虚拟内存

我们的内存需要被分成固定大小的页(Page),然后再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而我们的程序看到的内存地址,都是虚拟内存地址。
接下来介绍这些虚拟内存地址是如何转换成物理内存地址的。
简单页表
想要把虚拟内存地址,映射到物理内存地址,最直观的办法,就是来建一张映射表。这个映射表,能够实现虚拟内存里面的页,到物理内存里面的页的一一映射。这个映射表,在计算机里面,就叫作页表(Page Table)。页表这个地址转换的办法,会把一个内存地址分成页号(Directory)和偏移量(Offset)两个部分。
其实,前面的高位,就是内存地址的页号。后面的低位,就是内存地址里面的偏移量。做地址转换的页表,只需要保留虚拟内存地址的页号和物理内存地址的页号之间的映射关系就可以了。同一个页里面的内存,在物理层面是连续的。以一个页的大小是 4K 字节(4KB),物理内存共 4G 为例,我们需要 20 位的高位,12 位的低位。
页号是 20 位,另外 12 位是偏移地址。 每页大小是 4KB,4K=2^12B,所以要在 4KB 的页面里面进行寻址,偏移量是 12 位。 要表示 4GB 的内存,4GB = 2^32 = 2^20 * 2^12,所以需要 2^20 页,所以页号是 20 位。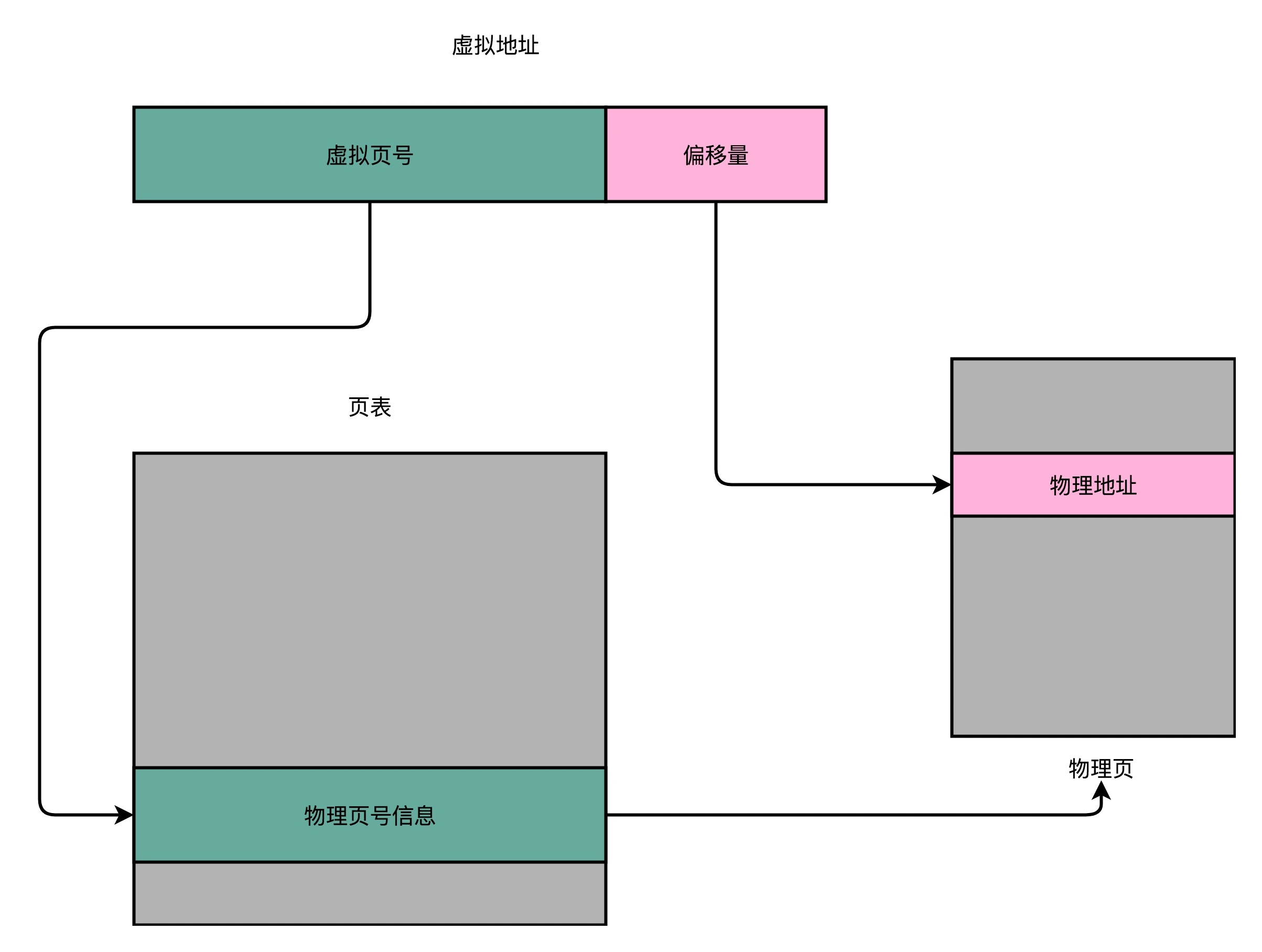
转换过程:将虚拟内存地址切分为页号和偏移量的组合,从页表里面查虚拟号对应的物理页号,直接拿物理页号加上前面的偏移量,就得到了物理内存。
但是为了维护这个页表会浪费大量的内存空间,于是出现了多级页表。
多级页表
以一个 4 级的多级页表为例,来看一下。同样一个虚拟内存地址,偏移量的部分和上面简单页表一样不变,但是原先的页号部分,我们把它拆成四段,从高到低,分成 4 级到 1 级这样 4 个页表索引。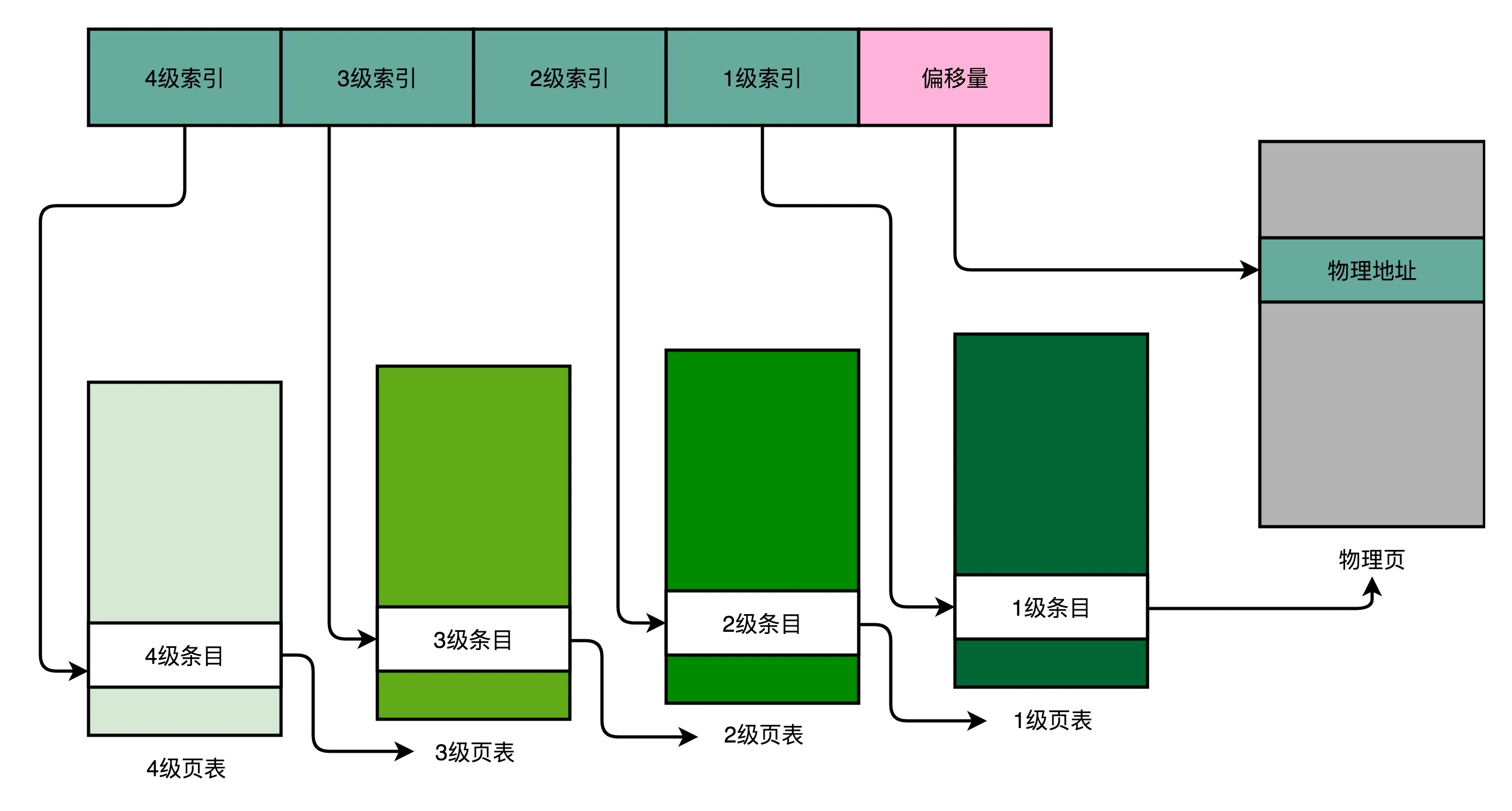
由于堆栈的地址变化规律以及局部性原则,我们知道一个进程中的内存总是一块或几块连续的,在页表对应时,有的虚拟地址对应的物理地址并未被使用,所以我们在 3 级以及之后的页表中不必进行映射。
以这样的分成 4 级的多级页表来看,每一级如果都用 5 个比特表示。那么每一张某 1 级的页表,只需要 2^5=32 个条目。如果每个条目还是 4 个字节,那么一共需要 128 个字节。而一个 1 级索引表,对应 32 个 4KB 的也就是 128KB 的大小。一个填满的 2 级索引表,对应的就是 32 个 1 级索引表,也就是 4MB 的大小。
举例:一个进程如果占用了 8MB 的内存空间,分成了 2 个 4MB 的连续空间。那么,它一共需要 2 个独立的、填满的 2 级索引表,也就意味着 64 个 1 级索引表,2 个独立的 3 级索引表,1 个 4 级索引表。一共需要 69 个索引表,每个 128 字节,大概就是 9KB 的空间。比起 4MB 来说,只有差不多 1/500。
这种方式下,4 级表覆盖了全部虚拟内存空间,而后 3 级表等可以在需要的时候再创建,如果不采用分级方式,假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了,所以页表一定要覆盖全部虚拟地址空间。
多级页表正是一个“以时间换空间”策略的体现,分级将原来只需要一次的内存地址查询改为了四次,接下来介绍为弥补在多次访问内存造成的损失都做了哪些优化。
扩展阅读:多级页表如何节约内存
加速地址转换:TLB
这里用到了“加个缓存”的方式,程序所需要使用的指令,都顺序存放在虚拟内存里面。我们执行的指令,也是一条条顺序执行下去的。也就是说,我们对于指令地址的访问,存在前面几讲所说的“空间局部性”和“时间局部性”,而需要访问的数据也是一样的。
假设我们连续执行 5 条指令,因为内存地址都是连续的,所以这 5 条指令通常都在同一个“虚拟页”里。因此,这连续 5 次的内存地址转换,其实都来自于同一个虚拟页号,转换的结果自然也就是同一个物理页号。那我们就可以用前面说过的,用一个“加个缓存”的办法。把之前的内存转换地址缓存下来,使得我们不需要反复去访问内存来进行内存地址转换。
于是,计算机工程师们专门在 CPU 里放了一块缓存芯片。这块缓存芯片我们称之为 TLB,全称是地址变换高速缓冲(Translation-Lookaside Buffer)。这块缓存存放了之前已经进行过地址转换的查询结果。这样,当同样的虚拟地址需要进行地址转换的时候,我们可以直接在 TLB 里面查询结果,而不需要多次访问内存来完成一次转换。
TLB 和我们前面讲的 CPU 的高速缓存类似,可以分成指令的 TLB 和数据的 TLB,也就是 ITLB 和 DTLB。同样的,我们也可以根据大小对它进行分级,变成 L1、L2 这样多层的 TLB。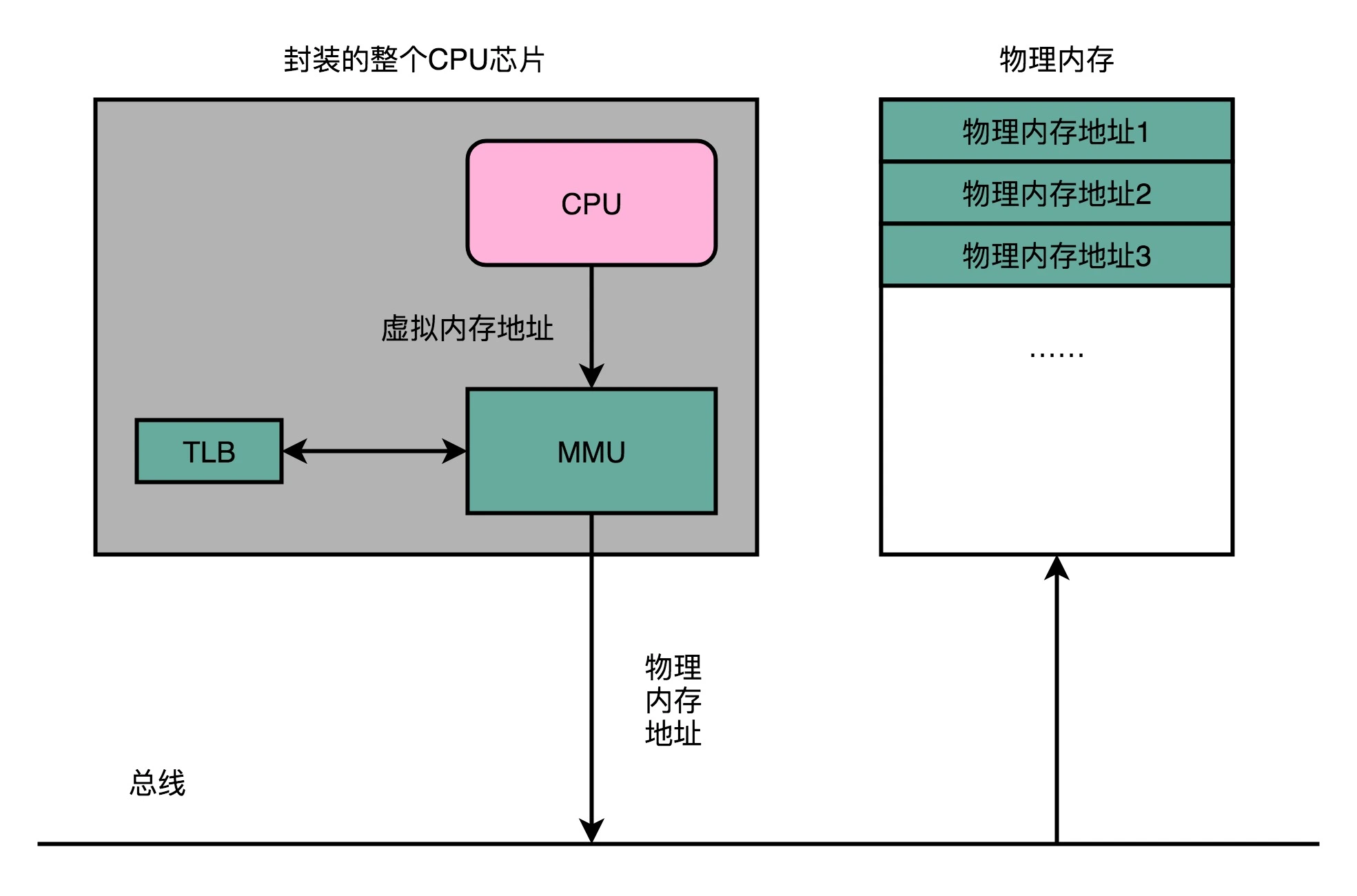
为了性能,我们整个内存转换过程也要由硬件来执行。在 CPU 芯片里面,我们封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换。和 TLB 的访问和交互,都是由这个 MMU 控制的。
安全与防护
正所谓没有不透风的墙,虽然我们现代的操作系统和 CPU,已经做了各种权限的管控。正常情况下,我们已经通过虚拟内存地址和物理内存地址的区分,隔离了各个进程。但是,无论是 CPU 这样的硬件,还是操作系统这样的软件,都太复杂了,难免还是会被黑客们找到各种各样的漏洞。
在对于内存的管理里面,计算机也有一些最底层的安全保护机制。这些机制统称为内存保护(Memory Protection)。
可执行空间保护
可执行空间保护(Executable Space Protection)是说,我们对于一个进程使用的内存,只把其中的指令部分设置成“可执行”的,对于其他部分,比如数据部分,不给予“可执行”的权限。因为无论是指令,还是数据,在我们的 CPU 看来,都是二进制的数据。我们直接把数据部分拿给 CPU,如果这些数据解码后,也能变成一条合理的指令,其实就是可执行的。
这个时候,黑客们想到了一些搞破坏的办法。他们在程序的数据区里,放入一些要执行的指令编码后的数据,然后找到一个办法,让 CPU 去把它们当成指令去加载,那 CPU 就能执行他们想要执行的指令了。对于进程里内存空间的执行权限进行控制,可以使得 CPU 只能执行指令区域的代码。对于数据区域的内容,即使找到了其他漏洞想要加载成指令来执行,也会因为没有权限而被阻挡掉。
这里举一个 SQL 注入攻击的例子。如果服务端执行的 SQL 脚本是通过字符串拼装出来的,那么在 Web 请求里面传输的参数就可以藏下一些我们想要执行的 SQL,让服务器执行一些我们没有想到过的 SQL 语句。这样的结果就是,或者破坏了数据库里的数据,或者被人拖库泄露了数据。
地址空间布局随机化
地址空间布局随机化(Address Space Layout Randomization),其他的人、进程、程序,会去修改掉特定进程的指令、数据,然后,让当前进程去执行这些指令和数据,造成破坏。要想修改这些指令和数据,需要知道这些指令和数据所在的位置才行。
原先我们一个进程的内存布局空间是固定的,所以任何第三方很容易就能知道指令在哪里,程序栈在哪里,数据在哪里,堆又在哪里。这为想要搞破坏的人创造了很大的便利。而地址空间布局随机化这个机制,就是让这些区域的位置不再固定,在内存空间随机去分配这些进程里不同部分所在的内存空间地址,让破坏者猜不出来,自然就没法找到想要修改的内容的位置。如果只是随便做点修改,程序只会 crash 掉,而不会去执行计划之外的代码。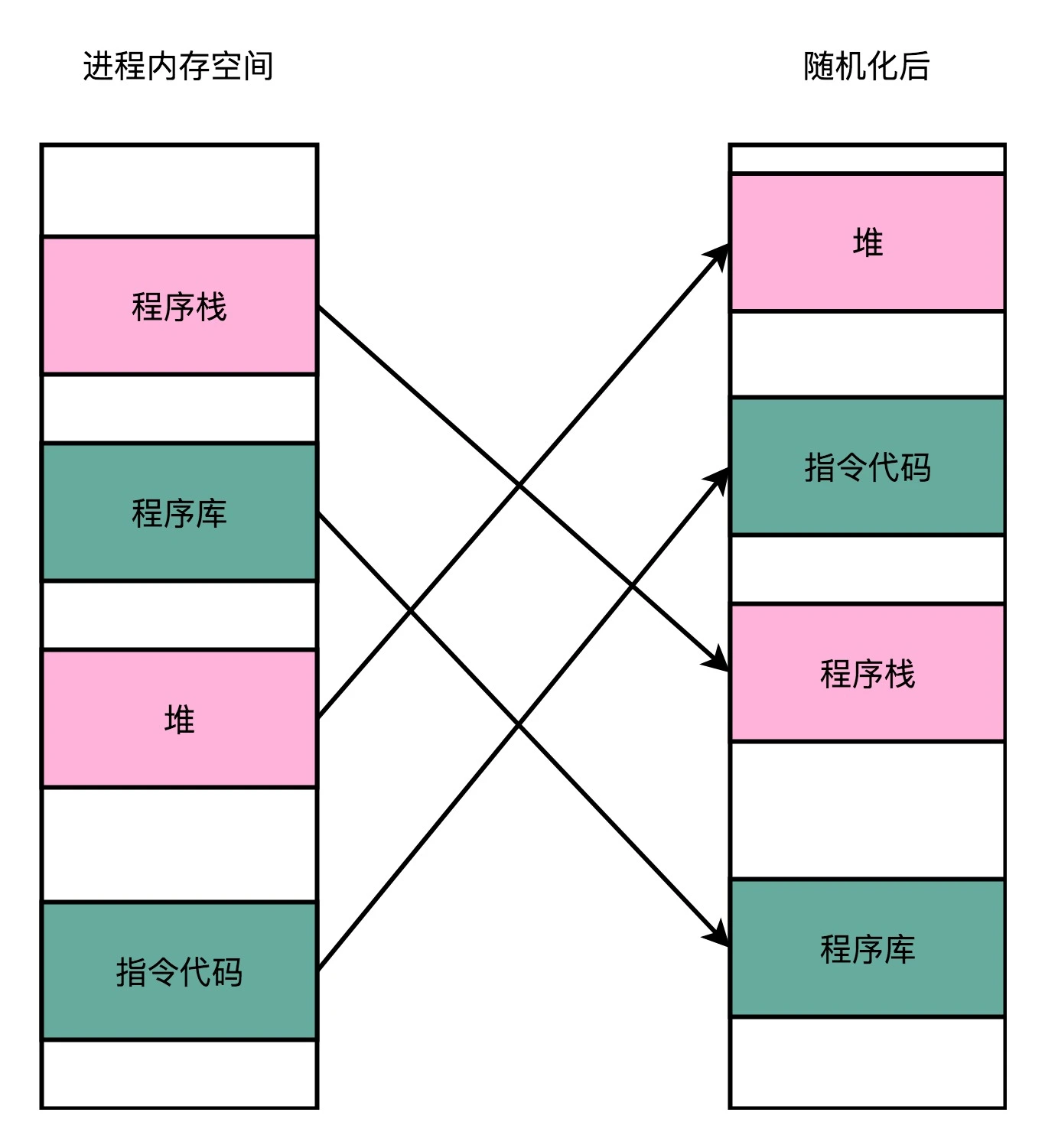
同样的思路也用到了密码的保存中:
$password = "goodmorning12345";// 我们的密码是明文存储的$hashed_password = hash('sha256', password);// 对应的hash值是 054df97ac847f831f81b439415b2bad05694d16822635999880d7561ee1b77ac// 但是这个hash值里可以用彩虹表直接“猜出来”原始的密码就是goodmorning12345$salt = "#21Pb$Hs&Xi923^)?";$salt_password = $salt.$password;$hashed_salt_password = hash('sha256', salt_password);// 这个hash后的slat因为有部分随机的字符串,不会在彩虹表里面出现。// 261e42d94063b884701149e46eeb42c489c6a6b3d95312e25eee0d008706035f

若有收获,就点个赞吧
0 人点赞
