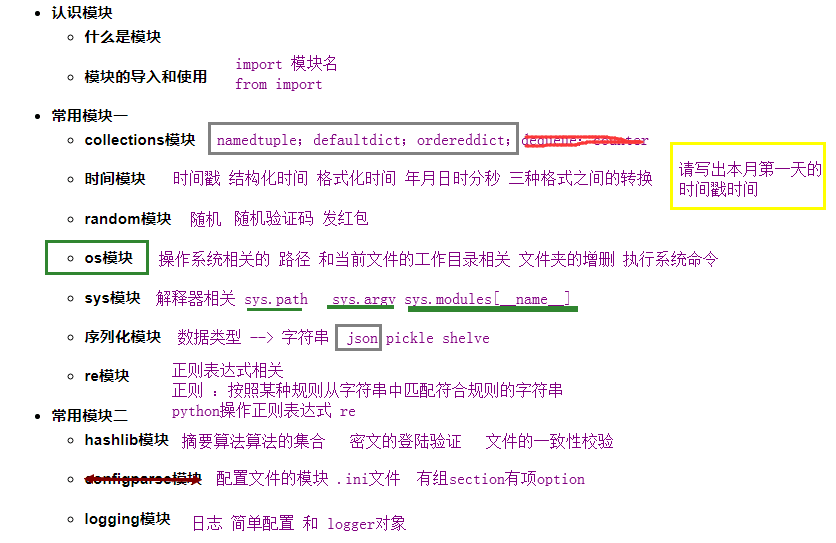
知识回顾
正则模块
正则表达式
元字符 :
. 匹配除了回车以外的所有字符\w 数字字母下划线\d 数字\n \s \t 回车 空格 和 tab^ 必须出现在一个正则表达式的最开始,匹配开头$ 必须出现在一个正则表达式的最后,匹配结尾| 或a|b 要么取左边的要么取右边的()|() 分组中的或 一定是长的在前面 短的在后面[] 在同一个位置上可能出现的所有字符都放在组里[^] 在同一个位置上不能出现的所有字符都放在组里() 对于一整个组做量词约束 ; python 分组优先
量词 :
* 0次或多次+ 1次或多次? 0次或1次{} 具体的 {n},{n,m},{n,}
问号的用法
惰性匹配 : 量词+? 表示使用惰性匹配分组优先 findall split ;取消分组优先 (?:。。。)分组命名 (?P<name>...)
示例
匹配整数
import reret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))")print(ret)
执行输出:
[‘1’, ‘2’, ‘60’, ‘40’, ‘35’, ‘5’, ‘4’, ‘3’]
结果是不对的,因为它把小数也拆分了,得到[‘40’,’35’]
有的时候 不想要的内容需要被匹配出来
你不想要的东西包含着你想要的东西
匹配小数
import reret=re.findall(r"-?\d+\.\d*","1-2*(60+(-40.35/5)-(-4*3))")print(ret)
执行输出: [‘-40.35’]
匹配小数或者整数
import reret=re.findall(r"-?\d+\.\d*|-?\d+","1-2*(60+(-40.35/5)-(-4*3))")print(ret)
执行输出:
[‘1’, ‘-2’, ‘60’, ‘-40.35’, ‘5’, ‘-4’, ‘3’]
加括号,优先匹配数字
['1', '-2', '60', '', '5', '-4', '3']
执行输出:
[‘1’, ‘-2’, ‘60’, ‘’, ‘5’, ‘-4’, ‘3’]
删除空格
import reret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")ret.remove('')print(ret)
执行输出:
[‘1’, ‘-2’, ‘60’, ‘5’, ‘-4’, ‘3’]
数字匹配
1、匹配一段文本中的每行的邮箱http://blog.csdn.net/make164492212/article/details/516566382、匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’;分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$3、匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,}4、匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d*5、匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 或者..6、匹配出所有整数
爬虫练习
先看一下,爬虫的过程
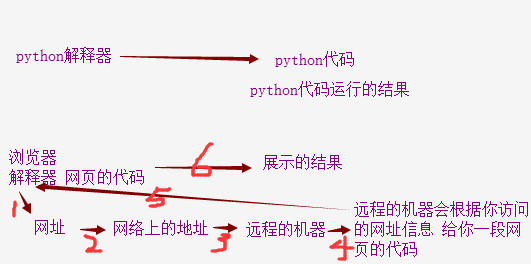
https://movie.douban.com/top250
豆瓣电影 Top 250
import requestsimport reimport jsondef getPage(url):response=requests.get(url)return response.textdef parsePage(s):com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>''.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S)ret=com.finditer(s)for i in ret:yield {"id":i.group("id"),"title":i.group("title"),"rating_num":i.group("rating_num"),"comment_num":i.group("comment_num"),}def main(num):url='https://movie.douban.com/top250?start=%s&filter='%numresponse_html=getPage(url)ret=parsePage(response_html)print(ret)f=open("move_info7","a",encoding="utf8")for obj in ret:print(obj)data=json.dumps(obj,ensure_ascii=False)f.write(data+"\n")if __name__ == '__main__':count=0for i in range(10):main(count)count+=25
简化版
import reimport jsonfrom urllib.request import urlopendef getPage(url):response = urlopen(url)return response.read().decode('utf-8')def parsePage(s):com = re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>''.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S)ret = com.finditer(s)for i in ret:yield {"id": i.group("id"),"title": i.group("title"),"rating_num": i.group("rating_num"),"comment_num": i.group("comment_num"),}def main(num):url = 'https://movie.douban.com/top250?start=%s&filter=' % numresponse_html = getPage(url)ret = parsePage(response_html)print(ret)f = open("move_info7", "a", encoding="utf8")for obj in ret:print(obj)data = str(obj)f.write(data + "\n")f.close()count = 0for i in range(10):main(count)count += 25
这一段是为了得到这一段,是为了得到 id,title,rating_num,comment_num
('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>''.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>'
https://movie.douban.com/top250?start=25&filter=
一页,有 25 行。所以 start=25 时,表示下一页。
总共有 10 页,调取 10 次,就取完了。
flags有很多可选值:re.I(IGNORECASE)忽略大小写,括号内是完整的写法re.M(MULTILINE)多行模式,改变^和$的行为re.S(DOTALL)点可以匹配任意字符,包括换行符re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flagre.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释flags
最常用的还是
re.S(DOTALL)点可以匹配任意字符,包括换行符
网络编程
1.楔子
你现在已经学会了写 python 代码,假如你写了两个 python 文件 a.py 和 b.py,分别去运行,你就会发现,这两个 python 的文件分别运行的很好。但是如果这两个程序之间想要传递一个数据,你要怎么做呢?
这个问题以你现在的知识就可以解决了,我们可以创建一个文件,把 a.py 想要传递的内容写到文件中,然后 b.py 从这个文件中读取内容就可以了。
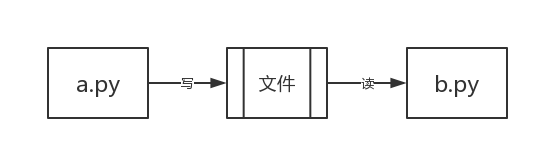
但是当你的 a.py 和 b.py 分别在不同电脑上的时候,你要怎么办呢?
类似的机制有计算机网盘,qq 等等。我们可以在我们的电脑上和别人聊天,可以在自己的电脑上向网盘中上传、下载内容。这些都是两个程序在通信。
2.软件开发的架构
我们了解的涉及到两个程序之间通讯的应用大致可以分为两种:
第一种是应用类:qq、微信、网盘、优酷这一类是属于需要安装的桌面应用
第二种是 web 类:比如百度、知乎、博客园等使用浏览器访问就可以直接使用的应用
这些应用的本质其实都是两个程序之间的通讯。而这两个分类又对应了两个软件开发的架构~
1.C/S 架构
C/S 即:Client 与 Server,中文意思:客户端与服务器端架构,这种架构也是从用户层面(也可以是物理层面)来划分的。
这里的客户端一般泛指客户端应用程序 EXE,程序需要先安装后,才能运行在用户的电脑上,对用户的电脑操作系统环境依赖较大。
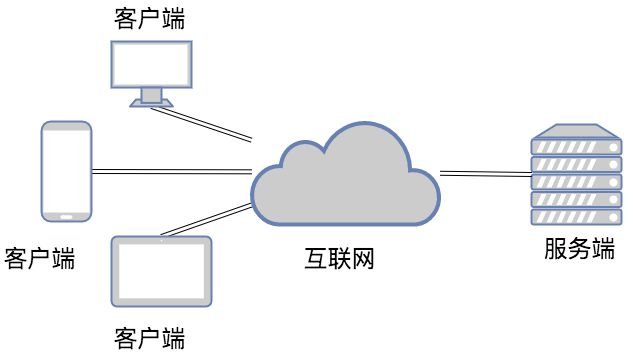
2.B/S 架构
B/S 即:Browser 与 Server,中文意思:浏览器端与服务器端架构,这种架构是从用户层面来划分的。
Browser 浏览器,其实也是一种 Client 客户端,只是这个客户端不需要大家去安装什么应用程序,只需在浏览器上通过 HTTP 请求服务器端相关的资源(网页资源),客户端 Browser 浏览器就能进行增删改查。
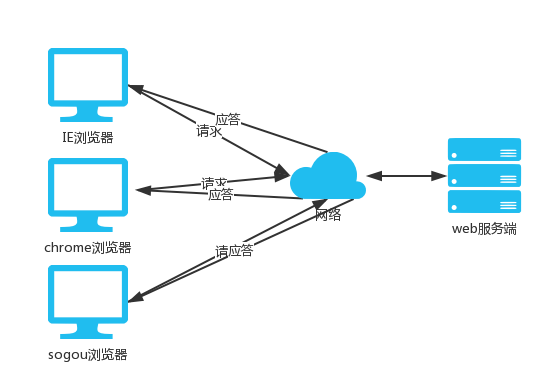
网络基础
计算机网络的发展及基础网络概念
问题:网络到底是什么?计算机之间是如何通信的?
早期 : 联机
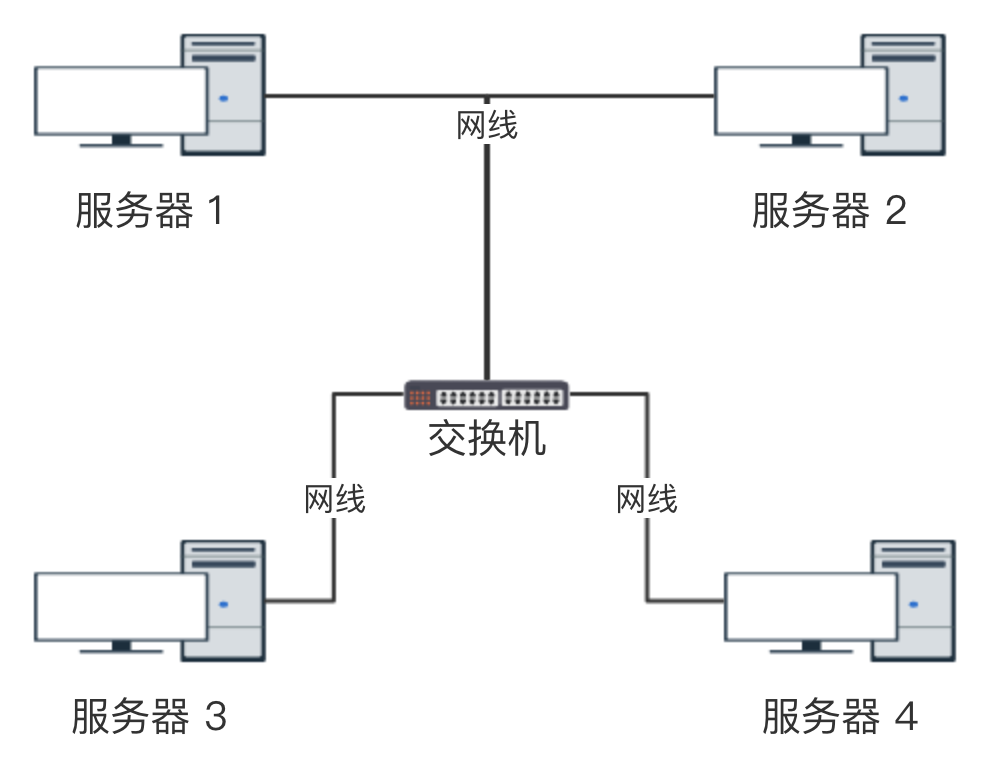
以太网 : 局域网与交换机
广播
主机之间“一对所有”的通讯模式,网络对其中每一台主机发出的信号都进行无条件复制并转发,所有主机都可以接收到所有信息(不管你是否需要),由于其不用路径选择,所以其网络成本可以很低廉。有线电视网就是典型的广播型网络,我们的电视机实际上是接受到所有频道的信号,但只将一个频道的信号还原成画面。在数据网络中也允许广播的存在,但其被限制在二层交换机的局域网范围内,禁止广播数据穿过路由器,防止广播数据影响大面积的主机。
ip 地址与 ip 协议
规定网络地址的协议叫 ip 协议,它定义的地址称之为 ip 地址,广泛采用的 v4 版本即 ipv4,它规定网络地址由 32 位 2 进制表示
范围 0.0.0.0-255.255.255.255
一个 ip 地址通常写成四段十进制数,例:172.16.10.1
mac 地址
head 中包含的源和目标地址由来:ethernet 规定接入 internet 的设备都必须具备网卡,发送端和接收端的地址便是指网卡的地址,即 mac 地址。
mac 地址:每块网卡出厂时都被烧制上一个世界唯一的 mac 地址,长度为 48 位 2 进制,通常由 12 位 16 进制数表示(前六位是厂商编号,后六位是流水线号)
arp 协议 ——查询IP地址和MAC地址的对应关系
地址解析协议,即 ARP(Address Resolution Protocol),是根据 IP 地址获取物理地址的一个 TCP/IP 协议。
主机发送信息时将包含目标 IP 地址的 ARP 请求广播到网络上的所有主机,并接收返回消息,以此确定目标的物理地址。
收到返回消息后将该 IP 地址和物理地址存入本机 ARP 缓存中并保留一定时间,下次请求时直接查询 ARP 缓存以节约资源。
地址解析协议是建立在网络中各个主机互相信任的基础上的,网络上的主机可以自主发送 ARP 应答消息,其他主机收到应答报文时不会检测该报文的真实性就会将其记入本机 ARP 缓存;由此攻击者就可以向某一主机发送伪 ARP 应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个 ARP 欺骗。ARP 命令可用于查询本机 ARP 缓存中 IP 地址和 MAC 地址的对应关系、添加或删除静态对应关系等。相关协议有 RARP、代理 ARP。NDP 用于在 IPv6 中代替地址解析协议。
广域网与路由器
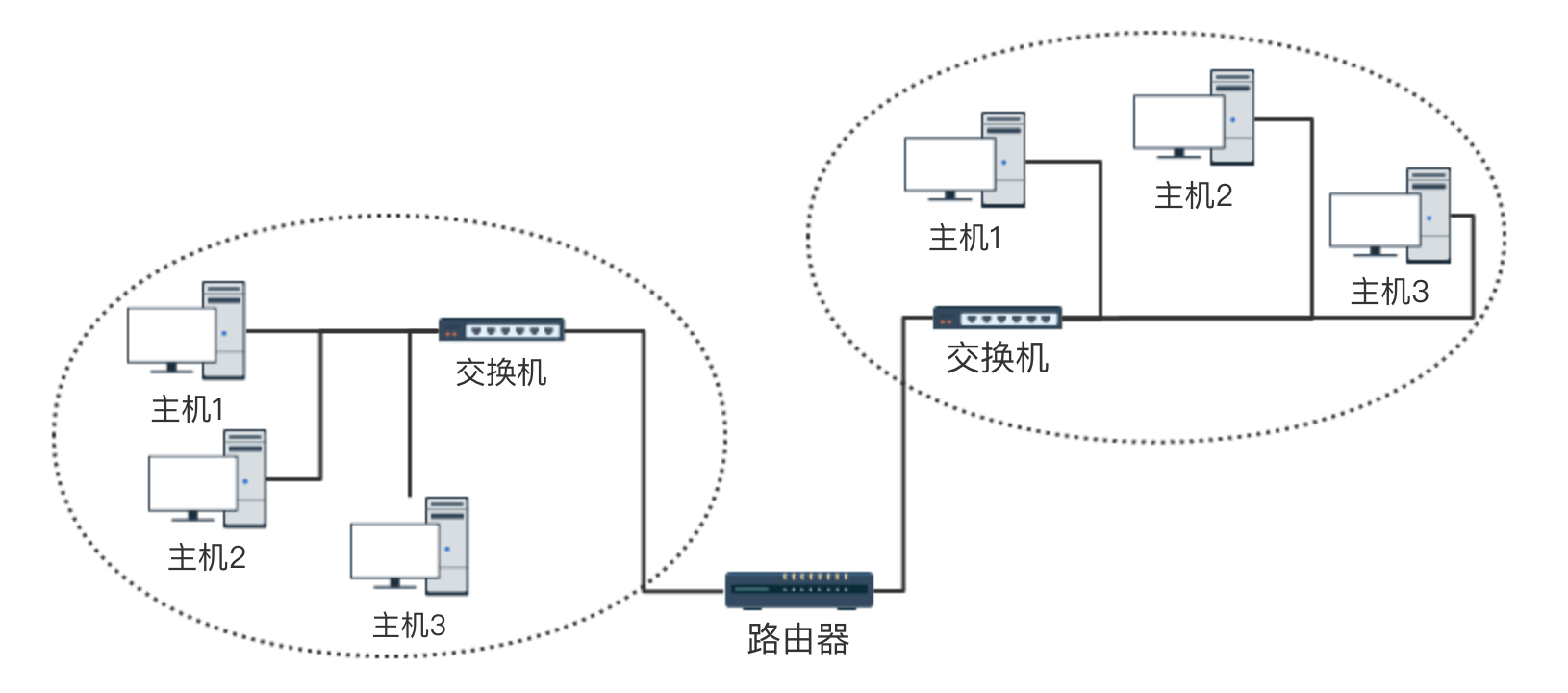
路由器
路由器(Router),是连接因特网中各局域网、广域网的设备,它会根据信道的情况自动选择和设定路由,以最佳路径,按前后顺序发送信号。 路由器是互联网络的枢纽,”交通警察”。目前路由器已经广泛应用于各行各业,各种不同档次的产品已成为实现各种骨干网内部连接、骨干网间互联和骨干网与互联网互联互通业务的主力军。路由和交换机之间的主要区别就是交换机发生在 OSI 参考模型第二层(数据链路层),而路由发生在第三层,即网络层。这一区别决定了路由和交换机在移动信息的过程中需使用不同的控制信息,所以说两者实现各自功能的方式是不同的。
路由器(Router)又称网关设备(Gateway)是用于连接多个逻辑上分开的网络,所谓逻辑网络是代表一个单独的网络或者一个子网。当数据从一个子网传输到另一个子网时,可通过路由器的路由功能来完成。因此,路由器具有判断网络地址和选择 IP 路径的功能,它能在多网络互联环境中,建立灵活的连接,可用完全不同的数据分组和介质访问方法连接各种子网,路由器只接受源站或其他路由器的信息,属网络层的一种互联设备。
局域网
局域网(Local Area Network,LAN)是指在某一区域内由多台计算机互联成的计算机组。一般是方圆几千米以内。局域网可以实现文件管理、应用软件共享、打印机共享、工作组内的日程安排、电子邮件和传真通信服务等功能。局域网是封闭型的,可以由办公室内的两台计算机组成,也可以由一个公司内的上千台计算机组成。
子网掩码
所谓”子网掩码”,就是表示子网络特征的一个参数。它在形式上等同于 IP 地址,也是一个 32 位二进制数字,它的网络部分全部为 1,主机部分全部为 0。比如,IP 地址 172.16.10.1,如果已知网络部分是前 24 位,主机部分是后 8 位,那么子网络掩码就是 11111111.11111111.11111111.00000000,写成十进制就是 255.255.255.0。
知道”子网掩码”,我们就能判断,任意两个 IP 地址是否处在同一个子网络。方法是将两个 IP 地址与子网掩码分别进行 AND 运算(两个数位都为 1,运算结果为 1,否则为 0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
例如
比如,已知IP地址172.16.10.1和172.16.10.2的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算,172.16.10.1:10101100.00010000.00001010.000000001255255.255.255.0:11111111.11111111.11111111.00000000AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0172.16.10.2:10101100.00010000.00001010.000000010255255.255.255.0:11111111.11111111.11111111.00000000AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0结果都是172.16.10.0,因此它们在同一个子网络。
IP 协议的作用主要有两个,一个是为每一台计算机分配 IP 地址,另一个是确定哪些地址在同一个子网络。
总结:
三.网络基础B/SB/S 有什么好?统一了所有应用的入口手机端 为什么B/S没火起来统一了所有应用的入口 —— 微信C/S 架构 几乎包含了所有网络开发的架构形态B/S 架构 也是C/S架构B/S 架构中的client都是browser浏览器统一了所有应用的入口 —— 趋势django tornado flask B/S 架构软件开发网络底层的网卡 mac地址局域网交换机 : 同一个局域网内的机器之间的交流路由器 : 跨局域网机器之间的交流网关ip : 跨局域网的机器之间不能直接通信,只能通过网关ip通信为什幺有局域网:因为IP地址不够用<br>全球的IP地址为0.0.0.0-255.255.255.255,它是有限的。<br>192.168.*.* 内网的保留字段<br>10.*.*.* 内网的保留字段<br>172.16.*.*-172.31.*.* 内网的保留字段8位 2进制asc码 只有 255 个00000001 --> 1ip地址代表了你在一个网络中的位置是一个四位点分十进制范围是 0.0.0.0 - 255.255.255.25511111111.1111111.1111111.1111111mac地址唯一的,为什么要有ip地址?192.168.11.***256台 0-255192.168.***.***256^2192.***.***.***256^3子网掩码网络地址ip和子网掩码ip做按位与运算 如果结果相同 那么说明在同一个网段内#192.168.12.62#11000000.10101000.00001011.00111110#11111111.11111111.11111111.00000000#11000000.10101000.00001011.00000000 == 192.168.0.0#255.255.0.0#192.168.11.94#255.255.0.011000000.10101000.00001011.0101111011111111.11111111.11111111.00000000 == 192.168.0.0

若有收获,就点个赞吧
0 人点赞
