1. 编码的开始
我们常见用到十进制数字可以通过进制转换的方式转换成二进制存进电脑里,除了数字,我们常说的语言都是字符,那么如何将字符存入电脑里呢?最容易想到的方式就是为所有字符进行编号,每一个字符对应一个特定的编号,存入电脑,然后根据其编号,再解析出对应的字符。于是电脑出现后,编码这个词就出现了,编码方式就是指将数据、字符存储在计算机中的编号规则。随着计算机的发展,编码方式各家百花齐放。
2. ASCII码
计算机最早是由西方国家发明出来的,由于西方国家说英语,因此英文字母、数字、特殊符号成了西方人编码的考虑内容,就像我们电脑键盘上的字母、字符基本都可以找到其对应的电脑编码。西方人发明了ASCII码(American Standard Code for Information Interchange: 美国信息交换标准代码),是基于拉丁字母的一套编码系统。到目前为止一共收录了128个字符,毕竟是要用二进制存储,因此128个字符用7位二进制位来存储就够了,因为你比如,两个二进制位有2*2中组合,可以表示四个字符,00、01、10、11,27=128,因此7位二进制位即可编号表示128个字符,但计算机存储一般是以字节为单位的,一个字节即8个二进制位,因此ASCII用8个二进制位存储,首位为0,也可以有其他含义。编码号可以用十进制0-127表示,也可用二进制、八进制、十六进制表示,0-127十进制编码号对应的ASCII码表如下: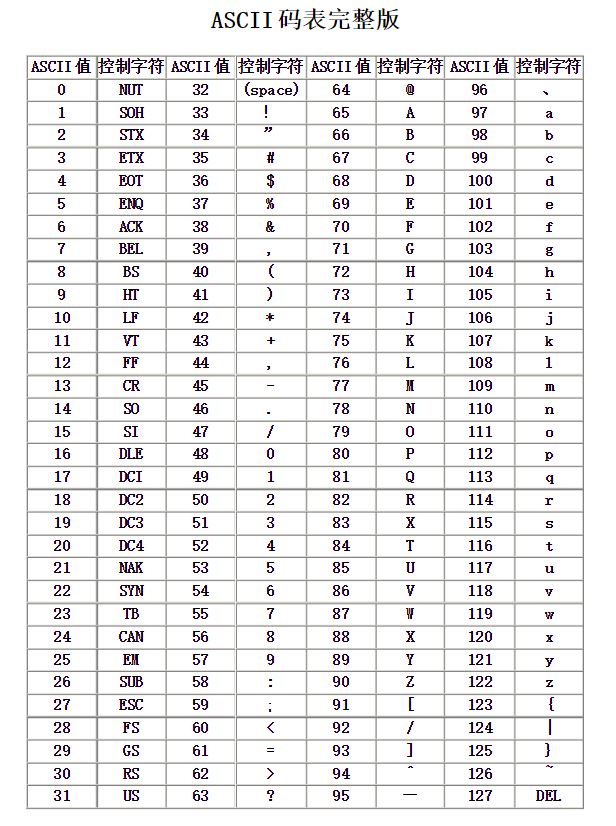
以后的编码格式,需要将拉丁字母编码进去的,一般兼容ASCII码,也就是说其编码的前127位也是和ASCII码一样,为了方便和兼容。然后常用的需要记忆的编码为:
0:48表示
A:65表示
a:97表示
3. GB2312编码
随着时代发展,计算机开始传入中国,中国人也开始用电脑了,那么问题就来了,电脑里存储编号的只是英文字符,中文字符无法存入,于是,中国国家标注局介入开始为汉字编码,名称为【国标2312】标准,是中国第一个计算机编码标准。取国标拼音首字母,即【GB2312】编码标准。由于中国汉字比较多,有上千个,因此一个字节肯定不够用,中国国标局就用2个字节,即16个二进制位表示一个汉字,即可以表示216=65536个字符。收录一些常用汉字足够了,当时GB2312只收录了6000多汉字,西文字母和日文假名,并没有收录中国汉字的生僻字、繁体字和韩文等。由于16位二进制太长了,因此汉字编码编号一般用十六进制位表示,即是十六进制0000-FFFF。太多了表太长,具体可自行百度,如“爸”的GB2312编号为B0G6,只截取部分编码表如下:
4. GBK编码
由于GB2312编码中没有将汉字字符包括完全,导致一些生僻字、繁体字存不到电脑里,如我们常见的有的同学的名字里有个生僻字,存入电脑就无法解析出来,只用*表示。因此,微软就出手了,微软在GB2312的基础上制定了GBK编码,也就是国标扩,K即为扩展的扩字的首拼音字母。GBK编码包含21886个汉字和图形符号,收录的是中日韩使用的所有汉字,并且是完全兼容GB2312的,兼容意思就是说只是在GB2312编码的后续编号扩充,前面的编号也是和GB2312一样的。由于21886<<65536,所以,GBK也是用两个字节进行编码的。因此,在一段时间内,GBK编码在中国很受欢迎。
5. GB18030编码
在微软制订了GBK编码后,中国国标局就出手了,毕竟汉字是中国占据大多数,理应由中国掌握标准,于是国标局又制定了GB18030,想取代微软的GBK,但是GB18030存在一个很大的问题导致其无法盛行,那就是其不兼容GB2312,也就是说以前在使用GB2312编码下写的汉字在GB18030编码下全乱了或者看不见了,因此很少人会去用它,GB18030编码取代失败。
6. Unicode编码
随着电脑的普及,几乎世界各地都在用电脑了,那么问题就又出现了,一些国家的奇怪字符就无法被存入电脑了,如中国的西藏地区的藏文,泰国的泰文等奇怪字符,在目前的编码中都尚未录入。那只能再接着扩充编号,将其加入进去,为了不再发生类似的问题,就发明了万国码,Unicode,Uni即是Unify统一的简称,即统一的编码方式,已经收录了13万的字符,在全世界通用,并在不断扩充中。那么13万>>65536,因此2个字节的编码已经不再够用了,每个字符的存储都要在3个字节或及其以上了。这样也暴露了Unicode编码格式的一个大缺点,即相比于GBK,Unicode的一个字符的存储所占的内存扩大了50%,这样所有文件大小都要扩大50%,当时的硬盘内存可是很贵的,因此这个缺点注定Unicode编码在当时无法盛行。
7. UTF-8编码
UTF-8编码是在Unicode编码方式上的进一步优化,采取变长的方式存储字符,对于前127位的英文字符,Unicode前16位二进制位都为0,其采用一个字节存储,对于汉字“爸”这样的字符Unicode前8位的二进制数为0,其就采用两个字节存储,并对确实占用三个字节的符号的存储也是有其更简单的特殊的方式存储。变长的字符如何区分分别是占几位呢?这就是UTF-8的巧妙之处,可具体搜索UTF-8的存储原理。由于UTF-8采取变长的方式存储,可能比定长存储的GBK编码还要省空间,并且支持的字符多,因此很受欢迎。并且UTF-8中的8表示的是一个字符至少是需要8位存储的,即是8位、16位、24位等。
特别注意:UTF-8还是用到Unicode的字符集,只是存储方式不一样。

若有收获,就点个赞吧
0 人点赞
