
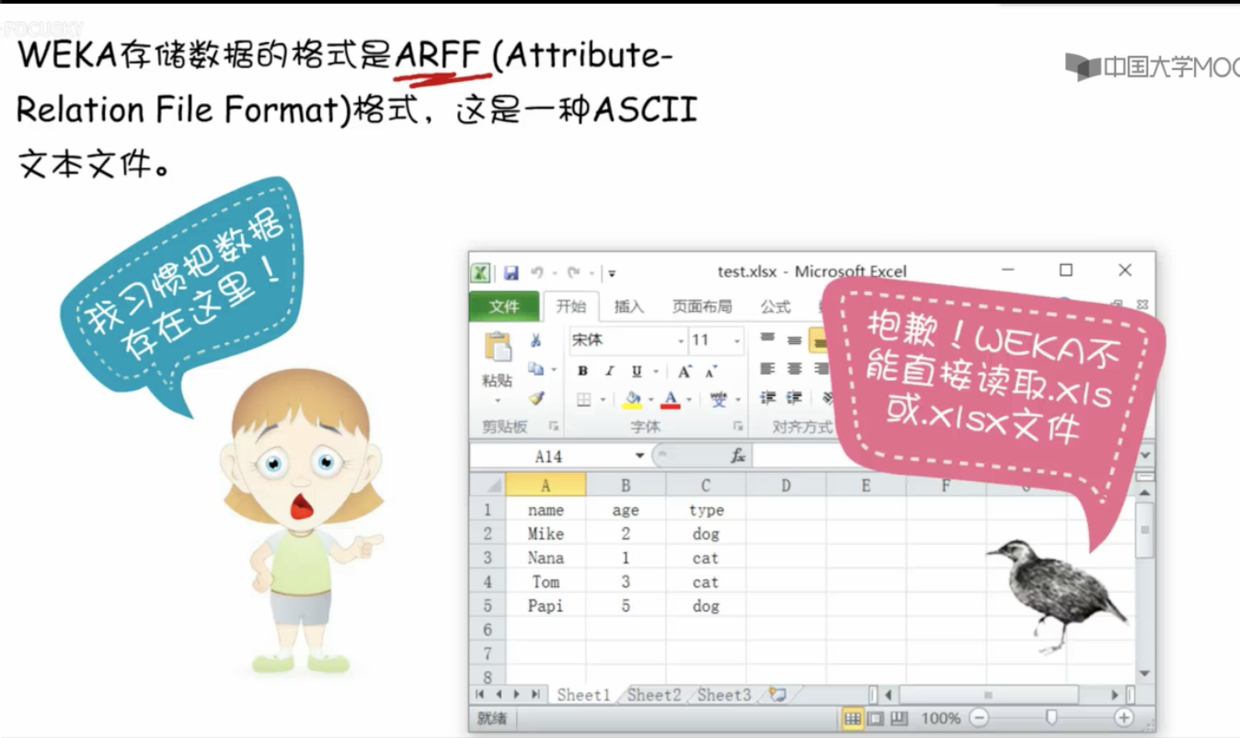
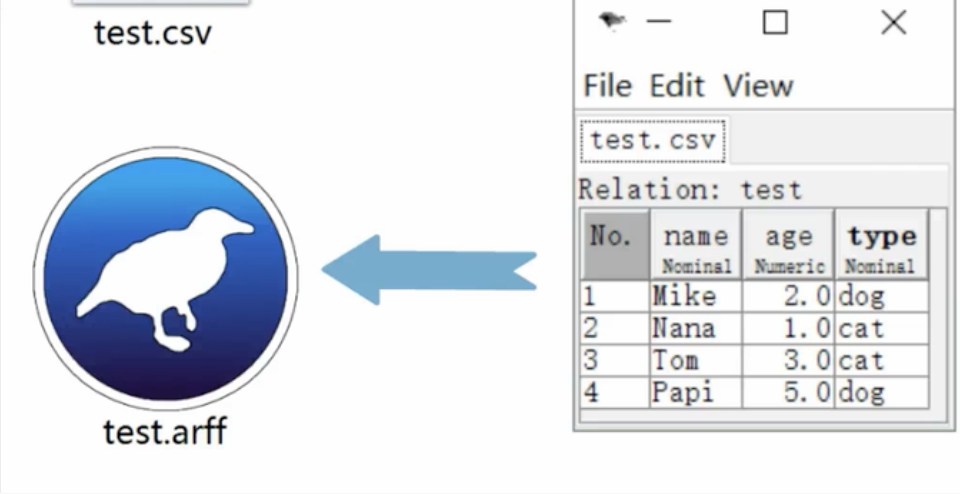
- weka 无法直接读取Excel文件
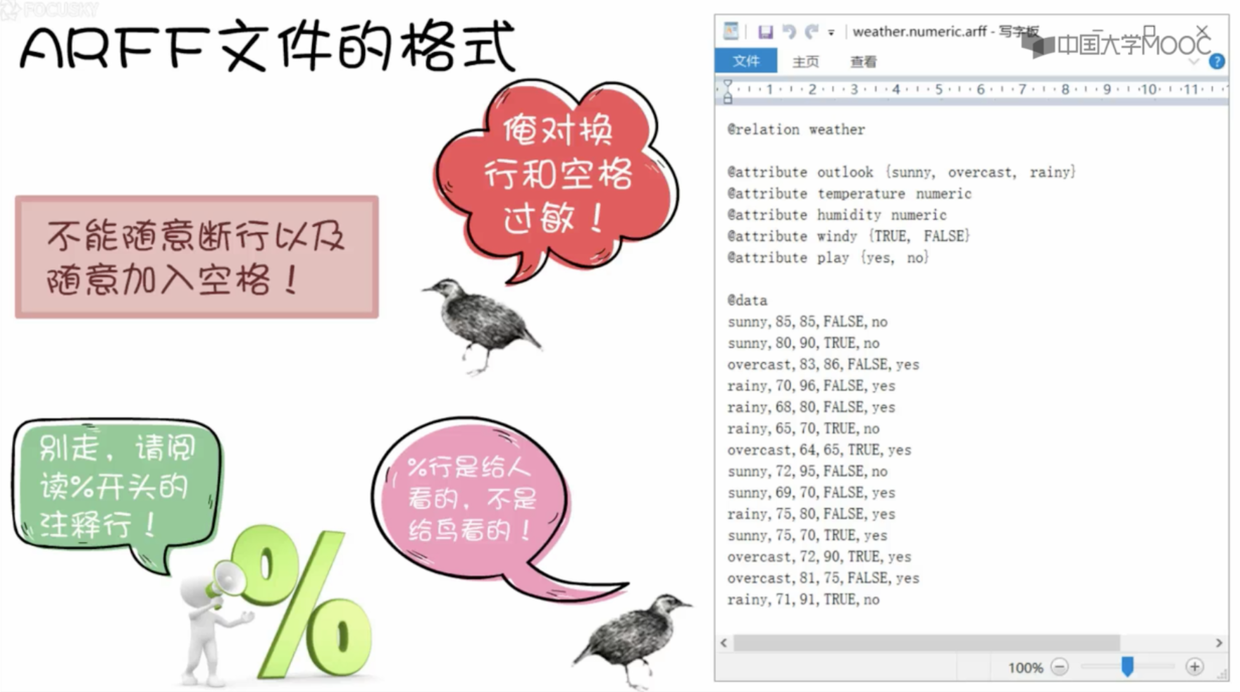
arff 文件格式要求
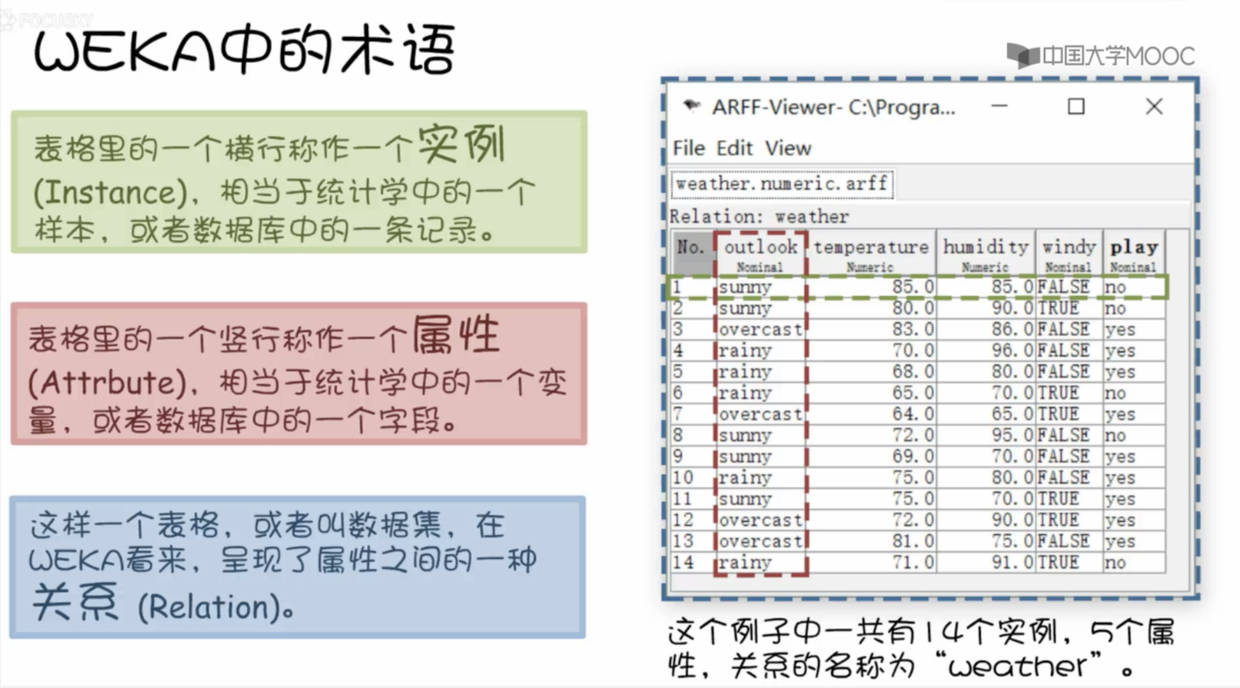
- arff 文件内容
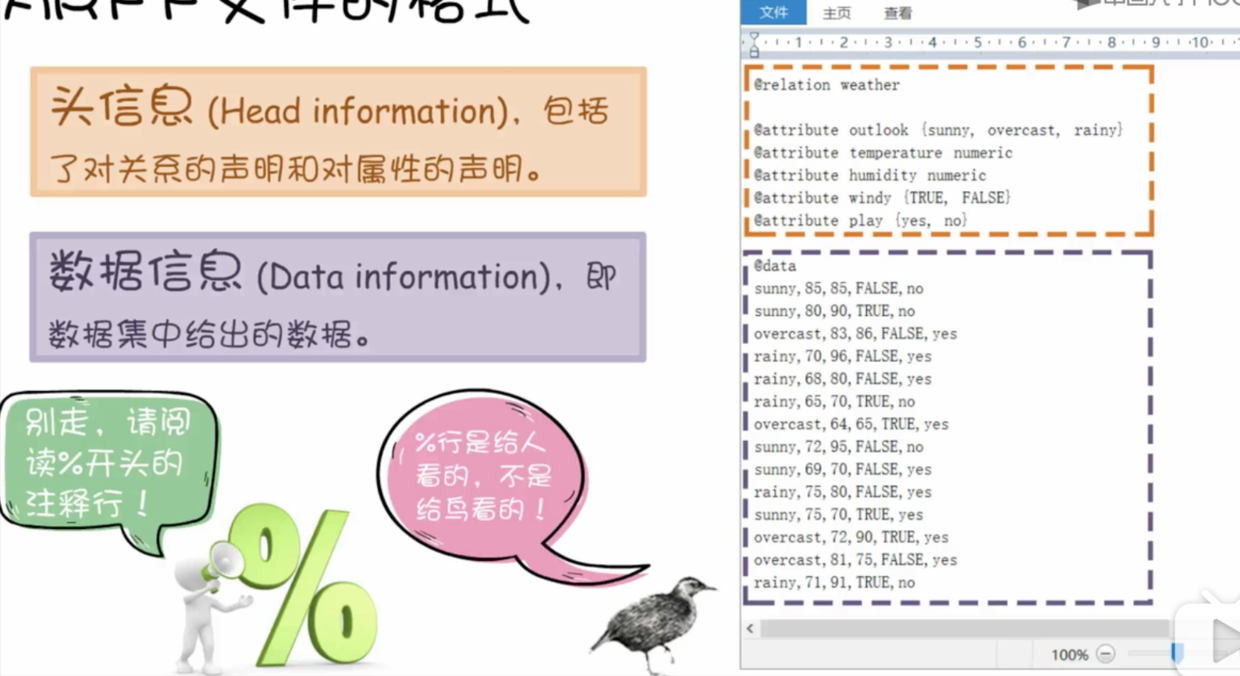
weka 头信息内容
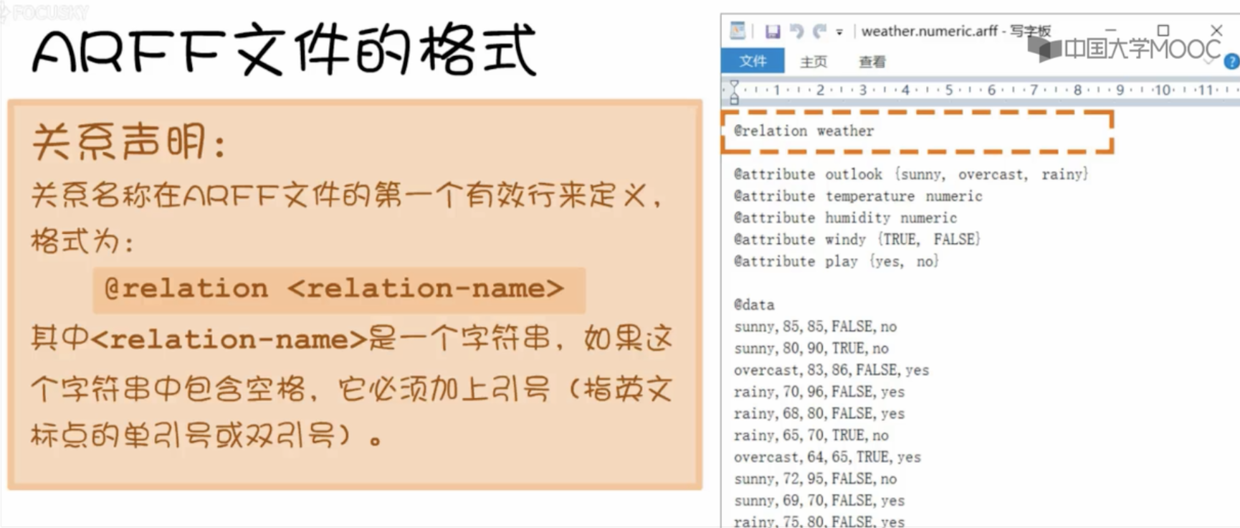
- 首先是关系声明
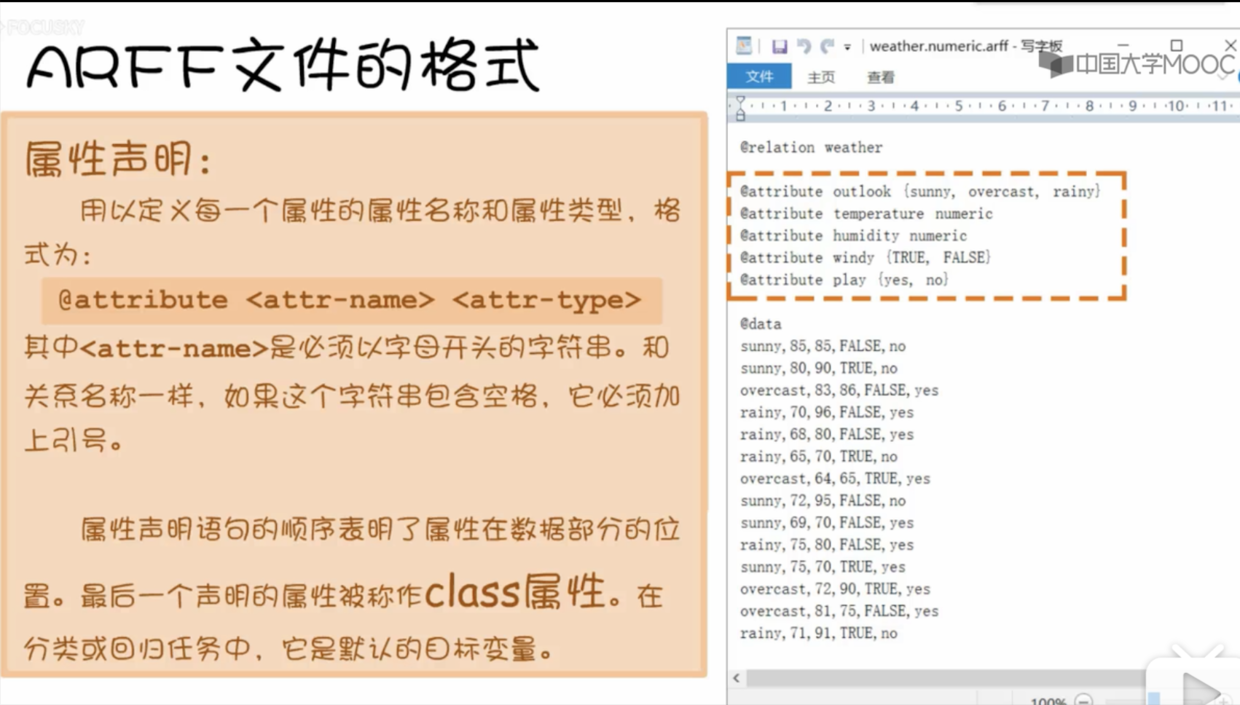
- 接着是属性声明
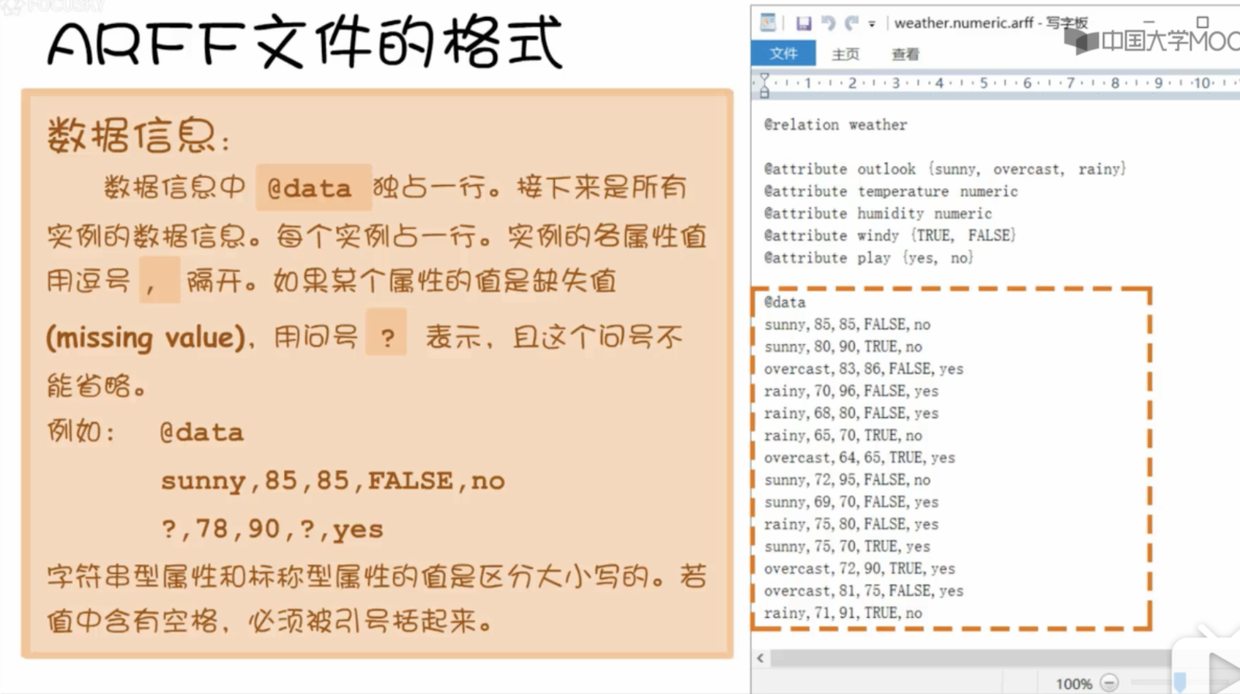
- 最后是数据信息
WEKA 属性类型与格式转换

数值型

标称型

字符串型

时间日期型

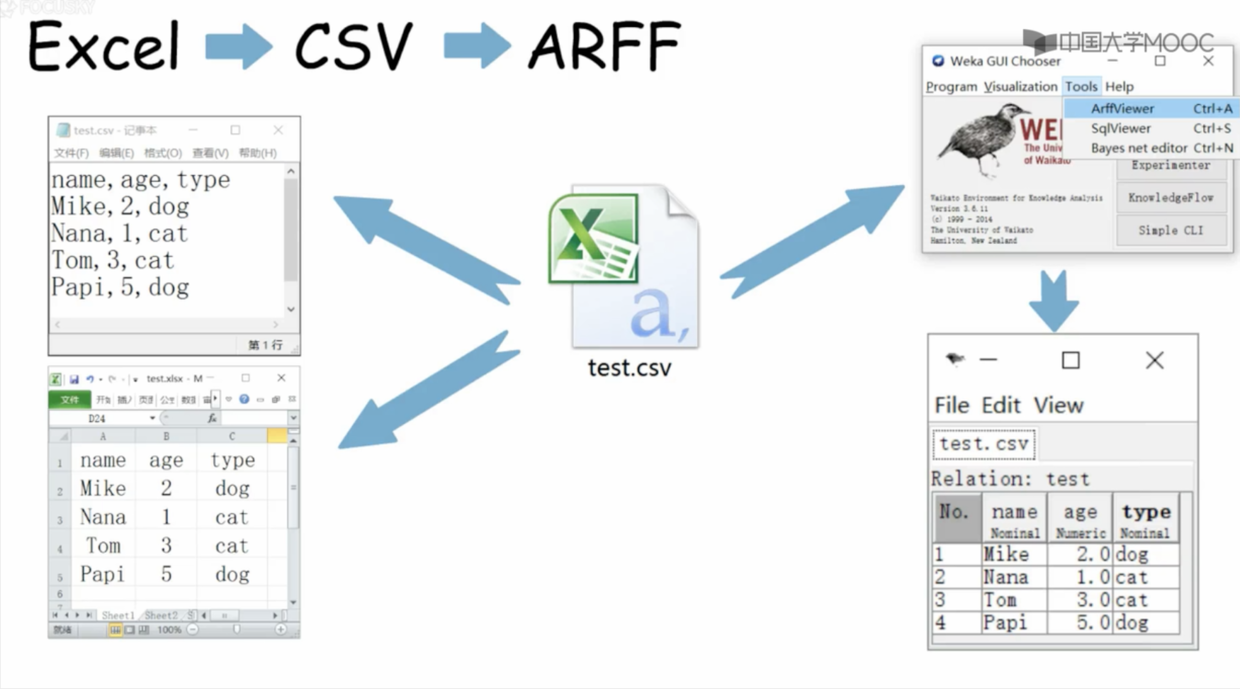
通过csv 转换xls 文件
WEKA 界面介绍
数据预处理及挖掘任务
- 打开explorer 下界面
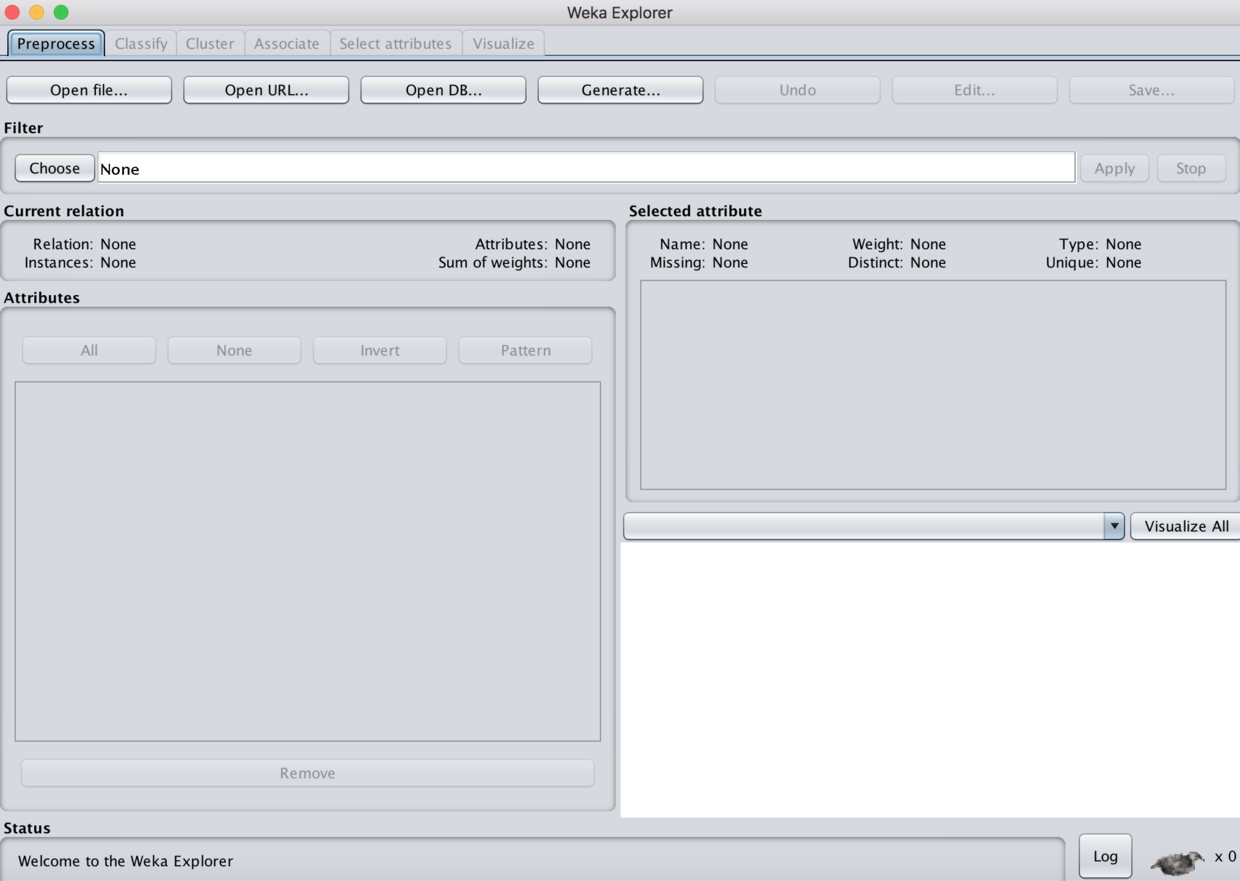
- 我们可以直接食用WEKA 自带的范例文件。
- 根据功能不同,WEKA 界面可分为8个区域。
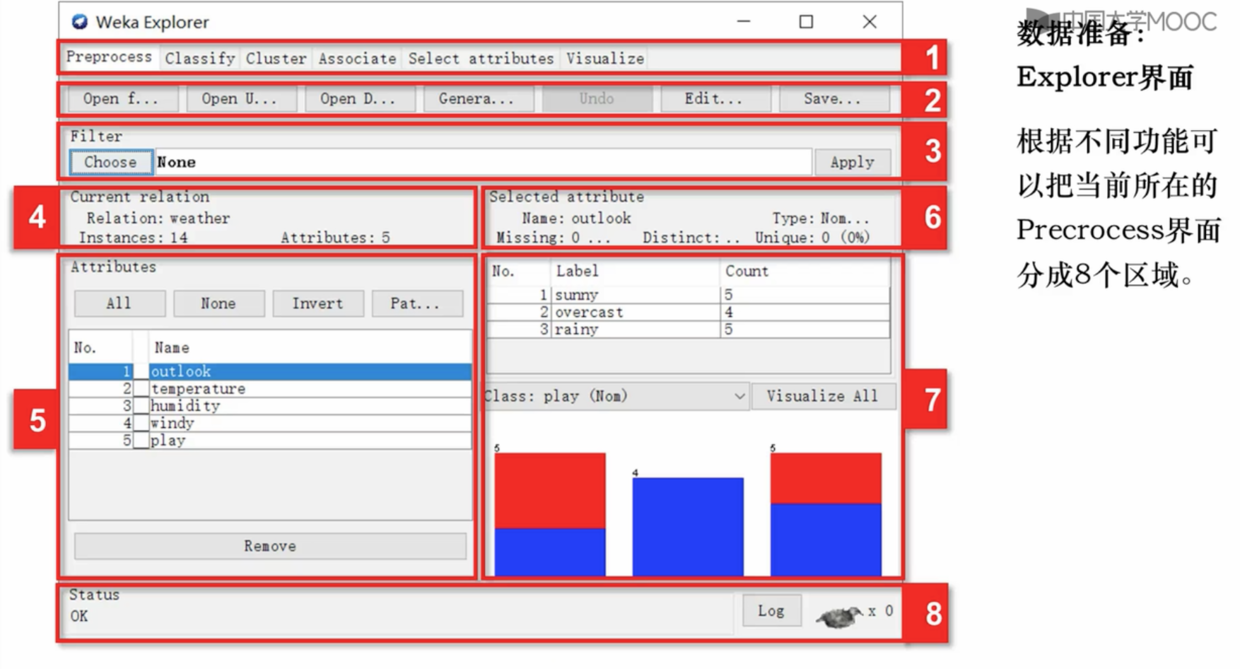
区域1
切换不同的挖掘任务面板
区域2
常用功能按钮
区域3
数据类型筛选与属性类型转换(预处理的主要实现区域)
区域4
展示数据集的基本信息。
区域5
罗列所有属性,可以进行添加和删除的操作。
区域6
用于显示区域5 选择的属性的详细信息。
区域7
显示区域5 中属性信息的基本计数信息,并可视化展示。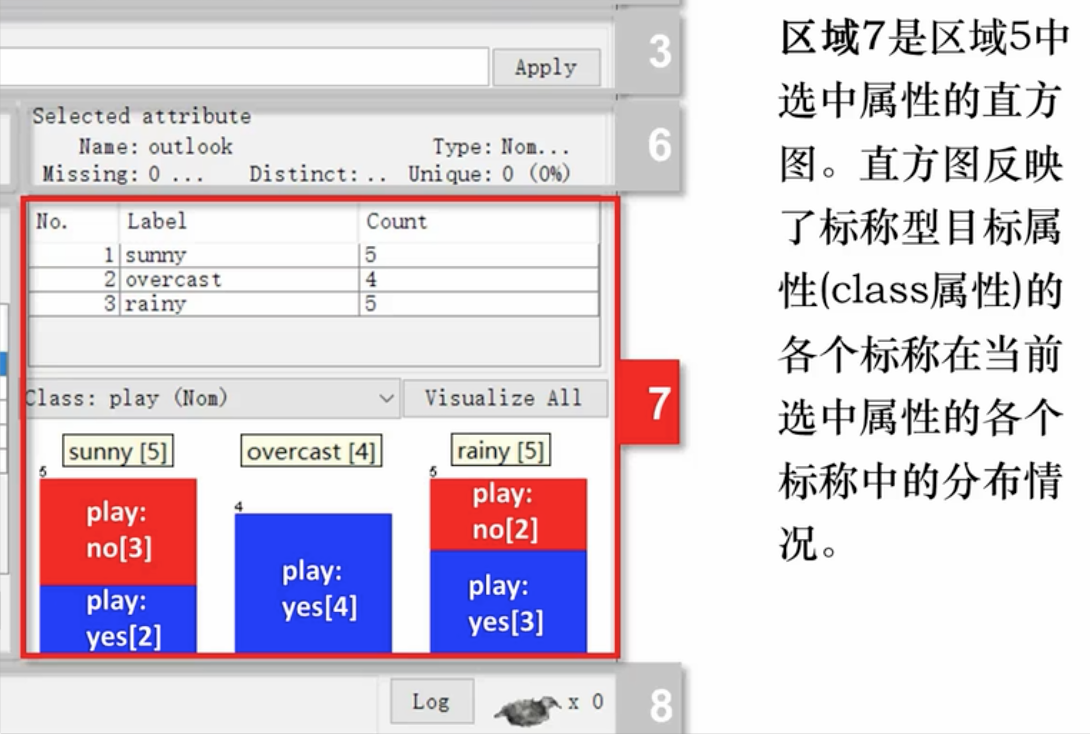
最后一个属性默认为目标属性。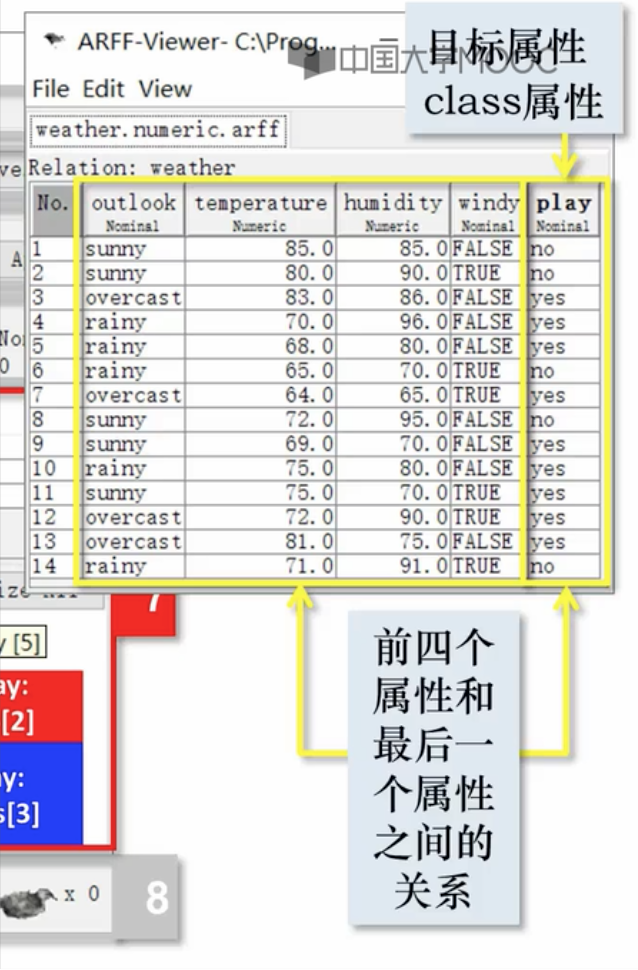
- 可以点击visualize all 进行可视化处理。
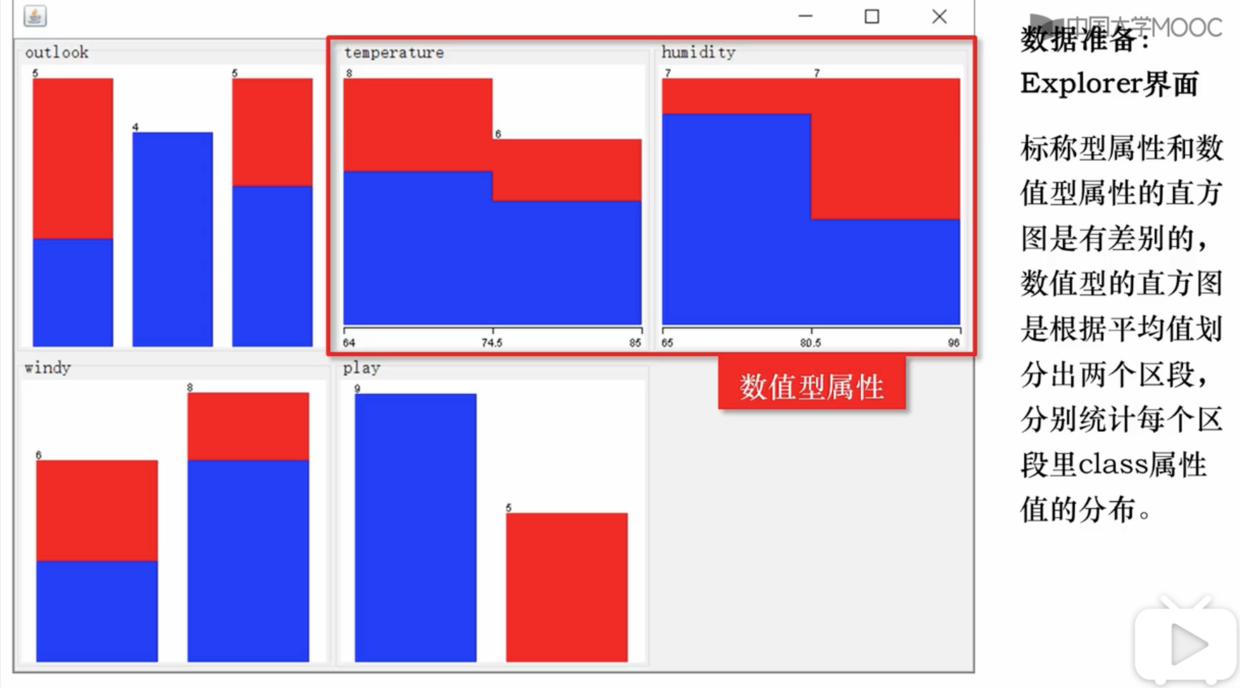
区域8
状态栏,可以查看操作日志以及数据挖掘任务的状态。
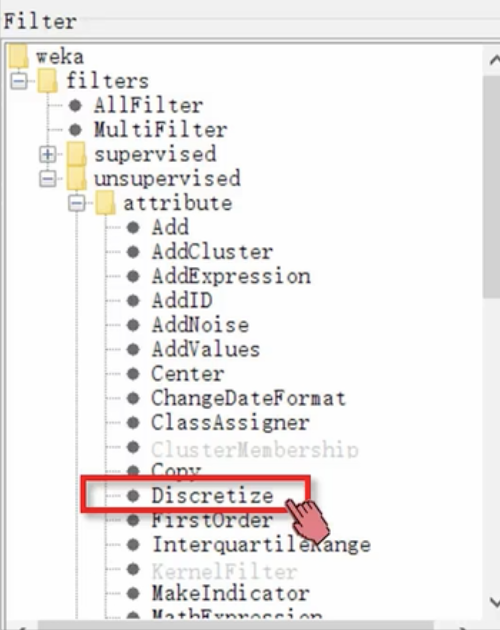
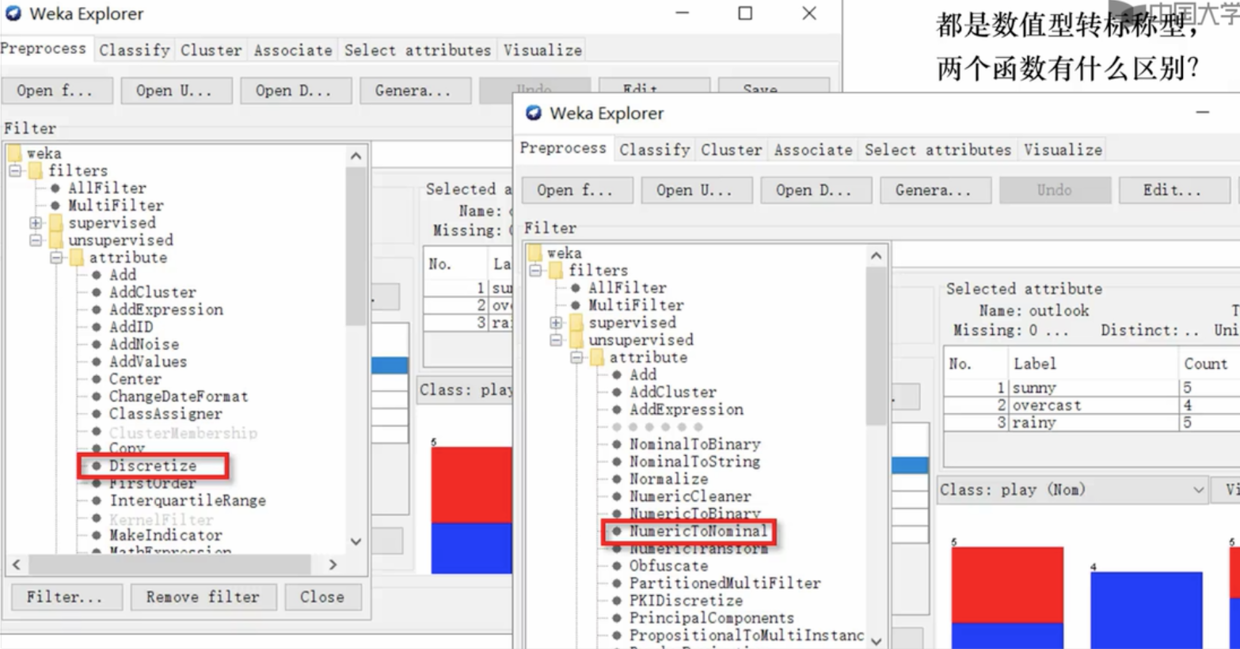
通过filter 进行数据预处理
- 将数值型属性转换为标称型属性
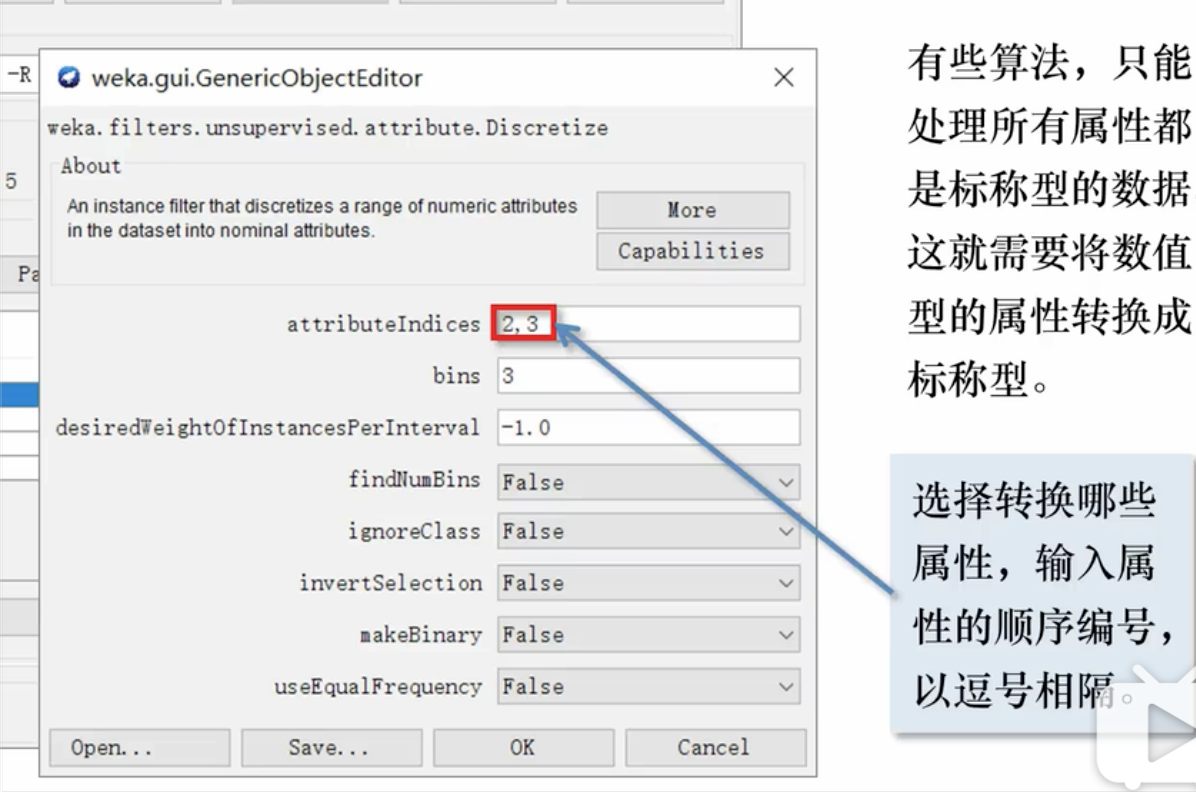
- bins 表示新属性的标称个数。
- apply 进行处理
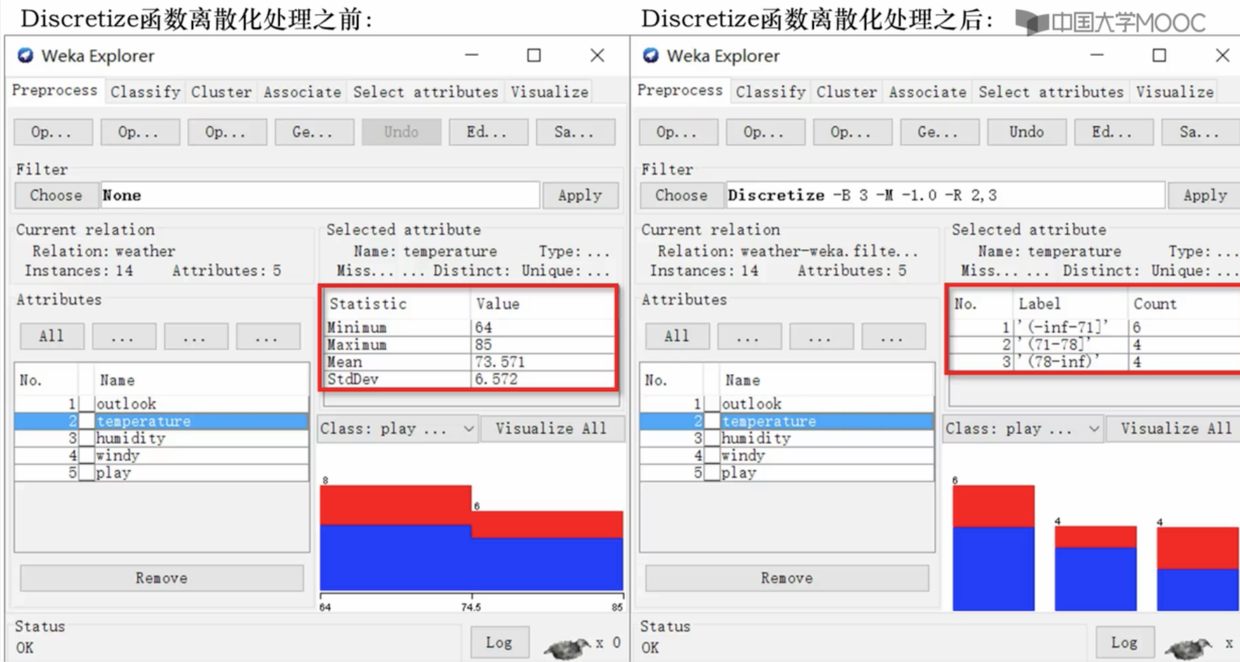
- 两个不同的数值-> 标称型函数的差异
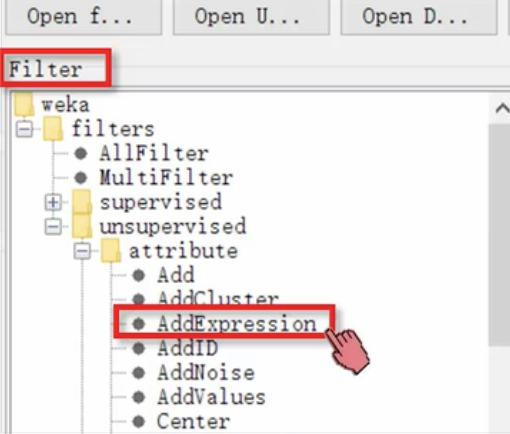
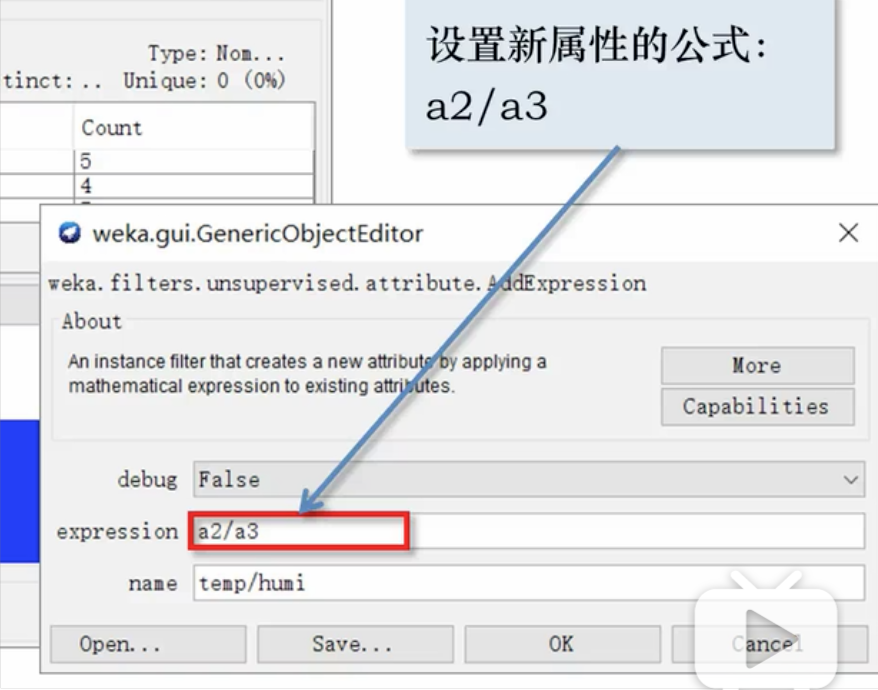
- 添加新的属性
执行挖掘任务
- 分类和回归数据挖掘都在classify中
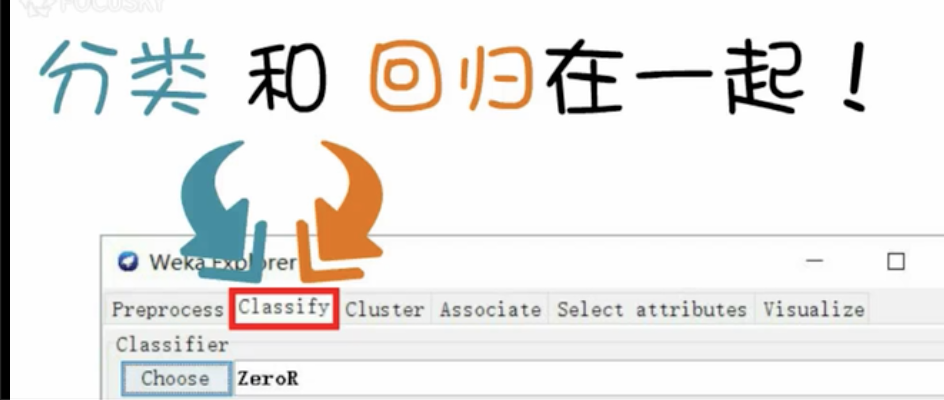
- 分类和回归都是通过输入数据训练以预测输出数据
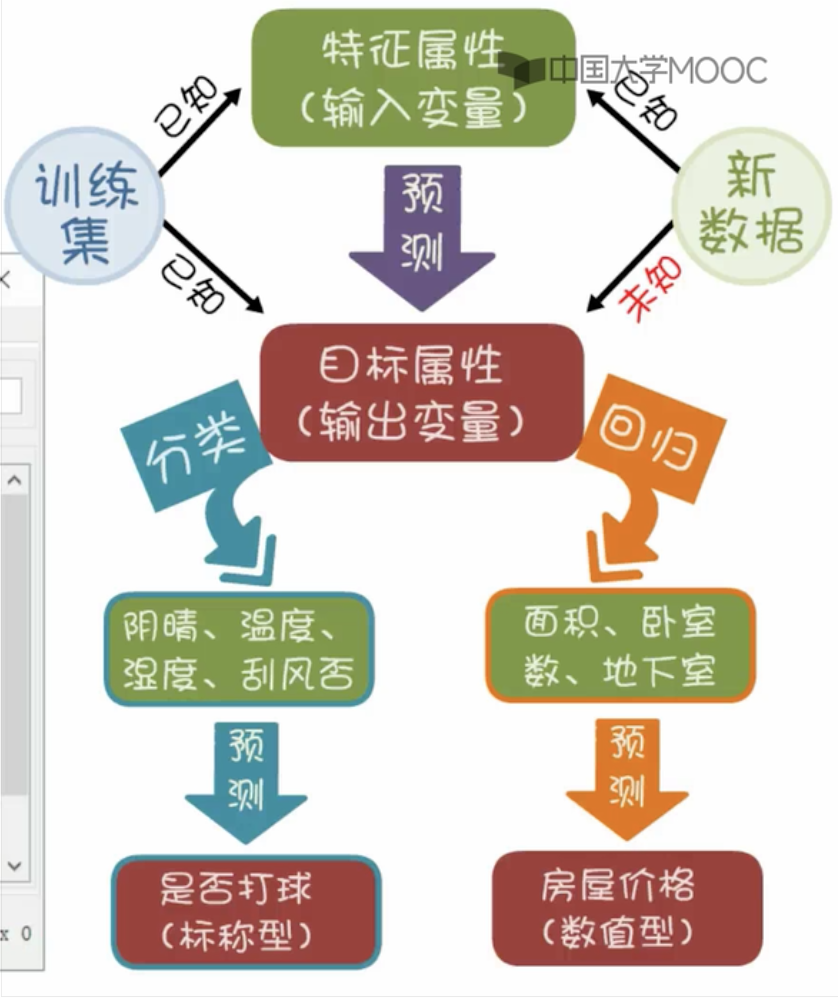
- WEKA 自带的算法

开始操作
- 首先在范例文件中打开 diabetes.arff 文件
- 接着选定分类算法模型
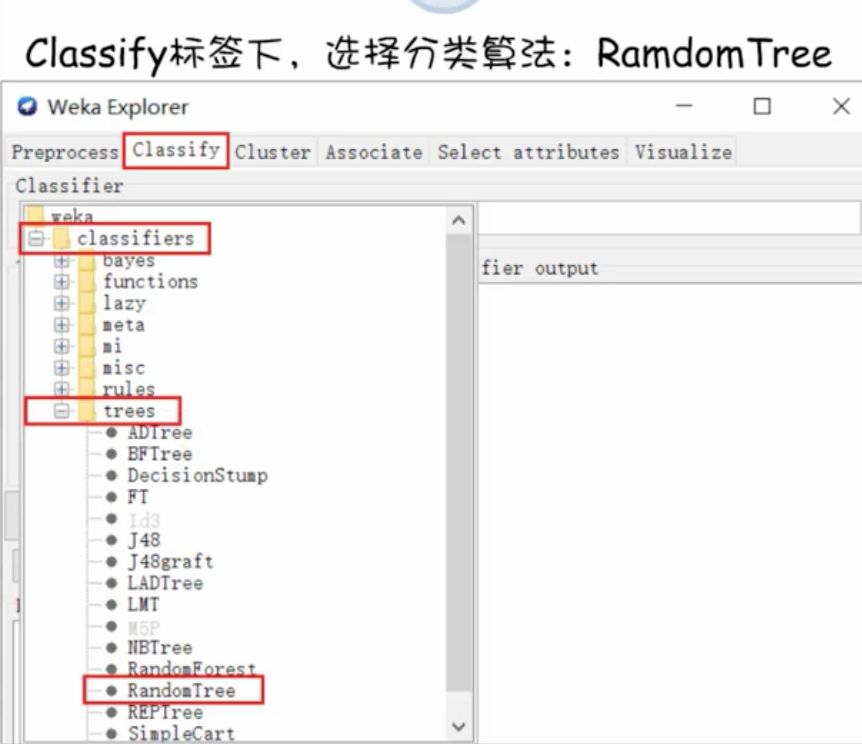
- 确定模型选项
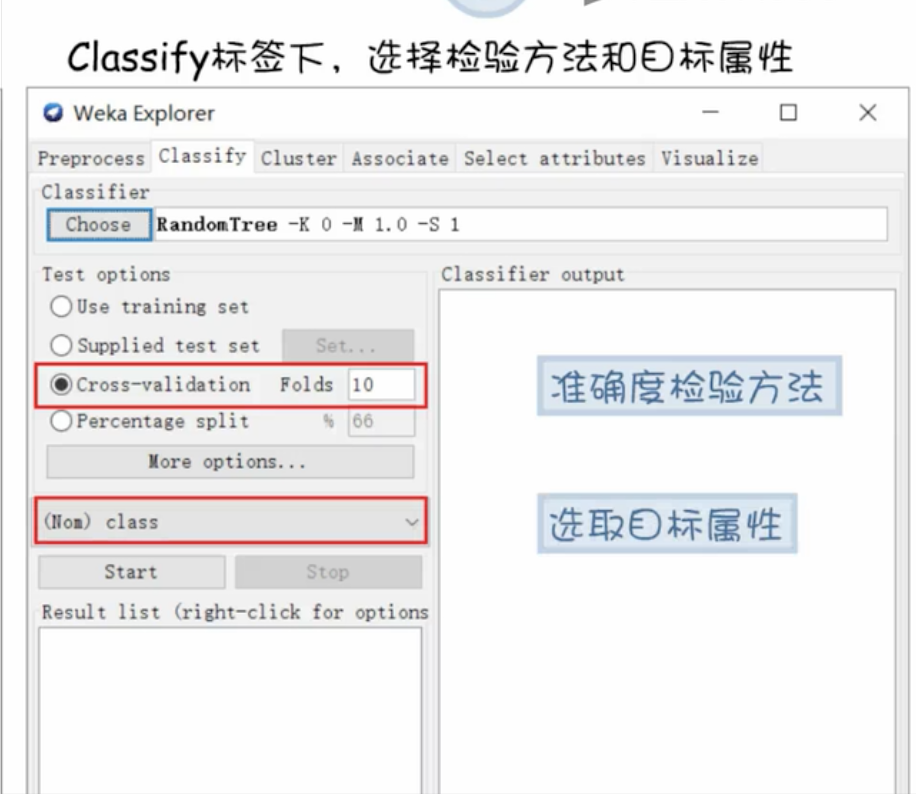
- 结果输出
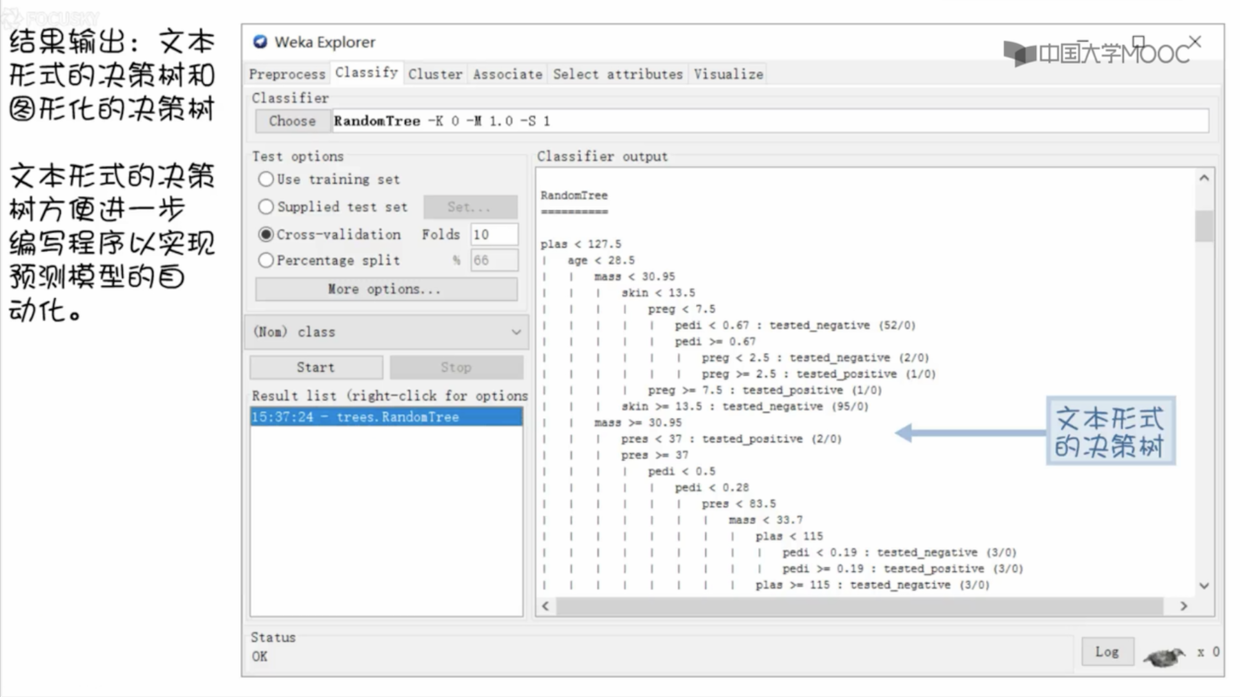
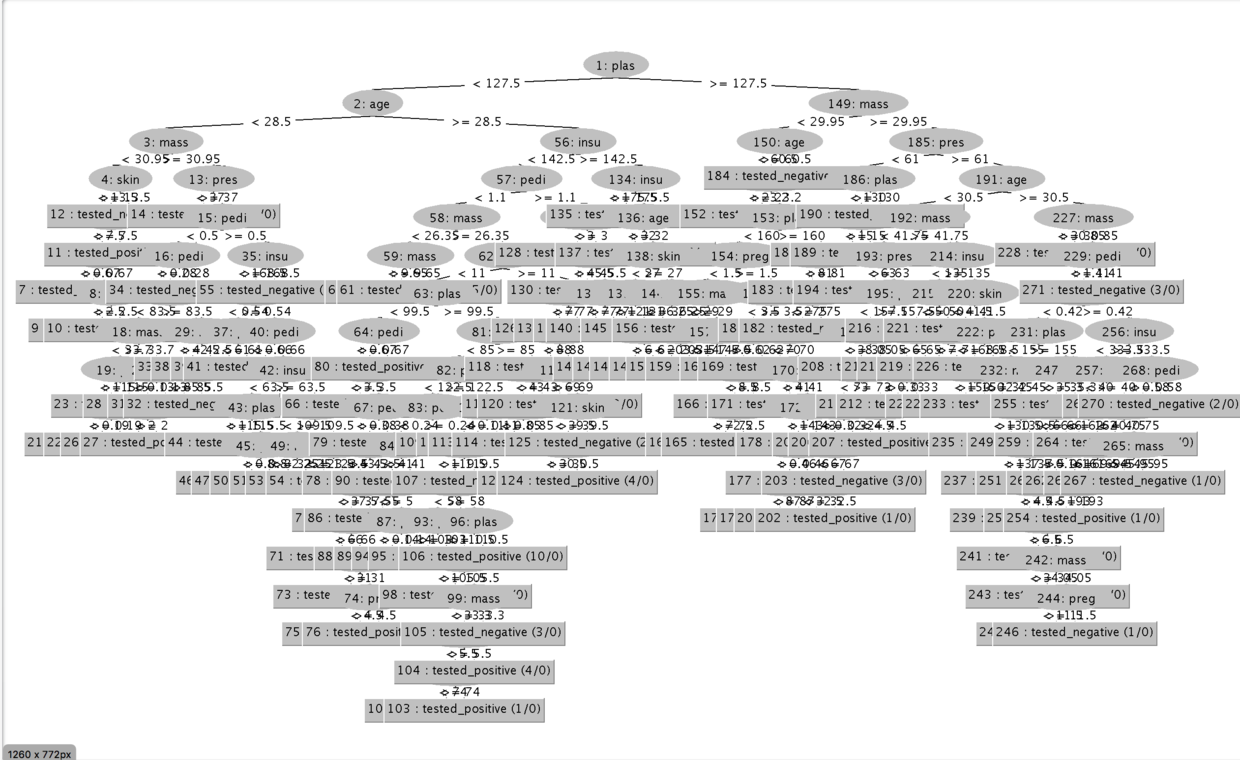
- 可以右键输出结果,选择可视化决策树
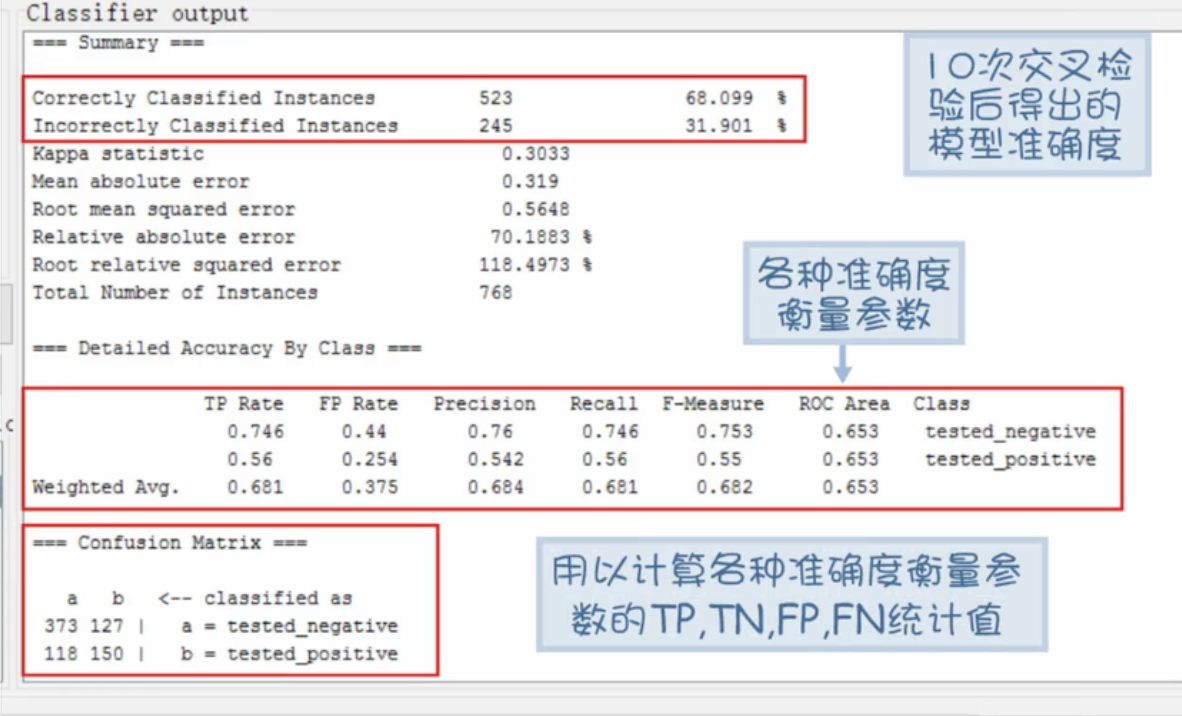
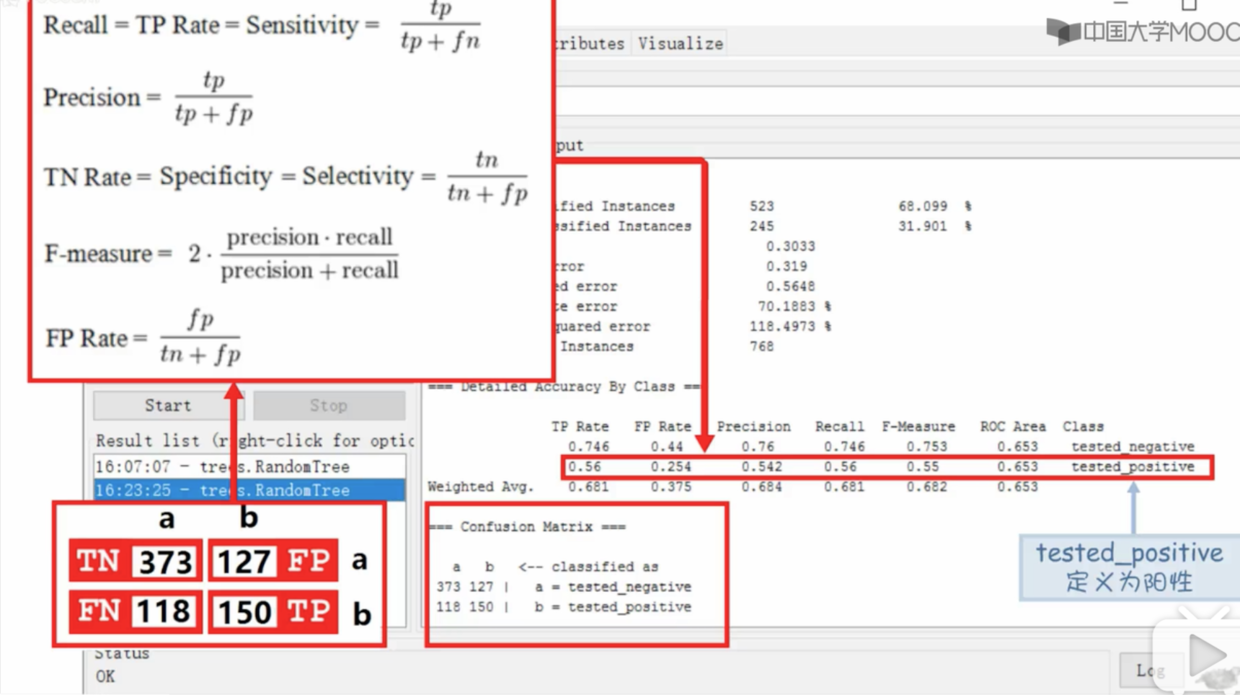
- 测试模型可信度
结果可以看到总结

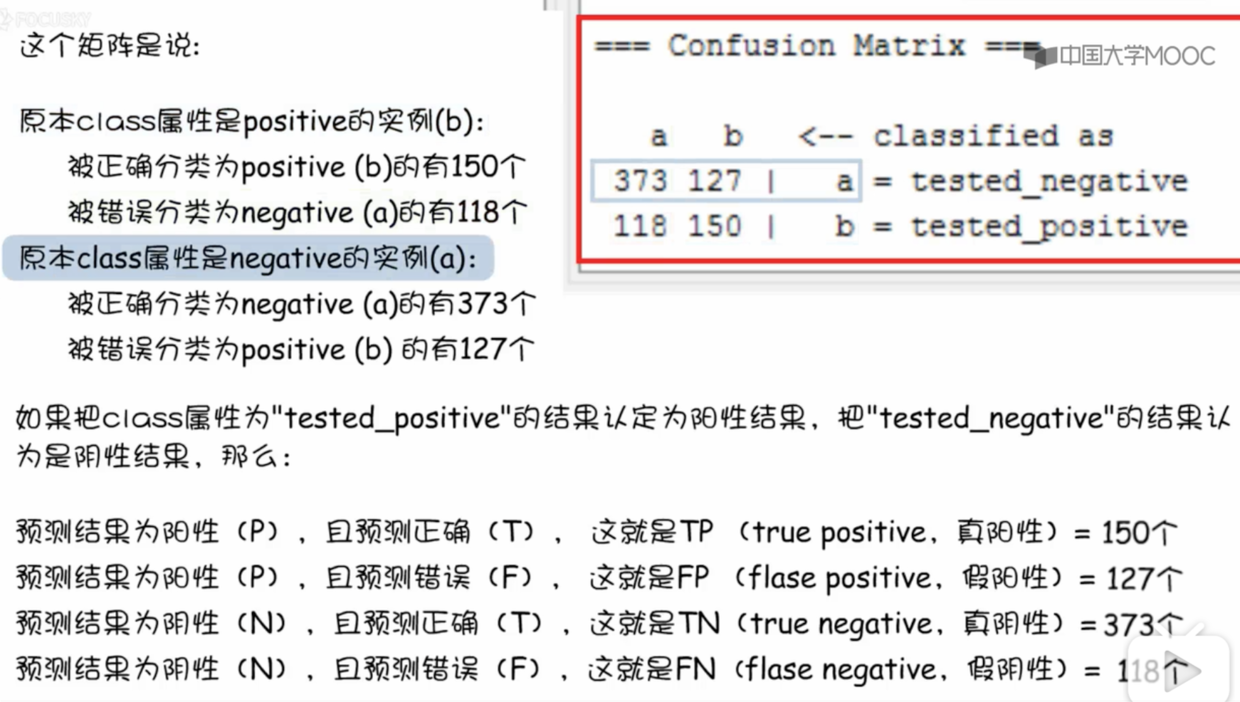
- 解读混合矩阵

若有收获,就点个赞吧
0 人点赞
