程序装载面临的挑战
已知链接器可以把多个文件合并成一个最终可执行文件。在运行这些可执行文件的时候,通过一个装载器,解析 ELF 或者 PE 格式的可执行文件。装载器会把对应的指令和数据加载到内存里面来,让 CPU 去执行。
要将可执行文件装载到内存,需要装载器满足两个要求:
第一,可执行程序加载后占用的内存空间应该是连续的。执行指令的时候,程序计数器是顺序地一条一条指令执行下去。这也就意味着,这一条条指令需要连续地存储在一起。
第二,需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。虽然编译出来的指令里已经有了对应的各种各样的内存地址,但是实际加载的时候,我们其实没有办法确保,这个程序一定加载在哪一段内存地址上。因为现在的计算机通常会同时运行很多个程序,可能你想要的内存地址已经被其他加载了的程序占用了。
要满足这两个基本的要求,可以在内存里面,找到一段连续的内存空间,然后分配给装载的程序,把这段连续的内存空间地址,和整个程序指令里指定的内存地址做一个映射。指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address),实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。
对于任何一个程序来说,它看到的都是同样的内存地址。这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。因为是连续的内存地址空间,所以我们只需要维护映射关系的起始地址和对应的空间大小就可以。
内存分段
这种找出一段连续的物理内存和虚拟内存地址进行映射的方法叫分段。段,就是指系统分配出来的那个连续的内存空间。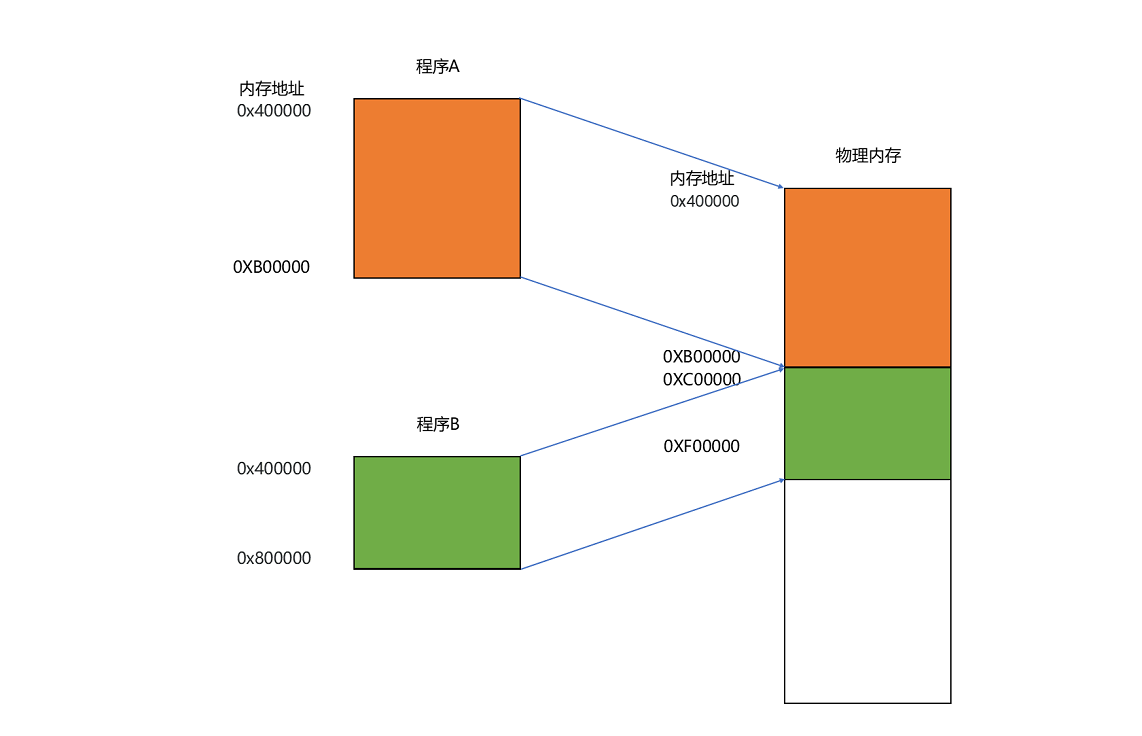
该方法解决了程序本身不需要关心具体的物理内存地址的问题,但又出现了内存碎片的问题。
对此有一个叫做内存交换的方法,我们可以把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。读回来的时候,直接写在那已经被占用了的 512MB 内存后面。这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。安装 Linux 操作系统时,会遇到过分配一个 swap 硬盘分区的问题。这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。
但这种方式由于硬盘的访问速度远远慢于内存,所以在进行内存交换的时候,会造成严重卡顿。
内存分页
既然问题出在内存碎片和内存交换的空间太大上,那么解决问题的办法就是,少出现一些内存碎片。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决这个问题。这个办法,在现在计算机的内存管理里面,就叫作内存分页(Paging)。
和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间就叫做页(Page)。从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下,通常设置成 4KB。
root@Wangying:/learncom/c# getconf PAGE_SIZE4096
由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。<br />使用分页方式,可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。这种方式,使得计算机可以运行那些远大于实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
通过引入虚拟内存、页映射和内存交换,程序本身就不再需要考虑对应的真实的内存地址、程序加载、内存管理等问题了。任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。
总结延伸
JVM 已经是上层应用,无需考虑物理分页,一般更直接是考虑对象本身的空间大小,物理硬件管理统一由承载 JVM 的操纵系统去解决。

若有收获,就点个赞吧
0 人点赞
