- 昨日内容回顾
- 一、单表操作
- 添加表纪录
- 查询表纪录
- 查询 API
- all() 查询所有结果
- filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
- first(): 返回第一条记录
- last(): 返回最后一条记录
- get(**kwargs): 返回与所给筛选条件相匹配的对象
- exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
- order_by(*field): 对查询结果排序
- reverse(): 对查询结果反向排序
- count(): 返回数据库中匹配查询的对象数量
- exists(): 如果 QuerySet 包含数据,就返回 True,否则返回 False
- values(*field): 返回一个 ValueQuerySet
- values_list(*field): values 返回的是一个字典序列
- distinct(): 从返回结果中剔除重复纪录
- 基于双下划线的模糊查询
- 删除表纪录
- 修改表纪录
- 章节作业
昨日内容回顾
1. {% include '' %}2. extendbase.html:<html>...............{% block content%}{% endblock%}</html>index.html:{% extend 'base.html'%}<p>python</p>{% block content%}<p>hello</p>{% endblock%}子网页,也可以设置css和js。比如:{% block css %}{% endblock %}{% block js %}{% endblock %}models:ORMclass ----- 表属性变量 ----- 字段名称属性值 ----- 字段约束对象 ------ 记录创建表的流程1. 在models里设计模型类class Book(models.Model):nid=models.AutoField(primary_key=True)...2. 更改数据库为mysql,在settings中:2.1 先注册appINSTALLED_APPS = [...'app01',]2.2 更改数据库引擎DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql', # 数据库引擎mysql'NAME': 'book', # 你要存储数据的库名,事先要创建之'USER': 'root', # 数据库用户名'PASSWORD': '', # 密码'HOST': 'localhost', # 主机'PORT': '3306', # 数据库使用的端口}}3. 创建数据库book4. 必须安装2个模块pip3 install pymysqlpip3 install mysqlclient5.python manage.py makemigrations(同步)python manage.py migrate(执行sql)
一、单表操作
添加表纪录
create(**kwargs) 建立新对象
返回值是添加的 model 对象
方式 1
create 方法的返回值 book_obj 就是插入 book 表中的 python 葵花宝典这本书籍纪录对象
book_obj=Book.objects.create(title="python 葵花宝典",state=True,price=100,publish="苹果出版社",pub_date="2012-12-12")
方式 2
book_obj=Book(title="python葵花宝典",state=True,price=100,publish="苹果出版社",pub_date="2012-12-12")book_obj.save()
举例:
修改 settings.py,打印 orm 转换过程中的 sql。最后一行,添加如下内容:
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console':{'level':'DEBUG','class':'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level':'DEBUG',},}}
修改 urls.py,增加 add 路径
from app01 import viewsurlpatterns = [path('admin/', admin.site.urls),path('add/', views.add),]
models.py 内容如下:
class Book(models.Model):nid = models.AutoField(primary_key=True)title = models.CharField(max_length=32, unique=True)price = models.DecimalField(max_digits=8, decimal_places=2)pub_date = models.DateField()publish = models.CharField(max_length=32)
表已经生成了,但是表记录是空的。
Pycharm 有自带的工具,可以操作 MySQL。点击右侧的 Database
点击加号—>Data Source—>MySQL
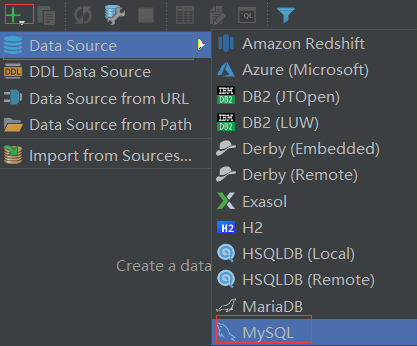
这里提示要安装 MySQL 驱动,点击旁边的 Download

正在下载安装

出现下面的效果,表示安装成功。

点击测试连接,出现 Successful,表示连接成功。

双击展开,就可以看到 app01_book 表了。虽然 models.py 里面的类名是 Book,但是实际创建的表名是应用名+models.py 里面的类名。用下划线分割,大写字母会变成小写。

修改 views.py,增加 add 视图函数。
注意,需要导入 models 模块
这里面的 title,price…变量是和 Book 类的属性是一一对应的,否则会报错。
from django.shortcuts import render,HttpResponsefrom app01.models import Book# Create your views here.def add(request):book = Book(title="北京折叠",price="11.11",pub_date="2012-12-12",publish="苹果出版社")book.save()return HttpResponse("添加成功")
这是第一种方式:实例化一个对象,并传参。
pub_date 的值,必须是 xxxx_xx_xx 格式。用下划线分隔,其他符合是不可以的。
访问网页,效果如下:

双击右边的 book 表,查看表记录。点击刷新按钮,就可以看到数据了。

注意:只要 django 执行了视图函数的那 2 句代码,就可以插入一条记录。
并不一定,非要在 views.py 里面才行。具体放在哪里,是根据业务逻辑来处理。
一般请求下,是放在 views.py 里面。
查看控制台输出信息,会看到一条 insert 语句
(0.001) INSERT INTO `app01_book` (`title`, `price`, `pub_date`, `publish`) VALUES ('北京折叠', '11.11', '2012-12-12', ' 苹果出版社'); args=['北京折叠', '11.11', '2012-12-12', '苹果出版社']
那么 book.save(),就是执行上面这句 SQL,来插入一条记录的。
第二种方式:推荐使用
objects:表示管理器。
Book.objects:表示管理 book 表。
book.objects.create:表示增加操作。
def add(request):book = Book.objects.create(title="放风筝的人", price="14.11", pub_date="2017-12-12", publish="苹果出版社")print(book)print(book.title)return HttpResponse("添加成功")
这种方式,一行代码,就搞定了。
create 是有返回值的,create 内部里面有 save。
访问 add 页面

查看控制台
(0.002) INSERT INTO `app01_book` (`title`, `price`, `pub_date`, `publish`) VALUES ('放风筝的人', '14.11', '2017-12-12', '苹果出版社'); args=['放风筝的人', '14.11', '2017-12-12', '苹果出版社']Book object (2)放风筝的人
create 的返回值是一个类对象,比如:Book object
book_obj.title 的返回值,就是 create 里面的值。
create 执行的 SQL 和 save 是一样的。区别是 create 代码更精简!
如果 create 少一个字段,比如 price 呢?测试一下
def add(request):book_obj = Book.objects.create(title="放风筝的人2",pub_date="2018-12-12",publish="苹果出版社")return HttpResponse("添加成功")
访问页面,提示 price 不允许为空
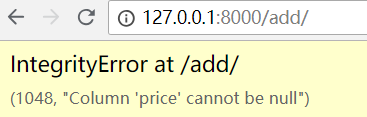
更改 models.py 里面的 price 属性,设置价格属性为空
添加字段 is_pub,表示是否发布
class Book(models.Model):nid = models.AutoField(primary_key=True)title = models.CharField(max_length=32, unique=True)price = models.DecimalField(max_digits=8, decimal_places=2,null=True)pub_date = models.DateField()publish = models.CharField(max_length=32)is_pub = models.BooleanField()
Pycharm 有一个工具,不同执行繁琐的同步命令
Tools—>Run manage.py Task…
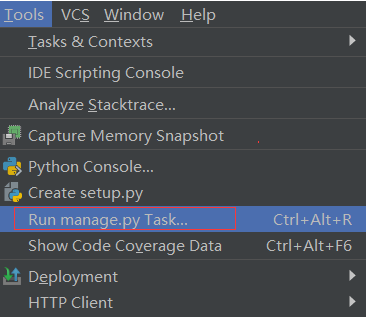
输入 ma,就会有提示信息。选择 makemigrations,直接回车
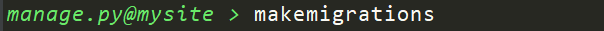
最后输出如下信息

意思就是 is_pub 字段必须设置一个默认值
重新修改 models.py 下的 Book 类,增加默认值
is_pub = models.BooleanField(default=False)
关闭下面的小窗口,重新运行命令 makemigrations
输出下面信息,表示成功了

执行 migrate
查看表记录,发现多了一个 is_pub 字段。BooleanField 对应的 MySQL 类型是 tinyint(1)
那么 False 对应的值是 0,true 对应的值是 1。

再次刷新页面,就可以了

查看表记录,点击 刷新按钮
刷新按钮
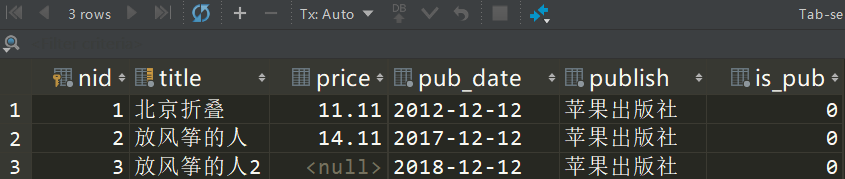
再次刷新页面,会报错!因为 title 字段是唯一的。
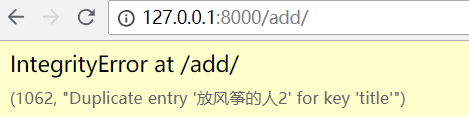
修改 views 里面的 add 视图函数
book_obj = Book.objects.create(title=”放风筝的人 3”, pub_date=”2018-12-12”, publish=”苹果出版社”)
再次刷新页面,就可以了。查看表记录,刷新一下

注意:在开发项目时,最好打开日志,这样可以查看 ORM 转换的 SQL 语句,方便后面的调试。
查询表纪录
查询 API
<1> all(): 查询所有结果<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象<5> order_by(*field): 对查询结果排序<6> reverse(): 对查询结果反向排序<8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。<9> first(): 返回第一条记录<10> last(): 返回最后一条记录<11> exists(): 如果QuerySet包含数据,就返回True,否则返回False<12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列<13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列<14> distinct(): 从返回结果中剔除重复纪录
all() 查询所有结果
它返回的是 QuerySet 数据类型对象,它是 django orm 特有的数据类型。
数据格式为:[model 对象 1,model 对象 2,model 对象 3 …]
它和下面的 animal_list 类似。先是一个列表,列表的元素是一个对象
class Annimal(object):def __init__(self, name, age):self.name = nameself.age = agedef call(self):return "汪汪汪"dog = Annimal("旺财", 3)cat = Annimal("小雪", 4)duck = Annimal("小黄", 5)animal_list = [dog, cat, duck]
一个对象,就是一条记录。有多少条记录,就有多少个对象。
举例:
修改 urls.py,增加 query 路径
urlpatterns = [path('admin/', admin.site.urls),path('add/', views.add),path('query/', views.query),]
修改 views.py,增加 query 视图函数
def query(request):ret = Book.objects.all()print(ret)return HttpResponse("查询成功")
访问页面,效果如下:

查看控制台输出信息:
(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` LIMIT 21; args=()<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (5)>]>
它执行的 sql,就是 select…。返回结果是一个 QuerySet 数据类型
它是一个列表,里面放了多个对象。个数取决于返回的行数!
QuerySet 和 model 对象的区别:
只有 model 对象,才能调用属性。
queryset 不能直接调用属性,因为它是一个列表。
既然是列表,就可以使用 for 循环,打印 title 属性。
修改 query 视图函数
def query(request):book_list = Book.objects.all()print(book_list)for obj in book_list:print(obj.title) # 打印title属性return HttpResponse("查询成功")
刷新页面,查看控制台,就会有 4 个书名
北京折叠放风筝的人放风筝的人2放风筝的人3
filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
filter 可以用指定条件来查询,它会返回一条或者多条记录。
它的返回值是 QuerySet 数据类型对象
举例:查看标题为北京折叠的记录
修改 query 视图函数
def query(request):ret = Book.objects.filter(title='北京折叠')print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台信息
(0.001) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`title` = '北京折叠' LIMIT 21; args=('北京折叠',)<QuerySet [<Book: Book object (1)>]>
它执行的 sql,是用了 where 条件的。
注意,下面这行代码,不能直接执行
print(ret.price)
刷新页面,报错。QuerySet 不能直接调用属性,即使它只有一个对象

虽然可以通过切片来调用属性,但是不推荐使用。
因为它的长度是不固定的。
需要使用 for 循环来执行。
first(): 返回第一条记录
first 用来取一条记录,如果返回结果有多条,只会取第一条。
它的返回结果是 model 对象。
修改 query 视图函数
def query(request):obj = Book.objects.all().first()print(obj)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` ORDER BY `app01_book`.`nid` ASC LIMIT 1; args=()Book object (1)北京折叠
查看 sql,发现它使用 order by 排序。对主键 nid,做了升序,并且使用 limit 1 返回一条结果。
ret 的返回结果一个是 model 对象,那么就可以直接调用对象了。所以输出:北京折叠
学习 API 接口,重要的是它的返回值是什么
last(): 返回最后一条记录
last 用来取最后一条记录,如果返回结果有多条,只会取最后一条。
它的返回结果是 model 对象。可以直接调用属性!
修改 query 视图函数
def query(request):obj = Book.objects.all().last()print(obj)print(obj.title)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.002) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` ORDER BY `app01_book`.`nid` DESC LIMIT 1; args=()Book object (5)放风筝的人3
查看 sql,发现它使用 order by 排序。对主键 nid,做了降序,并且使用 limit 1 返回一条结果。
所以最后输出:放风筝的人 3
还可以对 all()进行切片操作
def query(request):obj = Book.objects.all()[1:3]print(obj)for i in obj:print(i.title)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.001) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` LIMIT 2 OFFSET 1; args=()<QuerySet [<Book: Book object (2)>, <Book: Book object (3)>]>(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` LIMIT 2 OFFSET 1; args=()放风筝的人放风筝的人2
[1:3],返回 2 条记录。切片原则:顾头不顾尾。
get(**kwargs): 返回与所给筛选条件相匹配的对象
返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
它的返回结果是一个 model 对象。
举例:查询 nid 为 1 的记录
修改 query 视图函数
def query(request):obj = Book.objects.get(nid=2)print(obj)print(obj.title)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.001) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`nid` = 2; args=(2,)Book object (2)放风筝的人
查看 sql,发现它对应的 where 条件是 nid = 2。返回结果的 title 属性为:放风筝的人
举例:查询结果大于 1 时
查看表记录,修改第 3 条记录的价格为 14.11,并点击上面的提交按钮
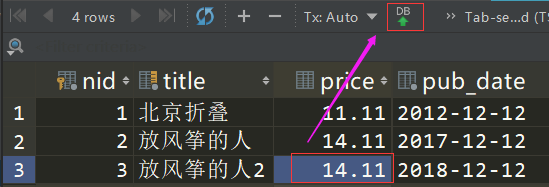
修改 query 视图函数,使用 get 查询价格等于 14.11 的记录。
def query(request):obj = Book.objects.get(price=14.11)print(obj)return HttpResponse("查询成功")
刷新页面,报错!提示返回结果过多,不能大于 2 条。
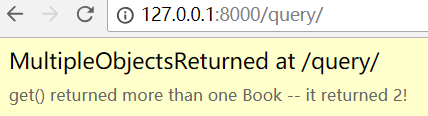
举例:查询结果大于 1 时,也就是记录不存在时
修改 query 视图函数,查询价格等于 110
def query(request):obj = Book.objects.get(price=110)print(obj)return HttpResponse("查询成功")
刷新页面,报错!提示查询结果不存在
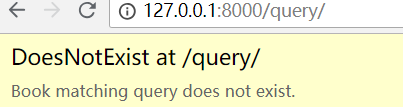
下面的代码,也可以返回一条记录
obj = Book.objects.filter(nid=2).first()
但是使用 first,它会执行 order by。上面的代码转为 SQL 为:
SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`nid` = 2 ORDER BY `app01_book`.`nid` ASC LIMIT 1;
那么它的效果不如直接使用 get!就一台记录,还排序干啥?
总结:
使用 get 有且只有一个结果时才有意义。
推荐使用 get 时,利用主键查询,因为主键是唯一的。
exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
exists 用来做排除的,它的返回结果是 QuerySet
举例:查询价格不等于 100 的
修改 query 视图函数
def query(request):obj = Book.objects.exclude(price=100)print(obj)for i in obj:print(i.title,i.price)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (5)>]>(0.001) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE NOT (`app01_book`.`price` = '100' AND `app01_book`.`price` IS NOT NULL); args=(Decimal('100'),)北京折叠 11.11放风筝的人 14.11放风筝的人2 14.11放风筝的人3 None
查看 sql,发现它对应的 where 条件用了 Not,返回结果是 QuerySet
order_by(*field): 对查询结果排序
order_by,默认是升序,它的返回结果是 QuerySet
举例:查询所有书籍,按照价格排序
修改表记录,效果如下:

修改 query 视图函数
def query(request):obj = Book.objects.order_by("price")print(obj)for i in obj:print(i.title,i.price)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: Book object (5)>, <Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>]>(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` ORDER BY `app01_book`.`price` ASC; args=()水浒传 11.00北京折叠 11.11放风筝的人 14.11西游记 233.00
如果指定的字段值为空,则按照主键排序。
每次 for 循环查看结果,太麻烦了。可以在 models.py 里面增加一个str方法。
修改 models.py,增加str方法,完整代码如下:
from django.db import models# Create your models here.class Book(models.Model):nid = models.AutoField(primary_key=True)title = models.CharField(max_length=32, unique=True)price = models.DecimalField(max_digits=8, decimal_places=2,null=True)pub_date = models.DateField()publish = models.CharField(max_length=32)is_pub = models.BooleanField(default=False)def __str__(self):return '{}:{}'.format(self.title,self.price)
修改 views.py 下的 query 方法,代码如下:
def query(request):obj = Book.objects.order_by("price")print(obj)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.001) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` ORDER BY `app01_book`.`price` ASC LIMIT 21; args=()<QuerySet [<Book: 水浒传:11.00>, <Book: 北京折叠:11.11>, <Book: 放风筝的人:14.11>, <Book: 西游记:233.00>]>
可以直接看到 title 和价格!
注意:只有 QuerySet 数据类型对象,才能调用 order_by
reverse(): 对查询结果反向排序
它的返回结果是 QuerySet
举例:
修改 query 方法
def query(request):obj = Book.objects.all().order_by("price").reverse()print(obj)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: 西游记:233.00>, <Book: 放风筝的人:14.11>, <Book: 北京折叠:11.11>, <Book: 水浒传:11.00>]>(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` ORDER BY `app01_book`.`price` DESC LIMIT 21; args=()
它的 sql 语句用的是 desc
count(): 返回数据库中匹配查询的对象数量
它的返回结果数据类型是 int
它是 queryset 的终止函数。为什么呢?因为它不能进行链式操作!
下面这种,就属于链式操作。因为 queryset 可以调用 API 接口,只要前一个接口的返回值是 queryset,它可以可以一直调用 API 接口,除非遇到返回值不是 queryset 的情况下,链式操作,才可以终止。因为 count 的返回值是 int,所以到这里,就结束了!不能再调用 API 接口了!
Book.objects.all().filter(price__gt=100).order_by("pirce").count()
举例:
修改 query 视图函数
def query(request):obj = Book.objects.all().count()print(obj)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
4(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT COUNT(*) AS `__count` FROM `app01_book`; args=()
obj 的返回结果为 4
exists(): 如果 QuerySet 包含数据,就返回 True,否则返回 False
它的返回结果是一个布尔值
举例:如果表里面有书,输入 ok,否则输出 none
修改 query 视图函数,使用常规方法
def query(request):ret = Book.objects.all()if ret:print('ok')return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
ok(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None(0.001) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book`; args=()
ret 结果为 ok,它使用全表查询,但是这样有一个 bug
如果数据库有 1000 万本,这样一查,数据库就崩溃了。
修改 query 视图函数,使用 exists
def query(request):ret = Book.objects.all().exists()if ret:print('ok')return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
ok(0.000) SELECT @@SQL_AUTO_IS_NULL; args=None(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.001) SELECT (1) AS `a` FROM `app01_book` LIMIT 1; args=()
ret 结果为 ok,它用 limit 1。它只查询了一条记录!
即使数据库记录过多,也不影响。这样才是合理的!
上述这些 API 方法,都是 QuerySet 在调用
下面即将讲到的 values,values_list,distinct。是一系列操作!
values(*field): 返回一个 ValueQuerySet
它是一个特殊的 QuerySet,运行后得到的并不是一系列 model 的实例化对象,而是一个可迭代的字典序列
它的返回结果是一个特殊的 QuerySet,列表每一个元素都是字典
除了使用 for 循环之外,还有一个更好的方式。使用 values,它内部封装了 for 循环
举例:查询所有书籍名称
修改 query 视图函数
def query(request):ret = Book.objects.all().values("title")print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT `app01_book`.`title` FROM `app01_book` LIMIT 21; args=()<QuerySet [{'title': '北京折叠'}, {'title': '放风筝的人'}, {'title': '水浒传'}, {'title': '西游记'}]>
values 返回的是 QuerySet,列表的每一个元素都是字典。
values 可以接收多个参数,比如
ret = Book.objects.all().values("title","price")
字典的 key,就是参数。一个字典,对应一条记录。
跟上面讲的 QuerySet 区别就在于:
不加 values,QuerySet 存放的是 model 对象。
加了 values 之后,QuerySet 存放的是字典。
查询某一个字段时,推荐使用 values****
values_list(*field): values 返回的是一个字典序列
它与 values()非常相似,它返回的是一个元组序列
它的返回结果是一个特殊的 QuerySet,列表每一个元素都是元组
举例:
修改 query 视图函数
def query(request):book_list = Book.objects.all().values_list("title","price","pub_date")print(book_list)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date` FROM `app01_book` LIMIT 21; args=()<QuerySet [('北京折叠', Decimal('11.11'), datetime.date(2012, 12, 12)), ('放风筝的人', Decimal('14.11'), datetime.date(2017, 12, 12)), ('西游记', Decimal('233.00'), datetime.date(2018, 7, 1)), ('水浒传', Decimal('11.00'), datetime.date(2018, 7, 2))]>
values_list 和 values 的区别在于:values_list 的类型是元组,vallues 是字典。
distinct(): 从返回结果中剔除重复纪录
它的返回结果是 QuerySet,注意:是一个常规的 QuerySet
修改表记录,将前 2 本书的价格修改为一样的。

使用原生 sql 查询价格,去除重复的值
mysql> select distinct(price) from app01_book;+--------+| price |+--------+| 100.00 || 233.00 || 11.00 |+--------+3 rows in set (0.00 sec)
如果使用 distinct 对主键做去重,是没有意义的。因为主键是唯一的!
mysql> select distinct(nid) from app01_book;+-----+| nid |+-----+| 1 || 2 || 5 || 3 |+-----+4 rows in set (0.01 sec)
对所有字段做去重,也是没有意义的,因为每一条记录,不可能有重复的,这不还有主键嘛
修改 query 视图函数
def query(request):ret = Book.objects.all().distinct()print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: 北京折叠:100.00>, <Book: 放风筝的人:100.00>, <Book: 西游记:233.00>, <Book: 水浒传:11.00>]>(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT DISTINCT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` LIMIT 21; args=()
所有记录都有了,毫无意义
举例:查看所有书籍的价格,结果是不重复的
修改 query 视图函数
def query(request):ret = Book.objects.all().values("price").distinct()print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT DISTINCT `app01_book`.`price` FROM `app01_book` LIMIT 21; args=()<QuerySet [{'price': Decimal('100.00')}, {'price': Decimal('233.00')}, {'price': Decimal('11.00')}]>
举例:查看所有书籍的价格以及出版社,价格和出版社同时不能重复
修改 query 视图函数
def query(request):ret = Book.objects.all().values("price","publish").distinct()print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [{'publish': '苹果出版社', 'price': Decimal('100.00')}, {'publish': '橘子出版社', 'price': Decimal('233.00')}, {'publish': '橘子出版社', 'price': Decimal('11.00')}]>(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.001) SELECT DISTINCT `app01_book`.`price`, `app01_book`.`publish` FROM `app01_book` LIMIT 21; args=()
发现结果只有 3 条,它使用了组合去重。2 个字段,同时不唯一!
基于双下划线的模糊查询
Book.objects.filter(price__in=[100,200,300])Book.objects.filter(price__gt=100)Book.objects.filter(price__lt=100)Book.objects.filter(price__range=[100,200])Book.objects.filter(title__contains="python")Book.objects.filter(title__icontains="python")Book.objects.filter(title__startswith="py")Book.objects.filter(pub_date__year=2012)
字段名__gt(大于)
举例:查询价格大于 100 的
不能这么写
ret = Book.objects.filter(price>100)
正确写法:
def query(request):ret = Book.objects.filter(price__gt=100)print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: 西游记:233.00>]>(0.001) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`price` > '100' LIMIT 21; args=(Decimal('100'),)
价格大于 100 的,只有西游记
字段名__lt(小于)
举例:查询价格小于 100 的
修改 query 视图函数
def query(request):ret = Book.objects.filter(price__lt=100)print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`price` < '100' LIMIT 21; args=(Decimal('100'),)<QuerySet [<Book: 水浒传:11.00>]>
价格小于 100 的,只有水浒传
字段名__lte(小于等于)
举例:查询价格小于等于 100 的
修改 query 视图函数
def query(request):ret = Book.objects.filter(price__lte=100)print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: 北京折叠:100.00>, <Book: 放风筝的人:100.00>, <Book: 水浒传:11.00>]>(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT VERSION(); args=None(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`price` <= '100' LIMIT 21; args=(Decimal('100'),)
价格小于等于 100 的,有北京折叠,放风筝的人,水浒传
字段名__gte(大于等于)
举例:查询价格小于等于 100 的
修改 query 视图函数
def query(request):ret = Book.objects.filter(price__gte=100)print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: 北京折叠:100.00>, <Book: 放风筝的人:100.00>, <Book: 西游记:233.00>]>(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.001) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`price` >= '100' LIMIT 21; args=(Decimal('100'),)
价格小于等于 100 的,有北京折叠,放风筝的人,西游记
字段名__in(支持多个选择)
举例:查询价格分别等于 100,200,300 的记录
修改 query 视图函数
def query(request):ret = Book.objects.filter(price__in=[100,200,300])print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`price` IN ('200', '100', '300') LIMIT 21; args=(Decimal('200'), Decimal('100'), Decimal('300'))[27/Jun/2018 20:58:08] "GET /query/ HTTP/1.1" 200 12<QuerySet [<Book: 北京折叠:100.00>, <Book: 放风筝的人:100.00>]>
价格等于 100,200,300 的有 北京折叠,放风筝的人
字段名__range(介于两个值之间的数据范围)
举例:查询价格在 100 到 233 之间的记录
修改 query 视图函数
def query(request):ret = Book.objects.filter(price__range=[100,300])print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: 北京折叠:100.00>, <Book: 放风筝的人:100.00>, <Book: 西游记:233.00>]>(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`price` BETWEEN '100' AND '300' LIMIT 21; args=(Decimal('100'), Decimal('300'))
价格在 100 到 233 之间的有 北京折叠,放风筝的人,西游记
字段名__startswith(以什么开头的)
举例:查询以”北京”开头的书名有哪些
修改 query 视图函数
def query(request):ret = Book.objects.filter(title__startswith="北京")print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`title` LIKE BINARY '北京%' LIMIT 21; args=('北京%',)<QuerySet [<Book: 北京折叠:100.00>]>
以”北京”开头的书名的有 北京折叠
字段名__contains(以什么结尾)
举例:查询书名包含“传”的有哪些
修改 query 视图函数
def query(request):ret = Book.objects.filter(title__contains="传")print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
<QuerySet [<Book: 水浒传:11.00>]>(0.001) SELECT @@SQL_AUTO_IS_NULL; args=None(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.001) SELECT VERSION(); args=None(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`title` LIKE BINARY '%传%' LIMIT 21; args=('%传%',)
书名包含“传”的有 水浒传
字段名__year(查询某年)
举例:查询出版日期是 2018 年的有哪些
修改 query 视图函数
def query(request):ret = Book.objects.filter(pub_date__year="2018")print(ret)return HttpResponse("查询成功")
刷新页面,查看控制台输出信息:
(0.000) SELECT `app01_book`.`nid`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`pub_date`, `app01_book`.`publish`, `app01_book`.`is_pub` FROM `app01_book` WHERE `app01_book`.`pub_date` BETWEEN '2018-01-01' AND '2018-12-31' LIMIT 21; args=('2018-01-01', '2018-12-31')<QuerySet [<Book: 西游记:233.00>, <Book: 水浒传:11.00>]>
出版日期是 2018 年的有 西游记,水浒传
删除表纪录
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:
model_obj.delete()
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
它的返回值是元组,元组第一个值,是执行状态。1 表示成功,0 表示失败!
例如,下面的代码将删除 pub_date 是 2005 年的 Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1)# This will delete the Blog and all of its Entry objects.b.delete()
要注意的是:delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
如果不想级联删除,可以设置为:
pubHouse = models.ForeignKey(to='Publisher', on_delete=models.SET_NULL, blank=True, null=True)
举例:删除价格等于 100 的
修改 urls.py,增加 delbook 路径
urlpatterns = [path('admin/', admin.site.urls),path('add/', views.add),path('query/', views.query),path('change/', views.change),path('delbook/', views.delbook),]
修改 views.py,增加 delbook 视图函数
注意:修改是基于查询的结果来修改的。所以是先有查询,再有修改!
def delbook(request):ret = Book.objects.filter(price=100).delete()print(ret)return HttpResponse("删除成功")
访问页面

查看控制台输出信息:
(0.001) DELETE FROM `app01_book` WHERE `app01_book`.`price` = '100'; args=(Decimal('100'),)(1, {'app01.Book': 1})
输出 1,表示删除成功!
查看表记录,点击刷新按钮,发现少了一条记录!

QuerySet 和 model 都可以调用 delete
举例:查询价格小于 100 的,并将第一条记录删除
修改 delbook 视图函数
def delbook(request):ret = Book.objects.filter(price__lte=100).delete()print(ret)return HttpResponse("删除成功")
查看控制台输出信息:
(0.000) DELETE FROM `app01_book` WHERE `app01_book`.`price` <= '100'; args=(Decimal('100'),)[27/Jun/2018 21:41:49] "GET /delbook/ HTTP/1.1" 200 12(1, {'app01.Book': 1})
输出结果为 1,说明删除成功了!
查看表记录,点击刷新按钮,发现少了一条记录!

举例 3:根据 url 的 id 值,来删除对应的记录
如果 url 的 id 为 2,就删除 nid 为 2 的记录
修改 urls.py,为 delbook 增加有名分组
注意:要导入 re_path 模块,完整代码如下:
from django.contrib import adminfrom django.urls import path,re_pathfrom app01 import viewsurlpatterns = [path('admin/', admin.site.urls),path('add/', views.add),path('query/', views.query),path('change/', views.change),re_path('delbook/(?P<id>\d+)', views.delbook),]
修改 delbook 视图函数
def delbook(request,id):ret = Book.objects.filter(nid=id).delete()print(ret)return HttpResponse("删除成功")
访问 url: http://127.0.0.1:8000/delbook/3

查看控制台输出信息:
(0.001) DELETE FROM `app01_book` WHERE `app01_book`.`nid` = 3; args=(3,)(1, {'app01.Book': 1})
输出结果为 1,说明删除成功了!
查看表记录,点击刷新按钮,发现少了一条记录!

如果删除一条不存在的记录呢?
访问 url: http://127.0.0.1:8000/delbook/4

查看控制台输出信息:
(0, {'app01.Book': 0})(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.001) SELECT VERSION(); args=None(0.001) DELETE FROM `app01_book` WHERE `app01_book`.`nid` = 4; args=(4,)
输出结果为 0,说明删除失败了!
但是页面提示删除成功是不对的。
修改 delbook 视图函数
def delbook(request,id):ret = Book.objects.filter(nid=id).delete()print(ret)print(ret,type(ret))if ret[0]:return HttpResponse("删除成功")else:return HttpResponse("删除失败")
再次访问 url: http://127.0.0.1:8000/delbook/4

查看控制台输出信息:
(0, {'app01.Book': 0})(0.001) SELECT @@SQL_AUTO_IS_NULL; args=None(0, {'app01.Book': 0}) <class 'tuple'>(0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None(0.000) SELECT VERSION(); args=None(0.000) DELETE FROM `app01_book` WHERE `app01_book`.`nid` = 4; args=(4,)
它的返回值是一个元组,通过取第一个元素,就可以得到数字 0。那么就可以进行 if 判断了!
修改表纪录
Book.objects.filter(title__startswith="py").update(price=120)
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录 update()方法会返回一个整型数值,表示受影响的记录条数。
update 的返回值为 int。1 表示成功,0 表示失败。
举例:修改 nid 为 1 的记录,将价格修改为 1000 元
修改 urls.py,增加 change 路径
urlpatterns = [path('admin/', admin.site.urls),path('add/', views.add),path('query/', views.query),path('change/', views.change),]
修改 views.py,增加 change 视图函数
注意:修改是基于查询的结果来修改的。所以是先有查询,再有修改!
def change(request):nid = 1ret = Book.objects.filter(nid=nid).update(price=1000)print(ret)return HttpResponse("修改成功")
访问页面

查看控制台输出信息:
(0.001) UPDATE `app01_book` SET `price` = '1000.00' WHERE `app01_book`.`nid` = 1; args=('1000.00', 1)1
ret 的返回结果为 1,表示修改成功!
查看表记录,点击刷新按钮,发现价格已经修改了!

举例:修改西游记的价格为 133 以及 is_pub 修改为 1
修改 change 视图函数
def change(request):nid = 3ret = Book.objects.filter(nid=nid).update(price=133,is_pub=1)print(ret)return HttpResponse("修改成功")
刷新页面,查看控制台输出信息:
(0.001) UPDATE `app01_book` SET `price` = '133.00', `is_pub` = 1 WHERE `app01_book`.`nid` = 3; args=('133.00', True, 3)1
ret 的返回结果为 1,表示修改成功!
查看表记录,点击刷新按钮,发现价格和 is_pub 已经修改了!

章节作业
1. 查询操作练习
. 查询苹果出版社出版过的价格大于200的书籍. 查询2017年6月出版的所有以py开头的书籍名称. 查询价格为50,100或者150的所有书籍名称及其出版社名称. 查询价格在100到200之间的所有书籍名称及其价格. 查询所有人民出版社出版的书籍的价格(从高到低排序,去重). 查询价格大于200的书籍的个数. 查询价格不等于100的所有书籍. 查询苹果出版社出版的书籍中的第3-7本(前提存在足够数量的书籍)
2. 图书管理系统
实现功能:book 单表的增删改查
第一题答案:
准备基础数据:
#截断表记录mysql> TRUNCATE TABLE app01_book;Query OK, 0 rows affected (0.19 sec)#插入数据:INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('1', 'python基础', '2017-06-01', '200.00', '人民出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('2', '西游记', '2017-08-08', '100.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('3', '红楼梦', '2017-08-10', '50.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('4', '水浒传', '2017-08-25', '150.00', '人民出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('5', '三国演义', '2017-12-20', '88.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('6', 'python爬虫', '2018-02-10', '300.00', '人民出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('7', 'python大数据', '2018-05-15', '350.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('8', 'java', '2017-08-11', '55.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('9', 'go', '2018-06-04', '66.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('10', 'php', '2018-06-08', '99.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('11', 'c', '2018-05-22', '156.00', '苹果出版社', '1');INSERT INTO `app01_book` (`nid`, `title`, `pub_date`, `price`, `publish`, `is_pub`) VALUES ('12', 'c++', '2018-04-17', '650.00', '苹果出版社', '1');
- 查询苹果出版社出版过的价格大于 200 的书籍
ret = Book.objects.filter(price__gt=200, publish='苹果出版社', is_pub=True).values('title', 'price')for i in ret:print(i['title'], i['price'])
查询结果:
python大数据 350.00c++ 650.00
- 查询 2017 年 6 月出版的所有以 py 开头的书籍名称
ret = Book.objects.filter(title__startswith='py',pub_date__year=2017, pub_date__month=6).values('title')for i in ret:print(i['title'])
查询结果:
python基础
- 查询价格为 50,100 或者 150 的所有书籍名称及其出版社名称
ret = Book.objects.filter(price__in=[50,100,150]).values('title', 'publish')for i in ret:print(i['title'], i['publish'])
查询结果:
西游记 苹果出版社红楼梦 苹果出版社水浒传 人民出版社
- 查询价格在 100 到 200 之间的所有书籍名称及其价格
ret = Book.objects.filter(price__range=[100, 200]).values('title', 'price')for i in ret:print(i['title'], i['price'])
查询结果:
python基础 200.00西游记 100.00水浒传 150.00c 156.00
- 查询所有人民出版社出版的书籍的价格(从高到低排序,去重)
ret = Book.objects.filter(publish='人民出版社').order_by('price').reverse().values('title','price','publish')..distinct()for i in ret:print(i['title'], i['price'],i['publish'])
查询结果:
python爬虫 300.00 人民出版社python基础 200.00 人民出版社水浒传 150.00 人民出版社
- 查询价格大于 200 的书籍的个数
ret = Book.objects.filter(price__gt=200).count()print(ret)
查询结果:3
- 查询价格不等于 100 的所有书籍
ret = Book.objects.exclude(price=100).values('id', 'title', 'price', 'publish')for i in ret:print(i['id'], i['title'], i['price'], i['publish'])
查询结果:
1 python基础 200.00 人民出版社3 红楼梦 50.00 苹果出版社4 水浒传 150.00 人民出版社5 三国演义 88.00 苹果出版社6 python爬虫 300.00 人民出版社7 python大数据 350.00 苹果出版社8 java 55.00 苹果出版社9 go 66.00 苹果出版社10 php 99.00 苹果出版社11 c 156.00 苹果出版社12 c++ 650.00 苹果出版社
- 查询苹果出版社出版的书籍中的第 3-7 本(前提存在足够数量的书籍)
ret = Book.objects.filter(publish='苹果出版社')[3:7].values('id','title','price','publish')for i in ret:print(i['id'], i['title'], i['price'], i['publish'])
查询结果:
7 python大数据 350.00 苹果出版社8 java 55.00 苹果出版社9 go 66.00 苹果出版社10 php 99.00 苹果出版社

若有收获,就点个赞吧
0 人点赞
