程序是如何运行起来的
软件被开发出来,是文本格式的代码,这些代码通常不能直接运行,需要使用编译器编译成操作系统或者虚拟机可以运行的代码,即可执行代码。要想让程序处理数据,完成计算任务,必须把程序从外部设备加载到内存中,并在操作系统的管理调度下交给 CPU 去执行,去运行起来,才能真正发挥软件的作用,程序运行起来以后,被称作进程。
进程除了包含可执行的程序代码,还包括进程在运行期使用的内存堆空间、栈空间、供操作系统管理用的数据结构。如下图所示:
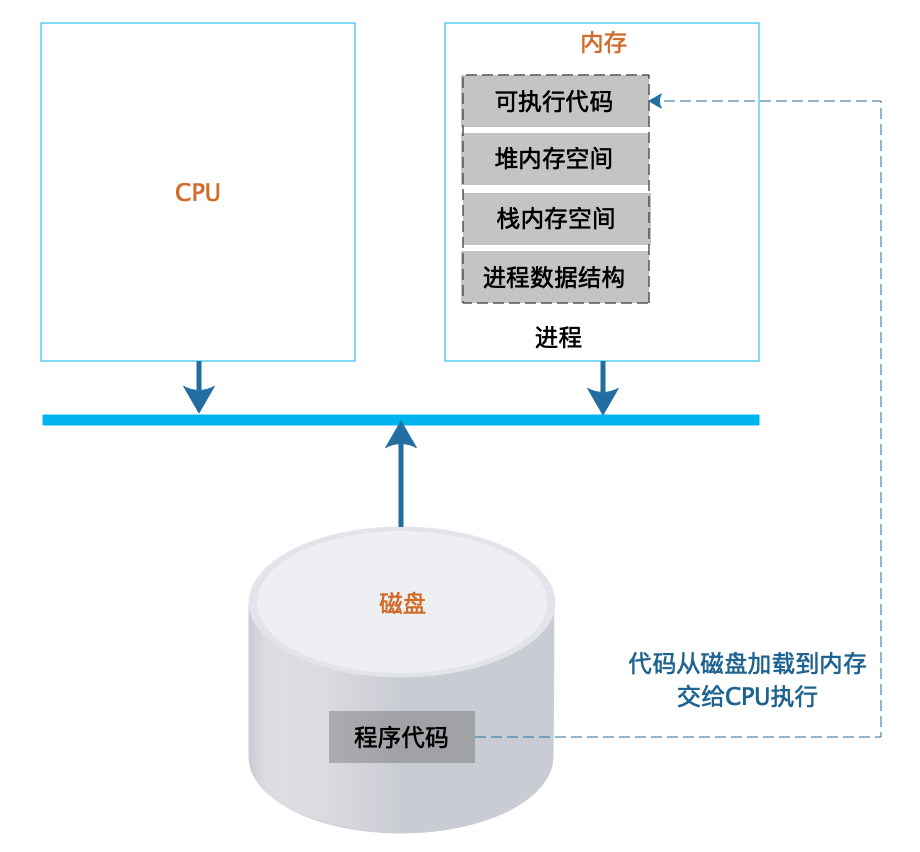
操作系统把可执行代码加载到内存中,生成相应的数据结构和内存空间后,就从可执行代码的起始位置读取指令交给 CPU 顺序执行。指令执行过程中,可能会遇到一条跳转指令,即 CPU 要执行的下一条指令不是内存中可执行代码顺序的下一条指令。编程中使用的循环 for…,while…和 if…else…最后都被编译成跳转指令。
程序运行时如果需要创建数组等数据结构,操作系统就会在进程的堆空间申请一块相应的内存空间,并把这块内存的首地址信息记录在进程的栈中。堆是一块无序的内存空间,任何时候进程需要申请内存,都会从堆空间中分配,分配到的内存地址则记录在栈中。
栈是严格的一个后进先出的数据结构,同样由操作系统维护,主要用来记录函数内部的局部变量、堆空间分配的内存空间地址等。
栈的操作过程:
void f(){int x = g(1); x++; //g函数返回,当前堆栈顶部为f函数栈帧,在当前栈帧继续执行f函数的代码。}int g(int x){ return x + 1;}
每次函数调用,操作系统都会在栈中创建一个栈帧(stack frame)。正在执行的函数参数、局部变量、申请的内存地址等都在当前栈帧中,也就是堆栈的顶部栈帧中。如下图所示:
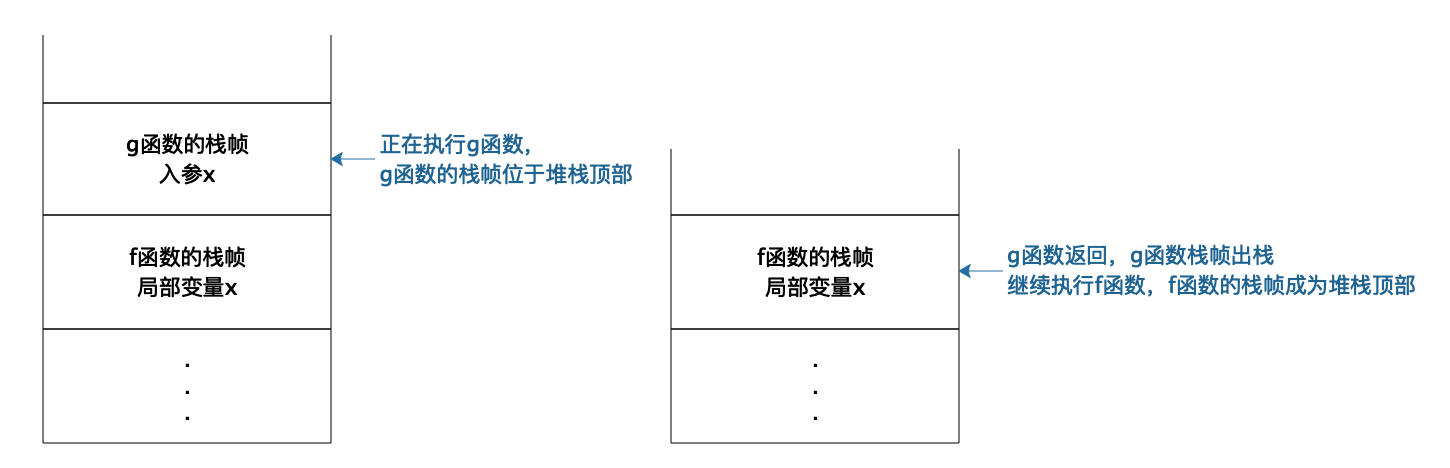
当 f 函数执行的时候,f 函数就在栈顶,栈帧中存储着 f 函数的局部变量,输入参数等等。当 f 函数调用 g 函数,当前执行函数就变成 g 函数,操作系统会为 g 函数创建一个栈帧并放置在栈顶。当函数 g() 调用结束,程序返回 f 函数,g 函数对应的栈帧出栈,顶部栈帧变又为 f 函数,继续执行 f 函数的代码,也就是说,真正执行的函数永远都在栈顶。而且因为栈帧是隔离的,所以不同函数可以定义相同的变量而不会发生混乱。
一台计算机如何同时处理数以百计的任务
主要依靠的是操作系统的 CPU 分时共享技术。如果同时有很多个进程在执行,操作系统会将 CPU 的执行时间分成很多份,进程按照某种策略轮流在 CPU 上运行。由于现代 CPU 的计算能力非常强大,虽然每个进程都只被执行了很短一个时间,但是在外部看来却好像是所有的进程都在同时执行,每个进程似乎都独占一个 CPU 执行。
所以虽然从外部看起来,多个进程在同时运行,但是在实际物理上,进程并不总是在 CPU 上运行的,一方面进程共享 CPU,所以需要等待 CPU 运行,另一方面,进程在执行 I/O 操作的时候,也不需要 CPU 运行。进程在生命周期中,主要有三种状态,运行、就绪、阻塞。
运行:当一个进程在 CPU 上运行时,则称该进程处于运行状态。处于运行状态的进程的数目小于等于 CPU 的数目。
就绪:当一个进程获得了除 CPU 以外的一切所需资源,只要得到 CPU 即可运行,则称此进程处于就绪状态,就绪状态有时候也被称为等待运行状态。
阻塞:也称为等待或睡眠状态,当一个进程正在等待某一事件发生(例如等待 I/O 完成,等待锁……)而暂时停止运行,这时即使把 CPU 分配给进程也无法运行,故称该进程处于阻塞状态。

若有收获,就点个赞吧
0 人点赞
