链表结构
单链表
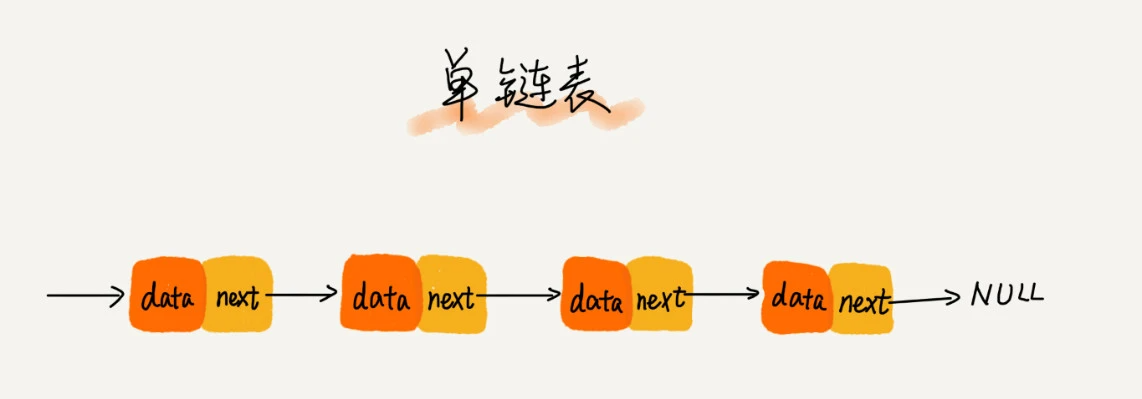
两个特殊节点:头节点,尾节点。其中,头节点来记录链表的基地址,一般不存储数据,尾结点不指向下一个节点,而是指向空地址 NULL,表示这是链表的最后一个节点。
同数组一样,链表也支持数组的查找,删除,插入操作,相比数组,链表的删除,插入操作只需要修改结点的指针,释放内存空间,不必再将数据进行转移。相比之下,两种操作对于数组的时间复杂度都是 O(n) , 对链表都是 O(1) 。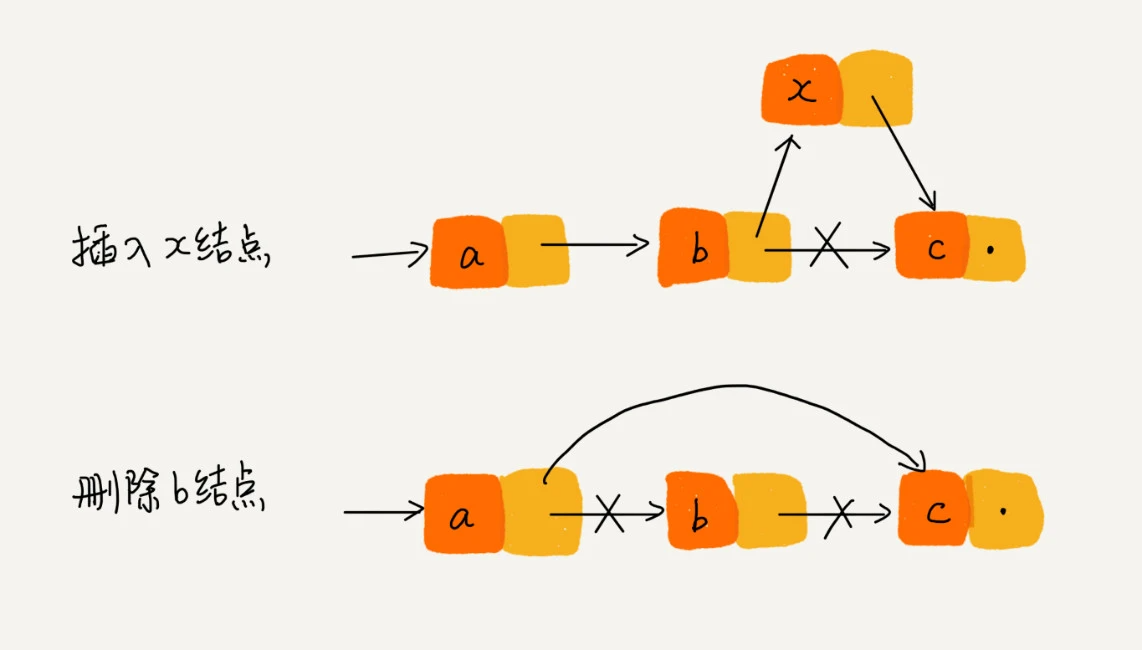
但是,想要随机访问链表中第 k 个元素就做不到数组这么高效。
虽然避免了大规模的数据的转移,但随机访问的时间复杂度到达了 O(n)。
循环链表
特点:在单链表的末尾引出一个指针,指向了头节点。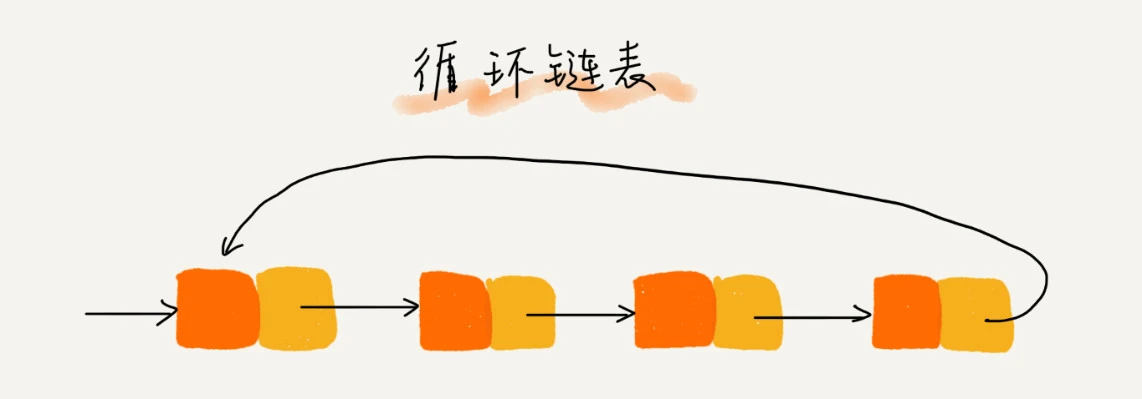
处理环形结构可以使代码更加简洁。例如:约瑟夫环
//人们站在一个等待被处决的圈子里。 计数从圆圈中的指定点开始,并沿指定方向围绕圆圈进行。//在跳过指定数量的人之后,处刑下一个人。 对剩下的人重复该过程,从下一个人开始,//朝同一方向跳过相同数量的人,直到只剩下一个人,并被释放。#include <iostream>#include <cstdlib>#include <cstdio>using namespace std;typedef struct _LinkNode {int value;struct _LinkNode* next;} LinkNode, *LinkNodePtr;LinkNodePtr createCycle(int total) {int index = 1;LinkNodePtr head = NULL, curr = NULL, prev = NULL;head = (LinkNodePtr) malloc(sizeof(LinkNode));// 分配所需的内存空间,并返回一个指向它的指针。head->value = index;prev = head;while (--total > 0) {curr = (LinkNodePtr) malloc(sizeof(LinkNode));curr->value = ++index;prev->next = curr;prev = curr;}curr->next = head;//实现循环return head;}void run(int total, int tag) {LinkNodePtr node = createCycle(total);//node 为生成的链表的第一个节点的指针LinkNodePtr prev = NULL;int start = 1;int index = start;while (node->next != node) { //只剩下一个if (index == tag) {printf("%d\n", node->value);if (tag == start) {prev = node->next;node->next = NULL;//释放当前 node 结点的内存node = prev;} else {prev->next = node->next;node->next = NULL;//为什么要这样释放?node = prev->next;}index = start;} else {prev = node;node = node->next;index++;}}}int main() {if (argc < 3) return -1;run(atoi(argv[1]), atoi(argv[2]));return 0;}
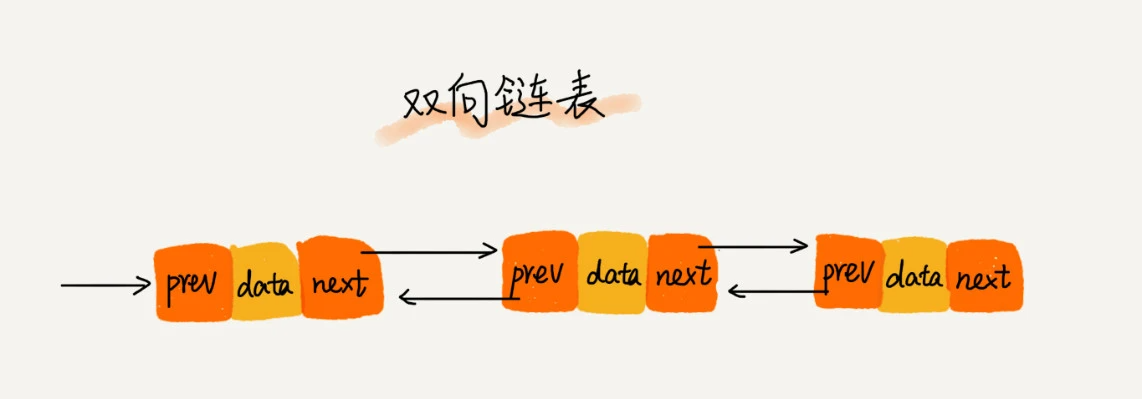
双向链表
运用了空间换时间的思想,当内存空间充足的时候,如果我们更加追求代码的执行速度,我们就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这个时候,就要反过来用时间换空间的设计思路。
相比于单链表,多了一个前驱指针 prev ,相比循环链表,我们可以使最后一个结点的 next 指向第一个结点,最第一个结点的 prev 指向最后一个结点,就形成了双向循环链表。相比单链表,数据密度下降,但有了前驱指针,使用起来更加灵活。
链表的删除和插入效率被提高:
1:删除某个给定值,可以进行双向遍历。
2:已知结点,将其删除或在它前边进行插入,就不必再遍历寻找前一个结点。此外对有序链表进行多次查找时,我们记住上一次查找的值得地址,下一次查找时先和上一个值进行对比,再决定查哪一边,这样就只需要再查一半就可以。
数组与链表
数组可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。(CPU 读取内存中一块连续的内存到缓存中,访问内存数据时现在缓存中查找,没有的话再去内存中查找(空间局部性))
数组受内存限制过大,需要连续内存,以及满了之后的扩容操作,go 语言的 slice,Java 中的 ArrayList 容器,只是将扩容这一步包装了起来,实质上还是数据转移。
实际的选择还要看使用位置,数据量,后期将要进行的操作来权衡选择哪一个。
C exampel
// Type your code here, or load an examp#include <stdio.h>#include <stdlib.h>typedef struct node {struct node *next;int value;} node_t, *node_ptr;typedef struct list {node_ptr head;} list_t;node_ptr create_node(int value) {node_ptr p_node = (node_ptr)malloc(sizeof(node_t));if (p_node != NULL) {p_node->next = NULL;p_node->value = value;}return p_node;}// Append at tailvoid list_append(list_t *list, node_ptr node) {if (node == NULL) {return;}if (list->head == NULL) {list->head = node;return;}node_ptr last = list->head;while(last->next != NULL) {last = last->next;}last->next = node;}void list_append_front(list_t *list, node_ptr node) {if (node == NULL) {return;}node->next = list->head;list->head = node;}void list_display(list_t *list) {node_ptr p_node = list->head;while(p_node != NULL) {printf("node[%u] {\n next: %u, \n value: %d\n}\n", p_node, p_node->next, p_node->value);p_node = p_node->next;}}void list_destroy(list_t *list) {node_ptr p_node = list->head->next;while(p_node != NULL) {free(list->head);list->head = p_node;p_node = p_node->next;}free(list->head);list->head = NULL;}void list_delete(list_t *list, node_ptr p_node) {if (p_node == list->head) {list->head = p_node->next;p_node->next = NULL;return;}node_ptr p_prev = list->head;while(p_prev != NULL && p_prev->next != p_node) {p_prev = p_prev->next;}if (p_prev == NULL) {return;}p_prev->next = p_node->next;p_node->next = NULL;}void list_reverse(list_t *list) {node_ptr p_node = list->head, p_next = list->head->next;list->head->next = NULL;while(p_next != NULL) {list->head = p_next;p_next = p_next->next;list->head->next = p_node;p_node = list->head;}list->head = p_node;}void list_push(list_t *list, node_ptr node) {if (node == NULL) {return;}node->next = list->head;list->head = node;}node_ptr list_pop(list_t *list) {if (list->head == NULL) {return NULL;}node_ptr p_node = list->head;list->head = list->head->next;p_node->next = NULL;return p_node;}int main() {list_t list = {.head = NULL};int const len = 10;for (int i = 0; i < len; i++) {node_ptr p_node = create_node(i);list_append_front(&list, p_node);}list_display(&list);printf("\n");list_reverse(&list);list_display(&list);printf("\n");node_ptr p_node = create_node(len);list_push(&list, p_node);list_delete(&list, p_node->next);list_delete(&list, p_node);list_display(&list);printf("\n");list_destroy(&list);return 0;}

Q & A
malloc & calloc
int * ptr = NULL;ptr = (int *)calloc(8, sizeof(int));// memset(ptr, 255, 8*sizeof(int));for (size_t i = 0; i < 8; i++){printf("ptr[%d] = %d \n", i, ptr[i]);}//outputptr[0] = 0ptr[1] = 0ptr[2] = 0ptr[3] = 0ptr[4] = 0ptr[5] = 0ptr[6] = 0ptr[7] = 0int * ptr = NULL;ptr = (int *)malloc(8, sizeof(int));// memset(ptr, 255, 8*sizeof(int));for (size_t i = 0; i < 8; i++){printf("ptr[%d] = %d \n", i, ptr[i]);}//outputptr[0] = 7476208ptr[1] = 0ptr[2] = 7471440ptr[3] = 0ptr[4] = 0ptr[5] = 0ptr[6] = 0ptr[7] = 0
区别:参数不同,malloc 不能初始化所分配的内存空间,后者可以,使用 malloc 分配的内容空间如果原来没有被使用过,那么其中的每一位都为 0,而如果该内存被使用过,那么其中就会有各种数据,如上所示的 ptr[0] ptr[2],calloc 函数会将每一位都初始化为 0,具体方式如下表:
| 字符/整数 | 指针 | 实型数据 |
|---|---|---|
| 0 | NULL | 浮点型 0 |
memset
//int * ptr = NULL;// ptr = (int *)malloc(8*sizeof(int));int ptr[5];memset(ptr, 1, 8*sizeof(int));for (size_t i = 0; i < 8; i++){printf("ptr[%d] = %d \n", i, ptr[i]);}//上下两种写法效果一致//output:ptr[0] = 16843009ptr[1] = 16843009ptr[2] = 16843009ptr[3] = 16843009ptr[4] = 16843009ptr[5] = 16843009ptr[6] = 16843009ptr[7] = 16843009int ptr[5];memset(ptr, 255, 8*sizeof(int));for (size_t i = 0; i < 8; i++){printf("ptr[%d] = %d \n", i, ptr[i]);}//output:ptr[0] = -1ptr[1] = -1ptr[2] = -1ptr[3] = -1ptr[4] = -1ptr[5] = -1ptr[6] = -1ptr[7] = -1
该函数按字节复制,其中第二个 int 参数的后八位二进制进行赋值,1 的二进制是(00000000 00000000 00000000 00000001),取后 8 位(00000001),int 型占 4 个字节,当初始化为 1 时,它把一个 int 的每个字节都设置为 1,也就是 0x01010101,二进制是(00000001 00000001 00000001 00000001),十进制就是16843009。
对于 -1,负数在计算机中以补码存储,二进制是(11111111 11111111 11111111 11111111),取后 8 位(11111111),则是 11111111 11111111 11111111 11111111 结果也是 -1 。
同理,传入的值为 255 最后的二进制格式也是 11111111 11111111 11111111 11111111 结果也是 -1 。
下面是关于使用 memset 的一些好处:
指针类型的作用
首先,不同类型的数据占有不同大小的内存空间,而指针只是指向内存空间的首地址,使用指针类型,就可以指定需要取出几个字节,准确得到需要的数据:
int i = 123456789; // 0x075bcd15
char *c = (char*)&i;
printf("char:%d\n", *c);
//char 类型指针,取出一个字节,小端机器,取出 16 进制的 15,十进制就是 21.
short *s = (short*)&i;
printf("short:%d\n", *s);
//shot 类型指针,取出 16 进制的 cd15,十进制就是 -13035
int *pi = &i;
printf("int:%d\n", *pi);
//打印出 123456789
其次,对于指针的加减操作,也是与指针的类型绑定的:
int *p = (int*)0x7fffffffe1e4;
printf("int p=%u, p+1=%u \n", p,p+1);
char *c = (char*)p;
printf("char p=%u, p+1=%u \n", c,c+1);
short *s = (short*)p;
printf("short p=%u, p+1=%u \n", s,s+1);
double *d = (double*)p;
printf("double p=%u, p+1=%u \n", d,d+1);
int ar[10] = {0};
int (*pa)[10] = &ar;
//pa是10个元素的int数组的指针,所以pa+1后,就移动了40(4*10)个字节
printf("ar[10] p=%u, p+1=%u \n", pa,pa+1);
//output
int p=4294959588, p+1=4294959592
char p=4294959588, p+1=4294959589
short p=4294959588, p+1=4294959590
double p=4294959588, p+1=4294959596
ar[10] p=6421968, p+1=6422008
int n = 10;
int b[n];
for(int i=0;i<n;i++)
{
b[i]=i;
}
fun1(b, n);
printf("%d, %d", b[0],*(b+1));
//output
a[0] = 0
a[1] = 1
a[2] = 2
a[3] = 3
a[4] = 4
a[5] = 5
a[6] = 6
a[7] = 7
a[8] = 8
a[9] = 9
9999, 1
void *
首先,void 可以限定函数的返回值以及参数,即不返回任何参数或者不接受任何参数。
void func(){}
int func(void){return 0;}
其次,指向任意类型数据,当将其赋值给其他指针时,需要进行类型转换,内存申请函数返回值也是 void * 类型数据,所以在使用时候首先要进行类型转换,例如:`int * p = (int *)malloc(sizeof(int));`
int a = 10;
int * p0 = &a;
void *p = p0;
int *b = (int*)p;
printf("int *b = (int*)p, *b = %d", *b);
//output
int *b = (int*)p, *b = 10
不同类型指针之间相互赋值需要强制类型转换:
int a = 10;
char c = '9';
int * ptr_a = &a;
int * ptr_c = &c;
ptr_a = ptr_c;
//change to: ptr_a = (int *)ptr_c;
//output
test.c:9:9: warning: assignment to 'int *' from incompatible pointer type 'char *' [-Wincompatible-pointer-types]
ptr_a = ptr_c;
^
//对于 void * ,任意类型指针都可以赋值给它,无需强制类型转换
int a = 10;
int * ptr_a = &a;
void * p = ptr_a;
此外 void * 还可以用在函数中,函数中形为指针类型时,就可以使用 void * 类型进行替代,这样函数就可以接受任意类型的指针。
void * memcpy(void *dest, const void *src, size_t len);
void * memset ( void * buffer, int c, size_t num );
选择与效率
不同变成语言拥有各自的特点,C 语言主要设计理念不同,C 追求极致性能,而 Go 追求简洁易用,在如下函数中:
void list_reverse(list_t *list) {
node_ptr p_node = list->head, p_next = list->head->next;
list->head->next = NULL;
while(p_next != NULL) {
list->head = p_next;
p_next = p_next->next;
list->head->next = p_node;
p_node = list->head;
}
list->head = p_node;
}
该函数并未判断链表是否为空,这样就不必每次调用都执行一次判断,此外按照实际使用情况来说,对一个链表进行反转,一般传进来空链表情况很少见,所以这里判断链表为空的操作就留给了函数的使用者。相比之下,Go 的代码实现如下:
func (this *LinkedList) Reverse() {
if nil == this.head || nil == this.head.next || nil == this.head.next.next {
return
}
var pre *ListNode = nil
cur := this.head.next
for nil != cur {
tmp := cur.next
cur.next = pre
pre = cur
cur = tmp
}
this.head.next = pre
}
只要传入链表即可,将所有功能打包在一起,简单易用。
这里发现两个问题,首先是对语言的特点了解不够深刻,C,Go 的核心理念还没搞懂,习惯于使用一套思维去写程序,另外一点就是要关注一个功能实现的情景,将函数调用方,函数本体以及返回值接受方等看作一个整体,来思考问题。
结构体别名
struct node
{
int value;
struct node *next;
};
//此时定义一个结果提类型的指针,应该是 struct node *p; 或者定义一个普通的结构体变量 struct node a;
//这样写起来比较麻烦,用 typedef 后
typedef struct node
{
int value;
struct node *next;
}linklist;
//那么现在 linklist 就代表这个结构体,现在定义结果提指针 linklist *p; 就方便了
//同样,把他定义成
typedef struct node
{
int age;
struct node *next;
}*linklist;
那么 linklist 就是代表这个结构体指针类型,linklist head; head 就是结构体指针类型了
还是以实际代码为例,其简便性一目了然:
typedef struct node {
struct node *next;
int value;
} node_t, *node_ptr;
// struct node n0; ok
// struct node *n1; ok
// node n2; no
// node *n3; no
// node_t n4; ok
// node_p n5; ok
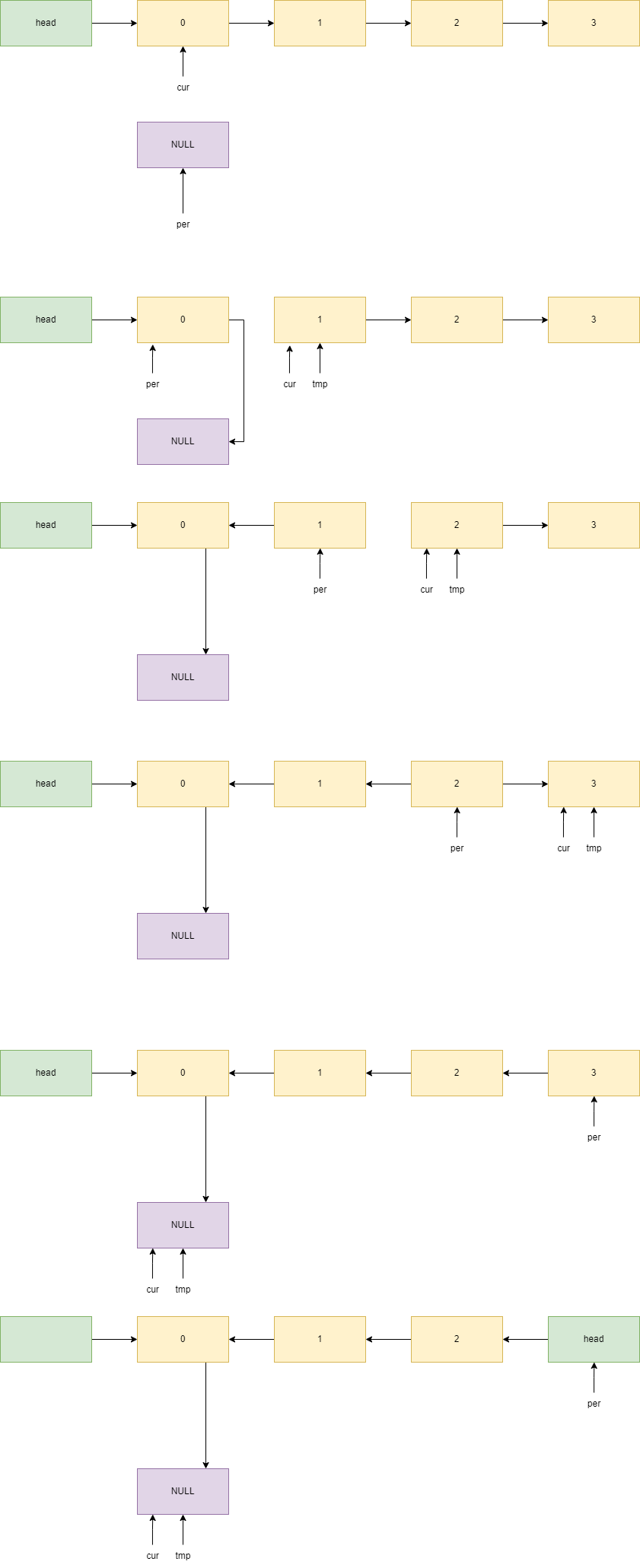
链表反转
void list_reverse(list_t *list) {
node_ptr p_node = list->head, p_next = list->head->next;
list->head->next = NULL;
while(p_next != NULL) {
list->head = p_next;
p_next = p_next->next;
list->head->next = p_node;
p_node = list->head;
}
list->head = p_node;
}

若有收获,就点个赞吧
0 人点赞
