1. 网页应用的发展
早在 ajax 技术出现以前,网页的运行模式就是在服务器端写好所有的静态页面,用户通过在浏览器输入不同的 url,浏览器负责向对应的 url 地址发送请求,服务器端响应请求,将对应的静态页面返回给浏览器,浏览器收到静态页面负责解析后显示给用户。此时的网页应用,用户想要与网页应用进行交互或者进行页面跳转,就必须发送不同的 url 请求得到,也就是说必须刷新浏览器。发送请求和响应请求的频繁操作让用户体验很不好。(页面交互和页面跳转都需要页面刷新)
后来,随着 ajax 技术的出现,做到了局部异步数据请求而不刷新浏览器。节省了很多的静态页面的频繁请求,而且 ajax 请求的发送和响应速度比静态页面的要快得多。这样一来,ajax 做到了用户在与页面交互时是无刷新的。(页面交互无刷新,页面跳转有刷新)
ajax 技术虽然极大地改善了用户与网页的交互性,但是,传统的网页应用还是需要向服务器端请求多个静态页面资源,发送请求和响应请求也都需要时间,在网络不好的情况下,用户体验还是很差。因此就有了后来的 SPA(single page application)单页面应用。单页面应用的设计思想就是,整个网页应用就只有一个 index.html 静态页面,页面显示内容的切换时通过更新 index.html 页面的 div 容器内的内容来实现的。这样一来,查看内容之间的切换就变成了类似于让 div 容器内的上一个内容隐藏,显示下一个内容这样的模式。当然了,肯定不是显示 / 隐藏的设计思想,而是通过 JavaScript 语言全权操作 DOM 元素 的模式更新视图(view = render(model))。把所有的元素都变成了 JS 控制的动态生成的方式,也就不用再频繁地向服务器发送请求了,网页与用户的交互性更强了,访问速度更快了。(页面交互和页面跳转都不需要页面刷新)
SPA 的核心思想就是:更新视图而不重新请求页面
2. SPA与前端路由
SPA 单页面应用虽然是用内容切换的方式代替了页面跳转,但是 SPA 依旧是根据 url 的改变来模拟页面跳转的。
那么如何用 url 模拟页面跳转而不让浏览器刷新呢?
这时前端路由就出现了,专门用于 SPA 单页面应用的,确保改变 url 的情况下,不让页面刷新。
无论是 Vue 还是 React,只要是 SPA 单页面应用,都需要前端路由。
3. 手动实现一个前端路由管理器
根据 url 的构成可知,当 url 中含 # 时,会被认为是 # 及其后面的内容是用于定位页面内的某一元素的,因此 # 及其后面的内容不会被发送到服务器,也就是说,当 url 中 # 后面的内容改变时,浏览器不会发送请求,因此就不会进行页面刷新。
因此可以用 url 中 # 后面内容的改变来让 url 改变,从而模拟跳转页面。
手动实现一个前端路由器的思路就是匹配不同的 url路径 ,然后动态渲染出对应的 html 内容。
用到的 URL 相关的 Web API 有:window.location.hash、hashchange event
//inde.html<body><a href="#1">查看第1个页面</a><a href="#2">查看第2个页面</a><a href="#3">查看第3个页面</a><a href="#4">查看第4个页面</a><div id="app"></div><script src="./index.js"></script></body>
//index.jsconst app = document.querySelector("#app")const div1 = document.createElement('div')div1.innerHTML = '我是第1个页面的内容'const div2 = document.createElement('div')div2.innerHTML = '我是第2个页面的内容'const div3 = document.createElement('div')div3.innerHTML = '我是第3个页面的内容'const div4 = document.createElement('div')div4.innerHTML = '我是第4个页面的内容'const div404 = document.createElement('div')div404.innerHTML = '您输入的页面不存在'const routeTable = {'1': div1,'2': div2,'3': div3,'4': div4}function route(){const hash = window.location.hash.substr(1) || '1' //保底值为默认路由let div = routeTable[hash]if(!div){div = div404}//404页面app.innerHTML = ''app.appendChild(div)}route()window.addEventListener('hashchange',()=>{route()})
4. 手动完善路由器之嵌套路由
上述手写的路由器只是单层的路由,嵌套路由是指,在第一层路由下的一个页面中还有向下层继续跳转的页面。url 要记录完整的路由信息,因此嵌套路由为如下形式 #1/1
//index.jsconst app = document.querySelector('#app')const div1 = document.createElement('div')div1.innerHTML = `<br/>我是第1个页面的内容,我有两个路由<a href="#1/1">查看1.1页面</a><a href="#1/2">查看1.2页面</a>`const div11 = document.createElement('div')div11.innerHTML = '我是1.1页面的内容'const div12 = document.createElement('div')div12.innerHTML = '我是1.2页面的内容'const div2 = document.createElement('div')div2.innerHTML = `<br/>我是第2个页面的内容,我有两个路由<a href="#2/1">查看2.1页面</a><a href="#2/2">查看2.2页面</a>`const div21 = document.createElement('div')div21.innerHTML = '我是2.1页面的内容'const div22 = document.createElement('div')div22.innerHTML = '我是2.2页面的内容'const div3 = document.createElement('div')div3.innerHTML = '我是第3个页面的内容'const div4 = document.createElement('div')div4.innerHTML = '我是第4个页面的内容'const div404 = document.createElement('div')div404.innerHTML = '您输入的页面不存在'const routeTable = {'1': div1,'2': div2,'3': div3,'4': div4}const routeTable2 = {'1/1': div11,'1/2': div12,'2/1': div21,'2/2': div22}const hashTable = {1: routeTable,2: routeTable2}//不同的层数对应不同的 routeTablefunction route(table){const hash = window.location.hash.substr(1) || '1'let div = table[hash]if(!div){div = div404}app.innerHTML = ''app.appendChild(div)}route(routeTable)window.addEventListener('hashchange',()=>{const hash = window.location.hash.substr(1) || '1'const hashArray = hash.split('/')const table = hashTable[hashArray.length]route(table)})
5. 更改路由模式为 history
上述内容是用 hash 的模式实现了前端路由器。所谓的 hash 就是 window.location.hash 获得的以 # 开头的 url。hash 模式的路由器的实现依赖的原理就是 url 中 # 后面的内容不会被浏览器发送到服务器,# 后面的内容变化不会引起浏览器的刷新,可以随时修改 # 后面的内容来模拟页面跳转。
hash 模式是所有情况下都可以使用的,但是有一个致命的缺点就是:SEO不友好。为什么会这样呢?那是因为搜索引擎(SEO)的服务器在收录网页信息时是根据一个 url 对应一个页面信息的方式来收录的。这样才能在用户搜索到页面中的关键字时准确地返回该页面。hash 模式下,无论是 http://localhost:1234/#1还是 http://localhost:1234/#3/1,在向后台发送请求时的 url 都是 http://localhost:1234/,返回的都是同一个页面,然后通过 JS文件 修改页面的显示内容。这样一来,在搜索引擎的服务器上存储该 SPA 的永远都是一个页面,就无法准确地提供相关的搜索。
在后来的发展中,Web API 中的 History 接口新增了两个方法,就是 pushState() 和 replaceState(),这两个方法的作用简单来说就是可以让程序员手动随意修改 url,而不是仅仅像 go() / back() / forward() 这样有限制地修改 url。而且,这两个方法最神奇的是不会引起浏览器的页面刷新,也就是说不会向后端发起请求。可看如下实例,注意 url 的变化。
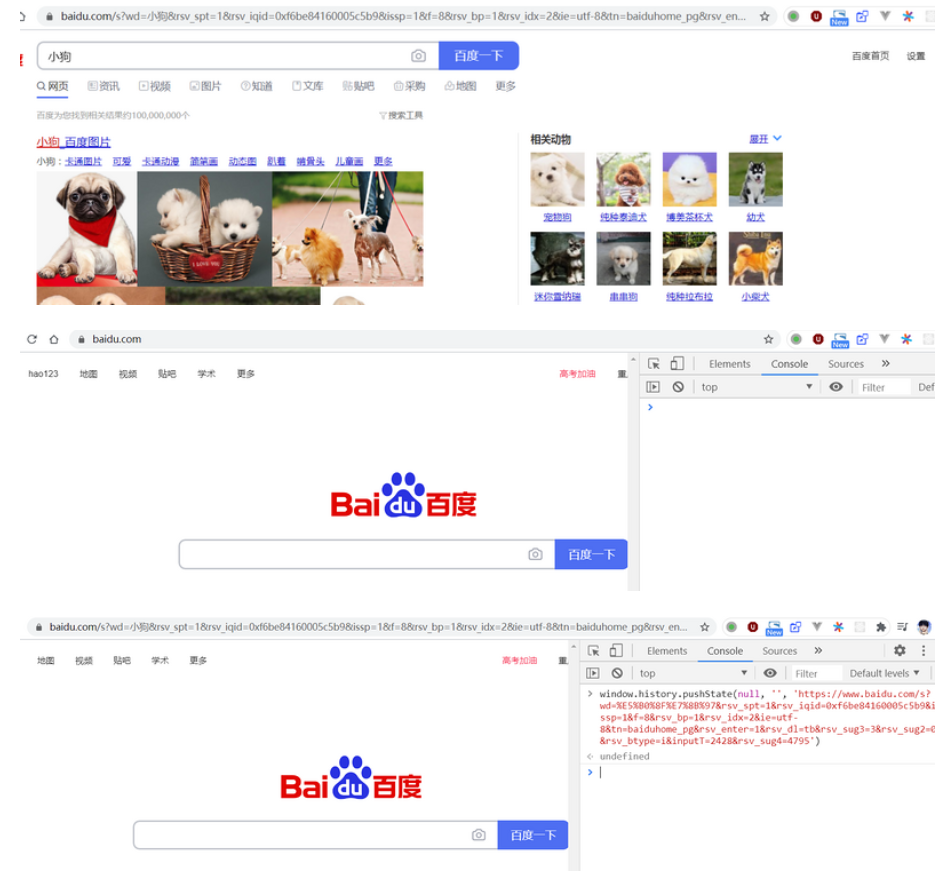
因此有了这两个神奇接口的出现,我们就可以修改 url 必须带 # 的 SPA 前端路由的局面。具体思路就是,手动拦截 a 标签的默认页面刷新事件,然后再手动改变 url。
下面开始代码实现,其实只要在上述的 hash 模式上修改就行。获取 url 的相关信息就不能再使用 window.location.hash 属性了,要用 window.location.pathname

用到的 API 为 window.location.pathname、window.history.pushState()
//index.html<body><a class="link" href="/1">查看第1个页面</a><a class="link" href="/2">查看第2个页面</a><a class="link" href="/3">查看第3个页面</a><a class="link" href="/4">查看第4个页面</a><div id="app"></div><script src="./index.js"></script></body>
//index.jsconst app = document.querySelector('#app')const div1 = document.createElement('div')div1.innerHTML = `<br/>我是第1个页面的内容,我有两个路由<a class="link" href="/1/1">查看1.1页面</a><a class="link" href="/1/2">查看1.2页面</a>`const div11 = document.createElement('div')div11.innerHTML = '我是1.1页面的内容'const div12 = document.createElement('div')div12.innerHTML = '我是1.2页面的内容'const div2 = document.createElement('div')div2.innerHTML = `<br/>我是第2个页面的内容,我有两个路由<a class="link" href="/2/1">查看2.1页面</a><a class="link" href="/2/2">查看2.2页面</a>`const div21 = document.createElement('div')div21.innerHTML = '我是2.1页面的内容'const div22 = document.createElement('div')div22.innerHTML = '我是2.2页面的内容'const div3 = document.createElement('div')div3.innerHTML = '我是第3个页面的内容'const div4 = document.createElement('div')div4.innerHTML = '我是第4个页面的内容'const div404 = document.createElement('div')div404.innerHTML = '您输入的页面不存在'const routeTable = {'1': div1,'2': div2,'3': div3,'4': div4}const routeTable2 = {'1/1': div11,'1/2': div12,'2/1': div21,'2/2': div22}const hashTable = {1: routeTable,2: routeTable2}//不同的层数对应不同的 routeTablefunction route(table){const pathname = window.location.pathname.substr(1) || '1'let div = table[pathname]if(!div){div = div404}app.innerHTML = ''app.appendChild(div)}document.body.addEventListener('click', (e)=>{e.preventDefault()const el = e.targetif(el.tagName === 'A' && el.matches('.link')){const href = el.getAttribute('href')window.history.pushState(null, '', href)onStateChange()}})route(routeTable)function onStateChange(){const pathname = window.location.pathname.substr(1) || '1'const pathArray = pathname.split('/')const table = hashTable[pathArray.length]route(table)}
但是 history 模式下的前端路由,IE8 不支持,并且需要后端服务器的支持。
因为刷新后发送的 url 请求为
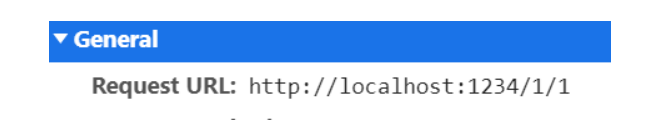
后端服务器面对来自前端浏览器发起的请求路径原本就有自己的服务器路由,因此会查询自己的服务器路由进行转发,会被发到 404 页面。因此,若想使用 history 模式下的路由,需要让后端服务器配合,将所有前端路由都渲染到同一页面,就是都返回同一个页面。
history 模式的特点:
1. 需要后端服务器的配合,将所有前端路由渲染至一个页面
2. IE8 不支持
6. memory 模式
SPA 路由器的实现方式还有一种 memory 模式,memory 模式的实现不依赖于 url 的变化,就是说,页面内容切换,url 始终保持不变,实现方法就是使用 window.localStorage 存储当前路径即可。在上述代码的基础上修改两句就是 memory 模式了,其他地方不变。
function route(table){//const pathname = window.location.pathname.substr(1) || '1'const pathname = window.localStorage.getItem('url') || '1'let div = table[pathname]if(!div){div = div404}app.innerHTML = ''app.appendChild(div)}document.body.addEventListener('click', (e)=>{e.preventDefault()const el = e.targetif(el.tagName === 'A' && el.matches('.link')){const href = el.getAttribute('href')//window.history.pushState(null, '', href)window.localStorage.setItem('url', href.substr(1))onStateChange()}})
但这种方式不适合网页应用,url 信息是存储到本地的,无法准确分享页面。因此只适合单机应用。在前端路由中一般不适用。
参考博客

若有收获,就点个赞吧
0 人点赞
