ALI
为打破数据孤岛,创造更大的数据价值,阿里设计了OneEntity来提供全域数据与服务。OneEntity体系主要包含统一实体、全域标签、全域关系、全域行为4大类。
01标签分类
其中GProfile全域标签的分类,将“人”的立体刻画划分为“人的核心属性”和“人的向往与需求”2大部分,具体包含4大类:
人的核心属性,可分为自然属性、社会属性。
-自然属性:是指人的肉体存在及其特征,是人自出生后自然存在的,一般不会因人为因素发生较大的改变。例如“性别”“生肖”“年龄”“身高”“体重”等。
-社会属性:指人在实践活动基础上产生的一切社会关系的总和。人一旦进入社会就会产生社会属性。例如经济状况、家庭状况、社会地位、政治宗教、地理位置、价值观等。
人的向往与需求,可分为兴趣偏好、行为消费偏好。
-兴趣偏好:是人堆非物化对象的内在心理向往与外在行为表达,是一种法子内心的本能喜好,与物质无必然关系。例如渴望爱情、需要安全感、讨厌脏乱环境等。
-行为消费偏好:是人对物化对象的需求与外在行为表达,涉及各行业,与物质世界存在千丝万缕的联系。例如母婴行业偏好、美妆行业偏好、洗护行业偏好、家装行业偏好等。
在以上四大类的基础上,我们又尝试根据不同的业务形态进一步细分二级、三级分类。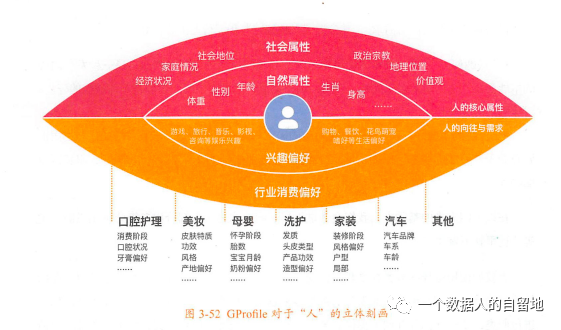
02标签萃取
标签的萃取工作包含:数据采集;清洗,去噪声并统一;反复试用并确定最佳算法及模型;为模型选择计算因子并对模型中的每一个计算因子调配权重;产出标签质量评估报告以辅助验收。
我们随机抽查了若干个在用的标签,预估工作量和工作周期,一个有价值的标签的萃取,平均耗时2周。
慢的主要原因,一是由于萃取流程复杂,每个标签萃取都依赖底层的基础数据,而较少依赖上一层汇总的数据中间层数据;二是大量重复的人力,对应的标签萃取逻辑时可以复用的,包含算法的选择、模型训练和计算因子的加权等,但由于不同人来做,造成了很多重复工作。
标签萃取过程复杂,那有什么可以参考的流程呢?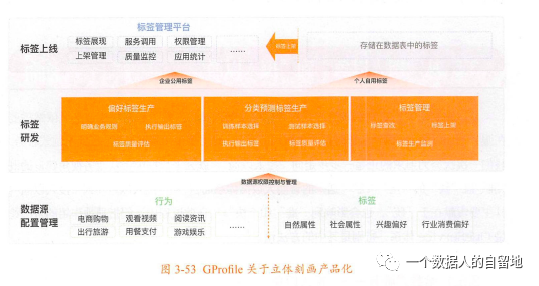
首先,数据源层面:建设一套完整的数据源,以OneEntity体系为核心,将OneEntity相关实体及其行为全部串联起来,与存量的标签一起作为数据源。
其次,标签计算层面:将标签萃取逻辑沉淀为2种,分别对应到偏好类标签和分类预测类标签的工具型产品的生产过程中,包含计算因子、权重等业务规则、数据样本选择、模型与算法选择等。
最后,标签监测层面:沉淀质量评估报告和生产监测、上线等管理流程。
当一整套工具型产品上线之后,批量生产十几个同类型标签只需要2天左右,这是因为在补足数据源、确定业务规则、选择数据样本、选择算法与模型的过程中,减少了大量的代码开发与模型训练的工作。
在这个过程中,参与的角色也发生了变化,从原本的以数据产品经理、数仓工程师、数据科学家为主导,转变为对业务更为熟悉的业务人员、数据分析师为主导。
WANGYI
网易大数据融合用户娱乐、电商购物、教育、新闻资讯、通讯等多行业10+产品线,构建起全域用户画像数据,目前总标签1000+,ID量URS、phone、idfa、IMEI、oaid等均达到忆级。
01标签分类
1.基础标签:
性别、年龄、教育背景、生活习惯(早起晚起)、地理位置(POI信息)、职业状况、经济情况(有车有房)、设备信息(手机、运营商等)、会员信息(会员等级)、衍生信息。
其中衍生标签,如评估是否已婚,在原由标签体系下没有此类标签,但可通过多个标签进行组合生成新的标签,包含是否有小孩、30岁等条件组合。
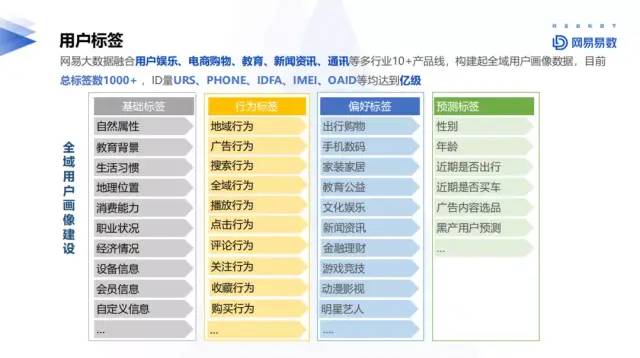
2. 行为标签
包含地域、广告、搜过、播放、点击、评论、关注、收藏、购买等维度。
3. 偏好标签
包含出行购物、手机数码、家装家居、教育公益、文化娱乐、新闻资讯、金融理财、游戏竞技、动漫影视、明星艺人等维度
4. 预测标签
包含利用算法进行预测生成的标签,包含是否出行、是否买车等标签。
注意:
1. 标签的枚举值十分重要,业务分析过程中很容易出现枚举值的偏差,不符合实际业务逻辑
2. 注意标签之间的冲突,如年龄15岁,学历却是博士或者有小孩
02标签计算
预测类标签案例:性别,主要包含三种方案:
1. 标签传播:根据用户在各个业务场景,如母婴商品点击行为,进行item标记,构建user-item的兴趣网络进行 Graph Embedding,最后进行分类,预测用户的性别。
语义分析:利用NLP算法对用户昵称进行语义分析
自行填写:利用业务属性自行填写的内容进行判断,此处需对数据质量进行过滤,排除如生日为1990-01-01的参数异常值信息。

基于上述三类算法特征结果集,对模型进行融合,然后对用户的性别进行预测,其准确率在0.6以上。
注意:需要突破的地方在于特征的稀疏性,因为ID-mapping打通后,数据覆盖率仅20%左右,严重影响了模型的整体效果。car family
用户画像的构建就是把用户标签分列到不同的类里面,这些类都是什么,彼此之间的联系,就构成了标签体系。
01按用途分类
1.人口属性:
用户自然属性、用户会员、用户所属年代、用户价值登记、是否增换购用户、用户分群、UVN-B用户分群、用户分层、用户流失预警
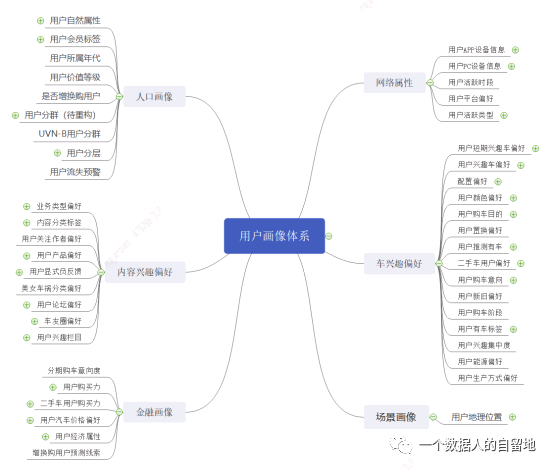
2.网络属性:
用户APP设备信息、用户PC设备信息、用户活跃时段、用户平台偏好、用户活跃类型
3.内容兴趣偏好:
业务类型偏好、内容分类标签、用户关注作者偏好、用户产品偏好、用户显式负反馈、用户论坛偏好、车友圈偏好、用户兴趣栏目
4.车兴趣偏好 :
用户短期兴趣车偏好、用户兴趣车偏好、配置偏好、用户颜色偏好、用户购车目的、用户置换偏好、用户推荐有车、二手车用户偏好、用户购车意向、用户新旧偏好、用户购车阶段、用户有车标签、用户兴趣集中度、用户能源偏好、用户生产方式偏好
5.金融画像:
分期购车意向度、用户购买力、二手车用户购买力、用户汽车价格偏好、用户经济属性、增换购用户预测线索
6.场景画像:
用户地理位置
02按统计方式分类
1.统计类标签
统计类标签,通过业务规则,将业务问题转化为数据口径实现。如收藏列表、 搜索关键词、保险到期时间、是否下过线索、30天内访问xx次等。
2.兴趣类标签
兴趣类标签,基于兴趣迁移模型构建用户标签。综合考虑特征、特征权重、距今时间、行为次数等因素,用户兴趣标签构建公式如下:
用户兴趣标签=行为类型权重时间衰减行为次
-特征:需要结合业务选择,如浏览、搜索、线索、对比、互动、点击、有车等行为。
-权重:用户在平台上发生的行为具体到用户标签层面有着不同的行为权重,一般而言,行为发生的成本越高,权重越大。可以由业务人员确定,也可以采用TF-IDF技术分析得出。
-时间衰减:用户行为收时间的影响不断衰减,距离现在越远,对用户兴趣的影响越低,这里采用牛顿冷却定律的思想拟合衰减系数,衰减周期结合业务制定。
-行为次数:在固定时间周期内行为发生的次数越多,兴趣倾向越重。
3.模型类标签
基于机器学习方法进行数据建模预测用户的标签,这类标签在标签体系中占比较少,其实现难度高,开发成本高。
例如:
-是否有车:基于RF+LR模型实现
-常驻地:基于GPS聚类获取,采用DBSCAN
-购车转化:GBDT
-用户分群:KMENAS聚类产生
03按时效分类
从数据时效上,可分为离线画像和实时画像。离线与实时采用的构建思想相同,不同之处在于:
-离线画像:描述用户长期的习惯;
-实时画像:描述用户当下的兴趣,会随时间的改变而发生变更;

若有收获,就点个赞吧
0 人点赞
