自己各自的缓存,很有可能在 A 线程的更新,到 B 线程里面是看不见的。
CPU 高速缓存的写入
现在用的 Intel CPU,通常都是多核的的。每一个 CPU 核里面,都有独立属于自己的 L1、L2 的 Cache,然后再有多个 CPU 核共用的 L3 的 Cache、主内存。
因为 CPU Cache 的访问速度要比主内存快很多,而在 CPU Cache 里面,L1/L2 的 Cache 也要比 L3 的 Cache 快。所以,CPU 始终都是尽可能地从 CPU Cache 中去获取数据,而不是每一次都要从主内存里面去读取数据。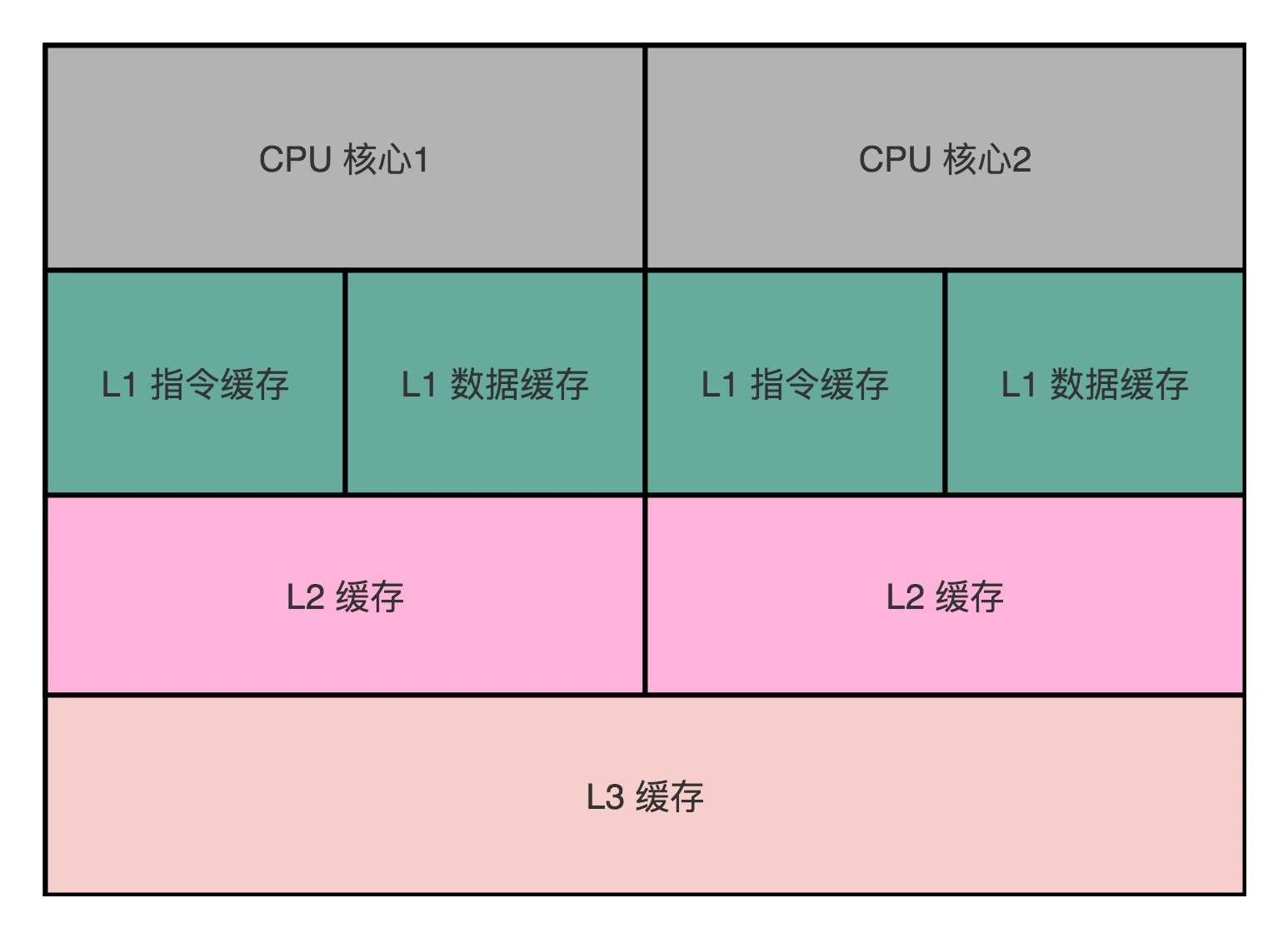
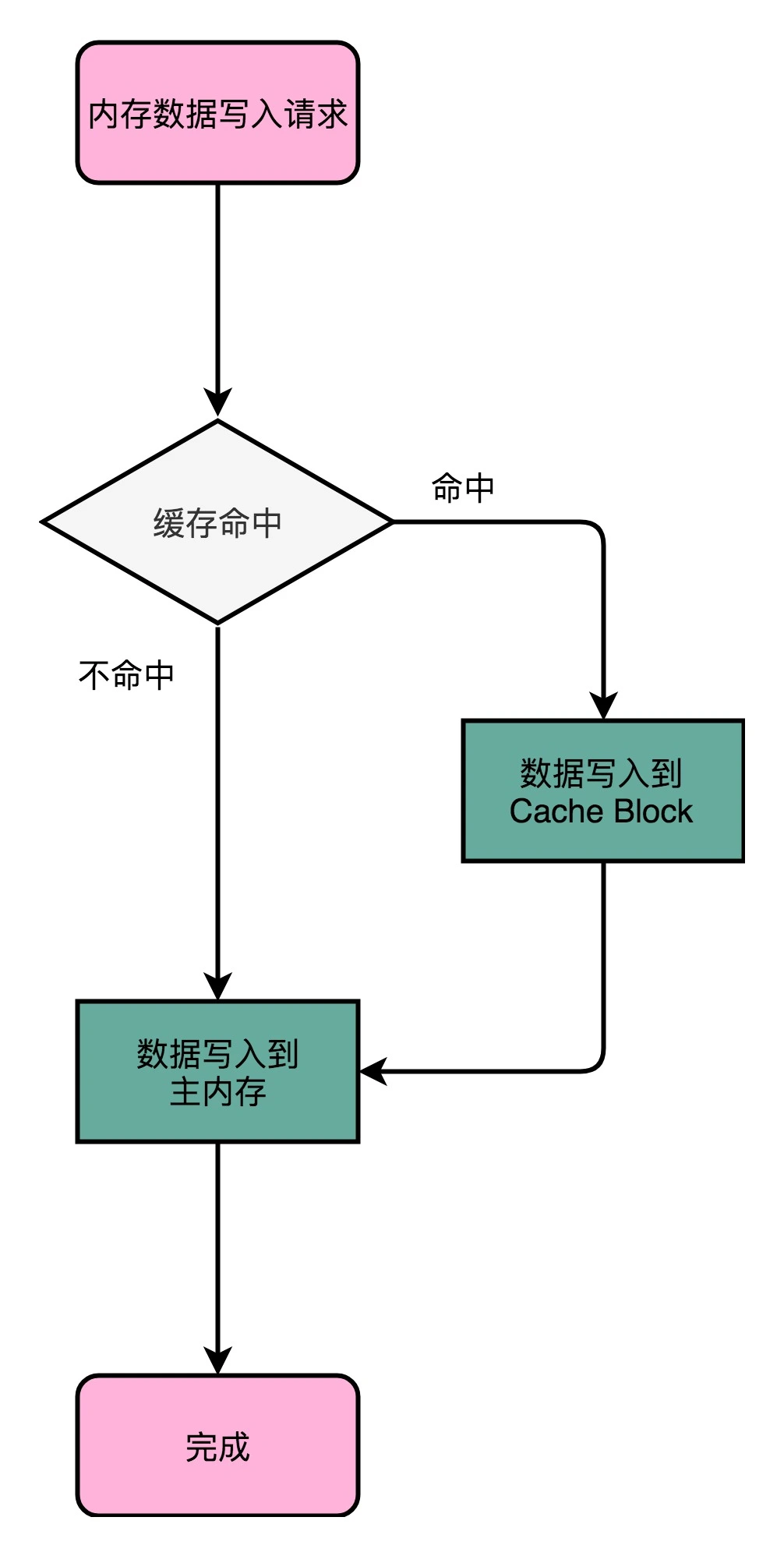
当数据既要读,又要对其进行修改时,就会出现两个问题:首先:写入 Cache 的性能比写入内存要快,那么写入的数据是写到 Cache 还是主存里呢,如果直接写到主内存中,Cache 里的数据是否会失效?其次,就是多个线程或者多个 CPU 核的缓存一致性问题如何解决?
写直达(Write-Through)
首先判断数据是否在缓存中,如果在的话,要先修改缓存中的数据,该方式最终都会将数据写到主内存中。
优点:直观统一;缺点:速度慢;类似上文中的 volatile。
写回(Write-Back)
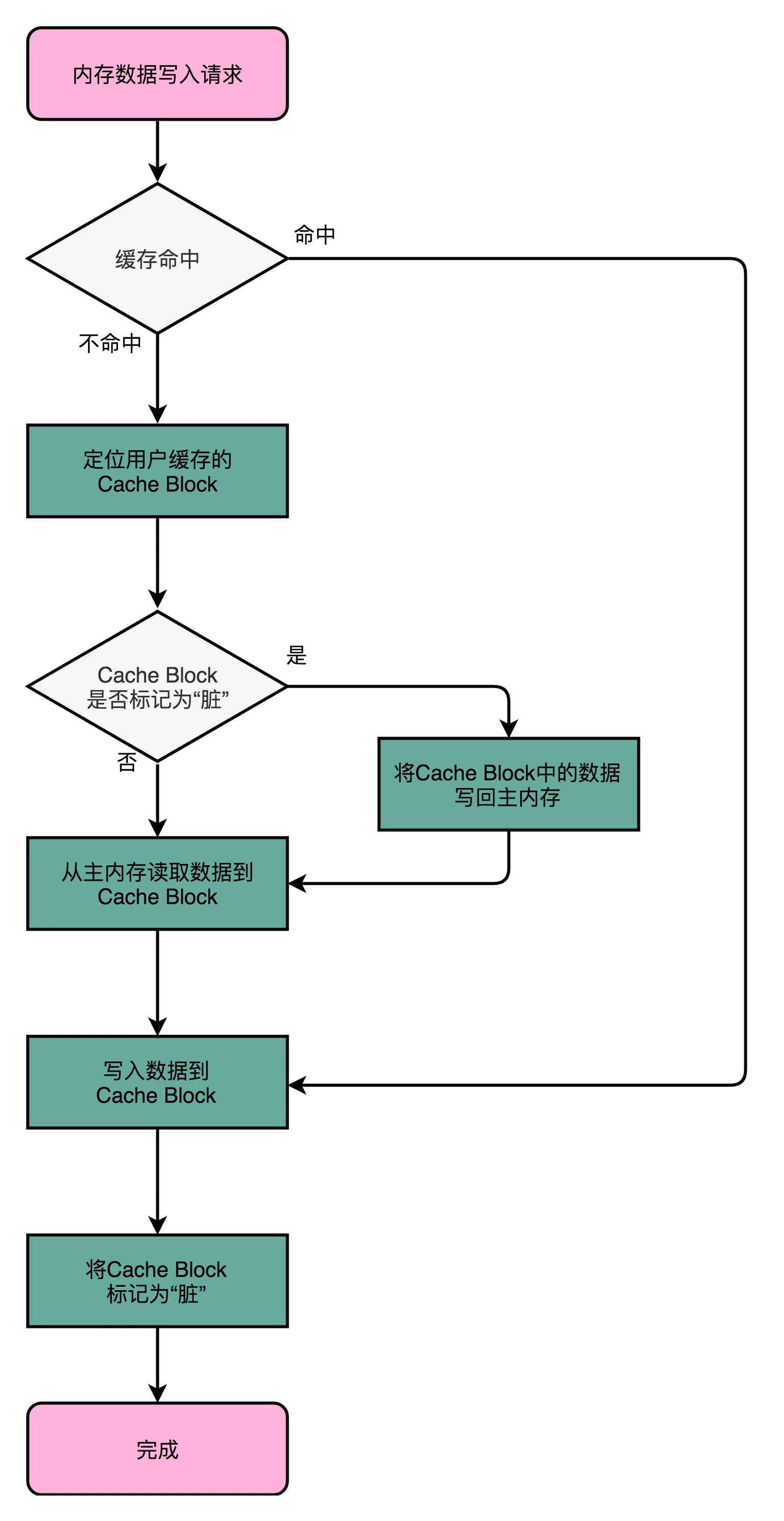
由于读数据也是从 Cache 中读取,所以我们可以先将修改的数据放到 Cache Block 中,之后访问到的也是修改的数据,如果之后需要对该 Cache Block 进行修改,再将上面的数据写到主内存中,这里可以发现,我们需要一个判断位,来表明主内存中的数据是否与 Cache 中的数据一致。
MESI 保持缓存一致
已知多核 CPU 里的每一个 CPU 核,都有独立的属于自己的 L1 Cache 和 L2 Cache。多个 CPU 之间,只是共用 L3 Cache 和主内存。
CPU Cache 解决的是内存访问速度和 CPU 的速度差距太大的问题。而多核 CPU 提供的是,在主频难以提升的时候,通过增加 CPU 核心来提升 CPU 的吞吐率的办法。当多核和 CPU Cache 、结合,因为 CPU 的每个核各有各的缓存,互相之间的操作又是各自独立的,就会带来缓存一致性(Cache Coherence)的问题。
缓存一致性问题
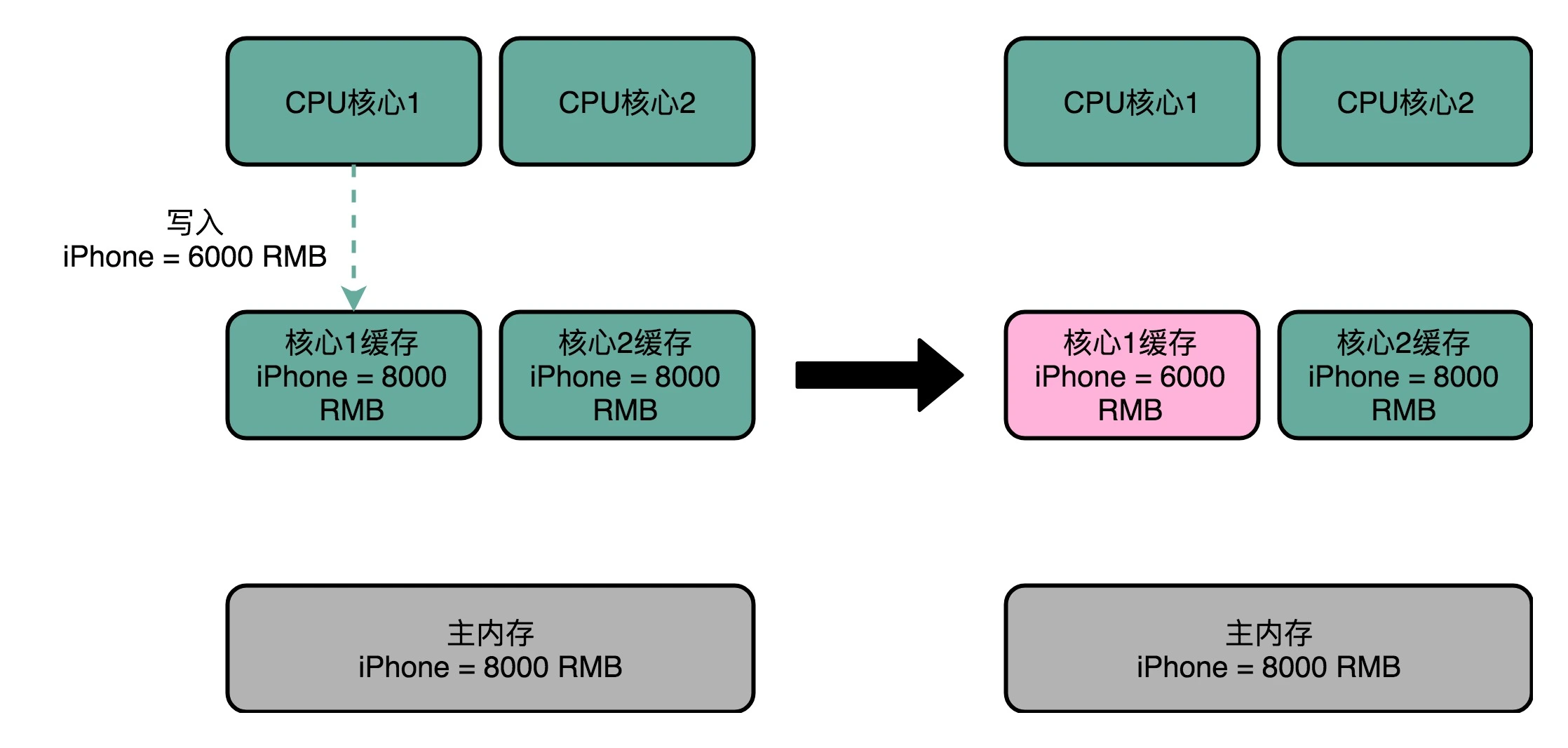
根据写回策略,核心 1 修改的内容只出现在该核心的 L2 Cache 中,并没有出现在核心2 的 L2 Cache 或者主内存中,这就是缓存一致性问题,两个核心在这时是不一致的。
为解决这一问题要做到两点:写传播,即在一个核心内 Cache 数据更新能够传播到其他对应节点的 Cache Line 中;事务串行化,也就是说在一个或者多个 CPU 核心内中对一个数据的读取和写入在其他节点看来顺序是一样的。
做到事务串行化需要做到两点:首先对于数据的操作要同步通信到其他核心,另外如果两个 CPU 核心中有一个相同的数据,这里就要用到锁。MESI 正是实现了这两个协议。
总线嗅探机制和 MESI 协议
总线嗅探(Bus Snooping),这个策略,本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。
基于总线嗅探机制,其实还可以分成很多种不同的缓存一致性协议。不过其中最常用的,就是 MESI 协议。和很多现代的 CPU 技术一样,MESI 协议也是在 Pentium 时代,被引入到 Intel CPU 中的。
写失效(Write Invalidate):只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。
写广播(Write Broadcast):一个写入请求广播到所有的 CPU 核心,同时更新各个核心里的 Cache。
写广播在实现上自然很简单,但是写广播需要占用更多的总线带宽。写失效只需要告诉其他的 CPU 核心,哪一个内存地址的缓存失效了,但是写广播还需要把对应的数据传输给其他 CPU 核心。
MESI 协议的由来,来自于对 Cache Line 的四个不同的标记,分别是:M:代表已修改(Modified)E:代表独占(Exclusive)S:代表共享(Shared)I:代表已失效(Invalidated)。
Modified:当前 CPU 缓存有最新数据,其他 CPU 拥有失效数据,当前 CPU 数据与内存不一致,但以当前 CPU 数据为准。
Exclusive:只有当前 CPU 有数据,其他 CPU 没有该数据,当前 CPU 数据与内存数据一致,如果收到了一个来自于总线的读取对应缓存的请求,它就会变成共享状态。
Shared:当前 CPU 与其他 CPU 拥有相同数据,并与内存中数据一致。该状态下更新 Cache 中的数据时,获取操作锁,通过广播将其他 CPU 中相应的缓存改为无效状态,然后修改当前 Cache 中的数据。这个广播操作,一般叫作 RFO(Request For Ownership),也就是获取当前对应 Cache Block 数据的所有权。
Invaild:当前 CPU 数据失效,其他 CPU 数据可能有可能无,数据应从内存中读取,且当前 CPU 与 内存数据不一致。

Modified
- LR:当前 CPU 读操作,缓存中拥有最新数据,直接从缓存中读取,状态不变。
- LW:当前 CPU 写操作,直接修改当前 CPU 缓存数据,修改后仍拥有最新数据,状态不变。
- RR:其他 CPU 方式读操作,为了保证一致性,当前 CPU 将数据写回内存,随后 RR 使得其他 CPU 与当前 CPU 拥有相同数据,状态 改为 S。
- RW:其他 CPU 写操作,当前 CPU 将数据写回内存,随后 RW 将内存数据修改,当前 CPU 缓存状态改为 I。
Shared
- LR:当前 CPU 读数据,状态不变
- LW:当前 CPU 写操作,并不会将数据立即写回内存,为了保证一致性,将状态修改为 M。
- RR:其他 CPU 读操作,因为多个 CPU 数据都与内存一致,状态不变。
- RW:其他 CPU 写操作,其他 CPU 数据为最新,当前 CPU 数据失效,状态改为 I。
Exclusive
- LR:当前 CPU 读操作,状态不变。
- LW:当前 CPU 写操作,修改当前 CPU 缓存值,状态改为 M。
- RR:其他 CPU 读操作,两个 CPU 和内存中数据一致,状态改为 S。
- RW:其他 CPU 写操作,其他 CPU 数据为最新,当前 CPU 数据失效,状态改为 I。
Invalid
- LR:当前 CPU 读操作,当前 CPU 缓存不可用,需要读内存。
- 其他 CPU 无数据,当前 CPU 独享数据,状态改为 E。
- 其他 CPU 有数据且状态为 S 、E,当前 CPU 与其他 CPU 以及内存数据一致,状态修改为 S。
- 其他 CPU 有数据且状态为 M, 其他 CPU 先将数据写回内存,随后当前 CPU 读数据,与其他 CPU 以及内存数据一致,状态改为 S。
- LW:当前 CPU 写操作,当前 CPU 缓存不可用,需要写内存。
- 其他 CPU 无数据,只有当前 CPU 缓存有数据,且被修改与内存不一致,状态改为 M。
- 其他 CPU 又数据且为 S、E,当前 CPU 缓存为最新且已修改,状态改为 M。
- 其他 CPU 有数据且状态为 M, 其他 CPU 先将数据写回内存,随后当前 CPU 写数据,状态改为 M。
- RR:其他 CPU 读操作,与当前 CPU 缓存无关,状态不变。
- RW:其他 CPU 写操作,与当前 CPU 缓存无关,状态不变。
扩展阅读:缓存一致性协议

若有收获,就点个赞吧
0 人点赞
