IPC
首先回顾一下之前提到过的程序的 CPU 执行时间:

CPI 平均每个指令需要的 CPU 时间,IPC(Instruction Per Clock)即 CPI 的倒数,代表一个 CPU 时钟周期内能够执行的指令数。代表了 CPU 的吞吐率。
流水线层面的优化,即使做到了指令层面的乱序执行,CPU 仍然只能在一个时钟周期内,取一条指令,对 IPC 的提升造成了限制。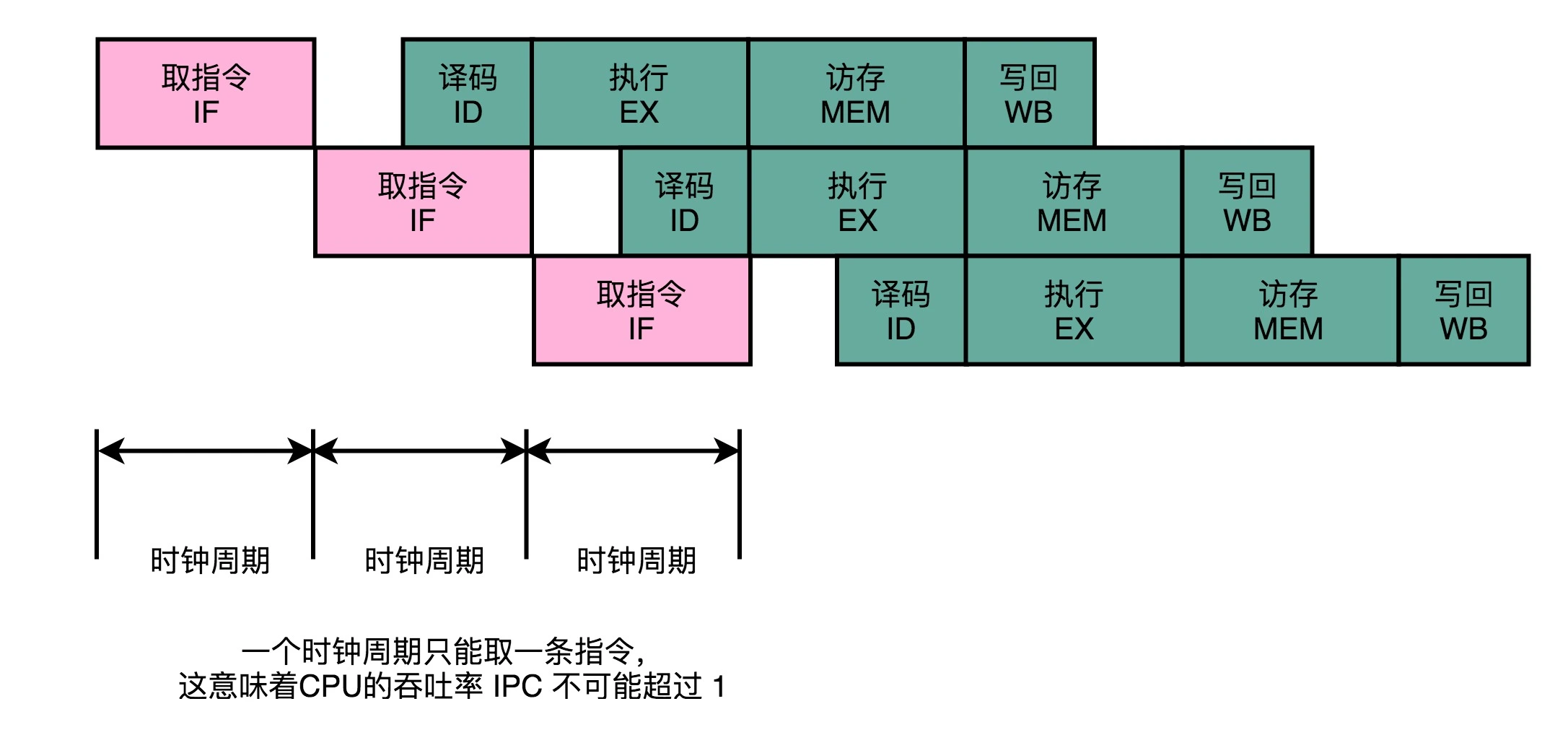
多发射与超标量
乱序执行中看到,取指令和指令译码部分并不是并行进行的:
为解决这个问题,可以像加法器一样,通过增加硬件,实现并行。这样可以一次性从内存中取出多条指令,然后分发给多个并行的译码器,进行译码,然后交给不同的功能单元去处理,这样在一个时钟周期内能够完成的指令就不止一条了,IPC 也就能够大于一了。
多发射(Mulitple Issue):同一时间,可能会同时把多条指令发射到不同的译码器或者后续流水线中去。
在超标量的 CPU 里面,有很多条并行的流水线,而不是只有一条流水线。“超标量“这个词是说,本来在一个时钟周期里面,只能执行一个标量(Scalar)的运算。在多发射的情况下,我们就能够超越这个限制,同时进行多次计算。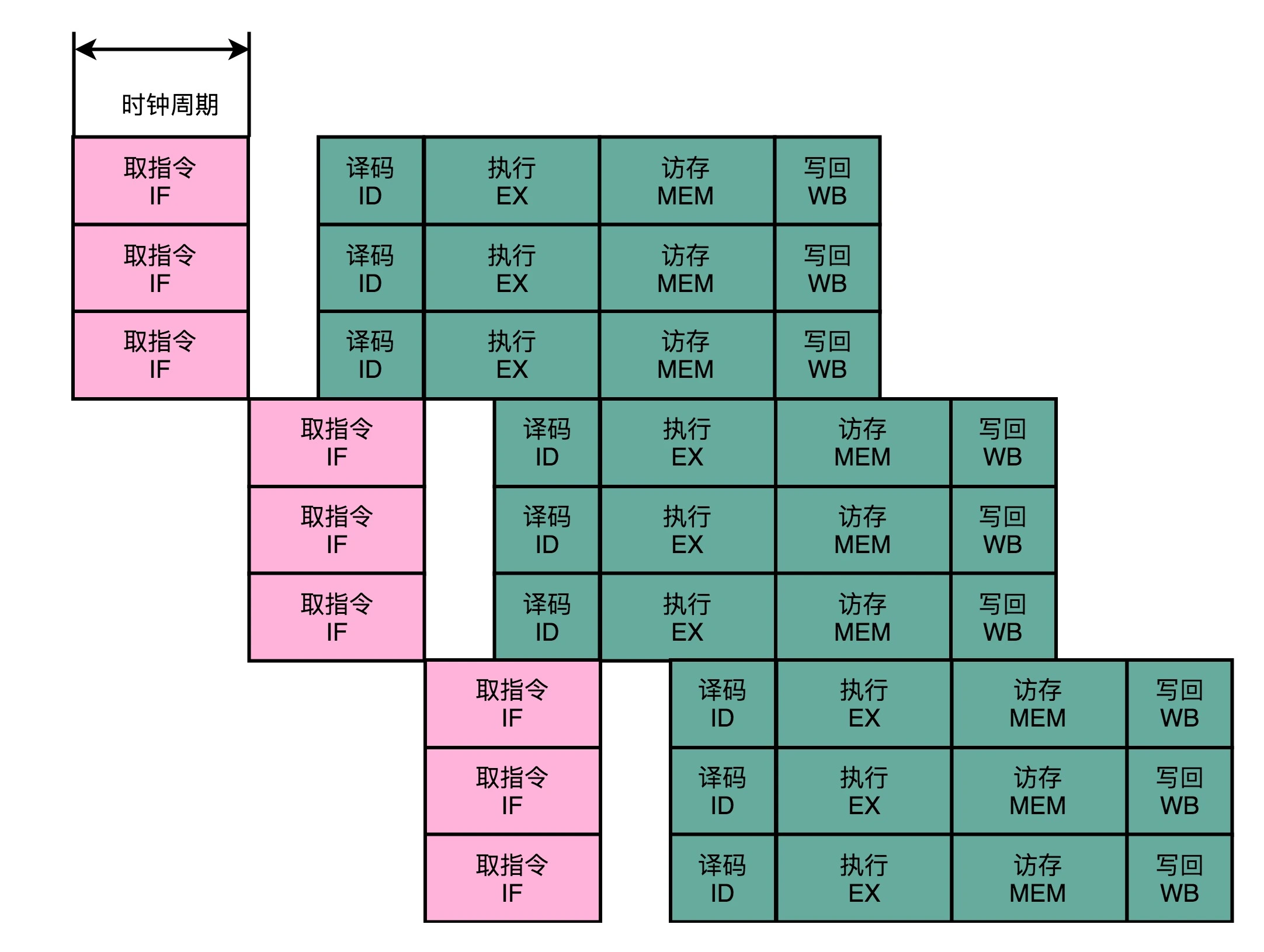
超长指令字设计
主要目的:通过编译器来优化 CPI。在乱序执行和超标量的 CPU 架构里,指令的前后依赖关系,是由 CPU 内部的硬件电路来实现的,而超长指令的架构里,这个工作交给了编译器这个软件。")
之前的 C 语言转换的代码中可以发现:编译器在编译过程中也可以分析前后数据的依赖,于是,可以让编译器把没有依赖关系的代码位置进行交换。然后,再把多条连续的指令打包成一个指令包。承接上图,将三条取指令操作变成一个指令包: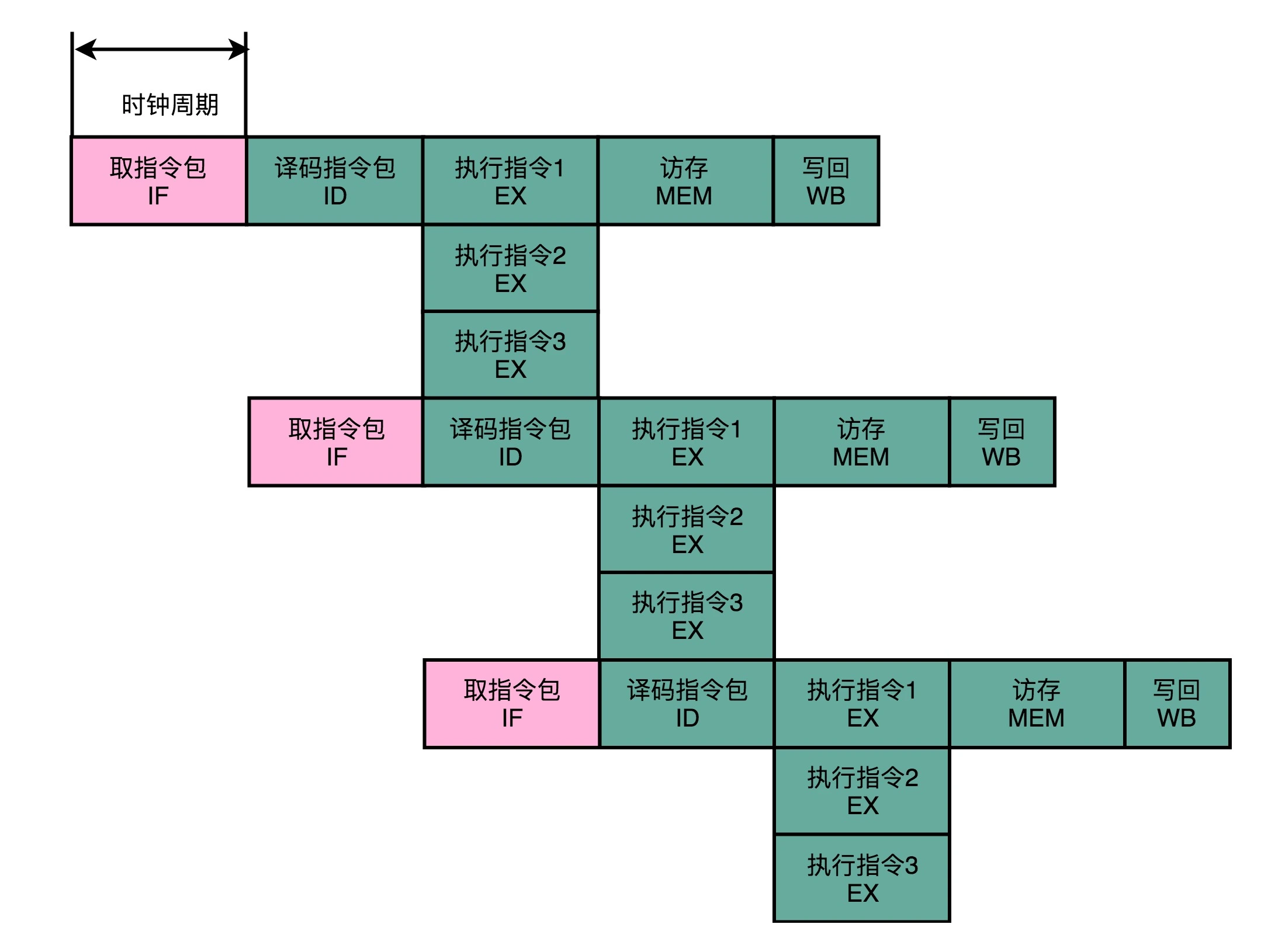
CPU 在运行的时候,不再是取一条指令,而是取出一个指令包。然后,译码解析整个指令包,解析出 3 条指令直接并行运行。可以看到,使用超长指令字架构的 CPU,同样是采用流水线架构的。也就是说,一组(Group)指令,仍然要经历多个时钟周期。同样的,下一组指令并不是等上一组指令执行完成之后再执行,而是在上一组指令的指令译码阶段,就开始取指令了。
重要问题:向上兼容
一方面,安腾处理器的指令集和 x86 是不同的。这就意味着,原来 x86 上的所有程序是没有办法在安腾上运行的,而需要通过编译器重新编译才行。
另一方面,安腾处理器的 VLIW 架构决定了,如果安腾需要提升并行度,就需要增加一个指令包里包含的指令数量,比方说从 3 个变成 6 个。一旦这么做了,虽然同样是 VLIW 架构,同样指令集的安腾 CPU,程序也需要重新编译。因为原来编译器判断的依赖关系是在 3 个指令以及由 3 个指令组成的指令包之间,现在要变成 6 个指令和 6 个指令组成的指令包。编译器需要重新编译,交换指令顺序以及 NOP 操作,才能满足条件。甚至,我们需要重新来写编译器,才能让程序在新的 CPU 上跑起来。
耦合度过高,使得安腾处理器既不容易向前兼容也不容易向后兼容,可见技术思想上的现金想法与现实实现之间的距离,所以在设计时,要更多的去考虑实践因素。

若有收获,就点个赞吧
0 人点赞
