回顾昨天的内容
异常处理
try except 一定要在 except 之后写一些提示或者处理的内容
try:
'''可能会出现异常的代码'''
except ValueError:
'''打印一些提示或者处理的内容'''
except NameError:
'''...'''
# except Exception as e:
# '''打印 e'''
else:
'''try 中的代码正常执行了'''
finally:
'''无论错误是否发生,都会执行这段代码,用来做一些收尾工作'''
一、re 模块
re 模块 可以读懂 你写的正则表达式
根据你写的表达式去执行任务
一般网站注册手机,会验证手机号是否有效 根据手机号码一共 11 位并且是只以 13、14、15、18 开头的数字这些特点,我们用 python 写了如下代码:
判断手机号码是否合法 1
while True:
phone_number = input('please input your phone number: ')
if len(phone_number) == 11 \
and phone_number.isdigit()\
and (phone_number.startswith('13') \
or phone_number.startswith('14') \
or phone_number.startswith('15') \
or phone_number.startswith('18')):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
上面的代码太冗长了
使用正则
import re
phone_number = input('please input your phone number: ')
if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
假如有一文件
一段文字
fefsfsd13838383838
f13838383838
13838383838ffsfsd
fdsa13838383838et13838383838
需要匹配出手机号码,用 if 就不好处理了,需要使用正则
正则表达式是做什么的?
正则表达式 字符串的操作
使用一些规则来检测字符串是否符合我的要求 —— 表单验证
从一段字符串中找到符合我要求的内容 —— 爬虫
网页的内容,最终也是字符串
正则表达式,是专属字符串操作规则
正则表达式不仅在 python 领域,在整个编程届都占有举足轻重的地位。
正则表达式本身也和 python 没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式
在线测试工具 http://tool.chinaz.com/regex/
这个是最好的正则表达式工具,正则可以随时匹配出结果
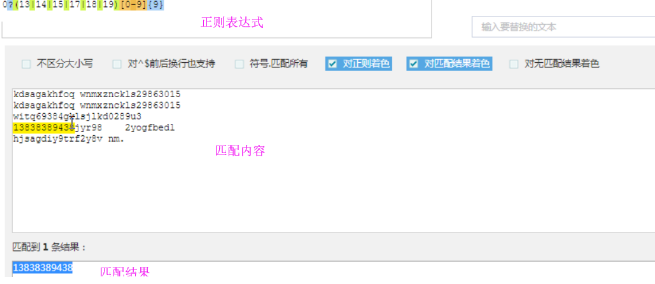
缺点:
如果只会用这个工具,而不会自己写的话,就不行了。
主要是自己写,不要太依赖它。
匹配一个字符串 a
import re
str1 = 'a'
ret = re.match('a',str1)
print(ret)
执行输出:
<_sre.SRE_Match object; span=(0, 1), match='a'>结果是一个匹配对象,请注意结尾的 match=’a’ 表示匹配出了 a
如果没有匹配上,结果为 None
打印匹配结果,使用 group()方法查看
import re
str1 = 'a'
ret = re.match('a',str1)
print(ret.group())
执行输出:a
如果没有匹配上,直接使用 group()方法,会报错
AttributeError: ‘NoneType’ object has no attribute ‘group’
所以得配合 if 判断才行
import re
str1 = 'a'
ret = re.match('ab',str1)
if ret:print(ret.group()) # 即是匹配不上,也不会报错
这种情况,是匹配不上的
import re
str1 = 'a1'
ret = re.match('a11',str1)
if ret:print(ret.group())
结论:
完全相等的字符串都可以匹配上
字符组
字符串用[]表示,它只能匹配一个字符串
字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是 0、1、2...9 这 10 个数之一。
import re
str1 = '2'
ret = re.match('[123abc]',str1)
if ret:print(ret.group())
执行输出:2
import re
str1 = '123'
ret = re.match('[123abc]',str1)
if ret:print(ret.group())
执行输出:1
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
|---|---|---|---|
| [0123456789] | 8 | True | 在一个字符组里枚举合法的所有字符,字符组里的任意一个字符 和”待匹配字符”相同都视为可以匹配 |
| [0123456789] | a | False | 由于字符组中没有”a”字符,所以不能匹配 |
[0-9] |
7 |
True | 也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的 a~f,用来验证十六进制字符 |
字符:
红色部分是比较常用的
量词:
| 量词 | 用法说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复 n 次 |
| {n,} | 重复 n 次或更多次 |
| {n,m} | 重复 n 到 m 次 |
字符在正则表达式中有特殊意义的
[9-0] 是不可以的
import re
str1 = '123'
ret = re.match('[123abc]',str1)
if ret:print(ret.group())
执行报错:
sre_constants.error: bad character range 9-0 at position 1
为啥呢?
re 模块搜查单字符,其字符集合必须按其 ASCII 值(或者说编码值)由小到大排列,否则报错:error: bad character range
[5-9] 这种是可以的
[5.5-9] 这种是不可以的,不允许有小数点
匹配 3 位数字
import re
str1 = '123'
ret = re.match('[1-9][1-9][1-9]',str1)
if ret:print(ret.group())
执行输出:123
第二种写法:
import re
str1 = '123'
ret = re.match('[1-9]{3}',str1) # {3}表示重复3次
if ret:print(ret.group())
执行输出:123
第三种写法:
import re
str1 = '123'
ret = re.match('\d{3}',str1) # \d表示匹配数字
if ret:print(ret.group())
执行输出:123
匹配大写
import re
str1 = 'AUE'
ret = re.match('[A-Z]{3}',str1)
if ret:print(ret.group())
执行输出:AUE
匹配大小写
import re
str1 = 'ilikeSHE'
ret = re.match('[A-Za-z]{8}',str1)
if ret:print(ret.group())
执行输出:ilikeSHE
不能写[A-z],因为 A-z 之间的 ASCII 码,不是连续的。中间还有特殊字符,比如[
[0-9a-fA-F] 表示匹配十六进制
总结:
字符组 字符组代表一个字符位置上可以出现的所有内容
范围 :
根据 asc 码来的,范围必须是从小到大的指向
一个字符组中可以有多个范围
. ^ $
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
|---|---|---|---|
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有”海.”的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配”海.” |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的”海.$” |
* + ? { }
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
|---|---|---|---|
| 李.? | 李杰和李莲英和李二棍子 | 李杰 李莲 李二 |
?表示重复零次或一次,即只匹配”李”后面一个任意字符 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 | *表示重复零次或多次,即匹配”李”后面 0 或多个任意字符 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 | +表示重复一次或多次,即只匹配”李”后面 1 个或多个任意字符 |
| 李.{1,2} | 李杰和李莲英和李二棍子 | 李杰和 李莲英 李二棍 |
{1,2}匹配 1 到 2 次 |
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
|---|---|---|---|
| 李.*? | 李杰和李莲英和李二棍子 | 李 李 李 |
惰性匹配 |
正则表示式,不能写在后面。比如海^.
它只能出现在开始位置不能在中间或者后面位置
.*表示匹配所有
惰性匹配
import re
str1 = '李杰和李莲英和李二棍子'
ret = re.match('李.{2,}?',str1) # 最多2次
if ret:print(ret.group())
执行输出:李杰和
匹配多个数字
import re
str1 = '22675853324354'
ret = re.match('\d+',str1)
if ret:print(ret.group())
执行输出:22675853324354
匹配 11 位以上,不能低于 11 位
import re
str1 = '12345678910111'
ret = re.match('\d{11,}',str1)
if ret:print(ret.group())
执行输出:12345678910111
匹配 11~15 位,如果符合 15 位,优先显示 15
import re
str1 = '12345678910111213'
ret = re.match('\d{11,15}',str1)
if ret:print(ret.group())
执行输出:123456789101112
匹配所有数字
import re
str1 = '12345678910111213'
ret = re.match('\d*',str1) # *表示零次或者更多次
if ret:print(ret.group())
执行输出:12345678910111213
匹配一位数字
import re
str1 = '1233335446575865'
ret = re.match('\d?',str1) # ? 重复零次或者一次
if ret:print(ret.group())
执行输出:1
重点:
量词只能约束一个字符组
这里是约束[A-Z]
import re
str1 = '2A32345446'
ret = re.match('\d[A-Z]*',str1)
if ret:print(ret.group())
执行输出:2A
约束\d 和[A-Z]
import re
str1 = '22323A454W46'
ret = re.match('\d*[A-Z]*',str1)
if ret:print(ret.group())
执行输出:22323A
元字符,一般和量词使用
分组 ()与 或 |[^]
身份证号码是一个长度为 15 或 18 个字符的字符串,如果是 15 位则全部由数字组成,首位不能为 0;如果是 18 位,则前 17 位全部是数字,末位可能是数字或 x,下面我们尝试用正则来表示:
步骤分析:
1.匹配非零的,使用 [1-9]
2.匹配 15 位数字,使用 [1-9]\d{14}
3.匹配 18 位数字,使用 [1-9]\d{16}[0-9x],优化成 [1-9]\d{16}[\dx]
4.将 15 位和 18 位的,一并判断,使用| ,规则为 [1-9]\d{16}[\dx]|[1-9]\d{14}
如果两个正则表达式之间用”或”连接,且有一部分正则规则相同,
那么一定要把规则长的放在前面
测试号码:
import re
str1 = '110101198001017'
ret = re.match('[1-9]\d{16}[\dx]|[1-9]\d{14}',str1)
if ret:print(ret.group())
执行输出:110101198001017
再测试一个
import re
str1 = '11010119800101702x'
ret = re.match('[1-9]\d{16}[\dx]|[1-9]\d{14}',str1)
if ret:print(ret.group())
执行输出:11010119800101702x
分组
import re
str1 = '1101011980010172345'
ret = re.match('[1-9]\d{14}(\d{2}[\dx])?',str1) # 最多匹配18位数字
if ret:print(ret.group())
执行输出:110101198001017234
如果对一组正则表达式整体有一个量词约束,就将这一组表达式分成一个组
在组外进行量词约束
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\d 和\s 等,如果要在正则中匹配正常的”\d”而不是”数字”就需要对”\”进行转义,变成’\‘。
在 python 中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次”\d”,字符串中要写成’\d’,那么正则里就要写成”\\d”,这样就太麻烦了。这个时候我们就用到了 r’\d’这个概念,此时的正则是 r’\d’就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
|---|---|---|---|
| \d | \d | False | 因为在正则表达式中\是有特殊意义的字符,所以要匹配\d 本身,用表达式\d 无法匹配 |
| \d | \d | True | 转义\之后变成\,即可匹配 |
| “\\d” | ‘\d’ | True | 如果在 python 中,字符串中的’\’也需要转义,所以每一个字符串’\’又需要转义一次 |
| r’\d’ | r’\d’ | True | 在字符串之前加 r,让整个字符串不转义 |
匹配\n,需要使用\n
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
|---|---|---|---|
| <.*> |

若有收获,就点个赞吧
0 人点赞
