序列是什么?
序列,sequence,本质就是一串字符串,string。
Si 代表序列的第i个字符。
S’ 表示原序列的子序列, substring,包含原序列的部分信息。

序列相似性
数据库中的序列相似性是指,对于一个蛋白质或核酸序列,你需要从序列数据库中找到与它相同或者相似的序列。
你可以用眼睛(手工)去比较,但非常不现实。一是数据库的量对于人来说规模过于庞大,仅凭借人的精力难以企及;二是纯手工的比较序列的准确性也是非常低的。
序列相似性的重要性
相似的序列往往起源于一个共同的祖先序列。它们可能有相似的空间结构与生物学功能。而如果与目的序列相似的蛋白质或基因的结构和功能已知,则可以推测这个未知结构和功能的蛋白质的结构和功能。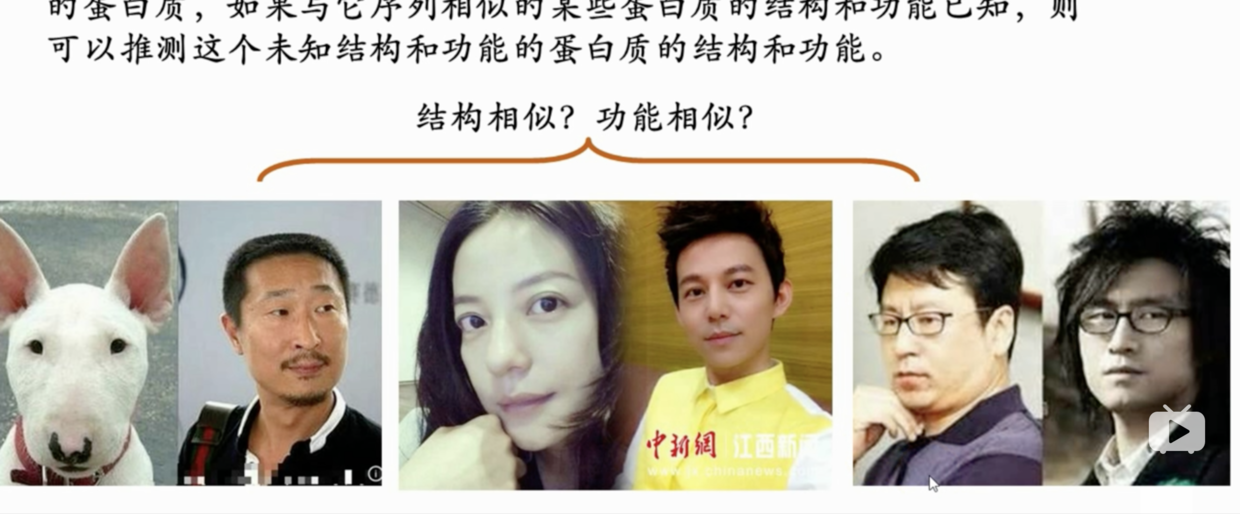
评价序列相似度
通过序列一致度(identity) 与相似度(similarity)。
一致度:如果两个序列(蛋白质或核酸)长度相同,那么它们的一致度定义为对应位置上相同的残基(氨基酸或碱基)的数目占总长度的百分比。
相似度:如果两个序列长度相同,则相似度定义为它们对应位置上相似的残基与相同的残基的数目和占总长度的百分数。
如序列1:CLHK 序列2:CIHL
则这两个序列的一致度为2/4 = 50%。
而L与I,K与 L的相似度则不是这么容易能被确定。
残基两两相似的量化关系被替换记分矩阵所定义。

若有收获,就点个赞吧
0 人点赞
