出现的背景
从 2012 年解决计算机视觉问题开始,深度学习一下子进入了大爆发阶段,也一下子带火了 GPU,NVidia 的股价一飞冲天。GPU 天生适合进行海量、并行的矩阵数值计算,于是它被大量用在深度学习的模型训练上。
深度学习热起来之后,计算量最大并不是进行深度学习的训练,而是深度学习的推断部分。
所谓推断部分,是指我们在完成深度学习训练之后,把训练完成的模型存储下来。这个存储下来的模型,是许许多多个向量组成的参数。然后,我们根据这些参数,去计算输入的数据,最终得到一个计算结果。这个推断过程,可能是在互联网广告领域,去推测某一个用户是否会点击特定的广告;也可能是我们在经过高铁站的时候,扫一下身份证进行一次人脸识别,判断一下是不是你本人。
虽然训练一个深度学习的模型需要花的时间不少,但是实际在推断上花的时间要更多。比如,我们上面说的高铁,去年(2018 年)一年就有 20 亿人次坐了高铁,这也就意味着至少进行了 20 亿次的人脸识别“推断“工作。
所以,第一代的 TPU,首先优化的并不是深度学习的模型训练,而是深度学习的模型推断。那模型的训练和推断有什么不同呢?主要有三个点。
第一点,深度学习的推断工作更简单,对灵活性的要求也就更低。模型推断的过程,我们只需要去计算一些矩阵的乘法、加法,调用一些 Sigmoid 或者 RELU 这样的激活函数。这样的过程可能需要反复进行很多层,但是也只是这些计算过程的简单组合。
第二点,深度学习的推断的性能,首先要保障响应时间的指标。我们在模型训练的时候,只需要考虑吞吐率问题就行了。因为一个模型训练少则好几分钟,多的话要几个月。而推断过程,像互联网广告的点击预测,我们往往希望能在几十毫秒乃至几毫秒之内就完成,而人脸识别也不希望会超过几秒钟。很显然,模型训练和推断对于性能的要求是截然不同的。
第三点,深度学习的推断工作,希望在功耗上尽可能少一些。深度学习的推断,要 7×24h 地跑在数据中心里面。而且,对应的芯片,要大规模地部署在数据中心。一块芯片减少 5% 的功耗,就能节省大量的电费。而深度学习的训练工作,大部分情况下只是少部分算法工程师用少量的机器进行。很多时候,只是做小规模的实验,尽快得到结果,节约人力成本。少数几台机器多花的电费,比起算法工程师的工资来说,只能算九牛一毛了。
这三点的差别,也就带出了第一代 TPU 的设计目标。那就是,在保障响应时间的情况下,能够尽可能地提高能效比这个指标,也就是进行同样多数量的推断工作,花费的整体能源要显著低于 CPU 和 GPU。
专用电路与大量缓存
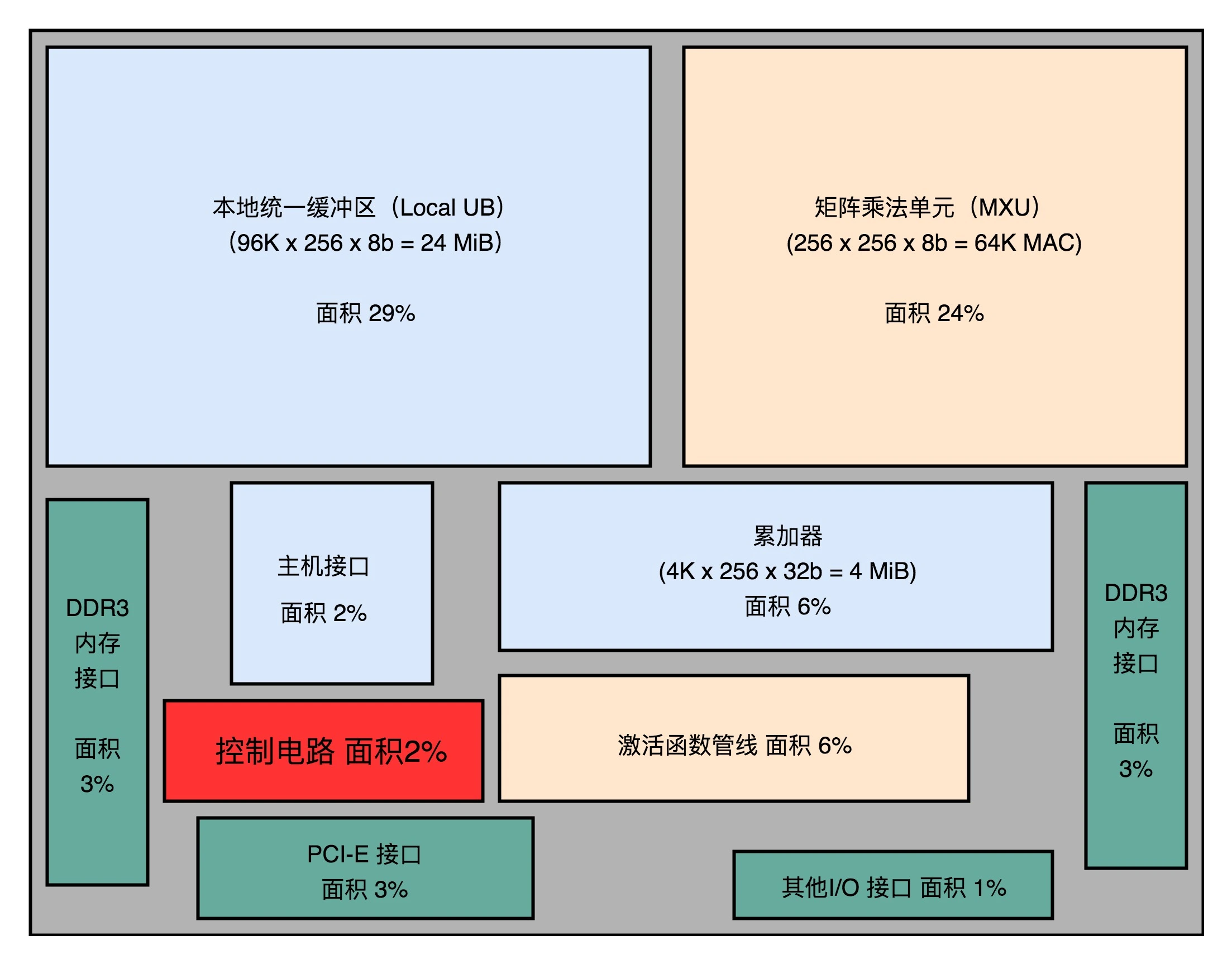
整个 TPU 里面,每一个组件的设计,完全是为了深度学习的推断过程设计出来的。这也是设计开发 ASIC 的核心原因:用特制的硬件,最大化特定任务的运行效率。
使用 8 bit 数据
在实践的机器学习应用中,会对数据做归一化(Normalization)和正则化(Regularization)的处理。这两个操作,会使得我们在深度学习里面操作的数据都不会变得太大。通常来说呢,都能控制在 -3 到 3 这样一定的范围之内。因为这个数值上的特征,我们需要的浮点数的精度也不需要太高了。
32 位浮点数的精度,差不多可以到 1/1600 万。如果我们用 8 位或者 16 位表示浮点数,也能把精度放到 2^6 或者 2^12,也就是 1/64 或者 1/4096。在深度学习里,常常够用了。特别是在模型推断的时候,要求的计算精度,往往可以比模型训练低。所以,8 Bits 的矩阵乘法器,就可以放下更多的计算量,使得 TPU 的推断速度更快。
实际效果
一方面,在性能上,TPU 比现在的 CPU、GPU 在深度学习的推断任务上,要快 15~30 倍。而在能耗比上,更是好出 30~80 倍。另一方面,Google 已经用 TPU 替换了自家数据中心里 95% 的推断任务,可谓是拿自己的实际业务做了一个明证。

若有收获,就点个赞吧
0 人点赞
