- 00 Kubernetes是什么
- 01 Node
- 02 pod
- 为什么需要 Kubernetes
- Kubernetes 组件
- Node 组件
- ">kubelet
- ">kube-proxy
- 容器运行时(Container Runtime)
- 插件(Addons)
- DNS
- Web 界面(仪表盘)
- 容器资源监控
- 集群层面日志
- 理解 Kubernetes 对象
- ">描述 Kubernetes 对象
- 必需字段
- ">指令式对象配置
- 对象名称和 IDs
- When to Use Multiple Namespaces
- Labels and Selectors
- Syntax and character set
- Labels and Selectors
- ">API
- ">Set references in API objects
- Field Selectors
- Labels
- Nodes
- Management
- ">Self-registration of Nodes
- ">Node status
- ">Addresses
- ">Conditions
00 Kubernetes是什么
Kubernetes 是 Google 于 2014 年 6 月基于其内部使用的 Borg 系统开源出来的容器编排调度引擎。
Kubernetes 运行在节点 (node) 上,节点是集群中的单个机器。如果有自己的硬件,节点可能对应于物理机器,但更可能对应于在云中运行的虚拟机。节点是部署的应用或服务的地方,是 Kubernetes 工作的地方。有 2 种类型的节点 ——master 节点和 worker 节点,所以说 Kubernetes 是主从结构的。
Kubernets所有的操作都可以通过Kubernetes API来进行,通过API来操作Kubernetes中的对象,包括Pod、Service、Volume、Namespace等等。
01 Node
Node 可以是一个物理机也可以是虚拟机,每个节点上都运行了可以运行 Pods 的服务。通过Master节点来进行管理。节点实际上是由云供应商提供的,Kubernetes管理中创建节点实际上只是在Kubernetes中创建一个代表节点的对象。
Node 包含以下几方面的信息:
- Addresses:包括主机名、内部IP、外部IP。
- Condition:描述运行的状态,包括OutOfDisk、Ready、MemoryPressure、PIDPressure、DiskPressure、NetworkUnavailable、ConfigOK。
- Capacity:描述节点资源的情况,包括CPU, memory and the maximum number of pods that can be scheduled onto the node.
- Info:包括内核版本、Kubernetes版本、Docker版本、OS等基础信息。
02 pod
Pod 是Kubernetes中可以创建和部署的最小单位。Pod包含了应用容器、存储资源、唯一的网络IP地址以及容器运行的参数。Pod内部的容器共享的网络、存储资源。Docker是Pod中最常用的容器运行环境,但仍允许用户使用其他的容器环境。
Pod使用有两种方式:一个容器一个Pod、一个Pod中运行多个容器。Pods设计的目标就是支持多个容器进程共同组合为一个服务,这种用法是一个相对高级的功能,仅有程序间存在紧耦合情况是才这么用。
为什么需要 Kubernetes
Kubernetes 为你提供:
- 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 - 存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 - 自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。 - 自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
Kubernetes 组件
一个 Kubernetes 集群由一组被称作节点的机器组成。这些节点上运行 Kubernetes 所管理的容器化应用。集群具有至少一个工作节点。
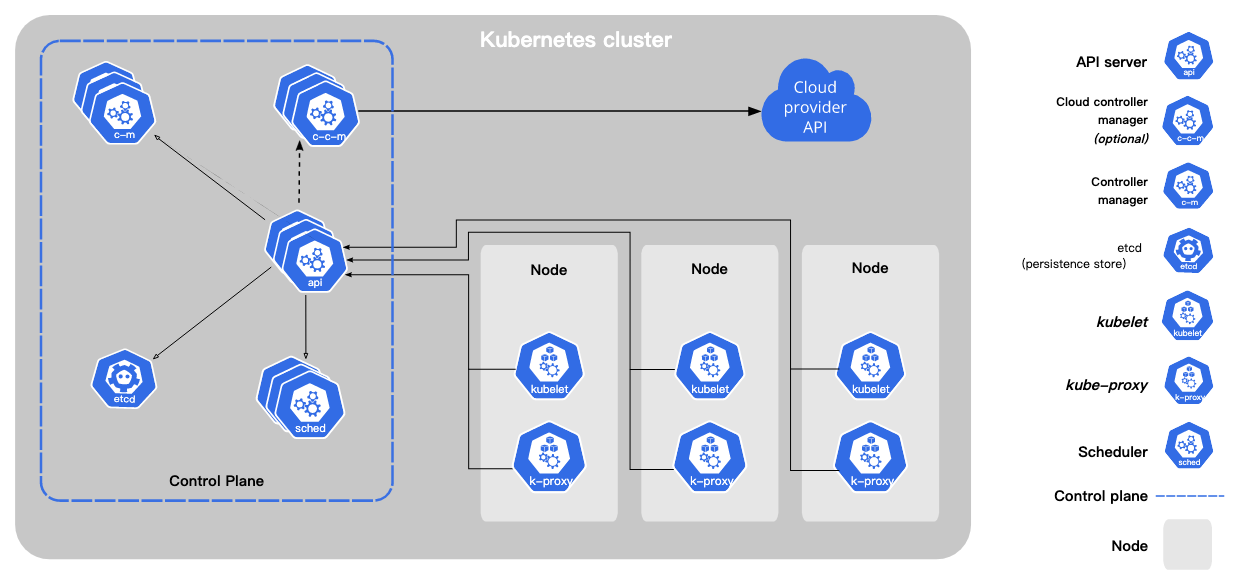
kube-apiserver
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。
etcd
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
kube-scheduler
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
kube-controller-manager
在主节点上运行 控制器 的组件。
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
cloud-controller-manager
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器允许您链接集群到云提供商的应用编程接口中, 并把和该云平台交互的组件与只和您的集群交互的组件分离开。
cloud-controller-manager 仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。
下面的控制器都包含对云平台驱动的依赖:
- 节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
- 路由控制器(Route Controller): 用于在底层云基础架构中设置路由
- 服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
Node 组件
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
kubelet
一个在集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
kube-proxy
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身。
容器运行时(Container Runtime)
容器运行环境是负责运行容器的软件。
Kubernetes 支持多个容器运行环境: Docker、 containerd、CRI-O 以及任何实现 Kubernetes CRI (容器运行环境接口)。
插件(Addons)
插件使用 Kubernetes 资源(DaemonSet、 Deployment等)实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于 kube-system 命名空间。
DNS
尽管其他插件都并非严格意义上的必需组件,但几乎所有 Kubernetes 集群都应该 有集群 DNS, 因为很多示例都需要 DNS 服务。
集群 DNS 是一个 DNS 服务器,和环境中的其他 DNS 服务器一起工作,它为 Kubernetes 服务提供 DNS 记录。
Kubernetes 启动的容器自动将此 DNS 服务器包含在其 DNS 搜索列表中。
Web 界面(仪表盘)
Dashboard 是 Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身并进行故障排除。
容器资源监控
容器资源监控 将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中,并提供用于浏览这些数据的界面。
集群层面日志
集群层面日志 机制负责将容器的日志数据 保存到一个集中的日志存储中,该存储能够提供搜索和浏览接口。
理解 Kubernetes 对象
在 Kubernetes 系统中,Kubernetes 对象 是持久化的实体。 Kubernetes 使用这些实体去表示整个集群的状态。特别地,它们描述了如下信息:
- 哪些容器化应用在运行(以及在哪些节点上)
- 可以被应用使用的资源
- 关于应用运行时表现的策略,比如重启策略、升级策略,以及容错策略
几乎每个 Kubernetes 对象包含两个嵌套的对象字段,它们负责管理对象的配置: 对象 _spec_(规约) 和 对象 _status_(状态) 。
操作 Kubernetes 对象 —— 无论是创建、修改,或者删除 —— 需要使用 Kubernetes API。 比如,当使用 kubectl 命令行接口时,CLI 会执行必要的 Kubernetes API 调用, 也可以在程序中使用 客户端库直接调用 Kubernetes API。
描述 Kubernetes 对象
创建 Kubernetes 对象时,必须提供对象的规约,用来描述该对象的期望状态, 以及关于对象的一些基本信息(例如名称)。 当使用 Kubernetes API 创建对象时(或者直接创建,或者基于kubectl), API 请求必须在请求体中包含 JSON 格式的信息。 大多数情况下,需要在 .yaml 文件中为 **kubectl** 提供这些信息。 kubectl 在发起 API 请求时,将这些信息转换成 JSON 格式。
必需字段
在想要创建的 Kubernetes 对象对应的 .yaml 文件中,需要配置如下的字段:
apiVersion- 创建该对象所使用的 Kubernetes API 的版本kind- 想要创建的对象的类别metadata- 帮助唯一性标识对象的一些数据,包括一个name字符串、UID 和可选的namespace
指令式对象配置
创建配置文件中定义的对象:
kubectl create -f nginx.yaml
删除两个配置文件中定义的对象:
kubectl delete -f nginx.yaml -f redis.yaml
对象名称和 IDs
DNS 子域名
这一要求意味着名称必须满足如下规则:
- 不能超过253个字符
- 只能包含小写字母、数字,以及’-‘ 和 ‘.’
- 须以字母数字开头
- 须以字母数字结尾
DNS 标签名
也就是命名必须满足如下规则:
- 最多63个字符
- 只能包含小写字母、数字,以及’-‘
- 须以字母数字开头
- 须以字母数字结尾
When to Use Multiple Namespaces
Namespaces cannot be nested inside one another and each Kubernetes resource can only be in one namespace.
Viewing namespaces
kubectl get namespace
Kubernetes starts with four initial namespaces:
- default The default namespace for objects with no other namespace
- kube-system The namespace for objects created by the Kubernetes system
- kube-public This namespace is created automatically and is readable by all users (including those not authenticated). This namespace is mostly reserved for cluster usage, in case that some resources should be visible and readable publicly throughout the whole cluster. The public aspect of this namespace is only a convention, not a requirement.
- kube-node-lease This namespace for the lease objects associated with each node which improves the performance of the node heartbeats as the cluster scales.
Setting the namespace for a request
For example
kubectl run nginx --image=nginx --namespace=<insert-namespace-name-here> kubectl get pods --namespace=<insert-namespace-name-here>
Setting the namespace preference
kubectl config set-context --current --namespace=<insert-namespace-name-here># Validate itkubectl config view --minify | grep namespace:
Not All Objects are in a Namespace
To see which Kubernetes resources are and aren’t in a namespace:
# In a namespacekubectl api-resources --namespaced=true# Not in a namespacekubectl api-resources --namespaced=false
Labels and Selectors
Labels can be used to organize and to select subsets of objects. Labels can be attached to objects at creation time and subsequently added and modified at any time. Each object can have a set of key/value labels defined. Each Key must be unique for a given object.
"metadata": {"labels": {"key1" : "value1","key2" : "value2"}}
Syntax and character set
apiVersion: v1kind: Podmetadata:name: label-demolabels:environment: productionapp: nginxspec:containers:- name: nginximage: nginx:1.14.2ports:- containerPort: 80
Labels and Selectors
Labels are key/value pairs that are attached to objects, such as pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users, but do not directly imply semantics to the core system. Labels can be used to organize and to select subsets of objects. Labels can be attached to objects at creation time and subsequently added and modified at any time. Each object can have a set of key/value labels defined. Each Key must be unique for a given object.
"metadata": {"labels": {"key1" : "value1","key2" : "value2"}}
Keep in mind that label Key must be unique for a given object.
API
using set-based requirements:
kubectl get pods -l 'environment in (production),tier in (frontend)'
Set references in API objects
Service and ReplicationController
The set of pods that a service targets is defined with a label selector. Similarly, the population of pods that a replicationcontroller should manage is also defined with a label selector.
Labels selectors for both objects are defined in json or yaml files using maps, and only equality-based requirement selectors are supported:
"selector": {"component" : "redis",}
or
selector:component: redis
Field Selectors
Field selectors let you select Kubernetes resources based on the value of one or more resource fields. Here are some examples of field selector queries:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
This kubectl command selects all Pods for which the value of the status.phase field is Running:
kubectl get pods --field-selector status.phase=Running
Labels
To illustrate these labels in action, consider the following StatefulSet object:
apiVersion: apps/v1kind: StatefulSetmetadata:labels:app.kubernetes.io/name: mysqlapp.kubernetes.io/instance: mysql-abcxzyapp.kubernetes.io/version: "5.7.21"app.kubernetes.io/component: databaseapp.kubernetes.io/part-of: wordpressapp.kubernetes.io/managed-by: helmapp.kubernetes.io/created-by: controller-manager
Nodes
Kubernetes runs your workload by placing containers into Pods to run on Nodes. A node may be a virtual or physical machine, depending on the cluster. Each node is managed by the control plane and contains the services necessary to run Pods
Typically you have several nodes in a cluster; in a learning or resource-limited environment, you might have only one node.
The components on a node include the kubelet, a container runtime, and the kube-proxy.
Management
There are two main ways to have Nodes added to the API server:
- The kubelet on a node self-registers to the control plane
- You (or another human user) manually add a Node object
After you create a Node object, or the kubelet on a node self-registers, the control plane checks whether the new Node object is valid. For example, if you try to create a Node from the following JSON manifest:
{"kind": "Node","apiVersion": "v1","metadata": {"name": "10.240.79.157","labels": {"name": "my-first-k8s-node"}}}
Kubernetes creates a Node object internally (the representation). Kubernetes checks that a kubelet has registered to the API server that matches the metadata.name field of the Node. If the node is healthy (i.e. all necessary services are running), then it is eligible to run a Pod. Otherwise, that node is ignored for any cluster activity until it becomes healthy.
note
Kubernetes keeps the object for the invalid Node and continues checking to see whether it becomes healthy.
Self-registration of Nodes
When the kubelet flag --register-node is true (the default), the kubelet will attempt to register itself with the API server. This is the preferred pattern, used by most distros.
For self-registration, the kubelet is started with the following options:
--kubeconfig- Path to credentials to authenticate itself to the API server.--cloud-provider- How to talk to a cloud provider to read metadata about itself.--register-node- Automatically register with the API server.--register-with-taints- Register the node with the given list of taints (comma separated<key>=<value>:<effect>).
No-op ifregister-nodeis false.--node-ip- IP address of the node.--node-labels- Labels to add when registering the node in the cluster (see label restrictions enforced by the NodeRestriction admission plugin).--node-status-update-frequency- Specifies how often kubelet posts node status to master.
When the Node authorization mode and NodeRestriction admission plugin are enabled, kubelets are only authorized to create/modify their own Node resource.
Node status
A Node’s status contains the following information:
You can use kubectl to view a Node’s status and other details:
kubectl describe node <insert-node-name-here>
Addresses
The usage of these fields varies depending on your cloud provider or bare metal configuration.
- HostName: The hostname as reported by the node’s kernel. Can be overridden via the kubelet
--hostname-overrideparameter. - ExternalIP: Typically the IP address of the node that is externally routable (available from outside the cluster).
- InternalIP: Typically the IP address of the node that is routable only within the cluster.
Conditions
The conditions field describes the status of all Running nodes. Examples of conditions include:
| Node Condition | Description |
|---|---|
Ready |
True if the node is healthy and ready to accept pods, False if the node is not healthy and is not accepting pods, and Unknown if the node controller has not heard from the node in the last node-monitor-grace-period (default is 40 seconds) |
DiskPressure |
True if pressure exists on the disk size—that is, if the disk capacity is low; otherwise False |
MemoryPressure |
True if pressure exists on the node memory—that is, if the node memory is low; otherwise False |
PIDPressure |
True if pressure exists on the processes—that is, if there are too many processes on the node; otherwise False |
NetworkUnavailable |

若有收获,就点个赞吧
0 人点赞
