- 使用Prometheus和Grafana监控kubernetes集群
k8s-centos8u2-集群-kubernetes集群监控与告警
使用Prometheus和Grafana监控kubernetes集群
1 prometheus概念
由于docker容器的特殊性,传统的zabbix无法对k8s集群内的docker状态进行监控,所以需要使用prometheus来进行监控。
prometheus官网:官网地址
1.1 Prometheus的特点
- 多维度数据模型,使用时间序列数据库TSDB而不使用mysql。
- 灵活的查询语言PromQL。
- 不依赖分布式存储,单个服务器节点是自主的。
- 主要基于HTTP的pull方式主动采集时序数据。
- 也可通过pushgateway获取主动推送到网关的数据。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。
1.2 基本原理
1.2.1 原理说明
- Prometheus的基本原理是通过各种exporter提供的HTTP协议接口周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。
- 不需要任何SDK或者其他的集成过程,非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。
- 互联网公司常用的组件大部分都有exporter可以直接使用,如Nginx、MySQL、Linux系统信息等。
1.2.2 架构图
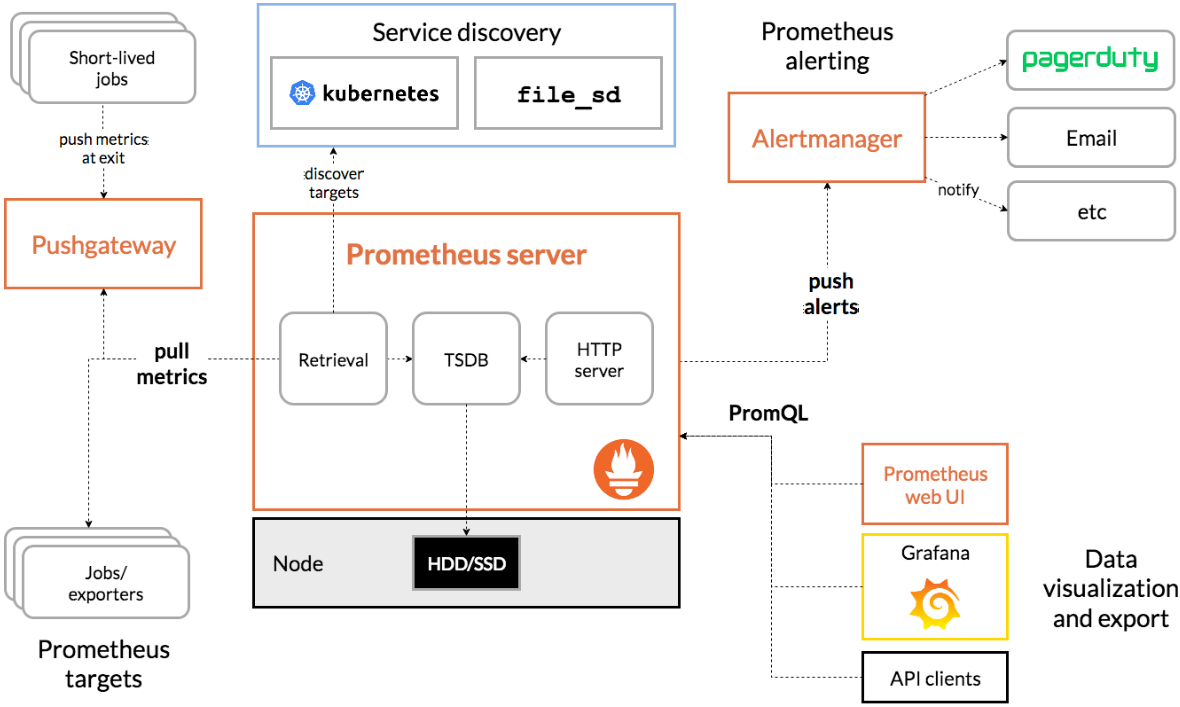
1.2.3 三大套件
Server主要负责数据采集和存储,提供PromQL查询语言的支持。Alertmanager警告管理器,用来进行报警。Push Gateway支持临时性Job主动推送指标的中间网关。
1.2.4 架构服务过程
- Prometheus Daemon负责定时去目标上抓取metrics(指标)数据
每个抓取目标需要暴露一个http服务的接口给它定时抓取。
支持通过配置文件、文本文件、Zookeeper、DNS SRV Lookup等方式指定抓取目标。 - PushGateway用于Client主动推送metrics到PushGateway
而Prometheus只是定时去Gateway上抓取数据。
适合一次性、短生命周期的服务。 - Prometheus在TSDB数据库存储抓取的所有数据
通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。 - Prometheus通过PromQL和其他API可视化地展示收集的数据。
支持Grafana、Promdash等方式的图表数据可视化。
Prometheus还提供HTTP API的查询方式,自定义所需要的输出。 - Alertmanager是独立于Prometheus的一个报警组件
支持Prometheus的查询语句,提供十分灵活的报警方式。
1.2.5 常用的exporter
prometheus不同于zabbix,没有agent,使用的是针对不同服务的exporter。正常情况下,监控k8s集群及node,pod,常用的exporter有四个:
kube-state-metrics
收集k8s集群master&etcd等基本状态信息node-exporter
收集k8s集群node信息cadvisor
收集k8s集群docker容器内部使用资源信息blackbox-exporter
收集k8s集群docker容器服务是否存活
1.3 部署软件说明
| 镜像 | 官方地址 | github地址 | 部署 |
|---|---|---|---|
| quay.io/coreos/kube-state-metrics:v1.5.0 | https://quay.io/repository/coreos/kube-state-metrics?tab=info | https://github.com/kubernetes/kube-state-metrics | Deployment |
| prom/node-exporter:v0.15.0 | https://hub.docker.com/r/prom/node-exporter | https://github.com/prometheus/node_exporter | DaemonSet |
| google/cadvisor:v0.28.3 | https://hub.docker.com/r/google/cadvisor | https://github.com/google/cadvisor | DaemonSet |
| prom/blackbox-exporter:v0.15.1 | https://hub.docker.com/r/prom/blackbox-exporter | https://github.com/prometheus/blackbox_exporter | Deployment |
| prom/prometheus:v2.14.0 | https://hub.docker.com/r/prom/prometheus | https://github.com/prometheus/prometheus | nodeName: vms21.cos.com |
| grafana/grafana:5.4.2 | https://grafana.com/ https://hub.docker.com/r/grafana/grafana | https://github.com/grafana/grafana | nodeName: vms22.cos.com |
| docker.io/prom/alertmanager:v0.14.0 | https://hub.docker.com/r/prom/alertmanager | https://github.com/prometheus/alertmanager | Deployment |
在使用较新版本出现问题时,使用较低版本,参考以上镜像版本。
2 部署kube-state-metrics
运维主机vms200
准备kube-state-metrics镜像
官方quay.io地址:https://quay.io/repository/coreos/kube-state-metrics?tab=info github地址:https://github.com/kubernetes/kube-state-metrics
[root@vms200 ~]# docker pull quay.io/coreos/kube-state-metrics:v1.5.0v1.5.0: Pulling from coreos/kube-state-metricscd784148e348: Pull completef622528a393e: Pull completeDigest: sha256:b7a3143bd1eb7130759c9259073b9f239d0eeda09f5210f1cd31f1a530599ea1Status: Downloaded newer image for quay.io/coreos/kube-state-metrics:v1.5.0quay.io/coreos/kube-state-metrics:v1.5.0[root@vms200 ~]# docker pull quay.io/coreos/kube-state-metrics:v1.9.7...[root@vms200 ~]# docker images | grep kube-state-metricsquay.io/coreos/kube-state-metrics v1.9.7 6497f02dbdad 3 months ago 32.8MBquay.io/coreos/kube-state-metrics v1.5.0 91599517197a 20 months ago 31.8MB[root@vms200 ~]# docker tag 6497f02dbdad harbor.op.com/public/kube-state-metrics:v1.9.7[root@vms200 ~]# docker tag quay.io/coreos/kube-state-metrics:v1.5.0 harbor.op.com/public/kube-state-metrics:v1.5.0[root@vms200 ~]# docker push harbor.op.com/public/kube-state-metrics:v1.9.7The push refers to repository [harbor.op.com/public/kube-state-metrics]d1ce60962f06: Pushed0d1435bd79e4: Mounted from public/metrics-serverv1.9.7: digest: sha256:2f82f0da199c60a7699c43c63a295c44e673242de0b7ee1b17c2d5a23bec34cb size: 738[root@vms200 ~]# docker push harbor.op.com/public/kube-state-metrics:v1.5.0The push refers to repository [harbor.op.com/public/kube-state-metrics]5b3c36501a0a: Pushed7bff100f35cb: Pushedv1.5.0: digest: sha256:16e9a1d63e80c19859fc1e2727ab7819f89aeae5f8ab5c3380860c2f88fe0a58 size: 739
准备资源配置清单
yaml下载要使用raw格式的地址
v1.9.7版本
v1.9.7:https://github.com/kubernetes/kube-state-metrics/tree/v1.9.7/examples/standard
[root@vms200 ~]# cd /data/k8s-yaml/[root@vms200 k8s-yaml]# mkdir kube-state-metrics[root@vms200 k8s-yaml]# cd kube-state-metrics[root@vms200 kube-state-metrics]# mkdir v1.9.7[root@vms200 v1.9.7]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/v1.9.7/examples/standard/service-account.yaml[root@vms200 v1.9.7]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/v1.9.7/examples/standard/service.yaml[root@vms200 v1.9.7]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/v1.9.7/examples/standard/deployment.yaml[root@vms200 v1.9.7]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/v1.9.7/examples/standard/cluster-role.yaml[root@vms200 v1.9.7]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/v1.9.7/examples/standard/cluster-role-binding.yaml
v1.9.7资源配置清单文件:/data/k8s-yaml/kube-state-metrics目录
rbac-v1.9.7.yaml(合并service-account.yaml、cluster-role.yaml、cluster-role-binding.yaml)
apiVersion: v1kind: ServiceAccountmetadata:labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: v1.9.7name: kube-state-metricsnamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: v1.9.7name: kube-state-metricsrules:- apiGroups:- ""resources:- configmaps- secrets- nodes- pods- services- resourcequotas- replicationcontrollers- limitranges- persistentvolumeclaims- persistentvolumes- namespaces- endpointsverbs:- list- watch- apiGroups:- extensionsresources:- daemonsets- deployments- replicasets- ingressesverbs:- list- watch- apiGroups:- appsresources:- statefulsets- daemonsets- deployments- replicasetsverbs:- list- watch- apiGroups:- batchresources:- cronjobs- jobsverbs:- list- watch- apiGroups:- autoscalingresources:- horizontalpodautoscalersverbs:- list- watch- apiGroups:- authentication.k8s.ioresources:- tokenreviewsverbs:- create- apiGroups:- authorization.k8s.ioresources:- subjectaccessreviewsverbs:- create- apiGroups:- policyresources:- poddisruptionbudgetsverbs:- list- watch- apiGroups:- certificates.k8s.ioresources:- certificatesigningrequestsverbs:- list- watch- apiGroups:- storage.k8s.ioresources:- storageclasses- volumeattachmentsverbs:- list- watch- apiGroups:- admissionregistration.k8s.ioresources:- mutatingwebhookconfigurations- validatingwebhookconfigurationsverbs:- list- watch- apiGroups:- networking.k8s.ioresources:- networkpoliciesverbs:- list- watch---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: v1.9.7name: kube-state-metricsroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metricssubjects:- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system
deployment-v1.9.7.yaml(修改deployment.yaml)
apiVersion: apps/v1kind: Deploymentmetadata:labels:grafanak8sapp: "true"app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: v1.9.7name: kube-state-metricsnamespace: kube-systemspec:replicas: 1selector:matchLabels:grafanak8sapp: "true"app.kubernetes.io/name: kube-state-metricstemplate:metadata:labels:grafanak8sapp: "true"app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: v1.9.7spec:containers:- image: harbor.op.com/public/kube-state-metrics:v1.9.7imagePullPolicy: IfNotPresentlivenessProbe:httpGet:path: /healthzport: 8080initialDelaySeconds: 5timeoutSeconds: 5name: kube-state-metricsports:- containerPort: 8080name: http-metrics- containerPort: 8081name: telemetryreadinessProbe:httpGet:path: /port: 8081initialDelaySeconds: 5timeoutSeconds: 5imagePullSecrets:- name: harbornodeSelector:kubernetes.io/os: linuxserviceAccountName: kube-state-metrics
说明:修改image、增加imagePullPolicy、增加imagePullSecrets
v1.5.0版本
v1.5.0:https://github.com/kubernetes/kube-state-metrics/tree/release-1.5/kubernetes
[root@vms200 kube-state-metrics]# mkdir v1.5.0[root@vms200 kube-state-metrics]# cd v1.5.0/[root@vms200 v1.5.0]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/release-1.5/kubernetes/kube-state-metrics-cluster-role-binding.yaml[root@vms200 v1.5.0]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/release-1.5/kubernetes/kube-state-metrics-cluster-role.yaml[root@vms200 v1.5.0]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/release-1.5/kubernetes/kube-state-metrics-deployment.yaml[root@vms200 v1.5.0]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/release-1.5/kubernetes/kube-state-metrics-role-binding.yaml[root@vms200 v1.5.0]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/release-1.5/kubernetes/kube-state-metrics-role.yaml[root@vms200 v1.5.0]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/release-1.5/kubernetes/kube-state-metrics-service-account.yaml[root@vms200 v1.5.0]# wget https://raw.githubusercontent.com/kubernetes/kube-state-metrics/release-1.5/kubernetes/kube-state-metrics-service.yaml
v1.5.0资源配置清单文件:/data/k8s-yaml/kube-state-metrics目录
rbac.yaml
[root@vms200 ~]# cd /data/k8s-yaml/[root@vms200 k8s-yaml]# mkdir kube-state-metrics[root@vms200 k8s-yaml]# cd kube-state-metrics[root@vms200 kube-state-metrics]# vi rbac.yaml
apiVersion: v1kind: ServiceAccountmetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: kube-state-metricsnamespace: kube-system---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: kube-state-metricsrules:- apiGroups:- ""resources:- configmaps- secrets- nodes- pods- services- resourcequotas- replicationcontrollers- limitranges- persistentvolumeclaims- persistentvolumes- namespaces- endpointsverbs:- list- watch- apiGroups:- extensionsresources:- daemonsets- deployments- replicasetsverbs:- list- watch- apiGroups:- appsresources:- statefulsetsverbs:- list- watch- apiGroups:- batchresources:- cronjobs- jobsverbs:- list- watch- apiGroups:- autoscalingresources:- horizontalpodautoscalersverbs:- list- watch---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: kube-state-metricsroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metricssubjects:- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system
deployment.yaml
apiVersion: apps/v1kind: Deploymentmetadata:annotations:deployment.kubernetes.io/revision: "2"labels:grafanak8sapp: "true"app: kube-state-metricsname: kube-state-metricsnamespace: kube-systemspec:selector:matchLabels:grafanak8sapp: "true"app: kube-state-metricsstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:creationTimestamp: nulllabels:grafanak8sapp: "true"app: kube-state-metricsspec:containers:- image: harbor.op.com/public/kube-state-metrics:v1.5.0name: kube-state-metricsports:- containerPort: 8080name: http-metricsprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /healthzport: 8080scheme: HTTPinitialDelaySeconds: 5periodSeconds: 10successThreshold: 1timeoutSeconds: 5imagePullPolicy: IfNotPresentimagePullSecrets:- name: harborrestartPolicy: AlwaysserviceAccount: kube-state-metricsserviceAccountName: kube-state-metrics
应用资源配置清单
任意一台运算节点上:
v1.5.0
[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/kube-state-metrics/rbac.yamlserviceaccount/kube-state-metrics createdclusterrole.rbac.authorization.k8s.io/kube-state-metrics createdclusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/kube-state-metrics/deployment.yamldeployment.apps/kube-state-metrics created
v1.9.7
[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/kube-state-metrics/rbac-v1.9.7.yamlserviceaccount/kube-state-metrics createdclusterrole.rbac.authorization.k8s.io/kube-state-metrics createdclusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/kube-state-metrics/deployment-v1.9.7.yamldeployment.apps/kube-state-metrics created
检查启动情况
v1.5.0
[root@vms22 ~]# kubectl get pods -n kube-system -o wide |grep kube-state-metricskube-state-metrics-5ff77848c6-9grj9 1/1 Running 0 101s 172.26.22.3 vms22.cos.com <none> <none>[root@vms22 ~]# curl http://172.26.22.3:8080/healthzok
v1.9.7
[root@vms21 ~]# kubectl get pods -n kube-system -o wide |grep kube-state-metricskube-state-metrics-5776ff76f-4f6dk 1/1 Running 0 20s 172.26.22.3 vms22.cos.com <none> <none>[root@vms21 ~]# curl http://172.26.22.3:8080/healthzOK[root@vms21 ~]#[root@vms21 ~]# curl http://172.26.22.3:8081<html><head><title>Kube-State-Metrics Metrics Server</title></head><body><h1>Kube-State-Metrics Metrics</h1><ul><li><a href='/metrics'>metrics</a></li></ul></body></html>
3 部署node-exporter
运维主机vms200上:
准备node-exporter镜像
官方dockerhub地址:https://hub.docker.com/r/prom/node-exporter github地址:https://github.com/prometheus/node_exporter
[root@vms200 ~]# docker pull prom/node-exporter:v1.0.1v1.0.1: Pulling from prom/node-exporter86fa074c6765: Pull completeed1cd1c6cd7a: Pull completeff1bb132ce7b: Pull completeDigest: sha256:cf66a6bbd573fd819ea09c72e21b528e9252d58d01ae13564a29749de1e48e0fStatus: Downloaded newer image for prom/node-exporter:v1.0.1docker.io/prom/node-exporter:v1.0.1[root@vms200 ~]# docker tag docker.io/prom/node-exporter:v1.0.1 harbor.op.com/public/node-exporter:v1.0.1[root@vms200 ~]# docker push harbor.op.com/public/node-exporter:v1.0.1
准备资源配置清单
[root@vms200 ~]# mkdir /data/k8s-yaml/node-exporter && cd /data/k8s-yaml/node-exporter
- 由于node-exporter是监控node的,需要每个节点启动一个,所以使用ds控制器
- 主要用途就是将宿主机的
/proc、sys目录挂载给容器,使容器能获取node节点宿主机信息
/data/k8s-yaml/node-exporter/node-exporter-ds.yaml
kind: DaemonSetapiVersion: apps/v1metadata:name: node-exporternamespace: kube-systemlabels:daemon: "node-exporter"grafanak8sapp: "true"spec:selector:matchLabels:daemon: "node-exporter"grafanak8sapp: "true"template:metadata:name: node-exporterlabels:daemon: "node-exporter"grafanak8sapp: "true"spec:containers:- name: node-exporterimage: harbor.op.com/public/node-exporter:v1.0.1imagePullPolicy: IfNotPresentargs:- --path.procfs=/host_proc- --path.sysfs=/host_sysports:- name: node-exporterhostPort: 9100containerPort: 9100protocol: TCPvolumeMounts:- name: sysreadOnly: truemountPath: /host_sys- name: procreadOnly: truemountPath: /host_procimagePullSecrets:- name: harborrestartPolicy: AlwayshostNetwork: truevolumes:- name: prochostPath:path: /proctype: ""- name: syshostPath:path: /systype: ""
应用资源配置清单
任意运算节点上:
[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/node-exporter/node-exporter-ds.yamldaemonset.apps/node-exporter created
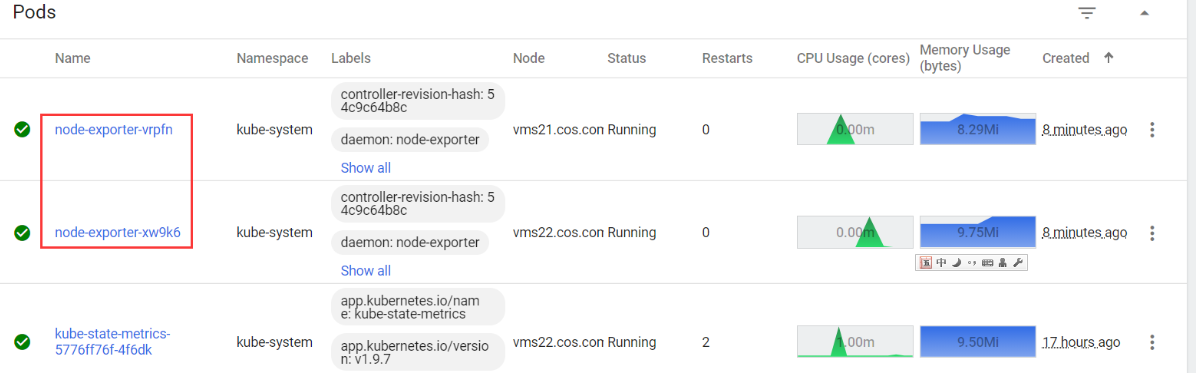
- 检查
[root@vms21 ~]# netstat -luntp | grep 9100tcp6 0 0 :::9100 :::* LISTEN 3711/node_exporter[root@vms21 ~]# kubectl get pod -n kube-system -o wide|grep node-exporternode-exporter-vrpfn 1/1 Running 0 2m8s 192.168.26.21 vms21.cos.com <none> <none>node-exporter-xw9k6 1/1 Running 0 2m8s 192.168.26.22 vms22.cos.com <none> <none>
[root@vms21 ~]# curl -s http://192.168.26.21:9100/metrics | more# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.# TYPE go_gc_duration_seconds summarygo_gc_duration_seconds{quantile="0"} 0go_gc_duration_seconds{quantile="0.25"} 0go_gc_duration_seconds{quantile="0.5"} 0go_gc_duration_seconds{quantile="0.75"} 0go_gc_duration_seconds{quantile="1"} 0go_gc_duration_seconds_sum 0go_gc_duration_seconds_count 0...[root@vms21 ~]# curl -s http://192.168.26.22:9100/metrics | more# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.# TYPE go_gc_duration_seconds summarygo_gc_duration_seconds{quantile="0"} 0go_gc_duration_seconds{quantile="0.25"} 0go_gc_duration_seconds{quantile="0.5"} 0go_gc_duration_seconds{quantile="0.75"} 0go_gc_duration_seconds{quantile="1"} 0go_gc_duration_seconds_sum 0go_gc_duration_seconds_count 0# HELP go_goroutines Number of goroutines that currently exist....
- 在
dashboard查看
4 部署cadvisor
运维主机vms200上:
准备cadvisor镜像
官方dockerhub地址:https://hub.docker.com/r/google/cadvisor
官方github地址:https://github.com/google/cadvisor
[root@vms200 ~]# docker pull google/cadvisor:v0.33.0v0.33.0: Pulling from google/cadvisor169185f82c45: Pull completebd29476a29dd: Pull completea2eb18ca776e: Pull completeDigest: sha256:47f1f8c02a3acfab77e74e2ec7acc0d475adc180ddff428503a4ce63f3d6061bStatus: Downloaded newer image for google/cadvisor:v0.33.0docker.io/google/cadvisor:v0.33.0[root@vms200 ~]# docker pull google/cadvisorUsing default tag: latestlatest: Pulling from google/cadvisorff3a5c916c92: Pull complete44a45bb65cdf: Pull complete0bbe1a2fe2a6: Pull completeDigest: sha256:815386ebbe9a3490f38785ab11bda34ec8dacf4634af77b8912832d4f85dca04Status: Downloaded newer image for google/cadvisor:latestdocker.io/google/cadvisor:latest[root@vms200 ~]# docker images | grep cadvisorgoogle/cadvisor v0.33.0 752d61707eac 18 months ago 68.6MBgoogle/cadvisor latest eb1210707573 22 months ago 69.6MB[root@vms200 ~]# docker tag 752d61707eac harbor.op.com/public/cadvisor:v0.33.0[root@vms200 ~]# docker tag eb1210707573 harbor.op.com/public/cadvisor:v200912[root@vms200 ~]# docker images | grep cadvisorgoogle/cadvisor v0.33.0 752d61707eac 18 months ago 68.6MBharbor.op.com/public/cadvisor v0.33.0 752d61707eac 18 months ago 68.6MBgoogle/cadvisor latest eb1210707573 22 months ago 69.6MBharbor.op.com/public/cadvisor v200912 eb1210707573 22 months ago 69.6MB[root@vms200 ~]# docker push harbor.op.com/public/cadvisor:v0.33.0The push refers to repository [harbor.op.com/public/cadvisor]09c656718504: Pushed6a395a55089d: Pushed767f936afb51: Pushedv0.33.0: digest: sha256:47f1f8c02a3acfab77e74e2ec7acc0d475adc180ddff428503a4ce63f3d6061b size: 952[root@vms200 ~]# docker push harbor.op.com/public/cadvisor:v200912The push refers to repository [harbor.op.com/public/cadvisor]66b3c2e84199: Pushed9ea477e6d99e: Pushedcd7100a72410: Pushedv200912: digest: sha256:815386ebbe9a3490f38785ab11bda34ec8dacf4634af77b8912832d4f85dca04 size: 952
准备资源配置清单
[root@vms200 ~]# mkdir /data/k8s-yaml/cadvisor && cd /data/k8s-yaml/cadvisor
该exporter是通过和kubelet交互,取到Pod运行时的资源消耗情况,并将接口暴露给Prometheus。
- cadvisor由于要获取每个node上的pod信息,因此也需要使用daemonset方式运行
- cadvisor采用daemonset方式运行在node节点上,通过污点的方式排除master
- 同时将部分宿主机目录挂载到本地,如docker的数据目录
daemonset.yaml下载:https://github.com/google/cadvisor/tree/release-v0.33/deploy/kubernetes/base
[root@vms200 cadvisor]# vi /data/k8s-yaml/cadvisor/daemonset.yaml
apiVersion: apps/v1kind: DaemonSetmetadata:name: cadvisornamespace: kube-systemlabels:app: cadvisorspec:selector:matchLabels:name: cadvisortemplate:metadata:labels:name: cadvisorspec:hostNetwork: truetolerations:- key: node-role.kubernetes.io/mastereffect: NoSchedulecontainers:- name: cadvisorimage: harbor.op.com/public/cadvisor:v200912imagePullPolicy: IfNotPresentvolumeMounts:- name: rootfsmountPath: /rootfsreadOnly: true- name: var-runmountPath: /var/run- name: sysmountPath: /sysreadOnly: true- name: dockermountPath: /var/lib/dockerreadOnly: true- name: diskmountPath: /dev/diskreadOnly: trueports:- name: httpcontainerPort: 4194protocol: TCPreadinessProbe:tcpSocket:port: 4194initialDelaySeconds: 5periodSeconds: 10args:- --housekeeping_interval=10s- --port=4194terminationGracePeriodSeconds: 30volumes:- name: rootfshostPath:path: /- name: var-runhostPath:path: /var/run- name: syshostPath:path: /sys- name: dockerhostPath:path: /data/docker- name: diskhostPath:path: /dev/disk
修改运算节点软连接
所有运算节点上:vms21、vms22
[root@vms21 ~]# mount -o remount,rw /sys/fs/cgroup/[root@vms21 ~]# ln -s /sys/fs/cgroup/cpu,cpuacct/ /sys/fs/cgroup/cpuacct,cpu[root@vms21 ~]# ll /sys/fs/cgroup/ | grep cpulrwxrwxrwx 1 root root 11 Sep 11 19:21 cpu -> cpu,cpuacctlrwxrwxrwx 1 root root 11 Sep 11 19:21 cpuacct -> cpu,cpuacctlrwxrwxrwx 1 root root 27 Sep 12 10:25 cpuacct,cpu -> /sys/fs/cgroup/cpu,cpuacct/dr-xr-xr-x 6 root root 0 Sep 11 19:21 cpu,cpuacctdr-xr-xr-x 4 root root 0 Sep 11 19:21 cpuset
[root@vms22 ~]# mount -o remount,rw /sys/fs/cgroup/[root@vms22 ~]# ln -s /sys/fs/cgroup/cpu,cpuacct/ /sys/fs/cgroup/cpuacct,cpu[root@vms22 ~]# ll /sys/fs/cgroup/ | grep cpulrwxrwxrwx 1 root root 11 Sep 11 19:22 cpu -> cpu,cpuacctlrwxrwxrwx 1 root root 11 Sep 11 19:22 cpuacct -> cpu,cpuacctlrwxrwxrwx 1 root root 27 Sep 12 10:25 cpuacct,cpu -> /sys/fs/cgroup/cpu,cpuacct/dr-xr-xr-x 6 root root 0 Sep 11 19:22 cpu,cpuacctdr-xr-xr-x 4 root root 0 Sep 11 19:22 cpuset
- 原本是只读,现在改为可读可写;应用清单前,先在每个node上做好软连接,否则pod可能报错。
应用资源配置清单
任意运算节点上:
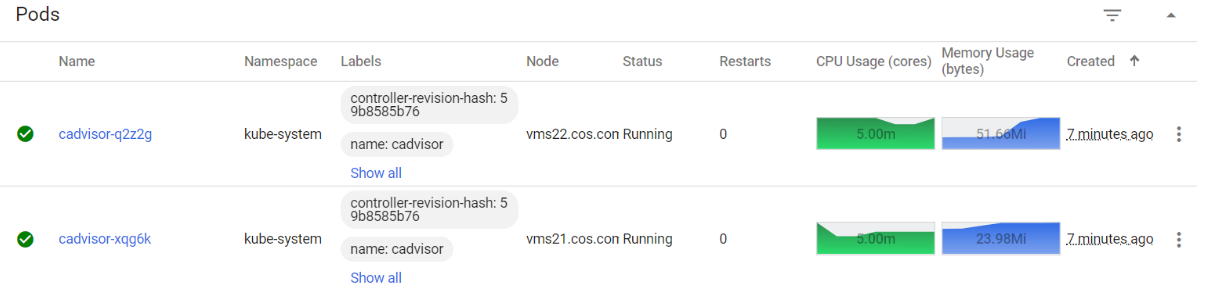
[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/cadvisor/daemonset.yamldaemonset.apps/cadvisor created[root@vms21 ~]# kubectl -n kube-system get pod -o wide|grep cadvisorcadvisor-q2z2g 0/1 Running 0 3s 192.168.26.22 vms22.cos.com <none> <none>cadvisor-xqg6k 0/1 Running 0 3s 192.168.26.21 vms21.cos.com <none> <none>[root@vms21 ~]# netstat -luntp|grep 4194tcp6 0 0 :::4194 :::* LISTEN 301579/cadvisor[root@vms21 ~]# kubectl get pod -n kube-system -l name=cadvisor -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATEScadvisor-q2z2g 1/1 Running 0 2m38s 192.168.26.22 vms22.cos.com <none> <none>cadvisor-xqg6k 1/1 Running 0 2m38s 192.168.26.21 vms21.cos.com <none> <none>[root@vms21 ~]# curl -s http://192.168.26.22:4194/metrics | more# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.# TYPE cadvisor_version_info gaugecadvisor_version_info{cadvisorRevision="8949c822",cadvisorVersion="v0.32.0",dockerVersion="19.03.12",kernelVersion="4.18.0-193.el8.x86_64",osVersion="Alpine Linux v3.7"} 1# HELP container_cpu_cfs_periods_total Number of elapsed enforcement period intervals.# TYPE container_cpu_cfs_periods_total counter
5 部署blackbox-exporter
运维主机vms200上:
准备blackbox-exporter镜像
官方dockerhub地址:https://hub.docker.com/r/prom/blackbox-exporter
官方github地址:https://github.com/prometheus/blackbox_exporter
[root@vms200 ~]# docker pull prom/blackbox-exporter:v0.17.0v0.17.0: Pulling from prom/blackbox-exporter0f8c40e1270f: Pull complete626a2a3fee8c: Pull completed018b30262bb: Pull complete2b24e2b7f642: Pull completeDigest: sha256:1d8a5c9ff17e2493a39e4aea706b4ea0c8302ae0dc2aa8b0e9188c5919c9bd9cStatus: Downloaded newer image for prom/blackbox-exporter:v0.17.0docker.io/prom/blackbox-exporter:v0.17.0[root@vms200 ~]# docker tag docker.io/prom/blackbox-exporter:v0.17.0 harbor.op.com/public/blackbox-exporter:v0.17.0[root@vms200 ~]# docker push harbor.op.com/public/blackbox-exporter:v0.17.0The push refers to repository [harbor.op.com/public/blackbox-exporter]d072d0db0848: Pushed42430a6dfa0e: Pushed7a151fe67625: Pushed1da8e4c8d307: Pushedv0.17.0: digest: sha256:d3e823580333ceedceadaa2bfea10c8efd4700c8ec0415df72f83c34e1f93314 size: 1155
准备资源配置清单
[root@vms200 ~]# mkdir /data/k8s-yaml/blackbox-exporter && cd /data/k8s-yaml/blackbox-exporter
ConfigMap
[root@vms200 blackbox-exporter]# vi /data/k8s-yaml/blackbox-exporter/configmap.yaml
apiVersion: v1kind: ConfigMapmetadata:labels:app: blackbox-exportername: blackbox-exporternamespace: kube-systemdata:blackbox.yml: |-modules:http_2xx:prober: httptimeout: 2shttp:valid_http_versions: ["HTTP/1.1", "HTTP/2"]valid_status_codes: [200,301,302]method: GETpreferred_ip_protocol: "ip4"tcp_connect:prober: tcptimeout: 2s
Deployment
[root@vms200 blackbox-exporter]# vi /data/k8s-yaml/blackbox-exporter/deployment.yaml
kind: DeploymentapiVersion: apps/v1metadata:name: blackbox-exporternamespace: kube-systemlabels:app: blackbox-exporterannotations:deployment.kubernetes.io/revision: "1"spec:replicas: 1selector:matchLabels:app: blackbox-exportertemplate:metadata:labels:app: blackbox-exporterspec:volumes:- name: configconfigMap:name: blackbox-exporterdefaultMode: 420containers:- name: blackbox-exporterimage: harbor.op.com/public/blackbox-exporter:v0.17.0args:- --config.file=/etc/blackbox_exporter/blackbox.yml- --log.level=debug- --web.listen-address=:9115ports:- name: blackbox-portcontainerPort: 9115protocol: TCPresources:limits:cpu: 200mmemory: 256Mirequests:cpu: 100mmemory: 50MivolumeMounts:- name: configmountPath: /etc/blackbox_exporterreadinessProbe:tcpSocket:port: 9115initialDelaySeconds: 5timeoutSeconds: 5periodSeconds: 10successThreshold: 1failureThreshold: 3imagePullPolicy: IfNotPresentimagePullSecrets:- name: harborrestartPolicy: Always
Service
[root@vms200 blackbox-exporter]# vi /data/k8s-yaml/blackbox-exporter/service.yaml
kind: ServiceapiVersion: v1metadata:name: blackbox-exporternamespace: kube-systemspec:selector:app: blackbox-exporterports:- protocol: TCPport: 9115name: http
Ingress
[root@vms200 blackbox-exporter]# vi /data/k8s-yaml/blackbox-exporter/ingress.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: blackbox-exporternamespace: kube-systemspec:rules:- host: blackbox.op.comhttp:paths:- backend:serviceName: blackbox-exporterservicePort: 9115
解析域名
vms11上
[root@vms11 ~]# vi /var/named/op.com.zone
...blackbox A 192.168.26.10
注意serial前滚一个序号
[root@vms11 ~]# systemctl restart named
检查:vms21上
[root@vms21 ~]# dig -t A blackbox.op.com 172.26.0.2 +short192.168.26.10
应用资源配置清单
任意运算节点上:
[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/blackbox-exporter/configmap.yamlconfigmap/blackbox-exporter created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/blackbox-exporter/deployment.yamldeployment.apps/blackbox-exporter created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/blackbox-exporter/service.yamlservice/blackbox-exporter created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/blackbox-exporter/ingress.yamlingress.extensions/blackbox-exporter created
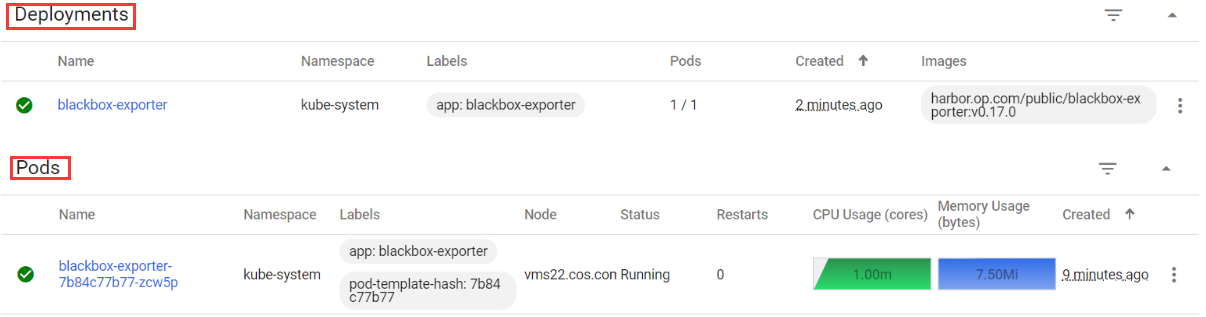
浏览器访问
http://blackbox.op.com/ 显示如下界面,表示blackbox已经运行成功。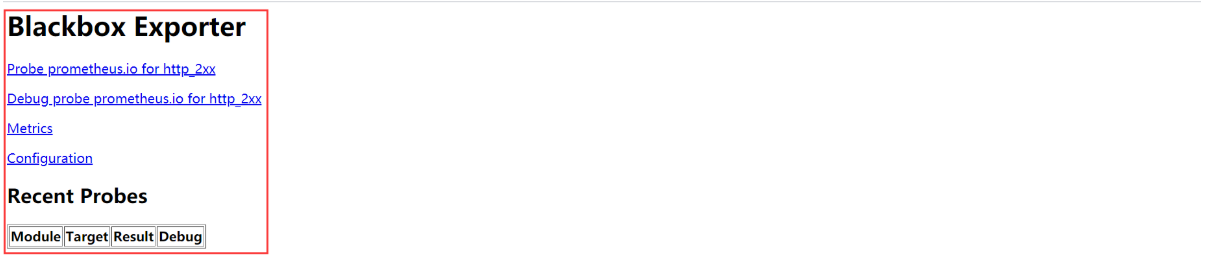
6 部署prometheus
运维主机vms200上:
准备prometheus镜像
官方dockerhub地址:https://hub.docker.com/r/prom/prometheus
官方github地址:https://github.com/prometheus/prometheus
[root@vms200 ~]# docker pull prom/prometheus:v2.21.0v2.21.0: Pulling from prom/prometheus...Digest: sha256:d43417c260e516508eed1f1d59c10c49d96bbea93eafb4955b0df3aea5908971Status: Downloaded newer image for prom/prometheus:v2.21.0docker.io/prom/prometheus:v2.21.0[root@vms200 ~]# docker tag prom/prometheus:v2.21.0 harbor.op.com/infra/prometheus:v2.21.0[root@vms200 ~]# docker push harbor.op.com/infra/prometheus:v2.21.0The push refers to repository [harbor.op.com/infra/prometheus]...v2.21.0: digest: sha256:f3ada803723ccbc443ebea19f7ab24d3323def496e222134bf9ed54ae5b787bd size: 2824
准备资源配置清单
运维主机vms200上:
[root@vms200 ~]# mkdir -p /data/k8s-yaml/prometheus && cd /data/k8s-yaml/prometheus
RBAC
[root@vms200 prometheus]# vi /data/k8s-yaml/prometheus/rbac.yaml
apiVersion: v1kind: ServiceAccountmetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: prometheusnamespace: infra---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: prometheusrules:- apiGroups:- ""resources:- nodes- nodes/metrics- services- endpoints- podsverbs:- get- list- watch- apiGroups:- ""resources:- configmapsverbs:- get- nonResourceURLs:- /metricsverbs:- get---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: prometheusroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: prometheussubjects:- kind: ServiceAccountname: prometheusnamespace: infra
Deployment
[root@vms200 prometheus]# vi /data/k8s-yaml/prometheus/deployment.yaml
Prometheus在生产环境中,一般采用一个单独的大内存node部署,采用污点让其它pod不会调度上来。本实验使用nodeName: vms21.cos.com来指定到192.168.26.21。--storage.tsdb.min-block-duration内存中缓存最新多少分钟的TSDB数据,生产中会缓存更多的数据。storage.tsdb.min-block-duration=10m只加载10分钟数据到内。--storage.tsdb.retentionTSDB数据保留的时间,生产中会保留更多的数据。storage.tsdb.retention=72h保留72小时数据。 加上--web.enable-lifecycle启用远程热加载配置文件,配置文件改变后不用重启prometheus。
调用指令是curl -X POST http://localhost:9090/-/reload。
apiVersion: apps/v1kind: Deploymentmetadata:annotations:deployment.kubernetes.io/revision: "5"labels:name: prometheusname: prometheusnamespace: infraspec:progressDeadlineSeconds: 600replicas: 1revisionHistoryLimit: 7selector:matchLabels:app: prometheusstrategy:rollingUpdate:maxSurge: 1maxUnavailable: 1type: RollingUpdatetemplate:metadata:labels:app: prometheusspec:nodeName: vms21.cos.comcontainers:- image: harbor.op.com/infra/prometheus:v2.21.0args:- --config.file=/data/etc/prometheus.yml- --storage.tsdb.path=/data/prom-db- --storage.tsdb.retention=72h- --storage.tsdb.min-block-duration=10m- --web.enable-lifecyclecommand:- /bin/prometheusname: prometheusports:- containerPort: 9090protocol: TCPresources:limits:cpu: 500mmemory: 2500Mirequests:cpu: 100mmemory: 100MivolumeMounts:- mountPath: /dataname: dataimagePullPolicy: IfNotPresentimagePullSecrets:- name: harborsecurityContext:runAsUser: 0dnsPolicy: ClusterFirstrestartPolicy: AlwaysserviceAccount: prometheusserviceAccountName: prometheusvolumes:- name: datanfs:server: vms200path: /data/nfs-volume/prometheus
Service
[root@vms200 prometheus]# vi /data/k8s-yaml/prometheus/service.yaml
apiVersion: v1kind: Servicemetadata:name: prometheusnamespace: infraspec:ports:- port: 9090protocol: TCPname: prometheusselector:app: prometheustype: ClusterIP
Ingress
[root@vms200 prometheus]# vi /data/k8s-yaml/prometheus/ingress.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:annotations:kubernetes.io/ingress.class: traefikname: prometheusnamespace: infraspec:rules:- host: prometheus.op.comhttp:paths:- backend:serviceName: prometheusservicePort: 9090
准备prometheus的配置文件
运维主机vms200上:
- 创建目录与拷贝证书
[root@vms200 ~]# mkdir -pv /data/nfs-volume/prometheus/{etc,prom-db}...[root@vms200 ~]# cd /data/nfs-volume/prometheus/etc[root@vms200 etc]# cp /opt/certs/{ca.pem,client.pem,client-key.pem} /data/nfs-volume/prometheus/etc/[root@vms200 etc]# lltotal 12-rw-r--r-- 1 root root 1338 Sep 12 16:22 ca.pem-rw------- 1 root root 1675 Sep 12 16:22 client-key.pem-rw-r--r-- 1 root root 1363 Sep 12 16:22 client.pem
- 准备配置
配置文件说明:此配置为通用配置,除第一个job
etcd是做的静态配置外,其他8个job都是做的自动发现。因此只需要修改etcd的配置后,就可以直接用于生产环境。
[root@vms200 etc]# vi /data/nfs-volume/prometheus/etc/prometheus.yml
global:scrape_interval: 15sevaluation_interval: 15sscrape_configs:- job_name: 'etcd'tls_config:ca_file: /data/etc/ca.pemcert_file: /data/etc/client.pemkey_file: /data/etc/client-key.pemscheme: httpsstatic_configs:- targets:- '192.168.26.12:2379'- '192.168.26.21:2379'- '192.168.26.22:2379'- job_name: 'kubernetes-apiservers'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2target_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- job_name: 'kubernetes-kubelet'kubernetes_sd_configs:- role: noderelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __address__replacement: ${1}:10255- job_name: 'kubernetes-cadvisor'kubernetes_sd_configs:- role: noderelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __address__replacement: ${1}:4194- job_name: 'kubernetes-kube-state'kubernetes_sd_configs:- role: podrelabel_configs:- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- source_labels: [__meta_kubernetes_pod_label_grafanak8sapp]regex: .*true.*action: keep- source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name']regex: 'node-exporter;(.*)'action: replacetarget_label: nodename- job_name: 'blackbox_http_pod_probe'metrics_path: /probekubernetes_sd_configs:- role: podparams:module: [http_2xx]relabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]action: keepregex: http- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path]action: replaceregex: ([^:]+)(?::\d+)?;(\d+);(.+)replacement: $1:$2$3target_label: __param_target- action: replacetarget_label: __address__replacement: blackbox-exporter.kube-system:9115- source_labels: [__param_target]target_label: instance- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- job_name: 'blackbox_tcp_pod_probe'metrics_path: /probekubernetes_sd_configs:- role: podparams:module: [tcp_connect]relabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]action: keepregex: tcp- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port]action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2target_label: __param_target- action: replacetarget_label: __address__replacement: blackbox-exporter.kube-system:9115- source_labels: [__param_target]target_label: instance- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- job_name: 'traefik'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]action: keepregex: traefik- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2target_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name
应用资源配置清单
任意运算节点上:
[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/prometheus/rbac.yamlserviceaccount/prometheus createdclusterrole.rbac.authorization.k8s.io/prometheus createdclusterrolebinding.rbac.authorization.k8s.io/prometheus created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/prometheus/deployment.yamldeployment.apps/prometheus created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/prometheus/service.yamlservice/prometheus created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/prometheus/ingress.yamlingress.extensions/prometheus created
解析域名
vms11上
[root@vms11 ~]# vi /var/named/op.com.zone
...prometheus A 192.168.26.10
注意serial前滚一个序号
[root@vms11 ~]# systemctl restart named[root@vms11 ~]# dig -t A prometheus.op.com 192.168.26.11 +short192.168.26.10
浏览器访问
- 先在
dashboard查看pod

- 访问:http://prometheus.op.com/ 如果能成功访问的话,表示启动成功
- 点击
Status>Configuration就是配置文件
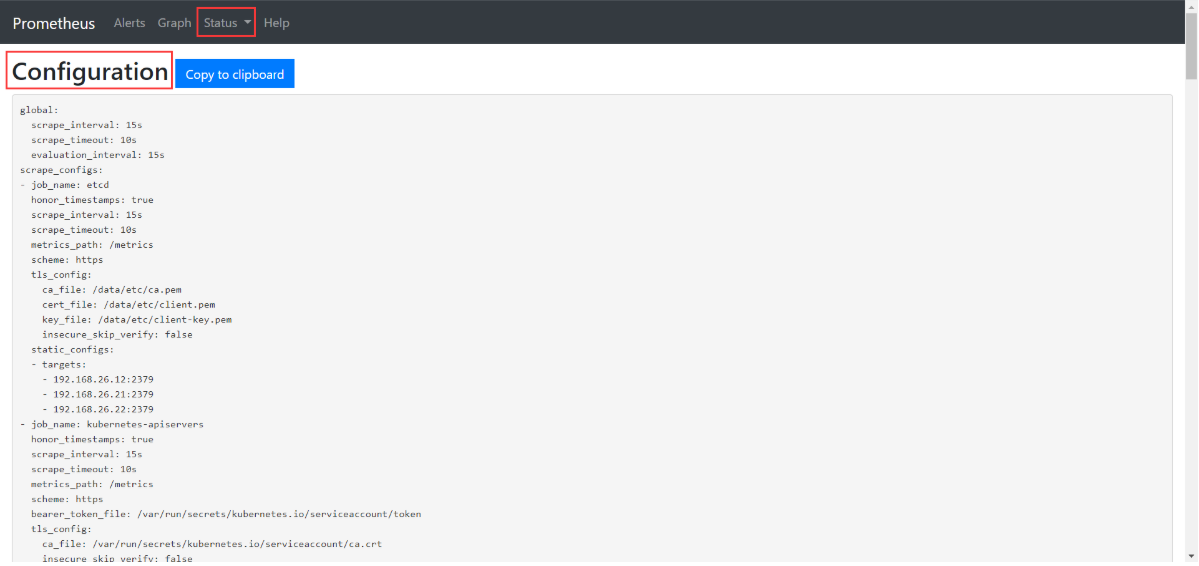
Prometheus配置文件解析
官方文档: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
- vms200:/data/nfs-volume/prometheus/etc/prometheus.yml
global:scrape_interval: 15s # 数据抓取周期,默认1mevaluation_interval: 15s # 估算规则周期,默认1mscrape_configs: # 抓取指标的方式,一个job就是一类指标的获取方式- job_name: 'etcd' # 指定etcd的指标获取方式,没指定scrape_interval会使用全局配置tls_config:ca_file: /data/etc/ca.pemcert_file: /data/etc/client.pemkey_file: /data/etc/client-key.pemscheme: https # 默认是http方式获取static_configs:- targets:- '192.168.26.12:2379'- '192.168.26.21:2379'- '192.168.26.22:2379'- job_name: 'kubernetes-apiservers'kubernetes_sd_configs:- role: endpoints # 目标资源类型,支持node、endpoints、pod、service、ingress等scheme: https # tls,bearer_token_file都是与apiserver通信时使用tls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs: # 对目标标签修改时使用- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keep # action支持:# keep,drop,replace,labelmap,labelkeep,labeldrop,hashmodregex: default;kubernetes;https- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2target_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- job_name: 'kubernetes-kubelet'kubernetes_sd_configs:- role: noderelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __address__replacement: ${1}:10255- job_name: 'kubernetes-cadvisor'kubernetes_sd_configs:- role: noderelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __address__replacement: ${1}:4194- job_name: 'kubernetes-kube-state'kubernetes_sd_configs:- role: podrelabel_configs:- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- source_labels: [__meta_kubernetes_pod_label_grafanak8sapp]regex: .*true.*action: keep- source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name']regex: 'node-exporter;(.*)'action: replacetarget_label: nodename- job_name: 'blackbox_http_pod_probe'metrics_path: /probekubernetes_sd_configs:- role: podparams:module: [http_2xx]relabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]action: keepregex: http- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path]action: replaceregex: ([^:]+)(?::\d+)?;(\d+);(.+)replacement: $1:$2$3target_label: __param_target- action: replacetarget_label: __address__replacement: blackbox-exporter.kube-system:9115- source_labels: [__param_target]target_label: instance- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- job_name: 'blackbox_tcp_pod_probe'metrics_path: /probekubernetes_sd_configs:- role: podparams:module: [tcp_connect]relabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]action: keepregex: tcp- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port]action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2target_label: __param_target- action: replacetarget_label: __address__replacement: blackbox-exporter.kube-system:9115- source_labels: [__param_target]target_label: instance- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name- job_name: 'traefik'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]action: keepregex: traefik- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2target_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_namealerting: # Alertmanager配置alertmanagers:- static_configs:- targets: ["alertmanager"]rule_files: # 引用外部的告警或者监控规则,类似于include- "/data/etc/rules.yml"
Prometheus监控内容及方法
Pod接入Exporter
- 当前实验部署的是通用的Exporter,其中
Kube-state-metrics是通过Kubernetes API采集信息,Node-exporter用于收集主机信息,这两个Exporter与Pod无关,部署完毕后直接使用即可。 - 根据Prometheus配置文件,可以看出Pod监控信息获取是通过标签(注释)选择器来实现的,给资源添加对应的标签或者注释来实现数据的监控。
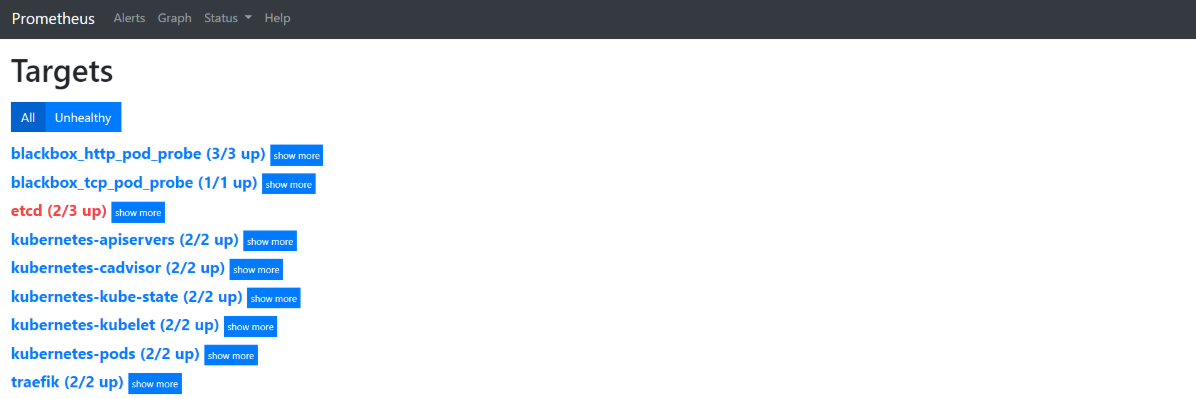
Targets - job-name
- 点击
Status>Targets,展示的就是在prometheus.yml中配置的job-name,这些targets基本可以满足监控收集数据的需求。
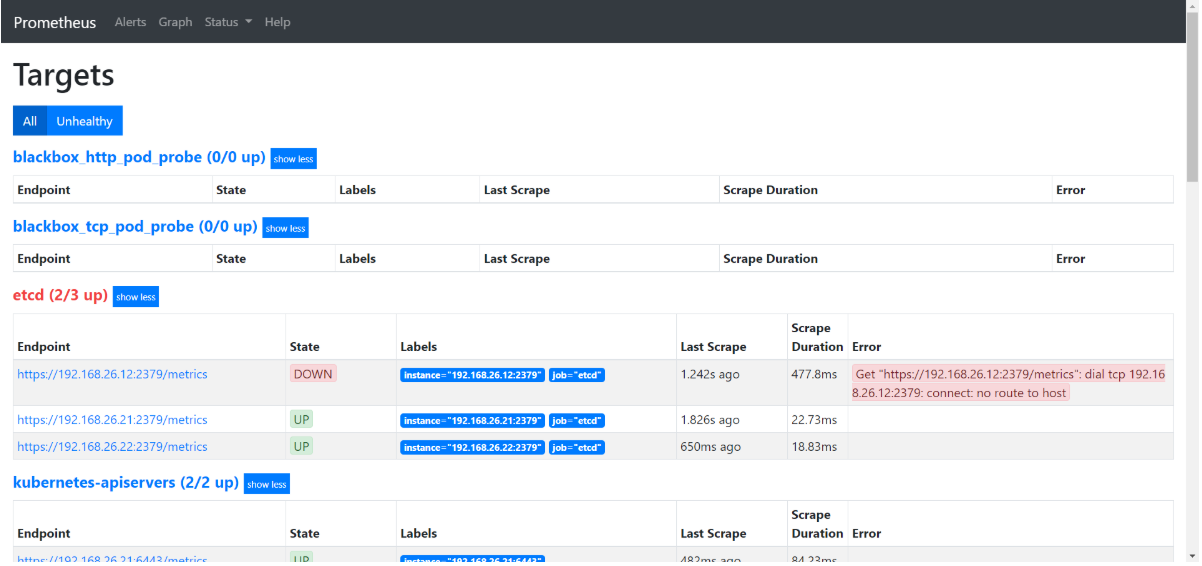
vms12服务器没启动,监控到了一个etcd为DOWN状态
- Targets(jobs):
show less
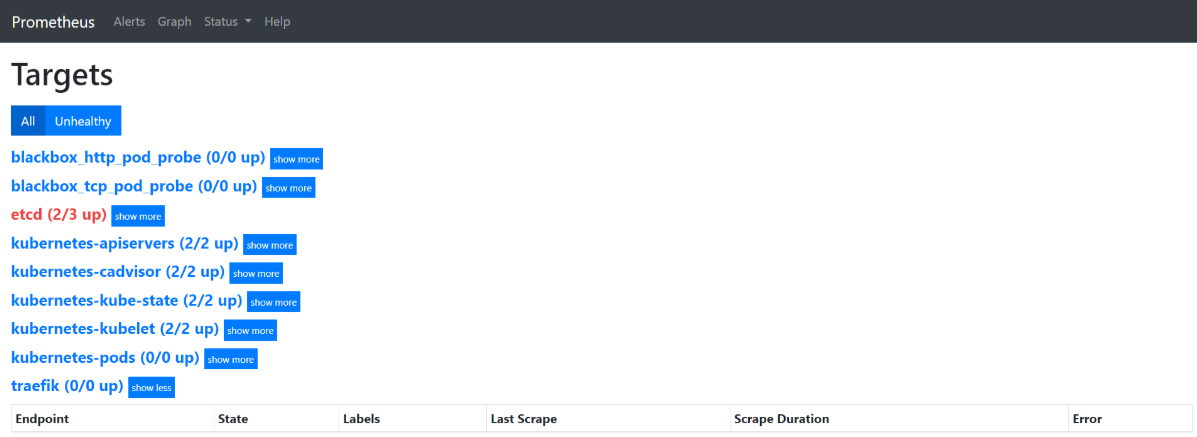
总共有9个job_name,有5个job-name已经被发现并获取数据;接下来就需要将剩下的4个job_name对应的服务纳入监控;纳入监控的方式是给需要收集数据的服务添加annotations。
etcd
监控etcd服务
| key | value |
|---|---|
| etcd_server_has_leader | 1 |
| etcd_http_failed_total | 1 |
| … | … |
kubernetes-apiserver
监控apiserver服务
kubernetes-kubelet
监控kubelet服务
kubernetes-kube-state
监控基本信息
- node-exporter> 监控Node节点信息
- kube-state-metrics> 监控pod信息
traefik
- 监控traefik-ingress-controller | key | value | | :—- | :—- | | traefik_entrypoint_requests_total{code=”200”,entrypoint=”http”,method=”PUT”,protocol=”http”} | 138 | | traefik_entrypoint_requests_total{code=”200”,entrypoint=”http”,method=”GET”,protocol=”http”} | 285 | | traefik_entrypoint_open_connections{entrypoint=”http”,method=”PUT”,protocol=”http”} | 1 | | … | … |
- Traefik接入:
在traefik的pod控制器上加annotations,并重启pod,监控生效。 (JSON格式)
"annotations": {"prometheus_io_scheme": "traefik","prometheus_io_path": "/metrics","prometheus_io_port": "8080"}
或在traefik的部署yaml文件中的spec.template.metadata加入注释,然后重启Pod。(yaml格式)
annotations:prometheus_io_scheme: traefikprometheus_io_path: /metricsprometheus_io_port: "8080"
blackbox*
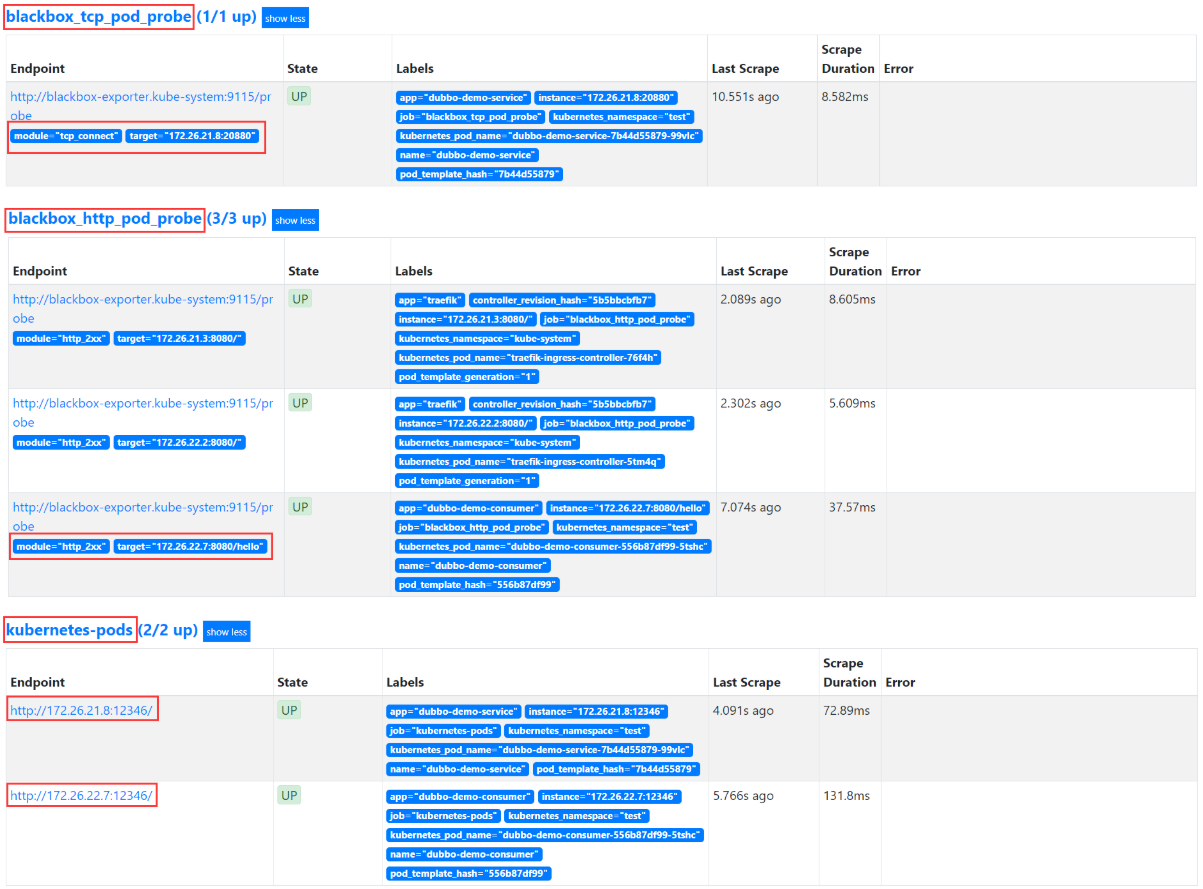
blackbox是检测容器内服务存活性的,也就是端口健康状态检查,分为tcp和http两种方法。能用http的情况尽量用http,没有提供http接口的服务才用tcp。
监控服务是否存活,检测TCP/HTTP服务状态
- blackbox_tcp_pod_porbe 监控tcp协议服务是否存活 | key | value | | :—- | :—- | | probe_success | 1 | | probe_ip_protocol | 4 | | probe_failed_due_to_regex | 0 | | probe_duration_seconds | 0.000597546 | | probe_dns_lookup_time_seconds | 0.00010898 |
接入Blackbox监控: 在pod控制器上加annotations,并重启pod,监控生效。(JSON格式)
"annotations": {"blackbox_port": "20880","blackbox_scheme": "tcp"}
- blackbox_http_pod_probe 监控http协议服务是否存活 | key | value | | :—- | :—- | | probe_success | 1 | | probe_ip_protocol | 4 | | probe_http_version | 1.1 | | probe_http_status_code | 200 | | probe_http_ssl | 0 | | probe_http_redirects | 1 | | probe_http_last_modified_timestamp_seconds | 1.553861888e+09 | | probe_http_duration_seconds{phase=”transfer”} | 0.000238343 | | probe_http_duration_seconds{phase=”tls”} | 0 | | probe_http_duration_seconds{phase=”resolve”} | 5.4095e-05 | | probe_http_duration_seconds{phase=”processing”} | 0.000966104 | | probe_http_duration_seconds{phase=”connect”} | 0.000520821 | | probe_http_content_length | 716 | | probe_failed_due_to_regex | 0 | | probe_duration_seconds | 0.00272609 | | probe_dns_lookup_time_seconds | 5.4095e-05 |
接入Blackbox监控: 在pod控制器上加annotations,并重启pod,监控生效。(JSON格式)
"annotations": {"blackbox_path": "/","blackbox_port": "8080","blackbox_scheme": "http"}
接入Blackbox监控:(yaml格式)在对应pod添加annotations,以下分别是TCP探测和HTTP探测。
annotations:blackbox_port: "20880"blackbox_scheme: tcpannotations:blackbox_port: "8080"blackbox_scheme: httpblackbox_path: /hello?name=health
kubernetes-pods*
- 监控JVM信息 | key | value | | :—- | :—- | | jvm_info{version=”1.7.0_80-b15”,vendor=”Oracle Corporation”,runtime=”Java(TM) SE Runtime Environment”,} | 1.0 | | jmx_config_reload_success_total | 0.0 | | process_resident_memory_bytes | 4.693897216E9 | | process_virtual_memory_bytes | 1.2138840064E10 | | process_max_fds | 65536.0 | | process_open_fds | 123.0 | | process_start_time_seconds | 1.54331073249E9 | | process_cpu_seconds_total | 196465.74 | | jvm_buffer_pool_used_buffers{pool=”mapped”,} | 0.0 | | jvm_buffer_pool_used_buffers{pool=”direct”,} | 150.0 | | jvm_buffer_pool_capacity_bytes{pool=”mapped”,} | 0.0 | | jvm_buffer_pool_capacity_bytes{pool=”direct”,} | 6216688.0 | | jvm_buffer_pool_used_bytes{pool=”mapped”,} | 0.0 | | jvm_buffer_pool_used_bytes{pool=”direct”,} | 6216688.0 | | jvm_gc_collection_seconds_sum{gc=”PS MarkSweep”,} | 1.867 | | … | … |
Pod接入监控:(JSON格式)在pod控制器上加annotations,并重启pod,监控生效。
"annotations": {"prometheus_io_scrape": "true","prometheus_io_port": "12346","prometheus_io_path": "/"}
Pod接入监控:(yaml格式)在对应pod添加annotations,并重启pod。该信息是jmx_javaagent-0.3.1.jar收集的,端口是12346。true是字符串!
annotations:prometheus_io_scrape: "true"prometheus_io_port: "12346"prometheus_io_path: /
修改traefik服务接入prometheus监控
dashboard上:kube-system名称空间 > daemonset > traefik-ingress-controller : spec > template > metadata下,添加(JSON格式)
"annotations": {"prometheus_io_scheme": "traefik","prometheus_io_path": "/metrics","prometheus_io_port": "8080"}
删除pod,重启traefik,观察监控
继续添加blackbox监控配置项(JSON格式)
"annotations": {"prometheus_io_scheme": "traefik","prometheus_io_path": "/metrics","prometheus_io_port": "8080","blackbox_path": "/","blackbox_port": "8080","blackbox_scheme": "http"}
也可以在vms200上修改traefik的yaml文件:
[root@vms200 ~]# vi /data/k8s-yaml/traefik/traefik-deploy.yaml
跟labels同级,添加annotations配置
apiVersion: apps/v1kind: DaemonSetmetadata:name: traefik-ingress-controllerlabels:app: traefikspec:selector:matchLabels:app: traefiktemplate:metadata:name: traefiklabels:app: traefikannotations:prometheus_io_scheme: "traefik"prometheus_io_path: "/metrics"prometheus_io_port: "8080"blackbox_path: "/"blackbox_port: "8080"blackbox_scheme: "http"...
任意节点重新应用配置
[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/traefik/traefik-deploy.yaml -n kube-systemservice/traefik unchangeddaemonset.apps/traefik-ingress-controller created
等待pod重启以后,再在prometheus上查看traefik、blackbox是否能正常获取数据了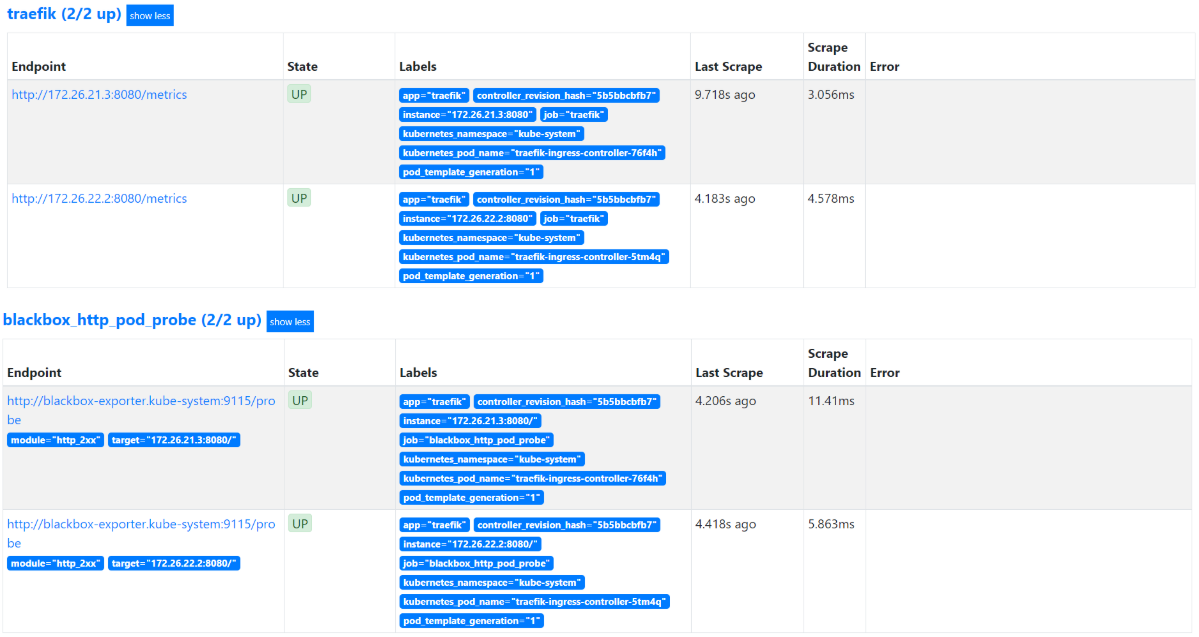
dubbo服务接入prometheus监控
使用测试环境FAT的dubbo服务来做演示,其他环境类似(注意启动vms11上的zk)
- dashboard中开启apollo-portal(infra空间)和test空间中的apollo
- dubbo-demo-service使用tcp的annotation
- dubbo-demo-consumer使用HTTP的annotation
以上环境比较耗资源,可以不使用apollo
- 修改dubbo-monitor(infra空间)的zk为zk_test(vms11上的zk)
- 修改app空间的dubbo-demo-service的镜像为master版本(不使用apollo配置),添加tcp的annotation
- 修改app空间的dubbo-demo-consumer的镜像为master版本(不使用apollo配置),添加HTTP的annotation
修改dubbo-service服务接入prometheus监控
dashboard上:
- 首先在dubbo-demo-service资源中添加一个TCP的annotations
- 添加监控jvm信息,以便监控pod中的jvm信息(12346是dubbo的POD启动命令中使用jmx_javaagent用到的端口,因此可以用来收集jvm信息)
test名称空间 > deployment > dubbo-demo-service Edit:spec > template > metadata下,添加 (JSON格式)
"annotations": {"prometheus_io_scrape": "true","prometheus_io_path": "/","prometheus_io_port": "12346","blackbox_port": "20880","blackbox_scheme": "tcp"}
删除pod,重启应用,观察监控(见后文监控观察)
也可以修改部署配置清单文件(增加annotations),然后在任意节点重新应用配置
spec:replicas: 0selector:matchLabels:name: dubbo-demo-servicetemplate:metadata:creationTimestamp: nulllabels:app: dubbo-demo-servicename: dubbo-demo-serviceannotations:blackbox_port: '20880'blackbox_scheme: tcpprometheus_io_path: /prometheus_io_port: '12346'prometheus_io_scrape: 'true'...
修改dubbo-consumer服务接入prometheus监控
dashboard上:
- 在dubbo-demo-consumer资源中添加一个HTTP的annotations;
- 添加监控jvm信息,以便监控pod中的jvm信息(12346是dubbo的POD启动命令中使用jmx_javaagent用到的端口,因此可以用来收集jvm信息)
test名称空间 > deployment > dubbo-demo-consumer Edit:spec > template > metadata下,添加 (JSON格式)
"annotations": {"prometheus_io_scrape": "true","prometheus_io_path": "/","prometheus_io_port": "12346","blackbox_path": "/hello","blackbox_port": "8080","blackbox_scheme": "http"}
删除pod,重启应用,观察监控(见后文监控观察)
也可以修改部署配置清单文件(增加annotations),然后在任意节点重新应用配置
spec:replicas: 1selector:matchLabels:name: dubbo-demo-consumertemplate:metadata:creationTimestamp: nulllabels:app: dubbo-demo-consumername: dubbo-demo-consumerannotations:blackbox_path: /helloblackbox_port: '8080'blackbox_scheme: httpprometheus_io_path: /prometheus_io_port: '12346'prometheus_io_scrape: 'true'...
监控观察
浏览器中查看http://blackbox.op.com和http://prometheus.op.com/targets运行的dubbo-demo-server服务,tcp端口20880已经被发现并在监控中

至此,所有9个job_name都成功完美获取了监控数据
7 部署Grafana
运维主机vms200上:
准备grafana镜像
官方dockerhub地址:https://hub.docker.com/r/grafana/grafana
官方github地址:https://github.com/grafana/grafana
grafana官网:https://grafana.com/
[root@vms200 ~]# docker pull grafana/grafana:7.1.57.1.5: Pulling from grafana/grafanadf20fa9351a1: Pull complete9942118288f3: Pull complete1fb6e3df6e68: Pull complete7e3d0d675cf3: Pull complete4c1eb3303598: Pull completea5ec11eae53c: Pull completeDigest: sha256:579044d31fad95f015c78dff8db25c85e2e0f5fdf37f414ce850eb045dd47265Status: Downloaded newer image for grafana/grafana:7.1.5docker.io/grafana/grafana:7.1.5[root@vms200 ~]# docker tag docker.io/grafana/grafana:7.1.5 harbor.op.com/infra/grafana:7.1.5[root@vms200 ~]# docker push harbor.op.com/infra/grafana:7.1.5The push refers to repository [harbor.op.com/infra/grafana]9c957ea29f01: Pushed7fcdc437fb25: Pushed5c98ed105d7e: Pushed43376507b219: Pushedcb596e3b6acf: Pushed50644c29ef5a: Pushed7.1.5: digest: sha256:dfd940ed4dd82a6369cb057fe5ab4cc8c774c1c5b943b2f4b618302a7979de61 size: 1579
准备资源配置清单
[root@vms200 ~]# mkdir /data/k8s-yaml/grafana && cd /data/k8s-yaml/grafana
RBAC
[root@vms200 grafana]# vi /data/k8s-yaml/grafana/rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: grafanarules:- apiGroups:- "*"resources:- namespaces- deployments- podsverbs:- get- list- watch---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:labels:addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/cluster-service: "true"name: grafanaroleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: grafanasubjects:- kind: Username: k8s-node
Deployment
[root@vms200 grafana]# vi /data/k8s-yaml/grafana/deployment.yaml
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: grafananame: grafananame: grafananamespace: infraspec:progressDeadlineSeconds: 600replicas: 1revisionHistoryLimit: 7selector:matchLabels:name: grafanastrategy:rollingUpdate:maxSurge: 1maxUnavailable: 1type: RollingUpdatetemplate:metadata:labels:app: grafananame: grafanaspec:containers:- image: harbor.op.com/infra/grafana:7.1.5imagePullPolicy: IfNotPresentname: grafanaports:- containerPort: 3000protocol: TCPvolumeMounts:- mountPath: /var/lib/grafananame: dataimagePullSecrets:- name: harbornodeName: vms22.cos.comrestartPolicy: AlwayssecurityContext:runAsUser: 0volumes:- nfs:server: vms200path: /data/nfs-volume/grafananame: data
创建grafana数据目录
[root@vms200 grafana]# mkdir /data/nfs-volume/grafana
Service
[root@vms200 grafana]# vi /data/k8s-yaml/grafana/service.yaml
apiVersion: v1kind: Servicemetadata:name: grafananamespace: infraspec:ports:- port: 3000protocol: TCPselector:app: grafanatype: ClusterIP
Ingress
[root@vms200 grafana]# vi /data/k8s-yaml/grafana/ingress.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: grafananamespace: infraspec:rules:- host: grafana.op.comhttp:paths:- path: /backend:serviceName: grafanaservicePort: 3000
应用资源配置清单
任意运算节点上:
[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/grafana/rbac.yamlclusterrole.rbac.authorization.k8s.io/grafana createdclusterrolebinding.rbac.authorization.k8s.io/grafana created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/grafana/deployment.yamldeployment.apps/grafana created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/grafana/service.yamlservice/grafana created[root@vms22 ~]# kubectl apply -f http://k8s-yaml.op.com/grafana/ingress.yamlingress.extensions/grafana created
[root@vms22 ~]# kubectl get pod -l name=grafana -o wide -n infraNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESgrafana-7677b5db6b-hrf87 1/1 Running 0 38m 172.26.22.8 vms22.cos.com <none> <none>
解析域名
vms11上
[root@vms11 ~]# vi /var/named/op.com.zone
...grafana A 192.168.26.10
注意serial前滚一个序号
[root@vms11 ~]# systemctl restart named[root@vms11 ~]# dig -t A grafana.op.com 192.168.26.11 +short192.168.26.10
浏览器访问
http://grafana.op.com (用户名:admin 密 码:admin)
登录后需要修改管理员密码(admin123),进入:
配置grafana页面
外观
Configuration > Preferences
UI Theme:LightHome Dashboard:DefaultTimezone:Browser time
save保存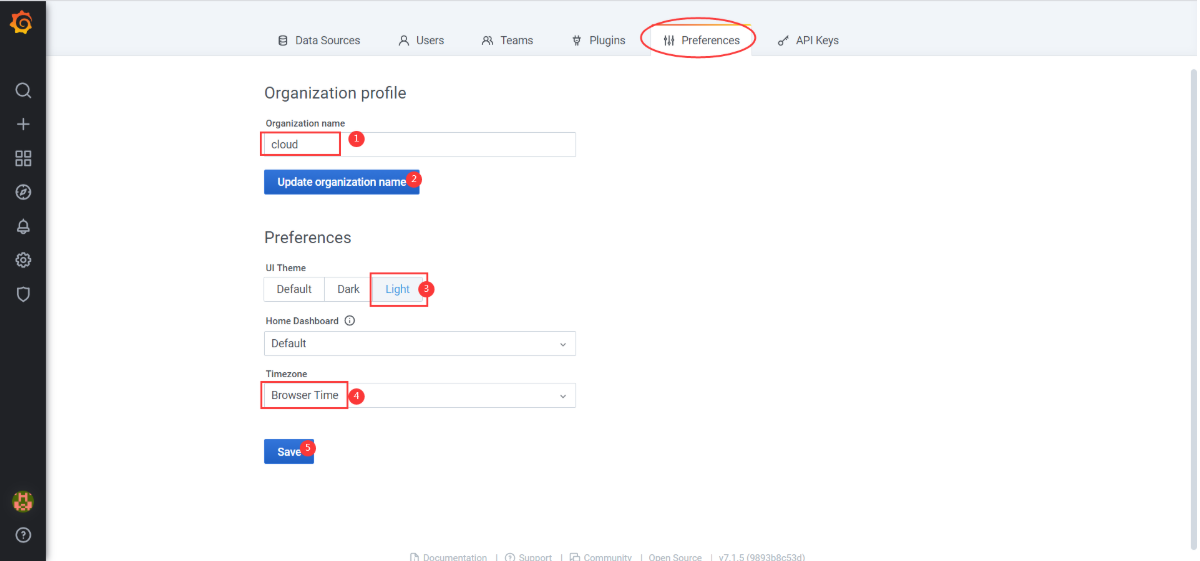
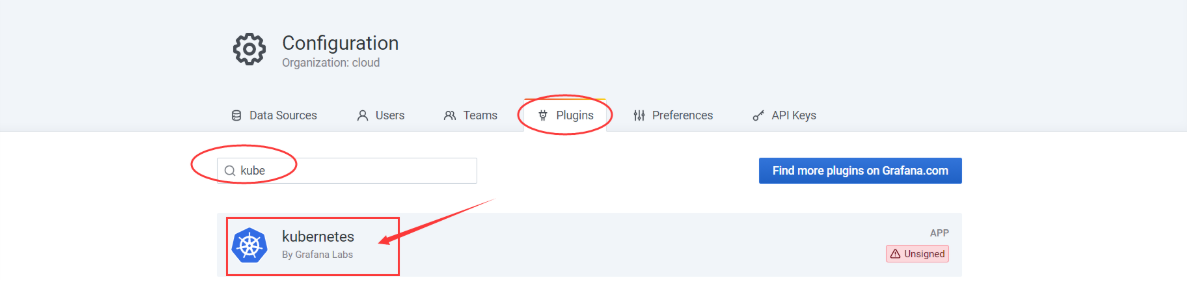
插件
Configuration > Plugins 查看插件,需要安装以下5个插件:
- grafana-kubernetes-app
- grafana-clock-panel
- grafana-piechart-panel
- briangann-gauge-panel
- natel-discrete-panel
插件安装有两种方式:(插件包下载地址:https://github.com/swbook/k8s-grafana-plugins)
- 方式一:进入Container中,执行 grafana-cli plugins install $plugin_name
- 方式二:手动下载插件zip包并解压
1、 查询插件版本号$version:访问 https://grafana.com/api/plugins/repo/$plugin_name
2、下载zip包:wget https://grafana.com/api/plugins/$plugin_name/versions/$version/download
3、将zip包解压到 /var/lib/grafana/plugins 下 - 两种方式的插件安装完毕后,重启Grafana的Pod。
grafana确认启动好以后,进入grafana容器内部,进行插件安装(方式一)
任一运算节点 vms22上
[root@vms22 ~]# kubectl -n infra exec -it grafana-7677b5db6b-hrf87 -- /bin/bashbash-5.0# grafana-cli plugins install grafana-kubernetes-appinstalling grafana-kubernetes-app @ 1.0.1from: https://grafana.com/api/plugins/grafana-kubernetes-app/versions/1.0.1/downloadinto: /var/lib/grafana/plugins✔ Installed grafana-kubernetes-app successfullyRestart grafana after installing plugins . <service grafana-server restart>bash-5.0# grafana-cli plugins install grafana-clock-panelinstalling grafana-clock-panel @ 1.1.1from: https://grafana.com/api/plugins/grafana-clock-panel/versions/1.1.1/downloadinto: /var/lib/grafana/plugins✔ Installed grafana-clock-panel successfullyRestart grafana after installing plugins . <service grafana-server restart>bash-5.0# grafana-cli plugins install grafana-piechart-panelinstalling grafana-piechart-panel @ 1.6.0from: https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.6.0/downloadinto: /var/lib/grafana/plugins✔ Installed grafana-piechart-panel successfullyRestart grafana after installing plugins . <service grafana-server restart>bash-5.0# grafana-cli plugins install briangann-gauge-panelinstalling briangann-gauge-panel @ 0.0.6from: https://grafana.com/api/plugins/briangann-gauge-panel/versions/0.0.6/downloadinto: /var/lib/grafana/plugins✔ Installed briangann-gauge-panel successfullyRestart grafana after installing plugins . <service grafana-server restart>bash-5.0# grafana-cli plugins install natel-discrete-panelinstalling natel-discrete-panel @ 0.1.0from: https://grafana.com/api/plugins/natel-discrete-panel/versions/0.1.0/downloadinto: /var/lib/grafana/plugins✔ Installed natel-discrete-panel successfullyRestart grafana after installing plugins . <service grafana-server restart>
安装完后查看: vms200上
[root@vms200 grafana]# cd /data/nfs-volume/grafana/plugins[root@vms200 plugins]# lltotal 0drwxr-xr-x 4 root root 253 Sep 12 20:39 briangann-gauge-paneldrwxr-xr-x 5 root root 253 Sep 12 20:34 grafana-clock-paneldrwxr-xr-x 4 root root 198 Sep 12 20:31 grafana-kubernetes-appdrwxr-xr-x 4 root root 233 Sep 12 20:35 grafana-piechart-paneldrwxr-xr-x 5 root root 216 Sep 12 20:41 natel-discrete-panel
安装方法二 (已按方法一进行安装,这里仅做示例)
vms200上
[root@vms200 grafana]# cd /data/nfs-volume/grafana/plugins
- Kubernetes App
下载地址:https://grafana.com/api/plugins/grafana-kubernetes-app/versions/1.0.1/download
[root@vms200 plugins]# wget https://grafana.com/api/plugins/grafana-kubernetes-app/versions/1.0.1/download -O grafana-kubernetes-app.zip...[root@vms200 plugins]# unzip grafana-kubernetes-app.zip
- Clock Pannel
下载地址:https://grafana.com/api/plugins/grafana-clock-panel/versions/1.1.1/download
- Pie Chart
下载地址:https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.6.0/download
- D3 Gauge
下载地址:https://grafana.com/api/plugins/briangann-gauge-panel/versions/0.0.6/download
- Discrete
下载地址:https://grafana.com/api/plugins/natel-discrete-panel/versions/0.1.0/download
插件安装完成后,重启grafana的pod
Configuration > Plugins:从插件列表中选择
Kubernetes:
出现
enable后点击
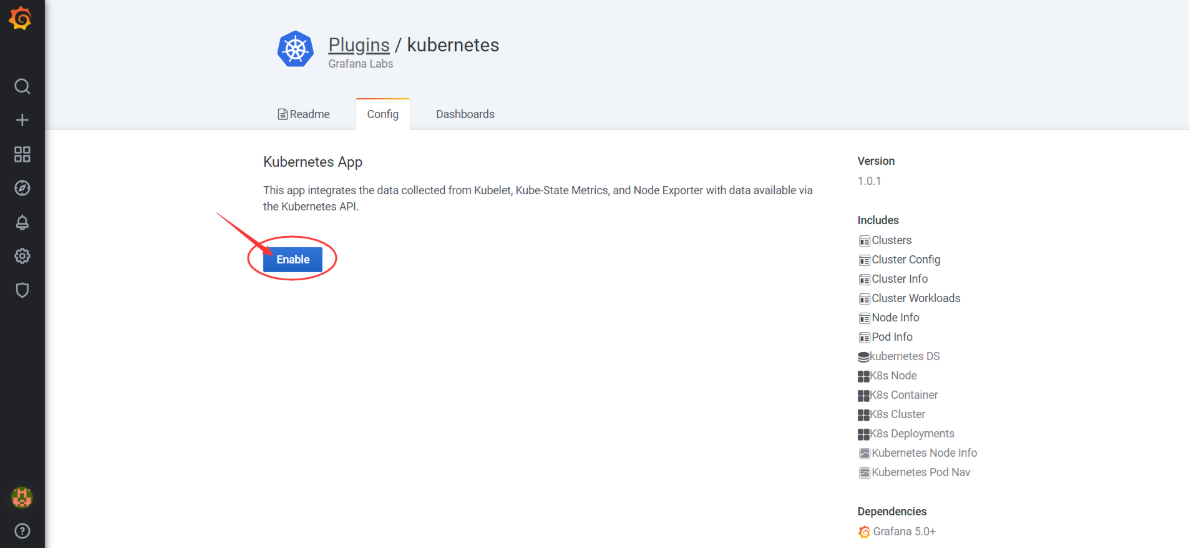
左侧菜单出现
Kubernetes图标
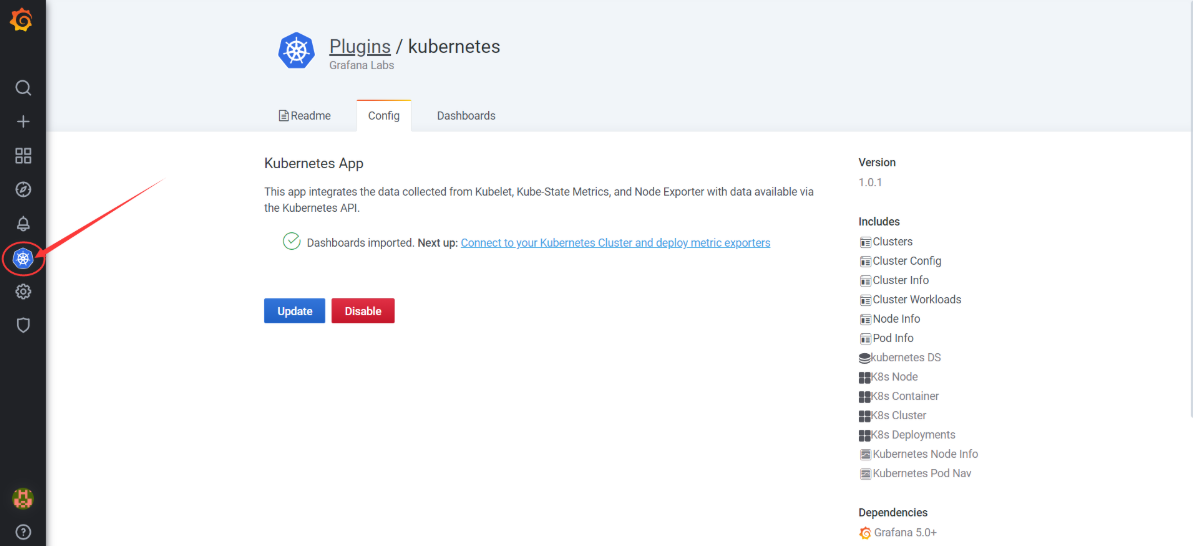
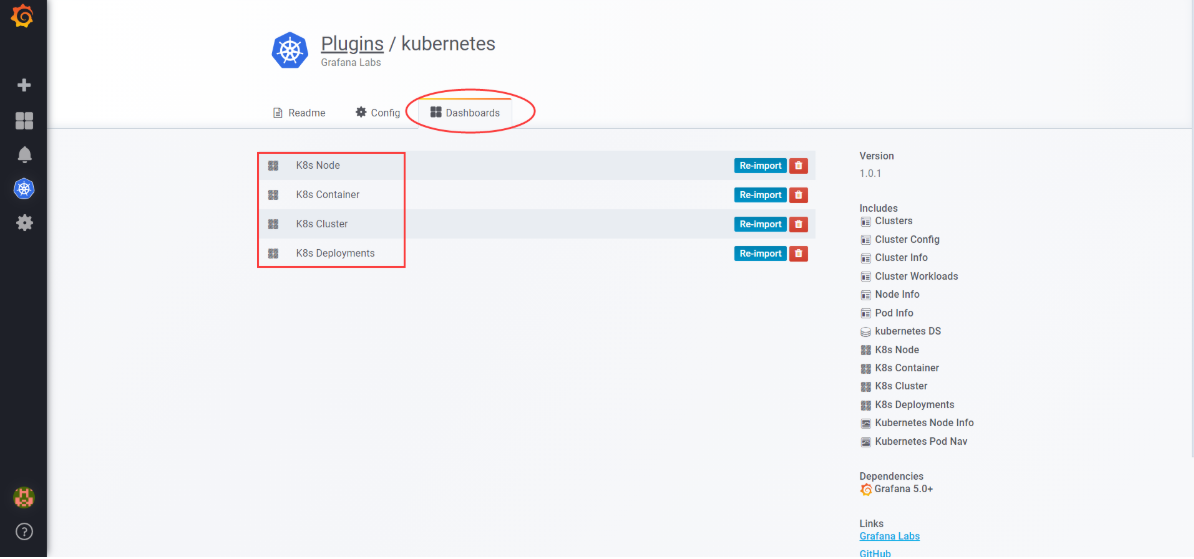
Kubernetes插件安装好后,会有4个dashboard
配置grafana数据源
Configuration >Data Sources,选择prometheus
HTTP| key | value | | :—- | :—- | | URL | http://prometheus.op.com | | Access | Server(Default) | | HTTP Method | GET | | TLS Client Auth | 勾选 | | With CA Cert | 勾选 | | CA Cert | CV:vms200:/opt/certs/ca.pem 复制粘贴文件内容 | | Client Cert | CV:vms200:/opt/certs/client.pem | | Client Key | CV:vms200:/opt/certs/client-key.pem |
Save & Test多点几次

配置Kubernetes集群Dashboard
kubernetes > +New Cluster
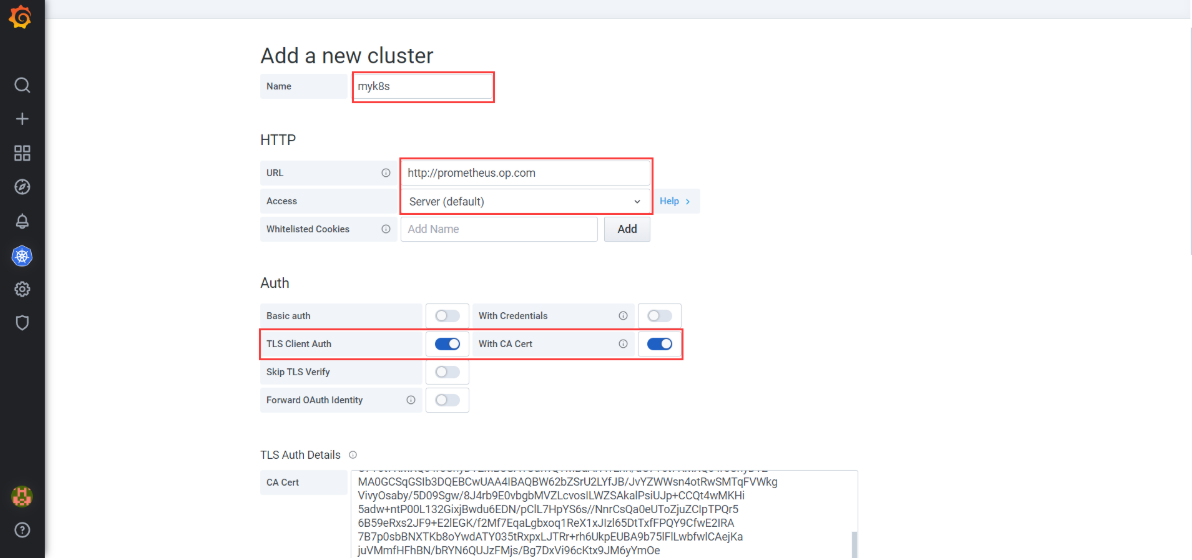
- Add a new cluster | key | value | | :—- | :—- | | Name | myk8s |
- Prometheus Read | Key | value | | —- | —- | | Datasource | Prometheus |
选择Datasource后,继续填写以下选项。
- HTTP | key | value | | :—- | :—- | | URL | https://192.168.26.10:8443 (api-server的VIP地址) | | Access | Server(Default) (这里要选择一下) |
- Auth | key | value | | :—- | :—- | | TLS Client Auth | 勾选 | | With Ca Cert | 勾选 |
将ca.pem、client.pem和client-key.pem内容分别粘贴至CA Cert、Client Cert、Client Key对应的文本框内
- Save
添加完成后,进入Configuration >Data Sources: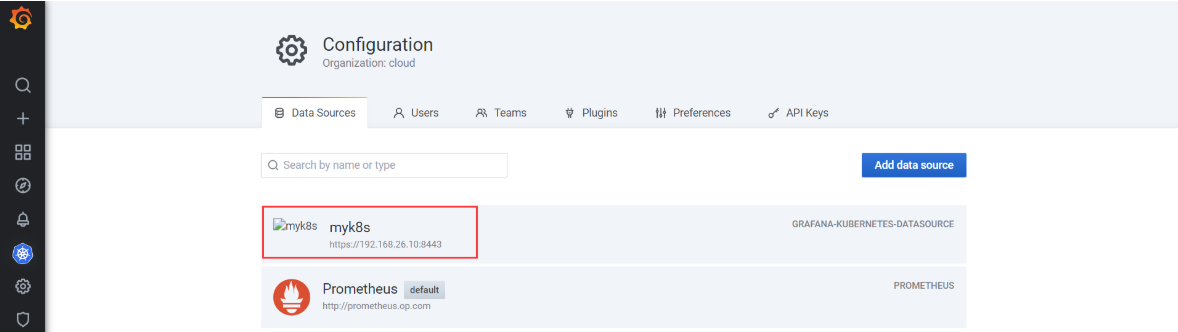
选择并点击myk8s,进入页面后,在页面底部点击Save & Test,不用管出现HTTP Error Forbidden(可能是设置的https请求),多点击几次Save & Test,测试发现grafana就可以获取数据了。
点击kubernetes,出现:(如果这里不出现,则切换低版本的grafana:5.4.2)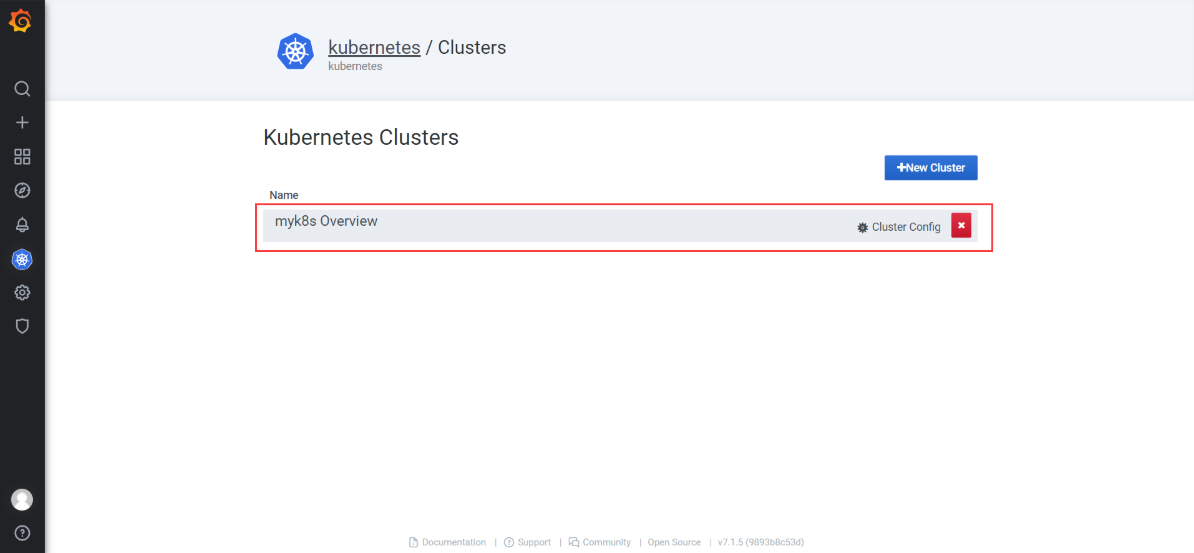
注意:
- K8S Container中,所有Pannel的pod_name 替换成 container_label_io_kubernetes_pod_name
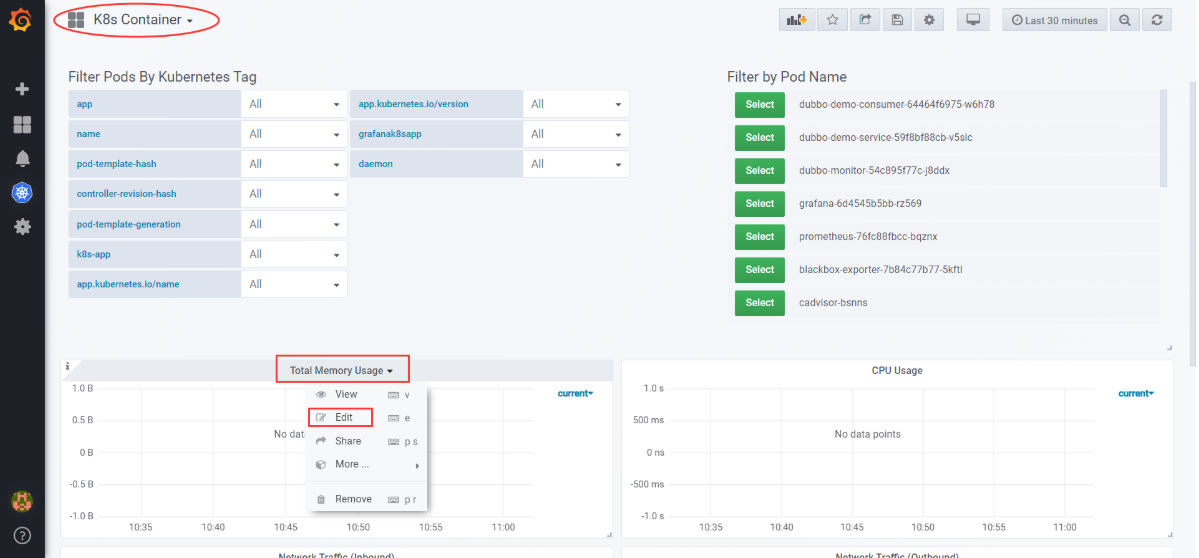
选择Total Memory Usage下拉菜单项Edit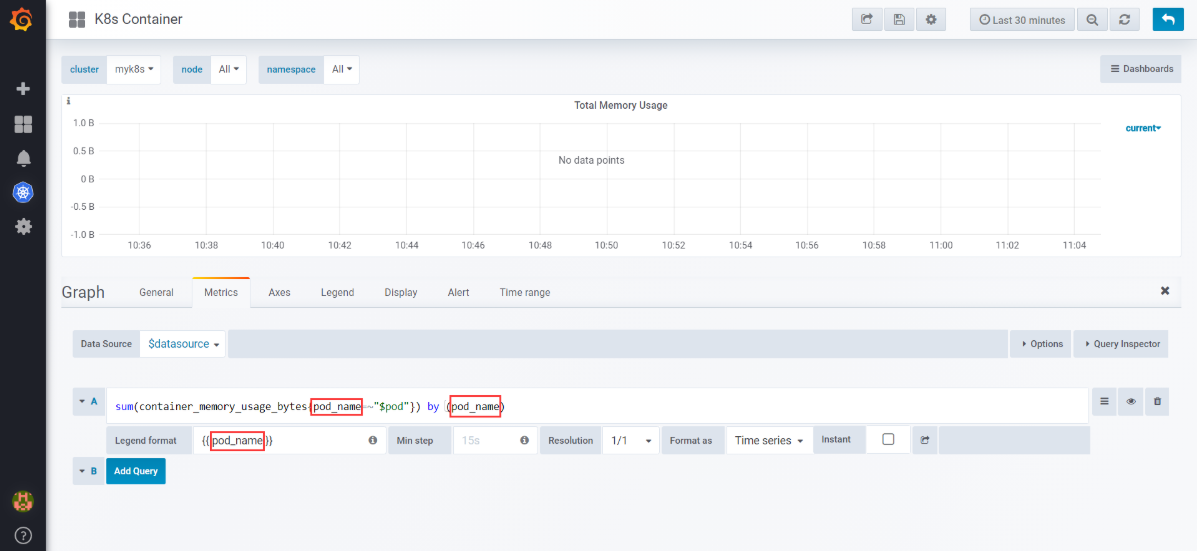
将pod_name替换成container_label_io_kubernetes_pod_name`,就有图了: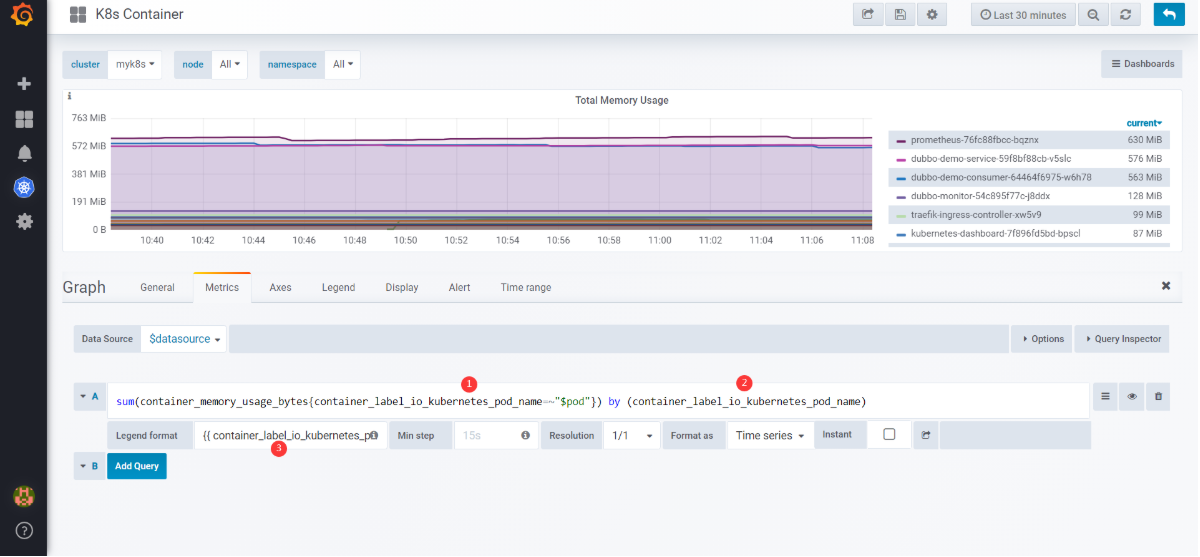
将所有Pannel的pod_name 替换成 container_label_io_kubernetes_pod_name
- K8S-Cluster
- K8S-Node
- K8S-Deployments
这4个dashboard根据实际进行优化。
配置自定义dashboard
根据Prometheus数据源里的数据,配置如下dashboard:
- etcd dashboard
- traefik dashboard
- generic dashboard
- JMX dashboard
- blackbox dashboard
这些dashboard的JSON配置文件下载地址:https://github.com/swbook/k8s-GrafanaDashboard
下载配置文件后,然后进行导入(Import dashboard from file or Grafana.com)。
示例:
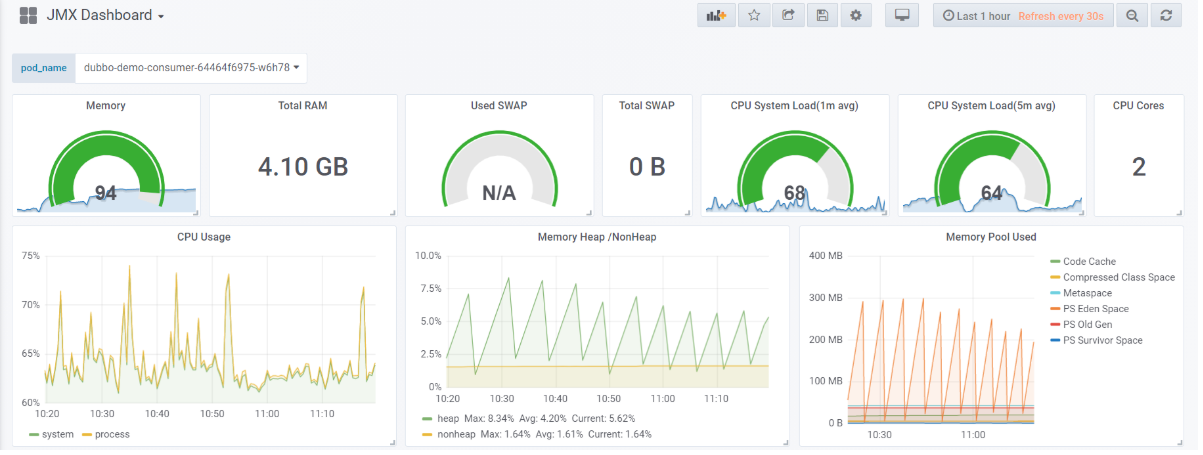
- JMX dashboard
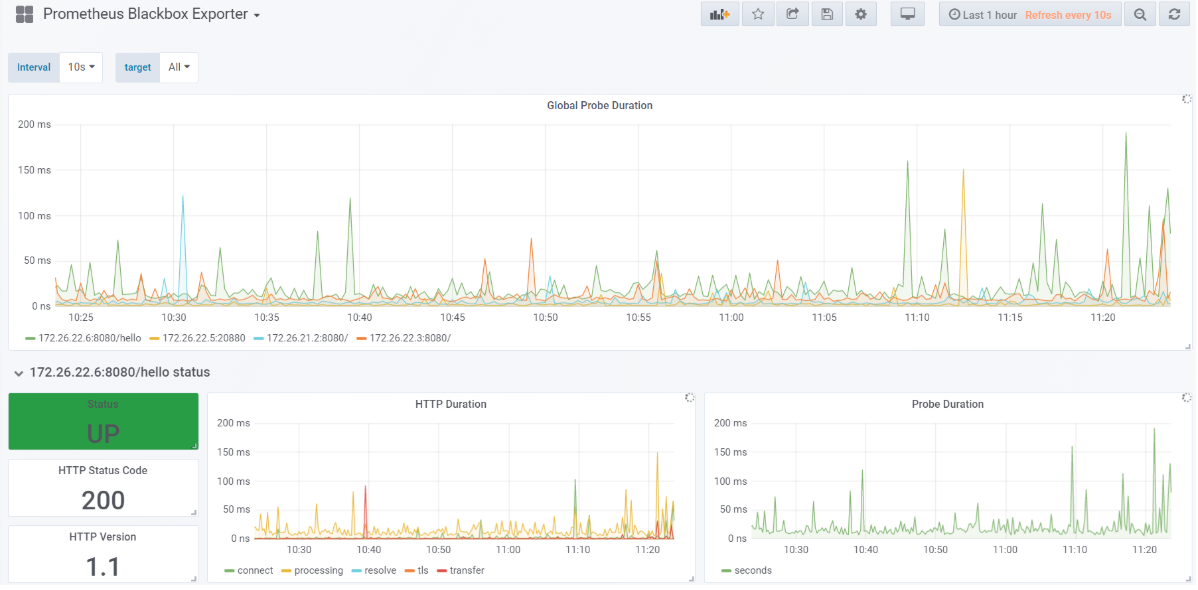
- blackbox dashboard
8 部署alertmanager告警插件
运维主机vms200上:
准备镜像
[root@vms200 ~]# docker pull docker.io/prom/alertmanager:v0.14.0[root@vms200 ~]# docker tag prom/alertmanager:v0.14.0 harbor.op.com/infra/alertmanager:v0.14.0[root@vms200 ~]# docker push harbor.op.com/infra/alertmanager:v0.14.0[root@vms200 ~]# docker pull prom/alertmanager:v0.21.0[root@vms200 ~]# docker tag prom/alertmanager:v0.21.0 harbor.op.com/infra/alertmanager:v0.21.0[root@vms200 ~]# docker push harbor.op.com/infra/alertmanager:v0.21.0
准备资源配置清单
[root@vms200 ~]# mkdir /data/k8s-yaml/alertmanager && cd /data/k8s-yaml/alertmanager
- configmap.yaml
apiVersion: v1kind: ConfigMapmetadata:name: alertmanager-confignamespace: infradata:config.yml: |-global:# 在没有报警的情况下声明为已解决的时间resolve_timeout: 5m# 配置邮件发送信息mtp_smarthost: 'smtp.qq.com:25'smtp_from: '385314590@qq.com'smtp_auth_username: '385314590@qq.com'smtp_auth_password: 'XXXX'smtp_require_tls: falsetemplates:- '/etc/alertmanager/*.tmpl'# 所有报警信息进入后的根路由,用来设置报警的分发策略route:# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面group_by: ['alertname', 'cluster']# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。group_wait: 30s# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。group_interval: 5m# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们repeat_interval: 5m# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器receiver: defaultreceivers:- name: 'default'email_configs:- to: 'k8s_cloud@126.com'send_resolved: true
注意改成自己的邮箱!网上有可以配置发送中文告警邮件:
...receivers:- name: 'default'email_configs:- to: 'xxxx@qq.com'send_resolved: truehtml: '{{ template "email.to.html" . }}'headers: { Subject: " {{ .CommonLabels.instance }} {{ .CommonAnnotations.summary }}" }email.tmpl: |{{ define "email.to.html" }}{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}告警程序: prometheus_alert <br>告警级别: {{ .Labels.severity }} <br>告警类型: {{ .Labels.alertname }} <br>故障主机: {{ .Labels.instance }} <br>告警主题: {{ .Annotations.summary }} <br>触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>{{ end }}{{ end -}}{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}告警程序: prometheus_alert <br>告警级别: {{ .Labels.severity }} <br>告警类型: {{ .Labels.alertname }} <br>故障主机: {{ .Labels.instance }} <br>告警主题: {{ .Annotations.summary }} <br>触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>{{ end }}{{ end -}}{{- end }}
- deployment.yaml
apiVersion: apps/v1kind: Deploymentmetadata:name: alertmanagernamespace: infraspec:replicas: 1selector:matchLabels:app: alertmanagertemplate:metadata:labels:app: alertmanagerspec:containers:- name: alertmanagerimage: harbor.op.com/infra/alertmanager:v0.21.0args:- "--config.file=/etc/alertmanager/config.yml"- "--storage.path=/alertmanager"ports:- name: alertmanagercontainerPort: 9093volumeMounts:- name: alertmanager-cmmountPath: /etc/alertmanagervolumes:- name: alertmanager-cmconfigMap:name: alertmanager-configimagePullSecrets:- name: harbor
- service.yaml
apiVersion: v1kind: Servicemetadata:name: alertmanagernamespace: infraspec:selector:app: alertmanagerports:- port: 80targetPort: 9093
Prometheus调用alert采用service nam,不走ingress
应用资源配置清单
vms21或vms22上
[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/alertmanager/configmap.yamlconfigmap/alertmanager-config created[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/alertmanager/deployment.yamldeployment.apps/alertmanager created[root@vms21 ~]# kubectl apply -f http://k8s-yaml.op.com/alertmanager/service.yamlservice/alertmanager created
添加告警规则
- rules.yml
[root@vms200 ~]# vi /data/nfs-volume/prometheus/etc/rules.yml
groups:- name: hostStatsAlertrules:- alert: hostCpuUsageAlertexpr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85for: 5mlabels:severity: warningannotations:summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)"- alert: hostMemUsageAlertexpr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85for: 5mlabels:severity: warningannotations:summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)"- alert: OutOfInodesexpr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10for: 5mlabels:severity: warningannotations:summary: "Out of inodes (instance {{ $labels.instance }})"description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})"- alert: OutOfDiskSpaceexpr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10for: 5mlabels:severity: warningannotations:summary: "Out of disk space (instance {{ $labels.instance }})"description: "Disk is almost full (< 10% left) (current value: {{ $value }})"- alert: UnusualNetworkThroughputInexpr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100for: 5mlabels:severity: warningannotations:summary: "Unusual network throughput in (instance {{ $labels.instance }})"description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})"- alert: UnusualNetworkThroughputOutexpr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100for: 5mlabels:severity: warningannotations:summary: "Unusual network throughput out (instance {{ $labels.instance }})"description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})"- alert: UnusualDiskReadRateexpr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50for: 5mlabels:severity: warningannotations:summary: "Unusual disk read rate (instance {{ $labels.instance }})"description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})"- alert: UnusualDiskWriteRateexpr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50for: 5mlabels:severity: warningannotations:summary: "Unusual disk write rate (instance {{ $labels.instance }})"description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})"- alert: UnusualDiskReadLatencyexpr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100for: 5mlabels:severity: warningannotations:summary: "Unusual disk read latency (instance {{ $labels.instance }})"description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})"- alert: UnusualDiskWriteLatencyexpr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100for: 5mlabels:severity: warningannotations:summary: "Unusual disk write latency (instance {{ $labels.instance }})"description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})"- name: http_statusrules:- alert: ProbeFailedexpr: probe_success == 0for: 1mlabels:severity: errorannotations:summary: "Probe failed (instance {{ $labels.instance }})"description: "Probe failed (current value: {{ $value }})"- alert: StatusCodeexpr: probe_http_status_code <= 199 OR probe_http_status_code >= 400for: 1mlabels:severity: errorannotations:summary: "Status Code (instance {{ $labels.instance }})"description: "HTTP status code is not 200-399 (current value: {{ $value }})"- alert: SslCertificateWillExpireSoonexpr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30for: 5mlabels:severity: warningannotations:summary: "SSL certificate will expire soon (instance {{ $labels.instance }})"description: "SSL certificate expires in 30 days (current value: {{ $value }})"- alert: SslCertificateHasExpiredexpr: probe_ssl_earliest_cert_expiry - time() <= 0for: 5mlabels:severity: errorannotations:summary: "SSL certificate has expired (instance {{ $labels.instance }})"description: "SSL certificate has expired already (current value: {{ $value }})"- alert: BlackboxSlowPingexpr: probe_icmp_duration_seconds > 2for: 5mlabels:severity: warningannotations:summary: "Blackbox slow ping (instance {{ $labels.instance }})"description: "Blackbox ping took more than 2s (current value: {{ $value }})"- alert: BlackboxSlowRequestsexpr: probe_http_duration_seconds > 2for: 5mlabels:severity: warningannotations:summary: "Blackbox slow requests (instance {{ $labels.instance }})"description: "Blackbox request took more than 2s (current value: {{ $value }})"- alert: PodCpuUsagePercentexpr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80for: 5mlabels:severity: warningannotations:summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"
- 在prometheus配置文件中追加配置:在末尾追加,关联告警规则
[root@vms200 ~]# vi /data/nfs-volume/prometheus/etc/prometheus.yml
...alerting:alertmanagers:- static_configs:- targets: ["alertmanager"]rule_files:- "/data/etc/rules.yml"
- 重载配置:> 可以重启Prometheus的pod,但生产商因为Prometheus太庞大,删掉容易拖垮集群,所以要采用平滑加载方法(Prometheus支持),有三种方法:
任一主机:
[root@vms200 ~]# curl -X POST http://prometheus.op.com/-/reload
或:(作一运算节点)
[root@vms21 ~]# kubectl get pod -n infra | grep promprometheus-76fc88fbcc-bqznx 1/1 Running 0 5h59m[root@vms21 ~]# kubectl exec -n infra prometheus-76fc88fbcc-bqznx -it -n -- kill -HUP 1
或:(Prometheus在vms21)
[root@vms21 ~]# ps aux|grep prometheus | grep -v greproot 192560 26.2 10.0 1801172 401368 ? Ssl 06:19 0:47 /bin/prometheus --config.file=/data/etc/prometheus.yml --storage.tsdb.path=/data/prom-db --storage.tsdb.retention=72h --storage.tsdb.min-block-duration=10m --web.enable-lifecycle[root@vms21 ~]# kill -SIGHUP 192560
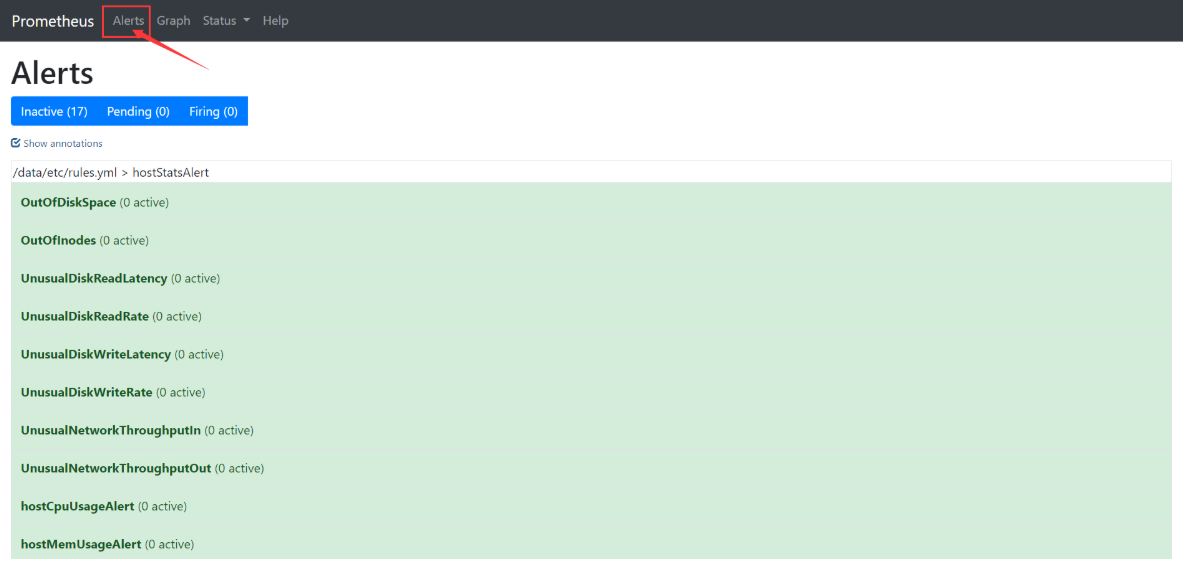
/data/etc/rules.yml > hostStatsAlertOutOfDiskSpace (0 active)OutOfInodes (0 active)UnusualDiskReadLatency (0 active)UnusualDiskReadRate (0 active)UnusualDiskWriteLatency (0 active)UnusualDiskWriteRate (0 active)UnusualNetworkThroughputIn (0 active)UnusualNetworkThroughputOut (0 active)hostCpuUsageAlert (0 active)hostMemUsageAlert (0 active)/data/etc/rules.yml > http_statusBlackboxSlowPing (0 active)BlackboxSlowRequests (0 active)PodCpuUsagePercent (0 active)ProbeFailed (0 active)SslCertificateHasExpired (0 active)SslCertificateWillExpireSoon (0 active)StatusCode (0 active)
告警测试
当停掉dubbo-demo-service的Pod后,blackbox的HTTP会探测失败,然后触发告警:

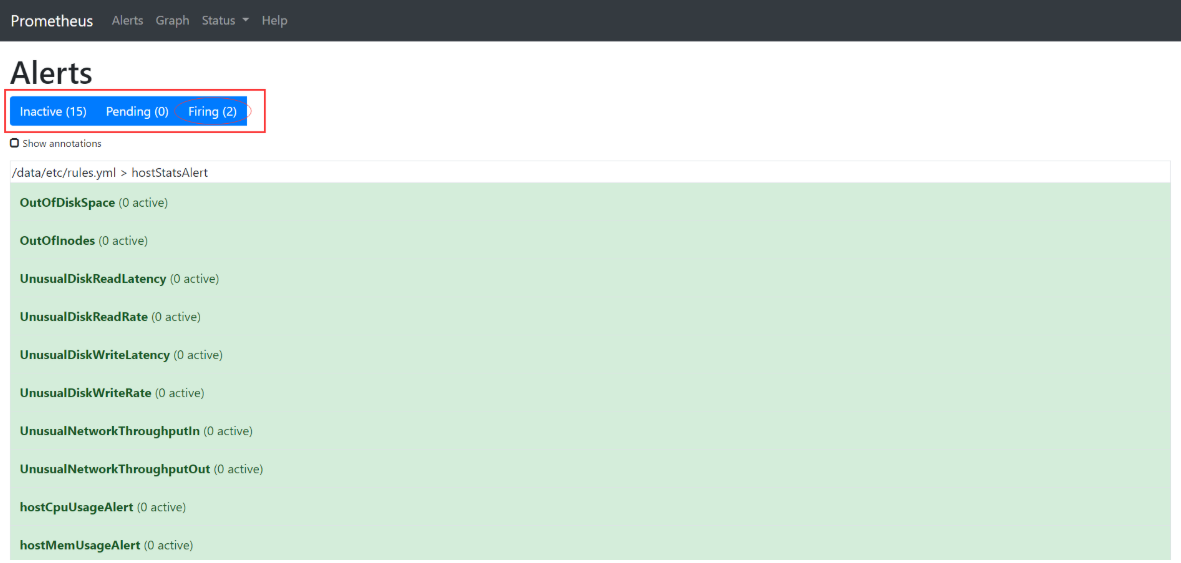
仔细观察,先是Pending(2),alert中项目变为黄色,然后Firing(2)。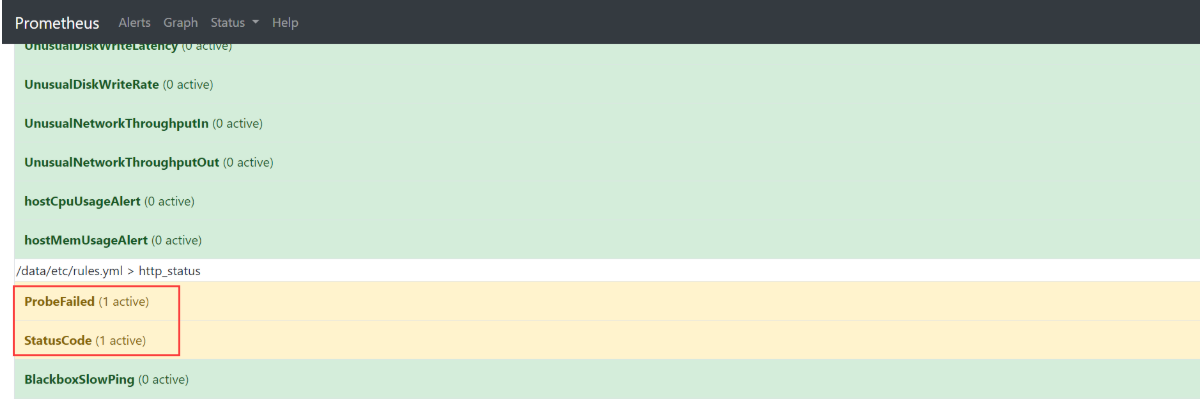
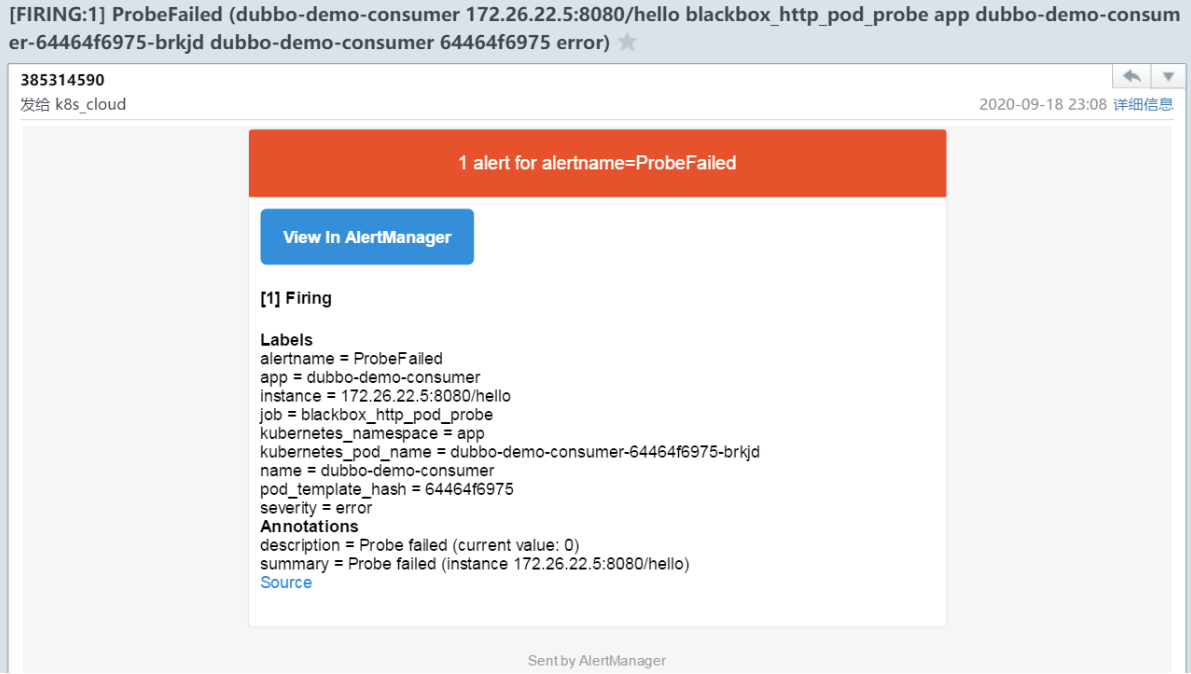
等到alert中项目变为红色的时候就会发邮件告警。
- 查看邮箱
如果需要自己定制告警规则和告警内容,需要研究promql,修改配置文件。
至此,promethus监控与告警完美交付成功!

若有收获,就点个赞吧
0 人点赞
