查看慢查询是否开启
show variables like '%slow_query_log';
开启慢查询
set global slow_query_log='ON';
看下慢查询的时间阈值设置
show variables like '%long_query_time%';
想把时间缩短,比如设置为 3 秒
set global long_query_time = 3;
使用 EXPLAIN 查看执行计划
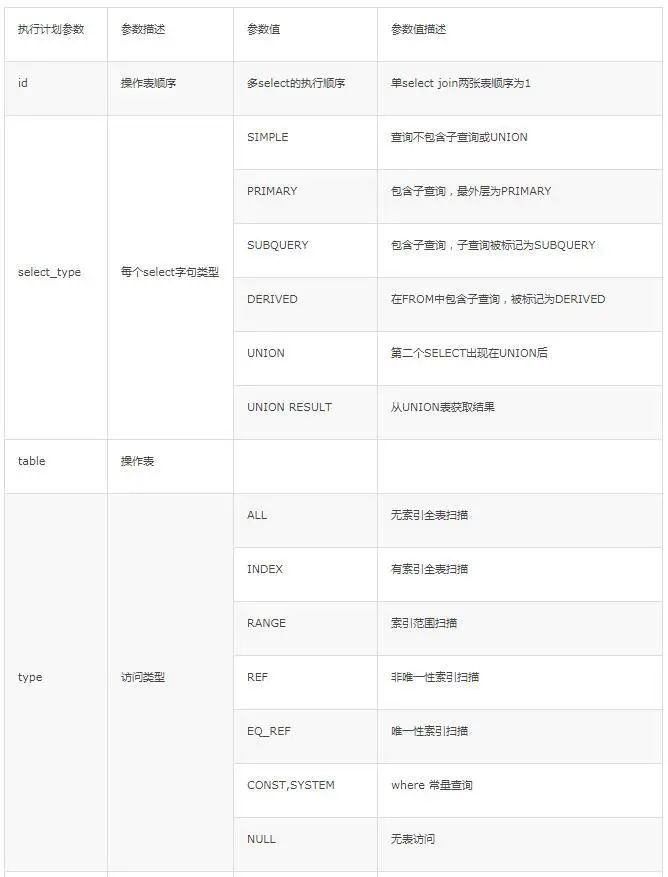
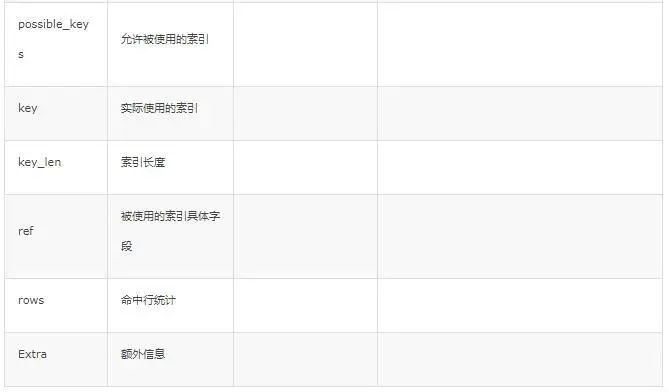
| 序号 | 列名 | 含义 |
|---|---|---|
| 0 | select_type | SELECT 查询的类型. |
| 1 | partitions | 匹配的分区 |
| 2 | type | join 类型 |
| 3 | possible_keys | 此次查询中可能选用的索引 |
| 4 | key | 此次查询中确切使用到的索引. |
| 5 | ref | 哪个字段或常数与 key 一起被使用 |
| 6 | rows | 显示此查询一共扫描了多少行. 这个是一个估计值. |
| 7 | filtered | 表示此查询条件所过滤的数据的百分比 |
| 8 | extra | 额外的信息 |
| 9 | key-len | 使用到索引字段的长度 |
select_type
select_type 表示了查询的类型, 它的常用取值有:
- SIMPLE, 表示此查询不包含 UNION 查询或子查询
- PRIMARY, 表示此查询是最外层的查询
- UNION, 表示此查询是 UNION 的第二或随后的查询
- DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询
- UNION RESULT, UNION 的结果
- SUBQUERY, 子查询中的第一个 SELECT
- DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
type
type 字段比较重要, 它提供了判断查询是否高效的重要依据依据. 通过 type 字段, 我们判断此次查询是 全表扫描 还是 索引扫描 等.
| type | 说明 |
|---|---|
| all | 全表扫描,mysql 遍历全表来找到匹配的行: |
| index | 索引全扫描,mysql 遍历整个索引来查询匹配的行 |
| range | 索引范围扫描,常见于<、<=、>、>=、between等操作: |
| ref | 根据索引查找一个或多个值,通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询. |
| index_merge | 合并索引,使用多个单列索引搜索 |
| eq_ref | 使用primary key 或unique类型,常用于多表联查 |
| const | 针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可. |
| system | 表中只有一条数据. 这个类型是特殊的 const 类型. |
all 是最坏的情况,因为采用了全表扫描的方式。index 和 all 差不多,只不过 index 对索引表进行全扫描,这样做的好处是不再需要对数据进行排序,但是开销依然很大。如果我们在 Extral 列中看到 Using index,说明采用了索引覆盖,也就是索引可以覆盖所需的 SELECT 字段,就不需要进行回表,这样就减少了数据查找的开销。
慢查询分析
- 先对 sql 语句进行 explain,查看语句存在的问题
- 使用 show profile 查看执行耗时,分析具体耗时原因
数据库瓶颈
- IO 瓶颈 第一种:磁盘读 IO 瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的 IO,降低查询速度 -> 分库和垂直分表。
第二种:网络 IO 瓶颈,请求的数据太多,网络带宽不够 -> 分库。
- CPU 瓶颈 第一种:SQL 问题,如 SQL 中包含 join,group by,order by,非索引字段条件查询等,增加 CPU 运算的操作 -> SQL 优化,建立合适的索引,在业务 Service 层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL 效率低,CPU 率先出现瓶颈 -> 水平分表。

若有收获,就点个赞吧
0 人点赞
