nsq 是什么
纯go实现的消息队列
A realtime distributed messaging platform
核心概念:
- message
- 数据流形式,生产者需要消费者处理的一个数据流(包)。
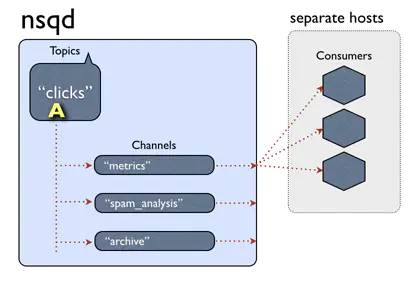
- topic
- message属于某个特定的topic
- 在由生产者在发布消息时生成
- 通常描述消息的内容
- channel
生产者与消费者之间的消息通道,相当于消息队列。
- 一个topic可以有多个channel
- 一个channel只能对应一个topic
- channel由消费者首次订阅产生,一个channel可以有多个消费者,起负载均衡的作用。
- 一个topic的消息会复制到与topic关联的各个channel
- channel的名称通常描述的是消费者的业务
nsqd
一个负责接收、排队、转发消息到客户端的守护进程。负责message的收发和队列的维护。
nsqd默认监听一个TCP端口(4150)和一个HTTP端口 (4151)。 nsqd功能特性:- topic发布到channel中的消息会被消费者消费
- 只要channel存在,即使没有消费者,生产者的message也会缓存在队列中
- topic发布的message至少会被消费一次,nsq正常退出,消息会被写入磁盘
- 限制内存中用,channel中的message是存放在内存中的,可以限制其大小,超出时可以将 message缓存到磁盘
- topic和channel一旦创建就会一直存在,除非主动删除
工作流程
- 启动nsqlookupd服务
- 启动nsqd服务,nsqd服务会向nsqlookup广播自己的节点信息,将自己的信息注册到nsqlookupd上
- 生产者选一个topic向nsqd发布消息,这时nsqd会将这些信息同步到nsqlookupd服务,在消费者没有准备好时会将数据存放在本地
- 消费者通过查询nsqlookupd或者直接绑定的方式连接nsqd,并创建channel和选择订阅自己感兴趣的topic
- 有topic发布消息时,这些消息会被复制到各个channel,将消息推送(PUSH)给消费者消费
消息的生命周期
生产者发布一个消息之后,通过以下途径保证消息可靠性:
- client连接上nsqd,并通过RDY参数告知可以处理的message数量
- nsqd 把消息暂存起来或者推送到各个连接的channels,对于状态为REQ 和 timeout的都会被暂存起来
- 客户端消费消息之后,回复nsqd一个FIN表示消息成功处理,或者REQ表示表示这个消息将会继续重新加入到队列中, 如果处理时间超过配置的timeout时间,则nsqd会把这个消息当成超时处理
- 如果客户端一直没有回复直到超时,则这个消息会被当成超时消息重新加入到队列中
特征:
- 分布式的
- NSQ提倡没有单点故障的分布式和分散拓扑,支持容错和高可用性,并提供可靠的消息传递保证
- 可扩展
- NSQ水平扩展,没有任何集中的代理。内置的发现功能简化了向集群添加节点的工作。支持发布-订阅和负载平衡的消息传递。它也很快。
- 操作友好
- NSQ易于配置和部署,并附带一个管理UI。二进制文件没有运行时依赖性,我们为linux、darwin、freebsd和windows以及官方Docker映像提供预编译版本。
- 完整的
- 官方的Go和Python库以及大多数主要语言的社区支持的库都是可用的(参见客户端库)。
- 主要操作在内存中,达到一定条件落到磁盘
其他特征:
- 基于低延迟推送的消息传递(性能)
- 负载平衡和多播风格的消息路由组合
- 在流(高吞吐量)和面向工作(低吞吐量)的工作负载方面表现出色
- 主要在内存中(超出高水位标记的消息透明地保存在磁盘上)
- 供使用者查找生产者的运行时发现服务(nsqlookupd)
- 传输层安全性(TLS)
- 不可知的数据格式
- 很少的依赖项(易于部署)和合理,有界的默认配置
- 支持任何语言的客户端库的简单TCP协议
- 统计信息,管理操作和生产者的HTTP接口(无需发布客户端库)
- 与statsd集成以进行实时检测
- 强大的集群管理界面(nsqadmin)
保证
- 消息不持久(默认情况下)
- 尽管系统支持一个—mem-queue-size选项,设置之后,消息可以透明的保存到磁盘上,但是,它主要还是一个内存中的消息传递平台。
- 可以将—mem-queue-size设置为0,以确保所有传入消息都持久保存到磁盘。 在这种情况下,如果节点发生故障,那么您的故障面就会减少
- 没有内置的复制。 但是,可以通过多种方式来管理此折衷方案,例如部署拓扑和以容错方式主动将主题从属并将其持久化到磁盘的技术。
- 消息至少传递一次
- 与上面的内容密切相关,这假定给定的nsqd节点不会失败。
- 这意味着,由于多种原因,可以多次传递消息(客户端超时,断开连接,重新排队等)。 客户有责任执行幂等操作或重复数据删除。
收到的消息是无序的
- 您不能依靠传递给使用者的消息顺序。
- 与消息传递语义类似,这是重新排队,内存中存储和磁盘存储组合以及每个nsqd节点不共享任何事实的结果。
- 通过在您的使用者中引入一个等待时间窗口以接受消息并在处理之前对其进行排序,可以轻松地实现松散的排序(即,对于给定的使用者,其消息是有序的,而不是整个集群)。 保留此不变变量,必须丢弃该窗口之外的消息)。
消费者最终会找到所有的主题生产者
- 发现服务(nsqlookupd)旨在最终保持一致。 nsqlookupd节点不协调维护状态或回答查询。网络分区不会影响可用性,因为分区的两侧仍然可以回答查询。 部署拓扑对缓解这些类型的问题具有最重要的作用。
Nsq的组件
NSQ由3个守护程序组成:
- nsqd是接收,排队并将消息传递到客户端的守护程序。它可以独立运行,但通常在具有nsqlookupd实例的群集中配置(在这种情况下,它将宣布主题和发现通道)。它监听两个TCP端口,一个用于客户机,另一个用于HTTP API。它可以选择监听HTTPS的第三个端口。
- nsqlookupd是管理拓扑信息并提供最终一致的发现服务的守护程序。 客户端查询nsqlookupd以发现特定主题的nsqd生产者,并且nsqd节点广播主题和频道信息。有两个接口:nsqd用于广播的TCP接口和客户机用于执行发现和管理操作的HTTP接口。
- nsqadmin是一个Web UI,用于实时内省群集(并执行各种管理任务)。
nsqd 消息队列的主体,对消息的接收,处理和把消息分发到客户端。 nsqlookupd nsq拓扑结构信息的管理者,有了他才能组成一个简单易用的无中心化的分布式拓扑网络结构。 go-nsq nsq官方的go语言客户端
使用方式
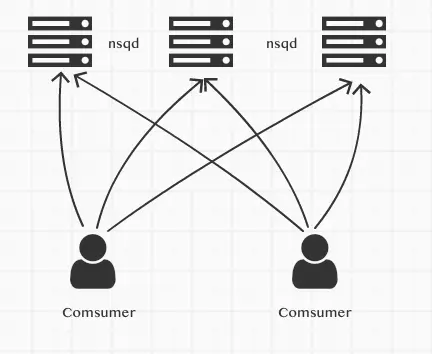
直连方式
nsqd是独立运行的,可以直接使用部署几个nsqd然后使用客户端直连的方式使用
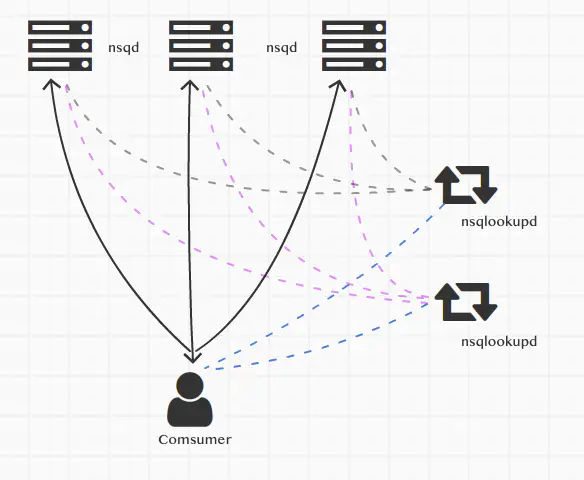
去中心化连接方式 nsqlookupd
官方推荐使用连接nsqlookupd的方式,nsqlookupd用于做服务的注册和发现,这样可以做到去中心化。
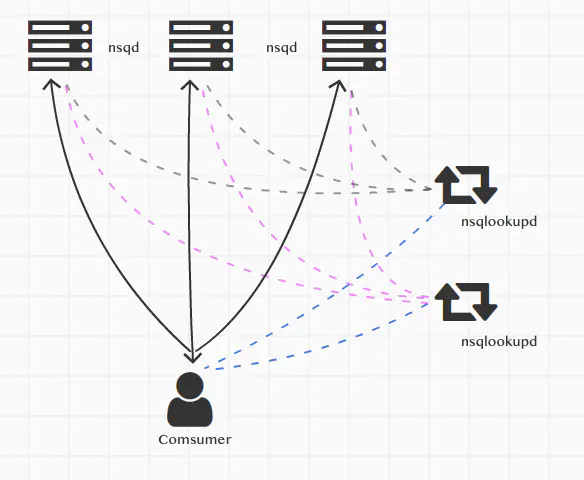
运行着多个nsqd和多个nsqlookupd的实例,客户端去连接nsqlookupd来操作nsqd
nsqlookupd用于管理整个网络拓扑结构,nsqd用他实现服务的注册,客户端使用他得到所有的nsqd服务节点信息,然后所有的consumer端连接 实现原理如下
nsqd把自己的服务信息广播给一个或者多个nsqlookupd客户端连接一个或者多个nsqlookupd,通过nsqlookupd得到所有的nsqd的连接信息,进行连接消费,- 如果某个
nsqd出现问题,down机了,会和nsqlookupd断开,这样客户端从nsqlookupd得到的nsqd的列表永远是可用的。客户端连接的是所有的nsqd,一个出问题了就用其他的连接,所以也不会受影响。
nsqd和nsqlookupd的通信实现
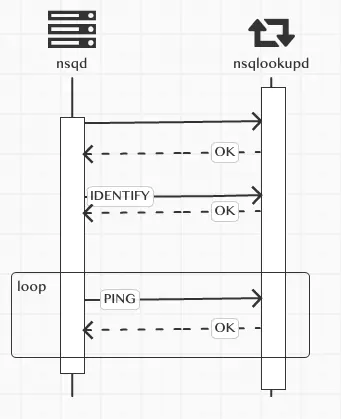
nsqd启动后连接nsqlookupd,连接成功后,要发送一个魔法标识nsq.MagicV1,这个标识有啥魔法么,当然不是,他只是用于标明,客户端和服务端双方使用的信息通信版本,不能的版本有不同的处理方式,为了后期做新的消息处理版本方便吧。nsqlookupd 的代码块
这个时候的nsqd已经和nsqlookupd建立好了连接,但是这时,仅仅说明他俩连接成功。nsqlookupd也并没有把这个连接加到可用的nsqd列表里。 建立连接完成后,nsqd会发送IDENTIFY命令,这个命令里包含了nsq的基本信息nsqd的代码
包含了nsqd 提供的tcp和http端口,主机名,版本等等,发送给nsqlookupd,nsqlookupd收到IDENTIFY命令后,解析信息然后加到nsqd的可用列表里 nsqlookupd 的代码块
然后每过15秒,会发送一个PING心跳命令给nsqlookupd,这样保持存活状态,nsqlookupd每次收到发过来的PING命令后,也会记下这个nsqd的最后更新时间,这样做为一个筛选条件,如果长时间没有更新,就认为这个节点有问题,不会把这个节点的信息加入到可用列表。 到此为止,一个nsqd就把自己的信息注册到nsqlookupd的可用列表了,我们可以启动多个nsqd和多个nsqlookupd,为nsqd指定多个nsqlookupd
nsqd和所有的nsqlookupd建立连接,注册服务信息,并保持心跳,保证可用列表的更新.
nsqlookupd 挂掉的处理方式
nsqd如果出现问题,nsqlookupd的nsqd可用列表里就会处理掉这个连接信息。如nsqlookupd挂了怎么办呢
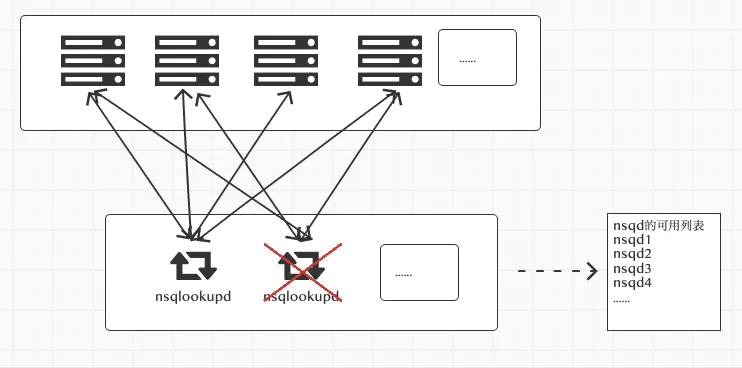
目前的处理方式是这样的, 无论是心跳,还是其他命令,nsqd会给所有的nsqlookup发送信息,当nsqd发现nsqlookupd出现问题时,在每次发送命令时,会不断的进行重新连接:
func (lp *lookupPeer) Command(cmd *nsq.Command) ([]byte, error) {initialState := lp.stateif lp.state != stateConnected {err := lp.Connect()if err != nil {return nil, err}lp.state = stateConnected_, err = lp.Write(nsq.MagicV1)if err != nil {lp.Close()return nil, err}if initialState == stateDisconnected {lp.connectCallback(lp)}if lp.state != stateConnected {return nil, fmt.Errorf("lookupPeer connectCallback() failed")}}// ...}
如果连接成功,会再次调用connectCallback方法,进行IDENTIFY命令的调用等。
客户端和nsqlookupd、nsqd的通信实现
adds := []string{"127.0.0.1:7201", "127.0.0.1:8201"}config := nsq.NewConfig()config.MaxInFlight = 1000config.MaxBackoffDuration = 5 * time.Secondconfig.DialTimeout = 10 * time.SecondtopicName := "testTopic1"c, _ := nsq.NewConsumer(topicName, "ch1", config)testHandler := &MyTestHandler{consumer: c}c.AddHandler(testHandler)if err := c.ConnectToNSQLookupds(adds); err != nil {panic(err)}
需要注意adds里地址的端口,是nsqlookupd的http端口
调用方法c.ConnectToNSQLookupds(adds),他的实现是访问nsqlookupd的http端口[http://127.0.0.1:7201/lookup?topic=testTopic1](http://127.0.0.1:7201/lookup?topic=testTopic1)得到提供consumer订阅的topic所有的producers节点信息
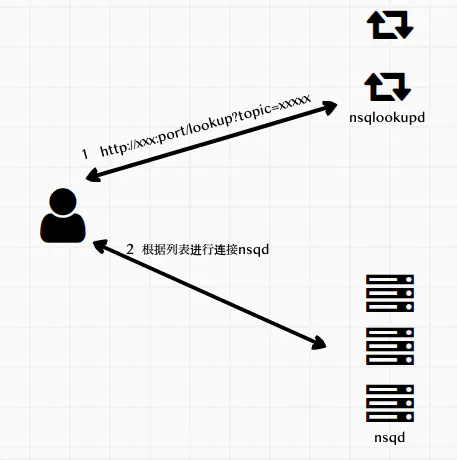
方法queryLookupd就是进行的上图的操作
- 得到提供订阅的
topic的nsqd列表 - 进行连接
如何刷新nsqd的可用列表
有新的nsqd加入,是如何处理的呢? 在调用ConnectToNSQLookupd时会启动一个协程go r.lookupdLoop() 调用方法lookupdLoop的定时循环访问 queryLookupd 更新 nsqd的可用列表
// poll all known lookup servers every LookupdPollIntervalfunc (r *Consumer) lookupdLoop() {// ...var ticker *time.Tickerselect {case <-time.After(jitter):case <-r.exitChan:goto exit}// 设置Interval 来循环访问 queryLookupdticker = time.NewTicker(r.config.LookupdPollInterval)for {select {case <-ticker.C:r.queryLookupd()case <-r.lookupdRecheckChan:r.queryLookupd()case <-r.exitChan:goto exit}}exit:// ...}
处理 nsqd 的单点故障
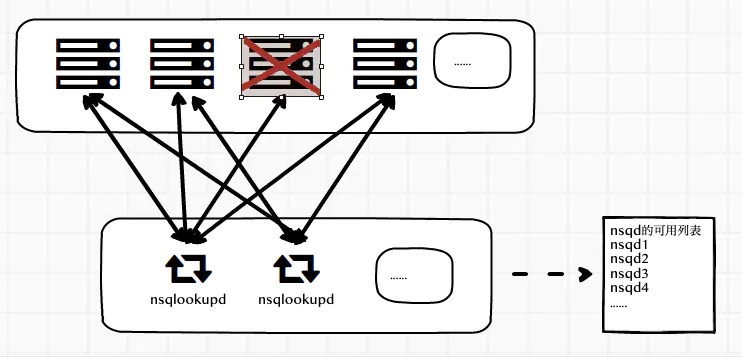
当有nsqd出现故障时怎么办?当前的处理方式是
nsqdlookupd会把这个故障节点从可用列表中去除,客户端从接口得到的可用列表永远都是可用的。- 客户端会把这个故障节点从可用节点上移除,然后要去判断是否使用了
nsqlookup进行了连接,如果是则case r.lookupdRecheckChan <- 1去刷新可用列表queryLookupd,如果不是,然后启动一个协程去定时做重试连接,如果故障恢复,连接成功,会重新加入到可用列表. 客户端实现的代码
func (r *Consumer) onConnClose(c *Conn) {// ...// remove this connections RDY count from the consumer's totaldelete(r.connections, c.String())left := len(r.connections)// ...r.mtx.RLock()numLookupd := len(r.lookupdHTTPAddrs)reconnect := indexOf(c.String(), r.nsqdTCPAddrs) >= 0// 如果使用的是nslookup则去刷新可用列表if numLookupd > 0 {// trigger a poll of the lookupdselect {case r.lookupdRecheckChan <- 1:default:}} else if reconnect {// ...}(c.String())}}
nsq是如何保证消息不丢的
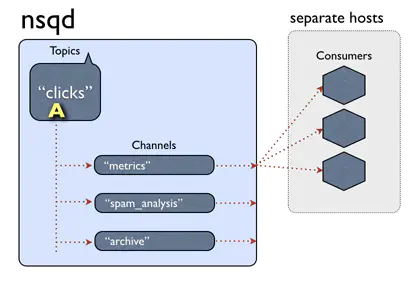
nsq topic、channel、和消费我客户端的结构如上图,一个topic下有多个channel每个channel可以被多个客户端订阅。 消息处理的大概流程:当一个消息被nsq接收后,传给相应的topic,topic把消息传递给所有的channel ,channel根据算法选择一个订阅客户端,把消息发送给客户端进行处理。 看上去这个流程是没有问题的,我们来思考几个问题
- 网络传输的不确定性,比如超时;客户端处理消息时崩溃等,消息如何重传;
- 如何标识消息被客户端成功处理完毕;
- 消息的持久化,
nsq服务端重新启动时消息不丢失;
服务端对发送中的消息处理逻辑
客户端和服务端进行连接后,会启动一个gorouting来发送信息给客户端
go p.messagePump(client, messagePumpStartedChan)
然后会监听客户端发过来的命令client.Reader.ReadSlice('\n')服务端会定时检查client端的连接状态,读取客户端发过来的各种命令,发送心跳等。每一个连接最终的目的就是监听channel的消息,发送给客户端进行消费。 当有消息发送给订阅客户端的时候,当然选择哪个client也是有规则的
func (p *protocolV2) messagePump(client *clientV2, startedChan chan bool) {// ...for {// ...case b := <-backendMsgChan:if sampleRate > 0 && rand.Int31n(100) > sampleRate {continue}msg, err := decodeMessage(b)if err != nil {p.ctx.nsqd.logf(LOG_ERROR, "failed to decode message - %s", err)continue}msg.Attempts++subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout)client.SendingMessage()err = p.SendMessage(client, msg)if err != nil {goto exit}flushed = falsecase msg := <-memoryMsgChan:if sampleRate > 0 && rand.Int31n(100) > sampleRate {continue}msg.Attempts++subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout)client.SendingMessage()err = p.SendMessage(client, msg)if err != nil {goto exit}flushed = falsecase <-client.ExitChan:goto exit}}// ...}
看一下这个方法调用subChannel.StartInFlightTimeout(msg, client.ID, msgTimeout),在发送给客户端之前,把这个消息设置为在飞翔中,
// pushInFlightMessage atomically adds a message to the in-flight dictionaryfunc (c *Channel) pushInFlightMessage(msg *Message) error {c.inFlightMutex.Lock()_, ok := c.inFlightMessages[msg.ID]if ok {c.inFlightMutex.Unlock()return errors.New("ID already in flight")}c.inFlightMessages[msg.ID] = msgc.inFlightMutex.Unlock()return nil}
在发送中的数据,存在的各种不确定性,nsq的处理方式是:对发送给客户端信息设置为在飞翔中,如果在如果处理成功就把这个消息从飞翔中的状态中去掉,如果在规定的时间内没有收到客户端的反馈,则认为这个消息超时,然后重新归队,两次进行处理。所以无论是哪种特殊情况,nsq统一认为消息为超时。
服务端处理超时消息
nsq对超时消息的处理,借鉴了redis的过期算法,但也不太一样redis的更复杂一些,因为redis是单线程的,还要处理占用cpu时间等等,nsq因为gorouting的存在要很简单很多。 简单来说,就是在nsq启动的时候启动协程去处理channel的过期数据
func (n *NSQD) Main() error {// ...// 启动协程去处理channel的过期数据n.waitGroup.Wrap(n.queueScanLoop)n.waitGroup.Wrap(n.lookupLoop)if n.getOpts().StatsdAddress != "" {n.waitGroup.Wrap(n.statsdLoop)}err := <-exitChreturn err}
当然不是每一个channel启动一个协程来处理过期数据,而是有一些规定,看一下一些默认值
return &Options{// ...HTTPClientConnectTimeout: 2 * time.Second,HTTPClientRequestTimeout: 5 * time.Second,// 内存最大队列数MemQueueSize: 10000,MaxBytesPerFile: 100 * 1024 * 1024,SyncEvery: 2500,SyncTimeout: 2 * time.Second,// 扫描channel的时间间隔QueueScanInterval: 100 * time.Millisecond,// 刷新扫描的时间间隔QueueScanRefreshInterval: 5 * time.Second,QueueScanSelectionCount: 20,// 最大的扫描池数量QueueScanWorkerPoolMax: 4,// 标识百分比QueueScanDirtyPercent: 0.25,// 消息超时MsgTimeout: 60 * time.Second,MaxMsgTimeout: 15 * time.Minute,MaxMsgSize: 1024 * 1024,MaxBodySize: 5 * 1024 * 1024,MaxReqTimeout: 1 * time.Hour,ClientTimeout: 60 * time.Second,// ...}
这些参数都可以在启动nsq的时候根据自己需要来指定,我们主要说一下这几个:
QueueScanWorkerPoolMax就是最大协程数,默认是4,这个数是扫描所有channel的最大协程数,当然channel的数量小于这个参数的话,就调整协程的数量,以最小的为准,比如channel的数量为2个,而默认的是4个,那就调扫描的数量为2个QueueScanSelectionCount每次扫描最大的channel数量,默认是20,如果channel的数量小于这个值,则以channel的数量为准。QueueScanDirtyPercent标识脏数据channel的百分比,默认为0.25,eg:channel数量为10,则一次最多扫描10个,查看每个channel是否有过期的数据,如果有,则标记为这个channel是有脏数据的,如果有脏数据的channel的数量 占这次扫描的10个channel的比例超过这个百分比,则直接再次进行扫描一次,而不用等到下一次时间点。QueueScanInterval扫描channel的时间间隔,默认的是每100毫秒扫描一次。QueueScanRefreshInterval刷新扫描的时间间隔 目前的处理方式是调整channel的协程数量。 这也就是nsq处理过期数据的算法,总结一下就是,使用协程定时去扫描随机的channel里是否有过期数据。
func (n *NSQD) queueScanLoop() {workCh := make(chan *Channel, n.getOpts().QueueScanSelectionCount)responseCh := make(chan bool, n.getOpts().QueueScanSelectionCount)closeCh := make(chan int)workTicker := time.NewTicker(n.getOpts().QueueScanInterval)refreshTicker := time.NewTicker(n.getOpts().QueueScanRefreshInterval)channels := n.channels()n.resizePool(len(channels), workCh, responseCh, closeCh)for {select {case <-workTicker.C:if len(channels) == 0 {continue}case <-refreshTicker.C:channels = n.channels()n.resizePool(len(channels), workCh, responseCh, closeCh)continuecase <-n.exitChan:goto exit}num := n.getOpts().QueueScanSelectionCountif num > len(channels) {num = len(channels)}loop:// 随机channelfor _, i := range util.UniqRands(num, len(channels)) {workCh <- channels[i]}numDirty := 0for i := 0; i < num; i++ {if <-responseCh {numDirty++}}if float64(numDirty)/float64(num) > n.getOpts().QueueScanDirtyPercent {goto loop}}exit:n.logf(LOG_INFO, "QUEUESCAN: closing")close(closeCh)workTicker.Stop()refreshTicker.Stop()}
在扫描channel的时候,如果发现有过期数据后,会重新放回到队列,进行重发操作。
func (c *Channel) processInFlightQueue(t int64) bool {// ...for {c.inFlightMutex.Lock()msg, _ := c.inFlightPQ.PeekAndShift(t)c.inFlightMutex.Unlock()if msg == nil {goto exit}dirty = true_, err := c.popInFlightMessage(msg.clientID, msg.ID)if err != nil {goto exit}atomic.AddUint64(&c.timeoutCount, 1)c.RLock()client, ok := c.clients[msg.clientID]c.RUnlock()if ok {client.TimedOutMessage()}//重新放回队列进行消费处理。c.put(msg)}exit:return dirty}
客户端对消息的处理和响应
客户端要消费消息,需要实现接口
type Handler interface {HandleMessage(message *Message) error}
在服务端发送消息给客户端后,如果在处理业务逻辑时,如果发生错误则给服务器发送Requeue命令告诉服务器,重新发送消息进处理。如果处理成功,则发送Finish命令
func (r *Consumer) handlerLoop(handler Handler) {r.log(LogLevelDebug, "starting Handler")for {message, ok := <-r.incomingMessagesif !ok {goto exit}if r.shouldFailMessage(message, handler) {message.Finish()continue}err := handler.HandleMessage(message)if err != nil {r.log(LogLevelError, "Handler returned error (%s) for msg %s", err, message.ID)if !message.IsAutoResponseDisabled() {message.Requeue(-1)}continue}if !message.IsAutoResponseDisabled() {message.Finish()}}exit:r.log(LogLevelDebug, "stopping Handler")if atomic.AddInt32(&r.runningHandlers, -1) == 0 {r.exit()}}
服务端收到命令后,对飞翔中的消息进行处理,如果成功则去掉,如果是Requeue则执行归队和重发操作,或者进行defer队列处理。
消息的持久化
默认的情况下,只有内存队列不足时MemQueueSize:10000时,才会把数据保存到文件内进行持久到硬盘。
如果将 —mem-queue-size 设置为 0,所有的消息将会存储到磁盘。我们不用担心消息会丢失,nsq 内部机制保证在程序关闭时将队列中的数据持久化到硬盘,重启后就会恢复。nsq自己开发了一个库go-diskqueue来持久会消息到内存。这个库的代码量不多,理解起来也不难, 看一下保存在硬盘后的样子:

select {case c.memoryMsgChan <- m:default:b := bufferPoolGet()err := writeMessageToBackend(b, m, c.backend)bufferPoolPut(b)c.ctx.nsqd.SetHealth(err)if err != nil {c.ctx.nsqd.logf(LOG_ERROR, "CHANNEL(%s): failed to write message to backend - %s",c.name, err)return err}}return nil
整体处理逻辑
go-diskqueue 会启动一个gorouting进行读写数据也就是方法ioLoop
会根据你设置的参数来进行数据的读写
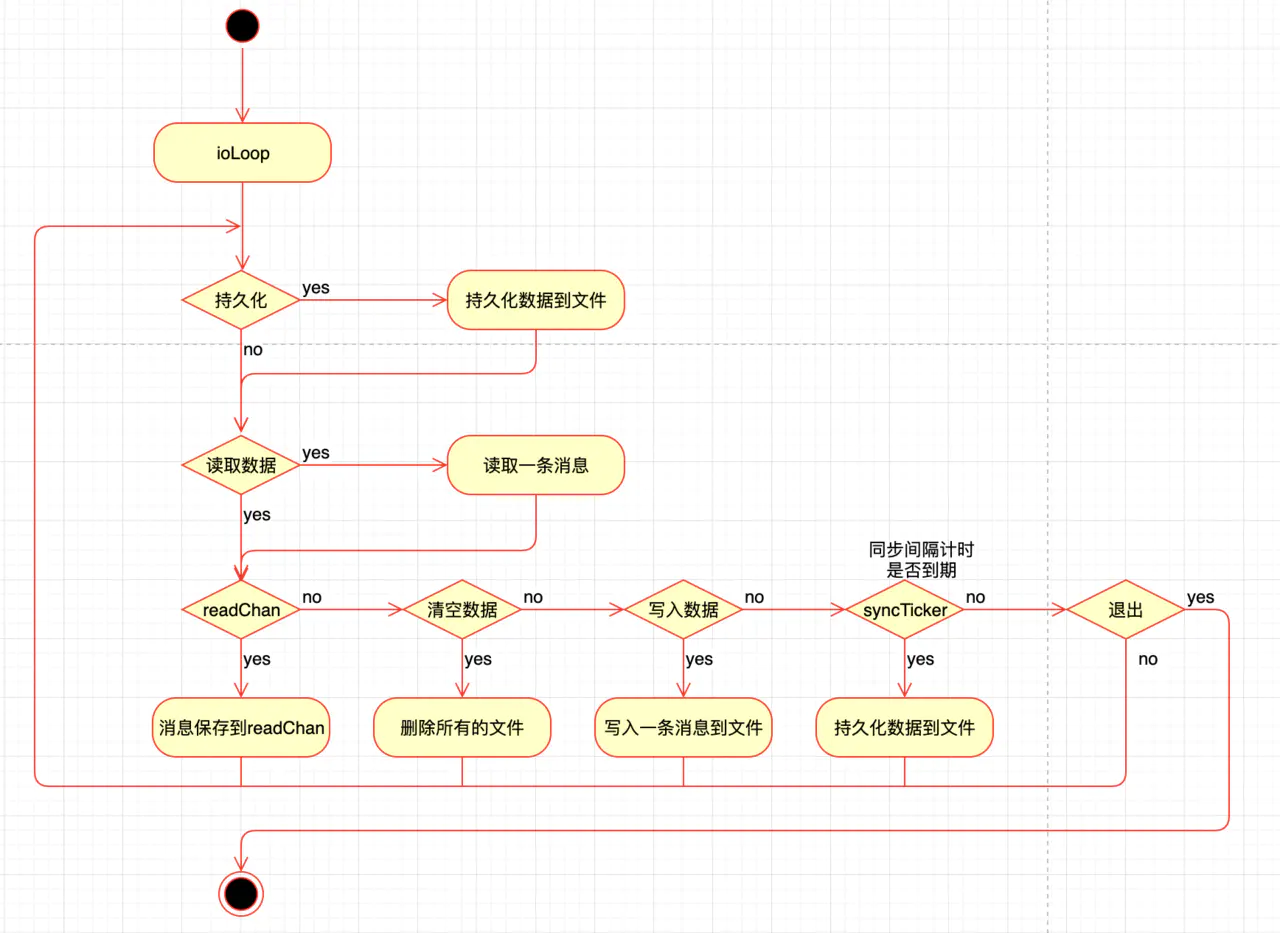
这个图画的也不是特别的准确 ioLoop 用的是 select 并不是if else 当有多个条件为true时,会随机选一个进行执行
参数说明
// diskQueue implements a filesystem backed FIFO queuetype diskQueue struct {// run-time state (also persisted to disk)// 读取数据的位置readPos int64// 写入数据的位置writePos int64// 读取文件的编号readFileNum int64// 写入文件的编号writeFileNum int64// 未处理的消息总数depth int64// instantiation time metadata// 每个文件的大小限制maxBytesPerFile int64 // currently this cannot change once created// 每条消息的最小大小限制minMsgSize int32// 每条消息的最大大小限制maxMsgSize int32// 缓存消息有多少条后进行写入syncEvery int64 // number of writes per fsync// 自动写入消息文件的时间间隔syncTimeout time.Duration // duration of time per fsyncexitFlag int32needSync bool// keeps track of the position where we have read// (but not yet sent over readChan)// 下一条消息的位置nextReadPos int64// 下一条消息的文件编号nextReadFileNum int64// 读取的文件readFile *os.File// 写入的文件writeFile *os.File// 读取的bufferreader *bufio.Reader// 写入的bufferwriteBuf bytes.Buffer// exposed via ReadChan()// 读取数据的channelreadChan chan []byte//.....}
写一条数据
ioLoop 中发现有数据写入时,会调用writeOne方法,把消息保存到文件内
select {// ...case dataWrite := <-d.writeChan:count++d.writeResponseChan <- d.writeOne(dataWrite)// ...
func (d *diskQueue) writeOne(data []byte) error {var err errorif d.writeFile == nil {curFileName := d.fileName(d.writeFileNum)d.writeFile, err = os.OpenFile(curFileName, os.O_RDWR|os.O_CREATE, 0600)// ...if d.writePos > 0 {_, err = d.writeFile.Seek(d.writePos, 0)// ...}}dataLen := int32(len(data))// 判断消息的长度是否合法if dataLen < d.minMsgSize || dataLen > d.maxMsgSize {return fmt.Errorf("invalid message write size (%d) maxMsgSize=%d", dataLen, d.maxMsgSize)}d.writeBuf.Reset()// 写入4字节的消息长度,以大端序保存err = binary.Write(&d.writeBuf, binary.BigEndian, dataLen)if err != nil {return err}// 写入消息_, err = d.writeBuf.Write(data)if err != nil {return err}// 写入到文件_, err = d.writeFile.Write(d.writeBuf.Bytes())// ...// 计算写入位置,消息数量加1totalBytes := int64(4 + dataLen)d.writePos += totalBytesatomic.AddInt64(&d.depth, 1)// 如果写入位置大于 单个文件的最大限制, 则持久化文件到硬盘if d.writePos > d.maxBytesPerFile {d.writeFileNum++d.writePos = 0// sync every time we start writing to a new fileerr = d.sync()// ...}return err}
写入完消息后,会判断当前的文件大小是否已经已于maxBytesPerFile如果大,就持久化文件到硬盘,然后重新打开一个新编号文件,进行写入。
读一条数据
元数据保存着 读取文件的编号 readFileNum 和读取数据的位置 readPos
并且diskQueue暴露出了一个方法来,通过channel来读取数据
func (d *diskQueue) ReadChan() chan []byte {return d.readChan}
ioLoop里,当发现读取位置小于写入位置 或者读文件编号小于写文件编号,并且下一个读取位置等于当前位置时才会读取一条数据,然后放在一个外部全局变量 dataRead 里,并把 读取的channel 赋值监听 r = d.readChan,当外部有人读取了消息,则进行moveForward操作
func (d *diskQueue) ioLoop() {var dataRead []bytevar err errorvar count int64var r chan []bytefor {// ...if (d.readFileNum < d.writeFileNum) || (d.readPos < d.writePos) {if d.nextReadPos == d.readPos {dataRead, err = d.readOne()if err != nil {d.handleReadError()continue}}r = d.readChan} else {r = nil}select {// ...case r <- dataRead:count++// moveForward sets needSync flag if a file is removedd.moveForward()// ...}}// ...}
readOne 从文件里读取一条消息,4个bit的大小,然后读取具体的消息。如果读取位置大于最大文件限制,则close。在moveForward里会进行删除操作
func (d *diskQueue) readOne() ([]byte, error) {var err errorvar msgSize int32// 如果readFile是nil,打开一个新的if d.readFile == nil {curFileName := d.fileName(d.readFileNum)d.readFile, err = os.OpenFile(curFileName, os.O_RDONLY, 0600)// ...d.reader = bufio.NewReader(d.readFile)}err = binary.Read(d.reader, binary.BigEndian, &msgSize)// ...readBuf := make([]byte, msgSize)_, err = io.ReadFull(d.reader, readBuf)totalBytes := int64(4 + msgSize)// ...d.nextReadPos = d.readPos + totalBytesd.nextReadFileNum = d.readFileNum// 如果读取位置大于最大文件限制,则close。在moveForward里会进行删除操作if d.nextReadPos > d.maxBytesPerFile {if d.readFile != nil {d.readFile.Close()d.readFile = nil}d.nextReadFileNum++d.nextReadPos = 0}return readBuf, nil}
moveForward方法会查看读取的编号,如果发现下一个编号 和当前的编号不同时,则删除旧的文件。
func (d *diskQueue) moveForward() {oldReadFileNum := d.readFileNumd.readFileNum = d.nextReadFileNumd.readPos = d.nextReadPosdepth := atomic.AddInt64(&d.depth, -1)// see if we need to clean up the old fileif oldReadFileNum != d.nextReadFileNum {// sync every time we start reading from a new filed.needSync = truefn := d.fileName(oldReadFileNum)err := os.Remove(fn)// ...}d.checkTailCorruption(depth)
什么时候持久化文件到硬盘
调用sync()方法会持久化文件到硬盘,然后重新打开一个新编号文件,进行写入。
有几个地方调用会调用这个方法:
- 一个写入文件的条数达到了
syncEvery的值时,也就是初始化时设置的最大的条数。会调用sync() syncTimeout初始化时设置的同步时间间隔,如果这个时间间隔到了,并且写入的文件条数>0的时候,会调用sync()- 还有就是上面说过的
writeOne方法,写入完消息后,会判断当前的文件大小是否已经已于maxBytesPerFile如果大,会调用sync() - 当读取文件时,把整个文件读取完时,会删除这个文件并且会把
needSync设置为true,ioLoop会调用sync() - 还有就是
Close的时候,会调用sync()
func (d *diskQueue) sync() error {if d.writeFile != nil {// 把数据 flash到硬盘,关闭文件并设置为 nilerr := d.writeFile.Sync()if err != nil {d.writeFile.Close()d.writeFile = nilreturn err}}// 保存元数据信息err := d.persistMetaData()// ...d.needSync = falsereturn nil}
nsq有个选项–mem-queue-size来指示内存消息队列的大小,大于这个大小的消息会被落到磁盘。而磁盘是单文件写入。不支持写入多个节点。总的来说nsqd处理比较简单。
func (t *Topic) put(m *Message) error {select {case t.memoryMsgChan <- m:default:b := bufferPoolGet()//如果消息满了写入backend, 使用go-diskqueue 写入文件。err := writeMessageToBackend(b, m, t.backend)bufferPoolPut(b)t.ctx.nsqd.SetHealth(err)if err != nil {t.ctx.nsqd.logf(LOG_ERROR,"TOPIC(%s) ERROR: failed to write message to backend - %s",t.name, err)return err}}return nil}
官方也介绍一种使用nsqtofile来备份消息,主要是利用一个topic的message会被多个channel消费。
消息的负载处理
实际应用中,一部分服务集群可能会同时订阅同一个topic,并且处于同一个channel下。当nsqd有消息需要发送给订阅客户端去处理时,发给哪个客户端是需要考虑的

如果不考虑负载情况,把随机的把消息发送到某一个客服端去处理消息,如果机器的性能不同,可能发生的情况就是某一个或几个客户端处理速度慢,但还有大量新的消息需要处理,其他的客户端处于空闲状态。理想的状态是,找到当前相对空闲的客户端去处理消息。
nsq的处理方式是客户端主动向nsqd报告自已的可处理消息数量(也就是RDY命令)。nsqd根据每个连接的客户端的可处理消息的状态来随机把消息发送到可用的客户端,来进行消息处理
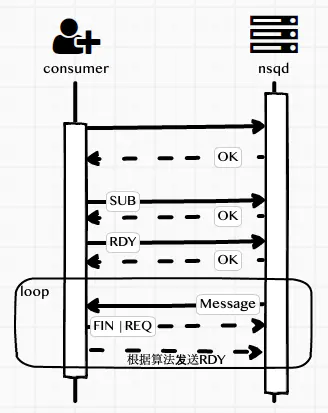
客户端更新RDY
配置consumer的config
config := nsq.NewConfig()config.MaxInFlight = 1000config.MaxBackoffDuration = 5 * time.Secondconfig.DialTimeout = 10 * time.Second
MaxInFlight 来设置最大的处理中的消息数量,会根据这个变量计算在是否更新RDY 初始化的时候 客户端会向连接的nsqd服务端来发送updateRDY来设置最大处理数,
func (r *Consumer) maybeUpdateRDY(conn *Conn) {inBackoff := r.inBackoff()inBackoffTimeout := r.inBackoffTimeout()if inBackoff || inBackoffTimeout {r.log(LogLevelDebug, "(%s) skip sending RDY inBackoff:%v || inBackoffTimeout:%v",conn, inBackoff, inBackoffTimeout)return}remain := conn.RDY()lastRdyCount := conn.LastRDY()count := r.perConnMaxInFlight()// refill when at 1, or at 25%, or if connections have changed and we're imbalancedif remain <= 1 || remain < (lastRdyCount/4) || (count > 0 && count < remain) {r.log(LogLevelDebug, "(%s) sending RDY %d (%d remain from last RDY %d)",conn, count, remain, lastRdyCount)r.updateRDY(conn, count)} else {r.log(LogLevelDebug, "(%s) skip sending RDY %d (%d remain out of last RDY %d)",conn, count, remain, lastRdyCount)}}
当剩余的可用处理数量remain 小于等于1,或者小于最后一次设置的可用数量lastRdyCount的1/4时,或者可用连接平均的maxInFlight大于0并且小于remain时,则更新RDY状态
当有多个nsqd时,会把最大的消息进行平均计算:
// perConnMaxInFlight calculates the per-connection max-in-flight count.//// This may change dynamically based on the number of connections to nsqd the Consumer// is responsible for.func (r *Consumer) perConnMaxInFlight() int64 {b := float64(r.getMaxInFlight())s := b / float64(len(r.conns()))return int64(math.Min(math.Max(1, s), b))}
当有消息从nsqd发送过来后也会调用maybeUpdateRDY方法,计算是否需要发送RDY命令
func (r *Consumer) onConnMessage(c *Conn, msg *Message) {atomic.AddInt64(&r.totalRdyCount, -1)atomic.AddUint64(&r.messagesReceived, 1)r.incomingMessages <- msgr.maybeUpdateRDY(c)}
上面就是主要的处理逻辑,但还有一些逻辑,就是当消息处理发生错误时,**nsq**有自己的退避算法**backoff**也会更新**RDY** 简单来说就是当发现有处理错误时,来进行重试和指数退避,在退避期间RDY会为0,重试时会先放尝试RDY为1看有没有错误,如果没有错误则全部放开,
同时订阅同一topic的客户端(comsumer)有很多个,每个客户端根据自己的配置或状态发送RDY命令到nsqd表明自己能处理多少消息量 nsqd服务端会检查每个客户端的的状态是否可以发送消息。也就是IsReadyForMessages方法,判断inFlightCount是否大于readyCount,如果大于或者等于就不再给客户端发送数据,等待Ready后才会再给客户端发送数据
func (c *clientV2) IsReadyForMessages() bool {if c.Channel.IsPaused() {return false}readyCount := atomic.LoadInt64(&c.ReadyCount)inFlightCount := atomic.LoadInt64(&c.InFlightCount)c.ctx.nsqd.logf(LOG_DEBUG, "[%s] state rdy: %4d inflt: %4d", c, readyCount, inFlightCount)if inFlightCount >= readyCount || readyCount <= 0 {return false}return true}
每一次发送消息inFlightCount会+1并保存到发送中的队列中,当客户端发送FIN会-1
func (p *protocolV2) messagePump(client *clientV2, startedChan chan bool) {// ...for {// 检查订阅状态和消息是否可处理状态if subChannel == nil || !client.IsReadyForMessages() {// the client is not ready to receive messages...memoryMsgChan = nilbackendMsgChan = nilflusherChan = nil// ...flushed = true} else if flushed {memoryMsgChan = subChannel.memoryMsgChanbackendMsgChan = subChannel.backend.ReadChan()flusherChan = nil} else {memoryMsgChan = subChannel.memoryMsgChanbackendMsgChan = subChannel.backend.ReadChan()flusherChan = outputBufferTicker.C}select {case <-flusherChan:// ...// 消息处理case b := <-backendMsgChan:client.SendingMessage()// ...case msg := <-memoryMsgChan:client.SendingMessage()//...}}// ...}
nsq如何水平扩展
nsqd pub消息的时候都会要求指定nsqd服务。nsqd并没有提供负载均衡的方式。需要手动确定使用的nsqd服务地址。也就是说需要客户端自己负载均衡。每一个topic对应唯一的nsqd,consumer端倒是可以通过nsqlookupd来进行服务发现。
func main(){cfg := nsq.NewConfig()p, _ := nsq.NewProducer("localhost:addr", cfg)p.Publish("hello world", []byte("hello world"))}

若有收获,就点个赞吧
0 人点赞
